去年之前,阿里巴巴的淘天集团测试环境是以领域方式运作:不局限测试环境治理本身,从测试模式方法论及用好测试环境思路引领集团测试环境治理。领域运作最难的是“统一思想”。业务进一步细分调整后,测试环境治理策略理应由业务方自行决策,领域尽可能多的提供更好用的工具产品供业务方使用。
测试环境产品得很稳定,让用户相信环境是可靠的,其次环境部署需要高效,二者缺一不可。下面从这两个方面做一下阐述。
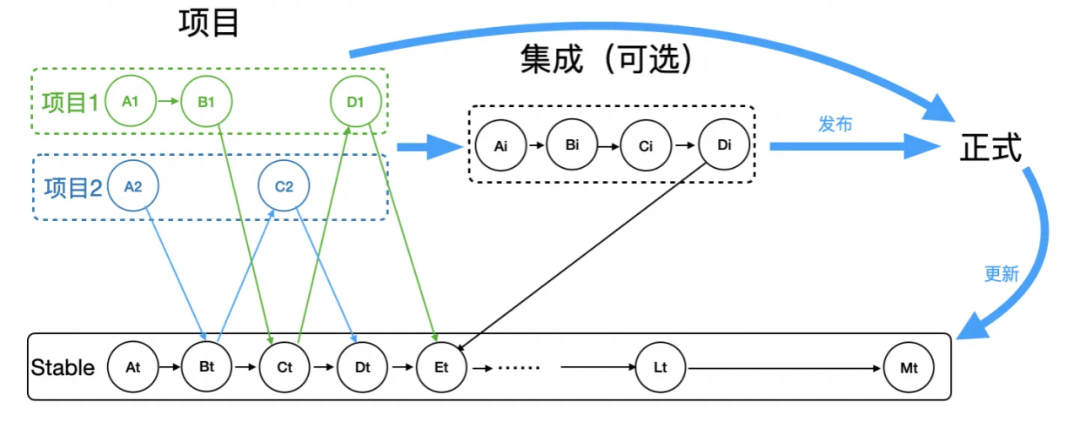
从图1可以看出,可靠性主要有两个:
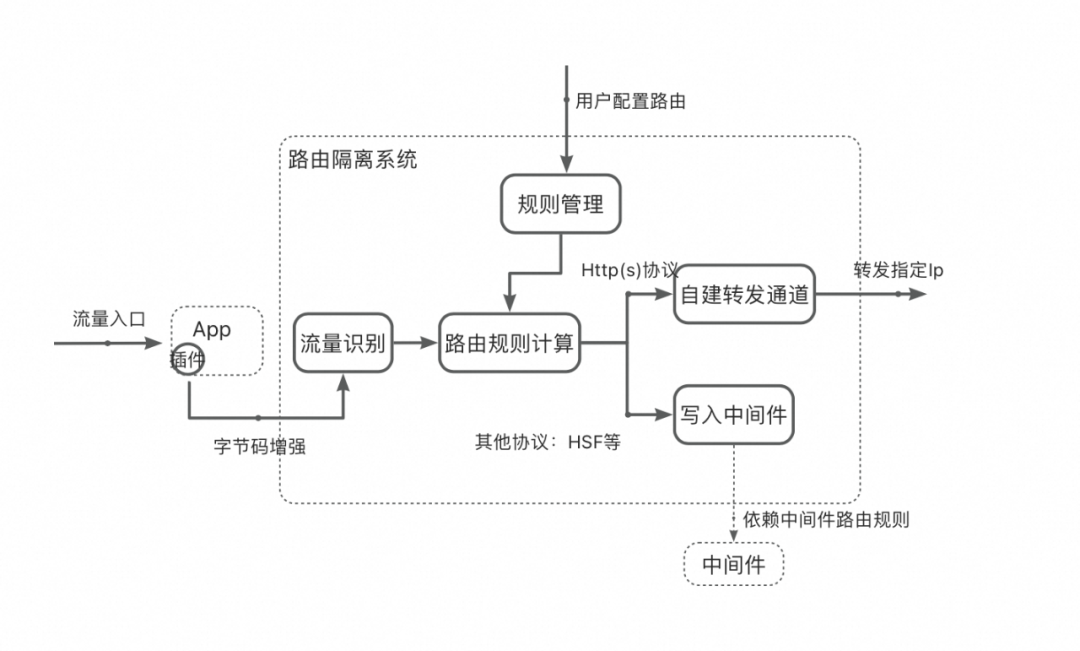
▐ 路由隔离
通用的隔离逻辑:从项目环境发起的流量,下游默认调用项目环境,如果没有,就调用Stable环境兜底。这看似很简单,只要使用过都能理解,但要所有人都能理解(统一思想)又挺难。团队新人入职,都需要深入学习一遍。
因此环境组在上述通用逻辑基础上,做了账号与环境绑定的路由隔离产品:只要用户绑定了账号和环境的关系,这个账号所有到这个应用的请求,一定会走到绑定的环境上,而不用了解环境相关的任何业务逻辑。
路由准确性高要求不言而喻,所以最近一年发了120+迭代来提升路由系统稳定性,稳定性有了质的飞跃。总结如下:
-
重构字节码增强。
-
升级插件安装:守护进程和路由插件分离。
-
改进自建转发路由方案。
路由稳定性提升还在持续,长尾问题如流量账号解析等还需进一步挖掘治理。
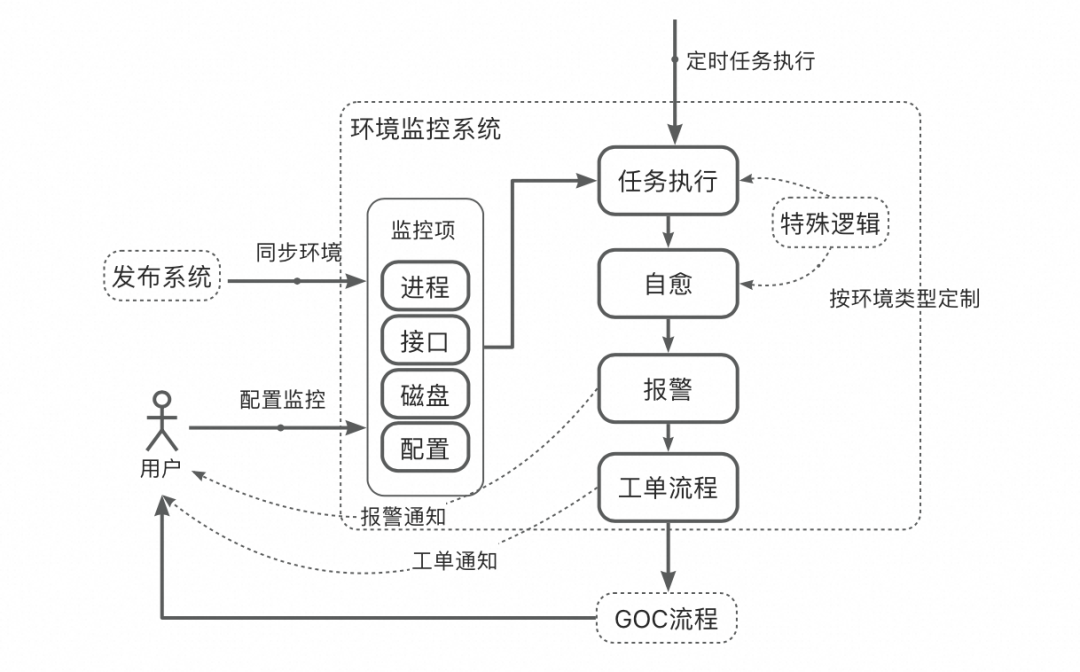
▐ 环境监控
Stable环境作为基座环境必须稳定,因此需要对Stable环境进行监控。Stable环境流量小,时有时无,和线上大流量不同,不可以通过流量下跌来判断稳定性。倘若借用线上思路,自动打大流量检测,投入产出比不高。环境组也尝试过,核心链路可行,但不具备通用性。经过这几年的实践,还是以业务视角的监控指标有用、可靠、维护成本低。
-
检测进程、HSF接口心跳、磁盘空间
-
接口(http(s)/HSF)自动化巡检并断言
监控只是提前发现问题,最终还是需要解决问题,所以发现问题后,系统先进行自愈(不限于重启、磁盘清理等),后故障仍然不能消除的,报警通知责任人,走GOC的风险预警及故障处理流程。
监控系统还需要考虑低成本的维护,在用户不介入的前提下就有较高的监控水平。环境系统自动同步Stable环境的变化,在无人介入情况下,通过fuzz方式随机出接口测试用例并发起接口调用巡检。针对不同的环境类型,分层处理,如:fuzz的测试用例是随机的,可以运用在线下Stable环境,而预发DB与线上共用,不能使用fuzz从而污染线上环境。同理,磁盘自动清理也只使用在线下。
环境的稳定,不仅仅在于服务的稳定,动态配置的一致性也至关重要。用户共用一套动态配置成本最低,而为了自己验证需要,可随意变更配置,以至于对其他用户产生影响也不自知。其他用户每次验证时不会也不可能做到check每个配置,就会出现“测非所测”情况。用户做不到的,由监控系统来兜底。
环境监控的业务监控逻辑也可以运用在线上环境,对线上环境监控是一个有力的补充。
▐ 可观测
环境报警后的问题排查就依赖可观测产品来快速排查与定位,好的可观测产品一定具备以下特点:
在实际实施过程中,具有业务定制的技术栈如:function函数服务等都需要关联系统对接,“逢山开路、遇水搭桥”。这也是环境治理最需要坚持的事情。
![]()
启动加速
环境可靠是基石,基石稳定后追求的自然是高效部署;一个应用构建与部署时长超过10分钟,感受不强烈,但是放到淘天集团的体量对效率的影响就非常巨大。以我自己应用为例,全量部署一次在12分钟左右,一个feature开发完后的第一次部署,因为心理有预期,能接受这个时长,大不了喝杯coffee;但是改bug的时候,改了一行验证也是需要12分钟,这就很难接受了。一天通常得部署5~6次,但也喝不了那么多coffee;所以,高效部署不仅仅是高效这点收益,同时是程序员的幸福感提升。
“高效部署”这个命题,前人前赴后继做了很多的工作。去年我们环境组与阿里云jvm团队合作也在cds技术上做了研究与尝试。环境系统会自动将分支没有修改到的代码缓存起来,无需重新进行类加载,从而提升部署效率,单次部署时长缩短30s。有一定的效果,但和总量10分钟相比又显的是“萤火之光”。要想达到秒级效果,还是得死磕热部署。
![]()
图4:热部署与部署流水线结合
代码差异检测这一点,就很难做到100%,在当下基于dcevm技术、爱橙科技的fastboot技术基础上,再新增插件能力来解决。目前的思路是通过分层的方式:
-
只修改方法体的代码,直接redefine,秒级生效
-
文件的增删,bean与中间件等变更借助于dcevm与fastboot技术,做到秒级生效
-
对于确实无法做到的热部署的,与现有的部署方式保持不变,走全量部署。
自从尝试了一下启动加速的秒级效果,有那种“天突然亮了”的感觉。启动加速还在继续丰富插件来支持更多的场景,降低第三种部署方式的次数。
![]()
测试数据
测试环境高效稳定,其实还不能做到高效的验证,因为测试数据也是验证过程中的关键一环。核心团队质量TL明确和我说:“如果能解决好测试数据构造的问题,至少我们的效率可以再提升30%”。可见测试数据的重要性。为此进行了相关调研,结论如下:
1. 跨部门的数据构造依旧很难
2. 自己域内容易解决,但解决方案对外部门通用性不够。
3. 链路级别的数据构造基本上需要再新起应用来包一层服务来提供,成本高。
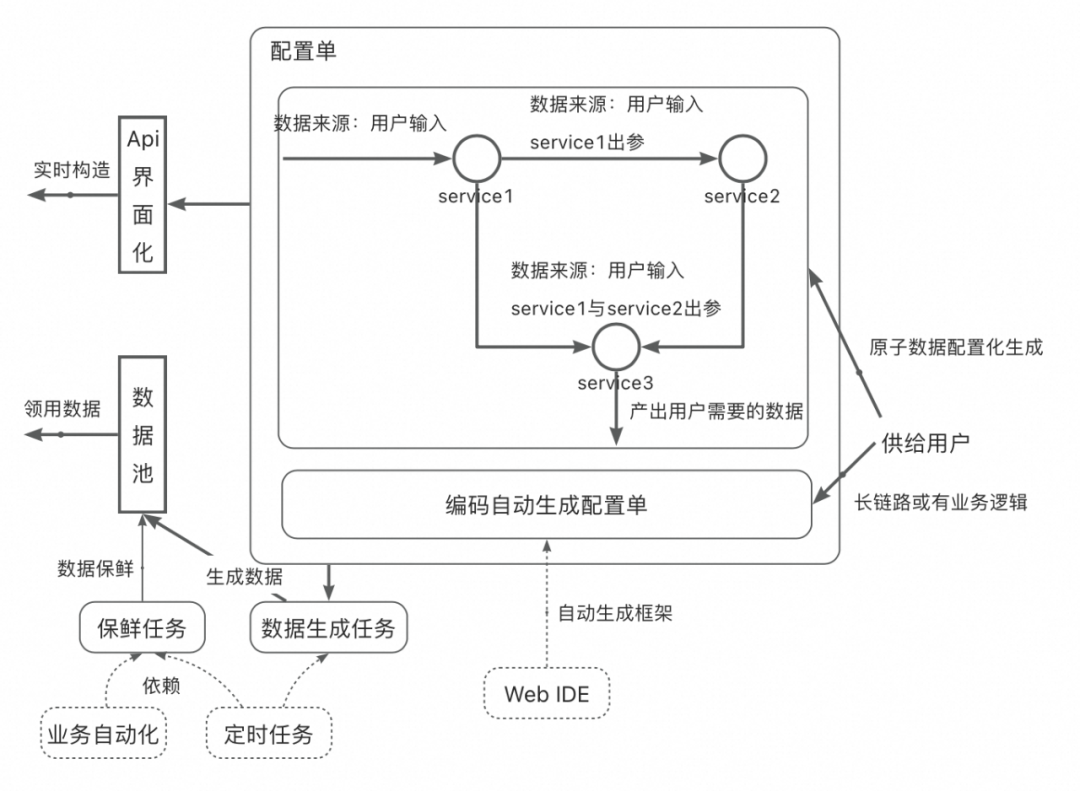
为此,环境组孵化了配置化数据构造的系统,具体的逻辑如下:
![]()
图5:配置化数据构造示意图
配置化数据构造,提供数据构造的两大基础能力:界面化通过接口完成数据配置单配置和用户利用基础节点编码框架生成配置单。用户可以通过Api界面化的面包版实时构造数据,也可以通过有保鲜能力的数据池直接领用想要的数据。
数据构造最核心的是原子数据的供给。供给原子数据丰富度以及更新效率直接影响上层用户的使用,这块是任何业务都需要优先保障的事项。
![]()
可测性
测试环境与测试数据是研发效能问题的基座。依然存在上层可测性问题带来低效点。当然可测性问题不是某个环境特有的,只是部分环境如:线下环境可以暴力的去解决,譬如:直接update DB、clean cache、modify Date等快速支持让线下环境的可测性不是那么突出。在预发环境或者SPE环境下,因为DB和线上共用,使得很多解决可测性的策略都需要考虑不能产生故障这条铁律!下面以时间穿越案例做一下阐述。
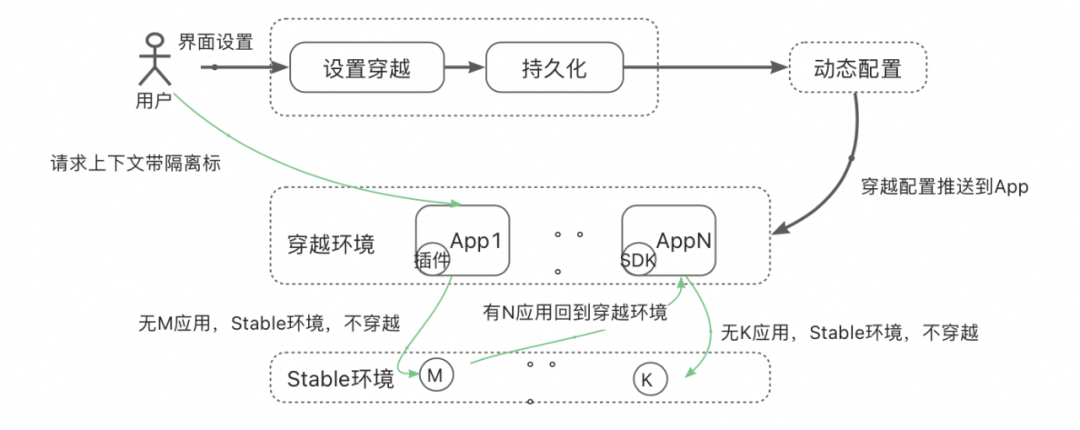
▐ 时间穿越
先抛一个问题:需要做一个活动,在3天后的00:00点发一批消费券。系统代码无需改动,只需要业务同学后台进行复杂的配置即可。那将如何测试?
从上述分析,问题转化为:业务同学作为用户只想有且只配置一次消费券,技术同学需要保证业务同学配置的这次消费券是正确的,能正常的发送到C端消费者手上。这就需要时间穿越。
很显然想到的方法,就是修改机器时间,这样带来两个问题:
因此,好的时间穿越产品就至少要必须具备以下3点:
环境组根据用户id,对System.currentTimeMillis做字节码增强,进行时间穿越,无需重启机器,环境准备时间<10分钟。
目前时间穿越产品已经支持多次大促预演,时间穿越是可测性的一个缩影,随着对研发效能的深入,相信会有更多可测性问题等着我们去解决,研发效能也将会逐步提升。
目前的测试环境实践部分方案是基于当前的现状做了局部最优的选择,并非终态方案。有些在已有的基础上做的升级,有些依赖于架构治理的妥协选择:
-
Stable环境稳定可靠最核心方案应该是运维等级等同于线上,如与线上一同发布、机器规格、部署策略、操作管控等。这方面能力淘天集团前几年已经完成相关的升级。
-
可观测系统对长尾技术栈需要按部就班的接入,如果所有架构统一,也就无需多余的投入。
-
动态配置产品在分支隔离和使用规范上做到极致,其实也无需配置巡检。
-
如果大促活动系统可以做到业务配置活动“所配即所得”,也无需独立的时间穿越产品。
在此希望各位同仁在做任何系统的时候,在考虑“功能又不是不能用”的同时,多思考一下系统的可测性和规范统一性。
![]()
团队介绍
我们是淘天集团-技术架构&后端研发团队,一支专注于研发基础设施和技术体系建设的团队,依托大淘宝现有的架构,致力于研发所需的运行时、工具、平台、流程等,确保研发效率的高效;不断探索和应用新技术、新方法,缩短交付周期、提高交付质量、降低交付成本,建立业界领先的技术架构和研发体系。我们不断通过技术创新和突破,使得淘天业务技术能快速响应市场变化和客户需求,提升公司的市场竞争力。