GaussDB关键技术原理:高性能(三)从查询重写RBO、物理优化CBO、分布式优化器、布式执行框架、轻量全局事务管理GTM-lite等五方面对高性能关键技术进行了解读,本篇将从USTORE存储引擎、计划缓存计划技术、数据分区与分区剪枝、列式存储和向量化引擎、SMP并行执行等方面继续介绍GaussDB高性能关键技术。
3.6 USTORE存储引擎
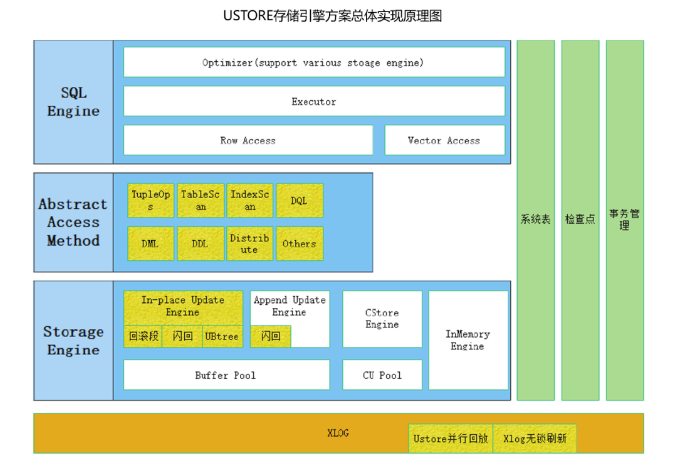
GaussDB新增的Ustore存储引擎,相比于Append Update(追加更新)行存储引擎,Ustore存储引擎可以提高数据页面内更新的HOT UPDATE的垃圾回收效率,有效减少多次更新元组后存储空间占用的问题。设计原理上Ustore存储引擎采用NUMA-aware的Undo子系统设计,使得Undo子系统可以在多核平台上有效扩展;同时采用多版本索引技术,解决索引清理问题,有效提升了存储空间的回收复用效率。Ustore存储引擎结合Undo空间,可以实现更高效、更全面的闪回查询和回收站机制,能快速回退人为“误操”为GaussDB Kernel提供了更丰富的企业级功能。Ustore基于Undo回滚段技术、页面并行回放技术、多版本索引技术、xLog无锁落盘技术等实现了高可用高可靠的行存储引擎。
![]()
USTORE存储引擎作为原有ASTORE存储引擎的替代者其核心目标定位于:
(1)针对OLTP场景,实现Inplace-update,利用Undo实现新旧版本分离存储;降低类似于AStore存储引擎由于频繁更新或闪回功能开启导致的数据页空间膨胀,以及相应的索引空间膨胀。
(2)通过在DML操作过程中执行动态页面清理,去除VACUUM依赖,减少由于异步数据清理产生的大量读写I/O。通过Undo子系统,实现事务级的空间管控,旧版本集中回收。
(3)对插入、更新、删除等各种负载的业务,性能和资源使用表现相对平衡。在频繁更新类的业务场景中,更新操作采用原地更新模式,可以获得更高、更平滑的性能表现。适合“短”(事务短)、“频”(更新操作频繁)、“快”(性能要求高)的典型 OLTP类业务场景
3.7 计划缓存计划技术
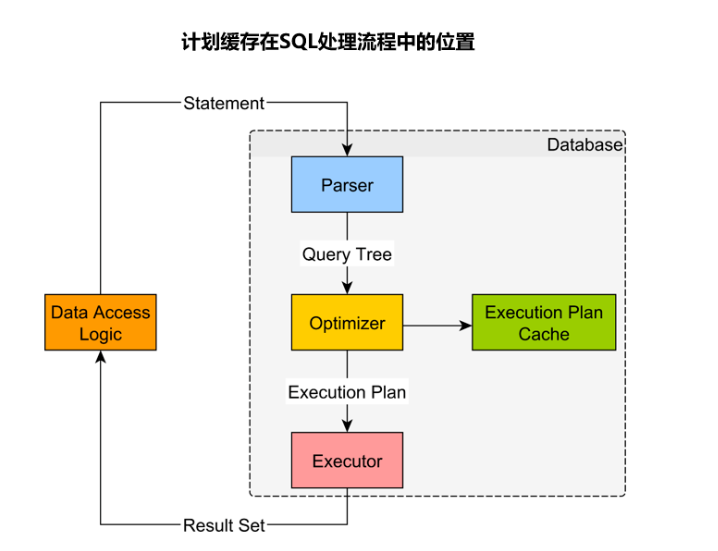
数据库接收到SQL语句后通常要经过如下处理:词语法解析->优化重写->生成执行计划-> 执行,从开始解析到计划生成其实是一个比较耗时的过程,一个常用的思想就是将计划缓存下来,当执行到相似的SQL时,从而可以复用计划,跳过SQL语句生成执行计划的整个过程,在一般OLTP业务负载中,由于涉及到的数据量较少,同时借助索引技术能够大大加速数据的访问路径,因此查询的解析、重写、优化阶段占比会比价高,如果能够讲一些模板性质的语句计划缓存起来,每次设置不同的参数那么点查询的处理流程能够大大简化,提升查询时延和并发吞吐量。
![]()
计划缓存技术:当数据库收到一条 SQL 请求后,首先会通过查询即系模块对 SQL 文本做一次快速参数化处理,参数化处理的作用是把 SQL 文本中的常量参数替换成通配符 ?,例如 SELECT * FROM t1 WHERE c1 = 1 会被替换为 SELECT * FROM t1 WHERE c1 = ?。接着数据库会从计划缓存中查看有没有已经生成好的计划给这条参数化后的 SQL 使用。如果找到了可用的计划,数据库就会直接执行这个计划。如果没有找到可用的计划,数据库会重新为这条 SQL 生成执行计划,并把生成好的计划保存到计划缓存中以备后续的 SQL 使用。通常情况下从计划缓存中直接获取执行计划相比于重新生成执行计划,耗时通常会低至少一个数量级,因此使用计划缓存可以大大降低获取执行计划的时间,从而减少 SQL 的响应时间。
![]()
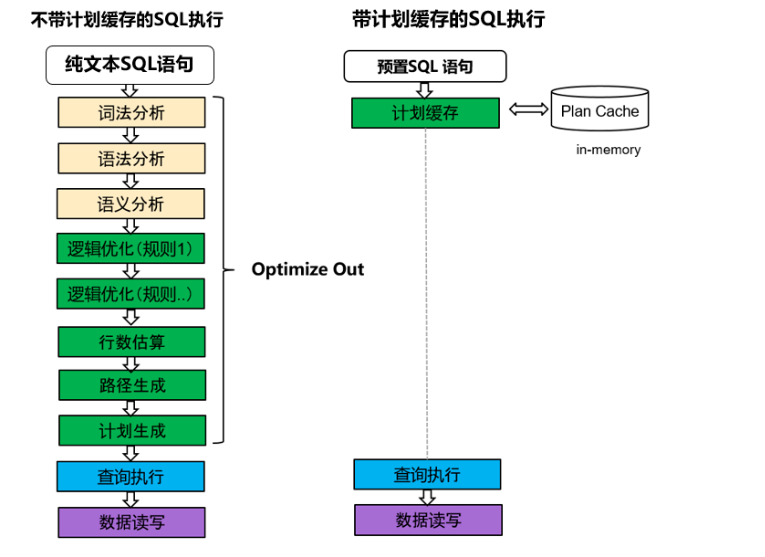
上图为对比走计划缓存、不走计划缓存的SQL执行过程,可以看到执行待计划缓存的查询语句可以规避掉大量的处理逻辑,在OLTP并发负载场景下提升效果镜像,首先,事务型负载单条查询执行时间本身就在毫秒级ms,查询解析、RBO/CBO优化等一些列过程也是毫秒级往往会超过查询本身的执行时间,另一方面,查询解析、RBO/CBO本身是消耗CPU计算资源的操作,这对事务型高并发、高吞吐的事务型复杂起来说非常明显的资源占用,如果能将这部分资源剩下、同时将查询解析的时延消减为0对整体性能是非常明显的提升
3.8 数据分区与分区剪枝
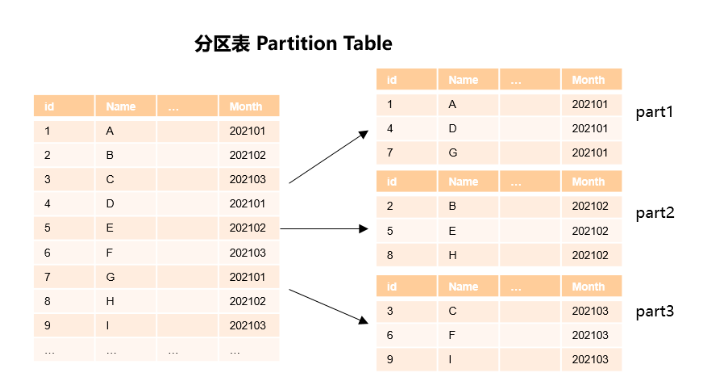
在数据系统中,数据分区是在一个实例内部按照用户指定的策略对数据做进一步的数据切分,将表按照指定规则划分为多个数据互不重叠的部分。从数据分区的角度来看是一种水平分区(horizontal partition)分区策略方式。分区表增强了数据库应用程序的性能、可管理性和可用性,并有助于降低存储大量数据的总体拥有成本。分区允许将表、索引和索引组织的表细分为更小的部分,使这些数据库对象能够在更精细的粒度级别上进行管理和访问。GaussDB Kernel提供了丰富的分区策略和扩展,以满足不同业务场景的需求。由于分区策略的实现完全由数据库内部实现,对用户是完全透明的,因此它几乎可以在实施分区表优化策略以后做平滑迁移,无需潜在耗费人力物力的应用程序更改:
(1)改善查询性能,对分区对象的查询可以仅搜索自己关心的分区,提高检索效率
(2)增强可用性,如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
(3)方便维护,如果分区表的某个分区出现故障需要修复数据,只修复该分区即可。
![]()
常见数据库支持的分区表为范围分区表、列表分区表、哈希分区表、间隔分区、组合分区(a.w.k 组合分区)。
(1)范围分区(Range Partition):将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的。范围分区功能,即根据表的一列或者多列,将要插入表的记录分为若干个范围(这些范围在不同的分区里没有重叠),然后为每个范围创建一个分区,用来存储相应的数据。
(2)列表分区(List Partition):将数据基于各个分区内包含的键值映射到每一个分区,分区包含的键值在创建分区时指定。列表分区功能,即根据表的一列,将要插入表的记录中出现的键值分为若干个列表(这些列表在不同的分区里没有重叠),然后为每个列表创建一个分区,用来存储相应的数据。
(3)哈希分区(Hash Partition):将数据通过哈希映射到每一个分区,每一个分区中存储了具有相同哈希值的记录。
(4)间隔分区(Interval Partition):可以看成是范围分区的一种增强和扩展方式,相比之下间隔分区定义分区时无需为新增的每个分区指定上限和下限值,只需要确定每个分区的长度,实际插入的过程中会自动进行分区的创建和扩展。间隔分区在创建初始时必须至少指定一个范围分区,范围分区键值确定范围分区的高值称为转换点,数据库为值超出该转换点的数据自动创建间隔分区。每个区间分区的下边界是先前范围或区间分区的非包容性上边界。
(5)二级分区(Sub Partition,也叫组合分区)是基本数据分区类型的组合,将表通过一种数据分布方法进行分区,然后使用第二种数据分布方式将每个分区进一步细分为子分区。给定分区的所有子分区表示数据的逻辑子集。常见的二级分区组合由Range、List、Hash组成。
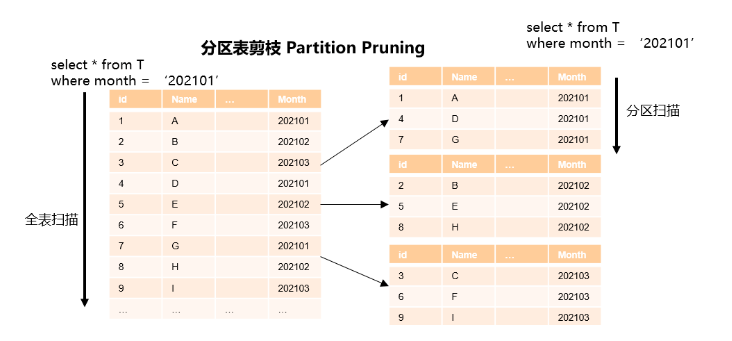
分区表对查询性能最大的贡献是分区剪枝优化技术,数据库SQL引擎会根据查询条件,只扫描特定的部分分区。分区剪枝是自动触发的,当分区表查询条件符合剪枝场景时,会自动触发分区剪枝。根据剪枝阶段的不同,分区剪枝分为静态剪枝和动态剪枝,静态剪枝在优化器阶段进行,在生成计划之前,数据库已经知道需要访问的分区信息;动态剪枝在执行器阶段进行(执行开始/执行过程中),在生成计划时,数据库并不知道需要访问的分区信息,只是判断“可以进行分区剪枝”,具体的剪枝信息由执行器决定。
![]()
注意,分区表由于相比普通表多了一层分区选择的处理逻辑,一般而言在数据导入场景下会有一定的性能损耗。
3.9 列式存储和向量化引擎
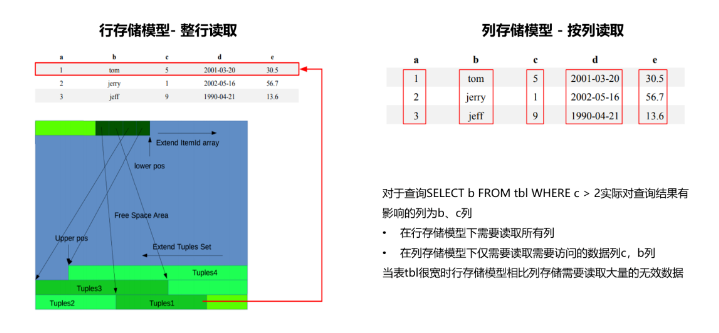
传统关系型数据库中对数据模式都是以元组(记录)的形式进行理解和存取,但是在大数量偏分析类的OLAP应用场景中,属于以列方式存储能够获得更高的执行效率,GaussDB Kernel支持行存储和列存储两种存储模型,用户可以根据应用场景,建表的时候选择行存储还是列存储表。一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不是很多,适合列存储;如果表的字段个数比较少查询大部分字段,那么选择行存储比较好,以下是行存表、列存表在存储模型上的对比。
![]()
可以看到通常在大宽表、数据量比较大的场景中,查询少数特定的列、行时,行存引擎查询性能比较差。例如单表有200~800个列,经常查询访问的仅其中10个列,在这种情况下,向量化执行技术和列存储引擎可以极大地提升性能,减少存储空间。
向量化执行引擎
针对数据的列式存储,GaussDB在执行层改进了传统的执行引擎数据流遵循一次一元组的VectorBatch模式,而向量化引擎VectorEngine将这个执行器算子数据传递、计算模型改成VectorBatch模式,这种看似简单的修改却带来非常明显的性能提升。
![]()
其中的主要提升原因可以应对上面介绍的CPU架构里影响性能的几个关键因素:
(1)Batch模式的函数模型在控制流的调动下,每次都需要进行函数调用,调用次数随着数据增长而增长,而一批元组的模式则大大降低了执行节点的函数调用开销,如果我们设定Batch元组数量为1000,函数调用相对于一次一元组能减少三个数量级。
(2)VectorBatch模式在内部实现通过数组来表达,数组对于CPU的预取非常友好,能够让数组在后续的数据处理过程中,大概率能够在CACHE中命中。比如对于下面这个简单计算两个整形加法的表达式函数(其代码仅为了展示,不代表真实实现),下面展示了单元组和VectorBatch元组的两种写法。
单元组的整形加法
int int4addint4(int4 a, int b)
{
return a+b;
}
VectorBatch模式的整型加法
void int4addint4(int4 a[], int b[], int res[])
{
for(int i = 0; i < N; i++)
{
res[i] = a[i] + b[i];
}
}
(3)VectorBatch模式计算函数内部因为CPU CACHE的局部性原理,数据和指令的cache命中率会非常好,极大提升处理性能,同时也为数据数组化的组织方式为利用SIMD特性带来了非常好的机会,SIMD能够大大提升在元组上的计算性能,还是以刚才上述整形加法的例子,我们可以重写上述的函数如下。可以看到,由于SIMD可以一次处理一批数据,循环的次数衰减,性能能得到进一步提升。
void int4addint4SIMD(int4 a[], int b[], int res[])
{
for(int i = 0; i < N/SIMDLEN; i++)
{
res[i..i+SIMDLEN] = SIMDADD(a[i..i+SIMDLEN], b[i..i+ SIMDLEN];
}
}
![]()
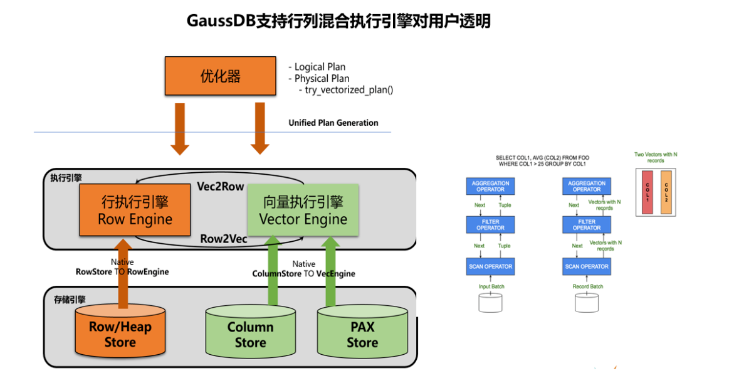
在当前GaussDB里向量化引擎和普通行存引擎共存对上上层用户透明,行引擎处理单元TupleSlot与向量化引擎处理单元VectorBatch通过行转列Row2Vec、列转行Vec2Row进行在线转换,因此在复杂查询中涉及到行存、列存表时优化器能够结合代价模型并针对一些典型场景判断使用向量化引擎、行存引擎进行处理将资源利用最大化。
3.10 SMP并行执行
GaussDB Kernel的SMP并行技术是一种利用计算机多核CPU架构来实现多线程并行计算,以充分利用CPU资源来提高查询性能的技术。在复杂查询场景中,单个查询的执行较长,系统并发度低,通过SMP并行执行技术实现算子级的并行,能够有效减少查询执行时间,提升查询性能及资源利用率。SMP并行技术的整体实现思想是对于能够并行的查询算子,将数据分片,启动若干个工作线程分别计算,最后将结果汇总,返回前端。SMP并行执行增加数据交互算子(Stream),实现多个工作线程之间的数据交互,确保查询的正确性,完成整体的查询。
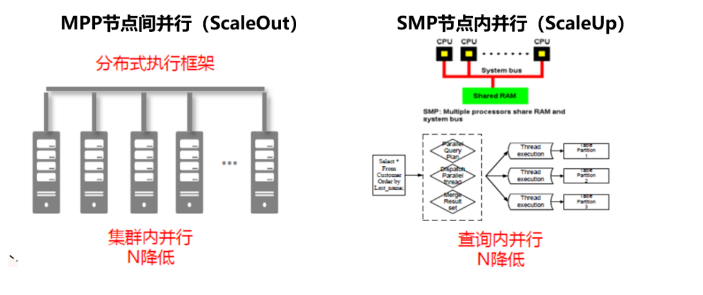
并行技术是提升数据库处理能力的有效手段,关于并行技术GaussDB总体升分成了两个大类:
(1)提升单节点ScaleUp:决定整体系统的理论性能上限,充分发挥单节点CPU、内存资源的对业务输出的贡献程度。
(2)提升分布式ScaleOut:决定整体系统的实际性能上限,分布式实现的好坏决定了横向的线性扩展比。
![]()
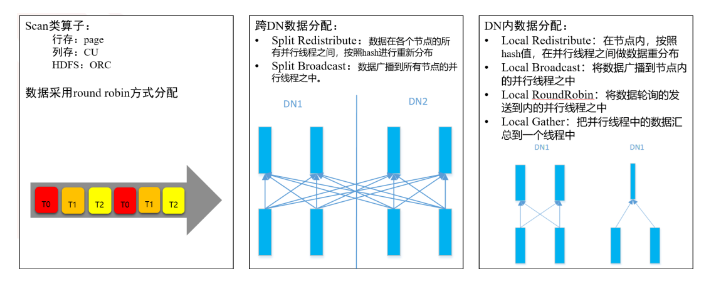
SMP对称多处理的实现过程:
(1)SMP计划生成:一阶段计划生成:在路径生成阶段,加入并行路径,最终根据代价,决定所选择的计划两阶段计划生成:第一步生成原有的串行计划,第二步在将串行计划改造成适应并行的计划。
(2)SMP执行过程:为并行执行线程之间进行数据分配、交换和汇总(Scan类:磁盘;stream:网络)。
![]()
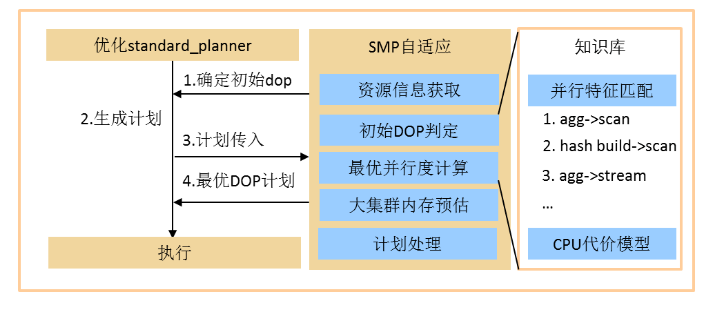
SMP对称多处理自适应选择
SMP优化执行对当前执行的资源环境因素相关,因此 不同的硬件环境、不同系统负载的情况下可用的计算资源存在差异,不同时刻特定查询复杂度需要的计算资源也存在不同;自适应SMP目标在于基于当前系统可用资源以及可生成SMP计划的情况,综合判定查询的执行计划。SMP自适应分为两个阶段,第一阶段确定初始dop,第二阶段对基于初始dop生成的计划进行优化。在第一阶段考虑CPU资源、串行还是并发。在第二阶段考虑计划复杂程度。
(1)资源情况:CPU core:服务器CPU core 数量 / 服务器部署DN数量;串行/并发:可用CPU core * (1 – CPU usage)。
(2)查询复杂度:执行计划被stream算子拆分成多个片段,每个片段由一个线程执行。该计划中,有多少stream可以无阻塞的运行,决定了整个计划的最大并行线程数。采用特征匹配来识别查询复杂度。
![]()
以上内容从USTORE存储引擎、计划缓存计划技术、数据分区与分区剪枝、列式存储和向量化引擎、SMP并行执行等五方面对高性能关键技术进行了分享,下篇将从LLVM动态查询编译执行、SQL-BYPASS执行优化、线程池化、多核处理器优化、日志无锁刷新与多级流水等方面继续解读GaussDB高性能关键技术,并对高斯数据库性能优化进行总结,敬请期待!