我们很高兴在 TRL 中介绍 RLOO (REINFORCE Leave One-Out) 训练器。作为一种替代 PPO 的方法,RLOO 是一种新的在线 RLHF 训练算法,旨在使其更易于访问和实施。特别是, RLOO 需要的 GPU 内存更少,并且达到收敛所需的挂钟时间也更短 。如下面的图表所示:
🤑根据模型大小,RLOO 使用的 vRAM 比 PPO 少大约 50-70% ;
🚀对于 1B 参数模型,RLOO 的运行速度比 PPO 快 2 倍 ,对于 6.9B 参数模型,RLOO 的运行速度比 PPO 快 3 倍 。
🔥在响应胜率 (由 GPT4 判断) 方面,RLOO 与 PPO 相当 ,并且始终优于 DPO 等流行的离线方法。
通过 RLOO,我们将强化学习重新引入 RLHF,使社区能够更轻松地探索在线 RL 方法。这令人兴奋,因为越来越多的研究表明,在线 RL 比 DPO 等离线方法更有效 (
https://arxiv.org/abs/2402.04792
,
https://arxiv.org/abs/2405.08448
)。
这篇博客将解释 RLOO 训练器的背后的动机,它是如何工作的,以及如何在 TRL 中使用它。
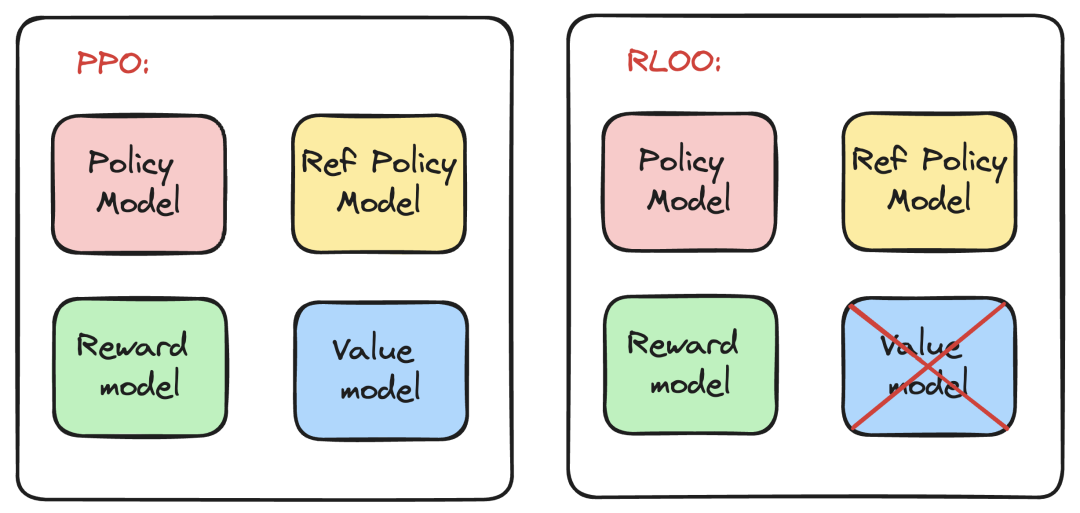
动机 PPO 是一种有效的在线 RLHF 训练算法,用于训练最先进的模型,如 GPT-4。然而,由于其对 GPU 内存的高要求,PPO 在实际使用中可能相当具有挑战性。特别是,PPO 需要将模型的 4 个副本加载到内存中: 1) 策略模型,2) 参考策略模型,3) 奖励模型,以及 4) 价值模型,如下面的图所示。PPO 还有许多微妙的实现细节,这些细节可能很难正确把握 (
Engstrom 等人; 2020
,
Huang 等人 2022
)。
Engstrom 等人; 2020
https://openreview.net/forum?id=r1etN1rtPB
Huang 等人 2022
https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
在 Cohere 的一篇新论文中,
Ahmadian 等人 (2024)
重新审视了 RLHF 训练的基础,并提出了一种更简洁的方法,称为 RLOO,这是一种新的在线训练算法。RLOO 只需要将模型的 3 个副本加载到内存中: 1) 策略模型,2) 参考策略模型,以及 3) 奖励模型,如上图所示。
Ahmadian 等人 (2024)
https://cohere.com/research/papers/back-to-basics-revisiting-reinforce-style-optimization-for-learning-from-human-feedback-in-llms-2024-02-23
重要的是,RLOO 需要更少的内存,这意味着它更容易:
在不出现 OOMs (内存不足错误) 的情况下运行
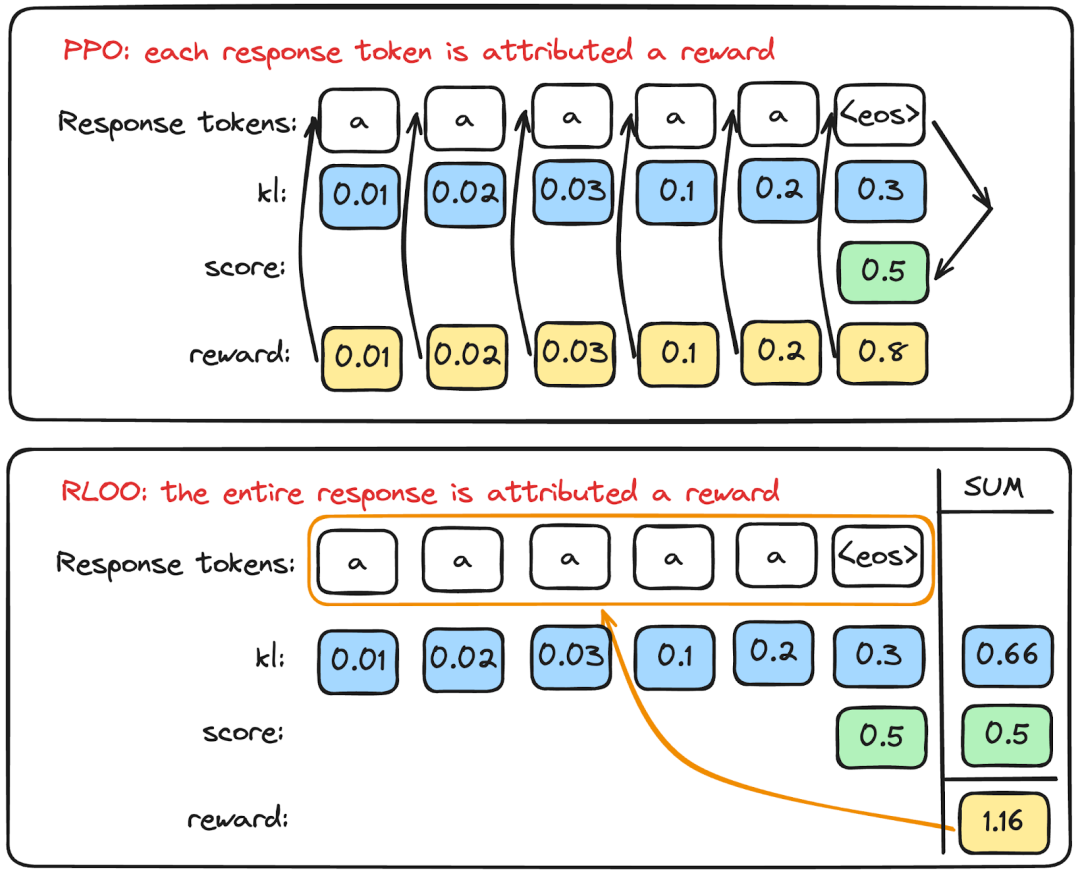
此外,RLOO 将整个补全 token 作为单一动作进行建模,如下图所示。在下一节中,我们将通过代码片段进一步详细介绍。
RLOO 是如何工作的 RLOO 和 PPO 有几个共同的步骤:
策略模型会生成一些补全 token ,并获取当前策略和参考策略下的每个 token 的对数概率。
然后我们计算每个 token 的 KL 惩罚,作为当前策略和参考策略下对数概率的差异。
从这里开始,常规的 PPO 和 RLOO 在方法上有所不同。RLOO 有几个关键想法。首先,它将 整个模型补全 视为单一动作,而常规 PPO 将 每个补全 token 视为单独的动作。通常,只有 EOS token 获得真正的奖励,这非常稀疏。常规 PPO 会将奖励归因于 EOS token,而 RLOO 会将 EOS 奖励归因于整个补全,如下所示。
from torch import Tensor4. , 5. , 6. ])-12.3 , -8.3 , -2.3 ])-11.3 , -8.4 , -2.0 ])1.0 f"{kl=} " ) # kl=tensor([-1.0000, 0.1000, -0.3000]) -1 ] += score_from_rm # assume last token is the EOS token f"{per_token_reward=} " ) # per_token_reward=tensor([-1.0000, 0.1000, 0.7000]) f"{score_from_rm=} " ) # score_from_rm=1.0 "#### Modeling each token as an action" )for action, reward in zip(response, per_token_reward):f"{action=} , {reward=} " )# action=tensor(4.), reward=tensor(-1.) # action=tensor(5.), reward=tensor(0.1000) # action=tensor(6.), reward=tensor(0.7000) "#### Modeling the entire response as an action" )f"action='entire completion', reward={entire_generation_reward} " )# action='entire completion', reward=-0.2000 (-1 + 0.1 + 0.7) 其次,RLOO 使用 REINFORCE 损失,它基本上将 (奖励 - 基线) 与动作的对数概率相乘。在这里,我们突出了每个 token 的 REINFORCE 损失与整个补全的 REINFORCE 损失之间的区别。请注意,对于 PPO 的损失,我们还需要基于价值模型和
广义优势估计 (GAE)
来计算优势。
广义优势估计 (GAE)
https://arxiv.org/abs/1506.02438
from torch import Tensor4. , 5. , 6. ])-12.3 , -8.3 , -2.3 ])-11.3 , -8.4 , -2.0 ])1.0 f"{kl=} " ) # kl=tensor([-1.0000, 0.1000, -0.3000]) -1 ] += score_from_rm # assume last token is the EOS token f"{per_token_reward=} " ) # per_token_reward=tensor([-1.0000, 0.1000, 0.7000]) f"{score_from_rm=} " ) # score_from_rm=1.0 "#### Modeling each token as an action" )for action, reward in zip(response, per_token_reward):f"{action=} , {reward=} " )# action=tensor(4.), reward=tensor(-1.) # action=tensor(5.), reward=tensor(0.1000) # action=tensor(6.), reward=tensor(0.7000) "#### Modeling the entire response as an action" )f"action='entire completion', reward={entire_generation_reward} " )# action='entire completion', reward=-0.2000 (-1 + 0.1 + 0.7) 0.2 , 0.3 , 0.4 ]) # dummy baseline "#### Modeling each token as an action" )f"{advantage=} " ) # advantage=tensor([-1.2000, -0.2000, 0.3000]) f"{per_token_reinforce_loss=} " ) # per_token_reinforce_loss=tensor([14.7600, 1.6600, -0.6900]) f"{per_token_reinforce_loss.mean()=} " ) # per_token_reinforce_loss.mean()=tensor(5.2433) "#### Modeling the entire response as an action" )f"{advantage=} " ) # advantage=tensor(-1.1000) f"{reinforce_loss=} " ) # reinforce_loss=tensor(25.1900) 第三,RLOO 聪明地计算基线。注意我们上面使用了一个虚拟基线。在实际操作中,RLOO 使用批次中所有其他样本的奖励作为基线。下面是一个有 3 个提示和每个提示 4 个补全的例子。我们通过平均同一提示的所有其他补全的奖励来计算每个补全的基线。
import torch3 4 1 , 2 , 3 , # first rlhf reward for three prompts 2 , 3 , 4 , # second rlhf reward for three prompts 5 , 6 , 7 , # third rlhf reward for three prompts 8 , 9 , 10 , # fourth rlhf reward for three prompts # here we have 3 prompts which have 4 completions each # slow impl 0 ) - rlhf_reward) / (rloo_k - 1 )for i in range(0 , len(advantages), local_batch_size):for j in range(0 , len(advantages), local_batch_size):if i != j:0 )assert (1 - (2 + 5 + 8 ) / 3 - advantages[0 ].item()) < 1e-6 assert (6 - (3 + 2 + 9 ) / 3 - advantages[7 ].item()) < 1e-6 # vectorized impl 0 ) - rlhf_reward) / (rloo_k - 1 )向 Arash Ahmadian 致谢,他提供了上述优势计算的向量化实现。
开始使用 TRL 的 RLOO 要开始使用 RLOO,你可以通过 pip install --upgrade trl 安装 TRL 的最新版本,并导入 RLOOTrainer。下面是一个展示一些高级 API 使用的简短代码片段。你可以随时查阅这些文档:
https://hf.co/docs/trl/main/en/rloo_trainer
https://hf.co/docs/trl/main/en/ppov2_trainer
from transformers import (from trl.trainer.rloo_trainer import RLOOConfig, RLOOTrainerfrom trl.trainer.utils import SIMPLE_QUERY_CHAT_TEMPLATE"EleutherAI/pythia-1b-deduped" "left" )"pad_token" : "[PAD]" })if tokenizer.chat_template is None :1 )# make sure to have columns "input_ids" 1 ,64 ,30000 ,这是一个跟踪权重和偏差实验的
例子
:
案例地址
https://wandb.ai/huggingface/trl/runs/dd2o3g35
在编写 RLOO 和 PPOv2 实现时,我们强调使模型开发的透明度更容易提升。特别是,我们已经增强了文档,包括对记录指标的解释以及阅读和调试这些指标的操作指南。例如,我们建议在训练期间密切监控 objective/rlhf_reward,这是 RLHF 训练的最终目标。
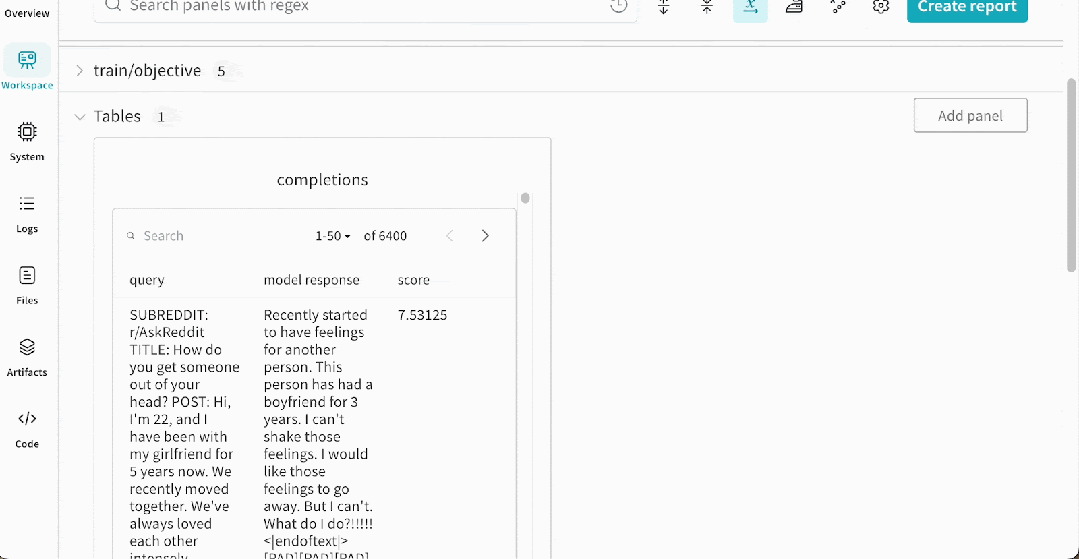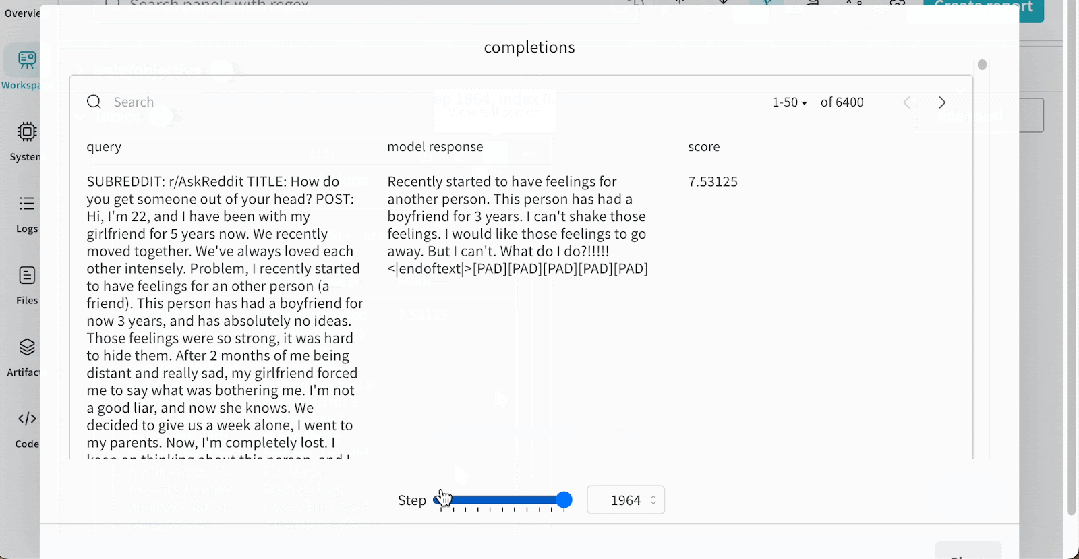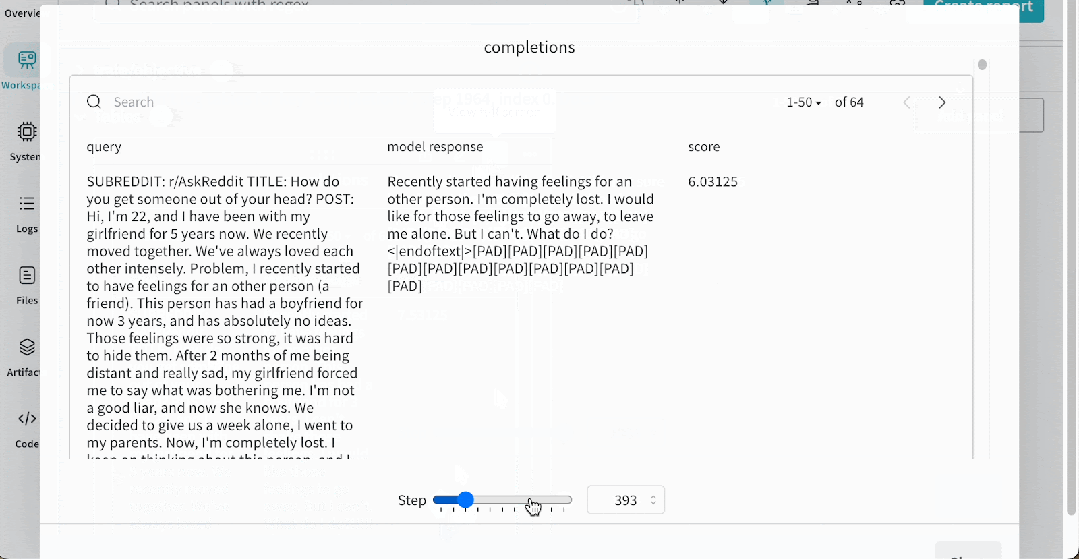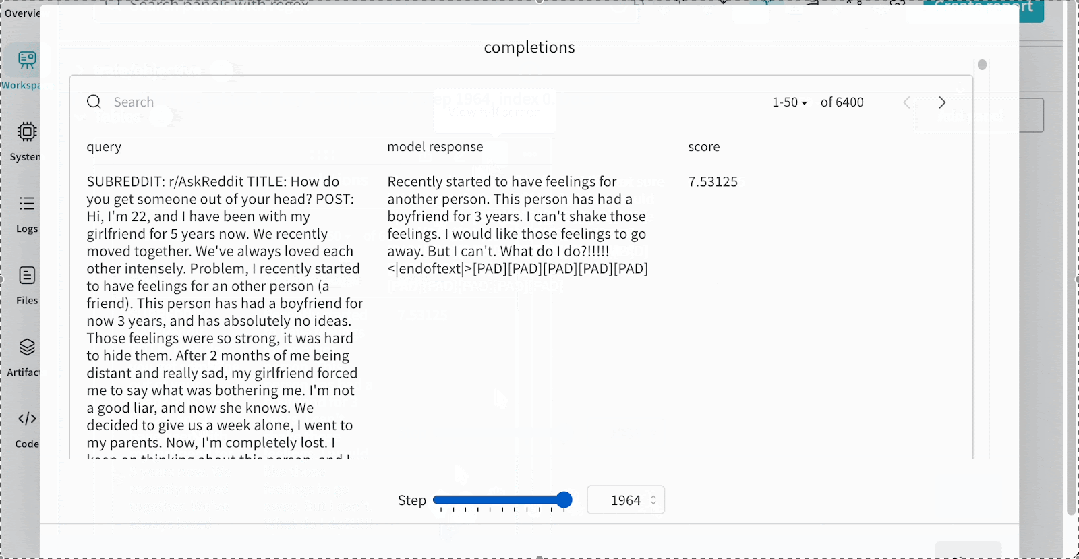
为了帮助可视化训练进度,我们定期记录模型的一些示例补全。这里是一个补全的例子。在一个权重和偏差跟踪运行的
示例
中,它看起来像下面这样,允许你看到模型在不同训练阶段的响应。默认情况下,我们在训练期间生成 –num_sample_generations 10,但你可以自定义生成的数量。
示例地址
https://wandb.ai/huggingface/trl/runs/dd2o3g35
我们如何在 TRL 中实现 RLOO 训练器 我们基于新的实验性 PPOv2Trainer 实现了 RLOO 训练器,后者又是基于 https://arxiv.org/abs/2403.17031。有趣的是,我们实现的 RLOO 训练器仍然使用 PPO 损失。这是因为 REINFORCE 的损失是 PPO 的一个特例 (https://arxiv.org/abs/2205.09123)。请注意,即使对数概率明确出现在 REINFORCE 损失中,它也隐含在 PPO 损失中。眼见为实,所以让我们用一个简单的例子来证明这一点。
import torch.nn.functional as Ffrom torch import LongTensor, Tensor, gather, no_grad1 ])1.0 ])1.0 , 2.0 , 1.0 , 1.0 ]])True -1 )with no_grad():1 , action.unsqueeze(-1 )).squeeze(-1 )1 , action.unsqueeze(-1 )).squeeze(-1 )# [πθ(at | st) / πθ_old(at | st)* At] # when the πθ and πθ_old are the same, the ratio is 1, and PPO's clipping has no effect f"{logits.grad=} " ) # tensor([[-0.1749, 0.5246, -0.1749, -0.1749]]) 1.0 , 2.0 , 1.0 , 1.0 ]])True -1 )1 , action.unsqueeze(-1 )).squeeze(-1 )# [log πθ(at | st)* At] f"{logits2.grad=} " ) # tensor([[-0.1749, 0.5246, -0.1749, -0.1749]]) 实验 为了验证 RLOO 实现的有效性,我们在 Pythia 1B 和 6.9B 模型上进行了实验,并在这里发布了训练后的
检查点
:
检查点链接
https://hf.co/collections/vwxyzjn/rloo-ppov2-tl-dr-summarize-checkpoints-66679a3bfd95ddf66c97420d
我们从
Huang 等人,2024
直接获取 SFT / RM 模型。为了评估,我们使用 vLLM 加载检查点,并使用 GPT4 作为评判模型来评估生成的 TL;DR 与参考 TL;DR 的对比。我们还查看了 GPU 内存使用情况和运行时间,正如博客开头所示的图表。要重现我们的工作,请随时查看我们文档中的命令:
Huang 等人,2024
https://arxiv.org/abs/2403.17031
https://hf.co/docs/trl/main/en/rloo_trainer#benchmark-experiments
https://hf.co/docs/trl/main/en/rloo_trainer#benchmark-experiments
关键结果如下:
🚀高性能 RLOO 检查点 : 使用 GPT4 作为评判模型,6.9B 检查点获得了 78.7% (k=2) 的偏好率,这甚至超过了原始
论文
中报告的最佳性能 77.9% (k=4) 和 74.2 (k=2)。这是一个很好的迹象,表明我们的 RLOO 训练按预期工作。
论文地址
https://arxiv.org/abs/2402.14740
RLOO 1B 检查点的胜率为 40.1%,而 SFT 检查点的胜率为 21.3%。这是一个很好的迹象,表明 RLOO 训练按预期工作。
🤑 减少 GPU 内存并运行更快 : RLOO 训练使用更少的内存并运行更快,使其成为在线 RL 训练中非常有用的算法。
数值稳定性: 黑暗面 尽管 RLOO 在性能和计算效率方面有优势,但我们想要强调一些数值问题。具体来说,生成过程中获得的响应对数概率与 bf16 下训练前向传递期间获得的对数概率在数值上略有不同。这给 PPO 和 RLOO 都带来了问题,但对于 RLOO 来说,问题更严重,如下所述。
例如,假设我们正在为两个序列生成 10 个 token。在 fp32 精度下,输出如下所示,其中 ratio = (forward_logprob - generation_logprob).exp() ,这是 PPO 用来裁剪的。在第一个周期和第一个小批量中,比率应该是完全相同的,因为模型还没有进行任何更新:
generation_logprob=tensor([[ -0.1527, -0.2258, -3.5535, -3.4805, -0.0519,'cuda:0' )'cuda:0' , grad_fn=<SqueezeBackward1>)'cuda:0' , grad_fn=<ExpBackward0>)然而,在 bf16 精度下,我们得到结果:
generation_logprob=tensor([[ -0.1426, -0.1904, -3.5938, -3.4688, -0.0618,'cuda:0' , dtype=torch.bfloat16)'cuda:0' , dtype=torch.bfloat16,'cuda:0' , dtype=torch.bfloat16, grad_fn=<ExpBackward0>)和在 fp16 精度下,我们得到的结果
generation_logprob=tensor([[ -0.1486, -0.2212, -3.5586, -3.4688, -0.0526,'cuda:0' , dtype=torch.float16)'cuda:0' , dtype=torch.float16,'cuda:0' , dtype=torch.float16, grad_fn=<ExpBackward0>)请注意, bf16 的比率由于某种原因非常不稳定。当比率变得很大时,PPO 的裁剪系数 = 0.2 开始发挥作用, 取消 那些比率大于 1.2 或小于 0.8 的 token 的梯度。对于 RLOO,这个问题更为极端,因为我们看到的是 (forward_logprob.sum(1) - generation_logprob.sum(1)).exp() = [ 1.0625, 12.1875] ,这意味着整个第二个序列的梯度被取消了。
在实际操作中,我们注意到 PPO 取消了大约 3% 的批次数据的梯度,而 RLOO 取消了大约 20-40% 的批次数据。从理论上讲,当不使用小批量时,RLOO 应该取消 0 %的批次数据。重要的是,我们观察到,一旦我们增加了在生成新批次之前的梯度步骤数 (通过 num_ppo_epochs 和 num_mini_batches),RLOO 的裁剪比率并没有显著变化; 这提供了实证证据,表明裁剪比率确实是由于 bf16 的数值问题,而不是因为行为和最新策略有很大不同,正如论文中所定位的。
要了解有关最新问题更新的更多信息,请查看
GitHub issue: #31267
。
Issue #31267 链接
https://github.com/huggingface/transformers/issues/31267
结论 TRL 中引入的 RLOO (REINFORCE Leave One-Out) 训练器是在线 RLHF 训练中一个令人兴奋的算法,它提供了一个比 PPO 更易访问和高效的替代方案。通过减少 GPU 内存使用和简化训练过程,RLOO 使得可以使用更大的批量大小和更快的训练时间。我们的实验表明,RLOO 在响应胜率方面与 PPO 竞争,并且优于 DPO 检查点,使其成为有效的在线 RLHF 的有力工具。查看我们的文档来开始使用吧!
https://hf.co/docs/trl/main/en/rloo_trainer
https://hf.co/docs/trl/main/en/ppov2_trainer
致谢和感谢 我们要感谢 Lewis Tunstall, Sara Hooker, Omar Sanseviero 和 Leandro Von Werra 对这篇博客提供的宝贵反馈。
原文链接: https://hf.co/blog/putting_rl_back_in_rlhf_with_rloo
原文作者: Shengyi Costa Huang, Arash Ahmadian
译者: innovation64