MySQL 级联复制的坑,我帮你们踩了。
作者:蒋士峰,爱可生 DBA 团队成员,熟悉 MySQL,Oracle 等数据库。每天的积累,时间久了,会带来不一样的收货。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1200 字,预计阅读需要 3 分钟。
业务场景
在日常运维的某个系统下,由于之前数据库主机所用硬盘是传统机械硬盘,容量小,传输速度低,并且数据库服务器整体性能不高。随着业务访问量的增加,现有数据库服务器无法满足需求,所以需要搭建一套高性能的数据库服务器,并且所用硬盘是 SSD。
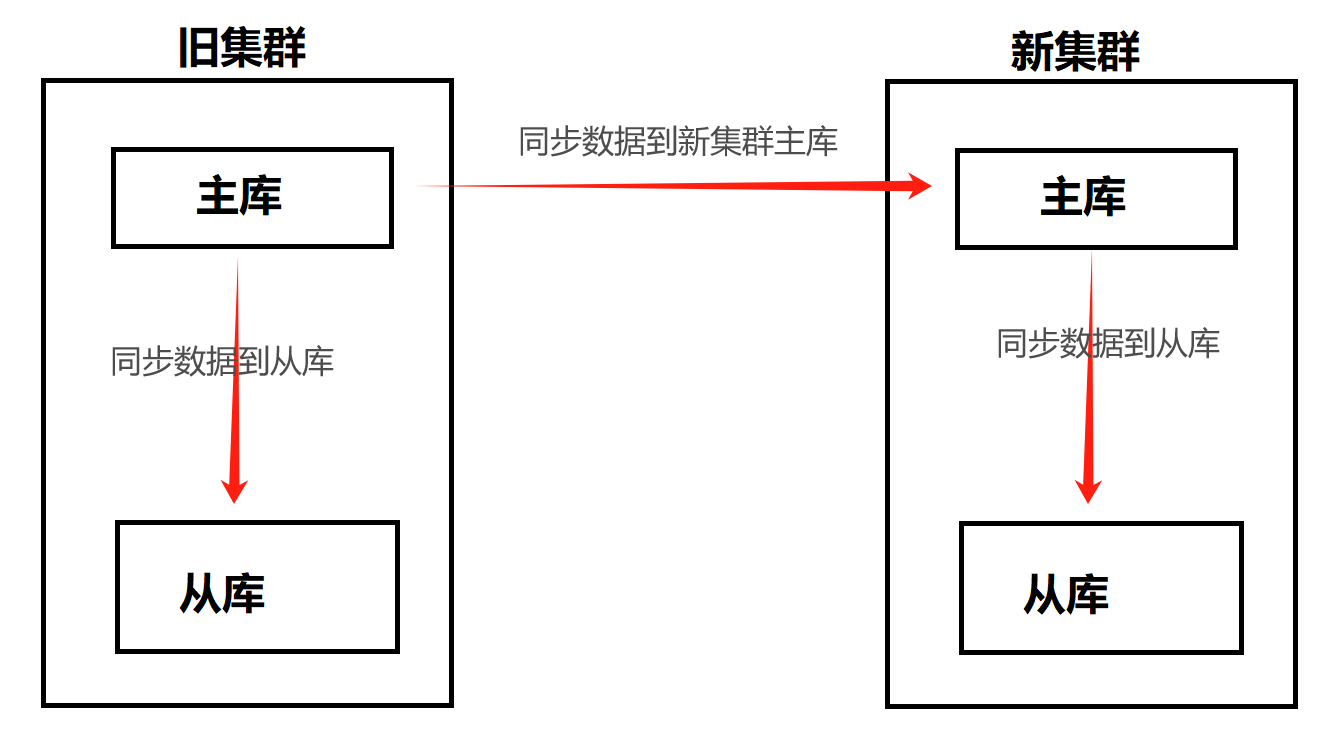
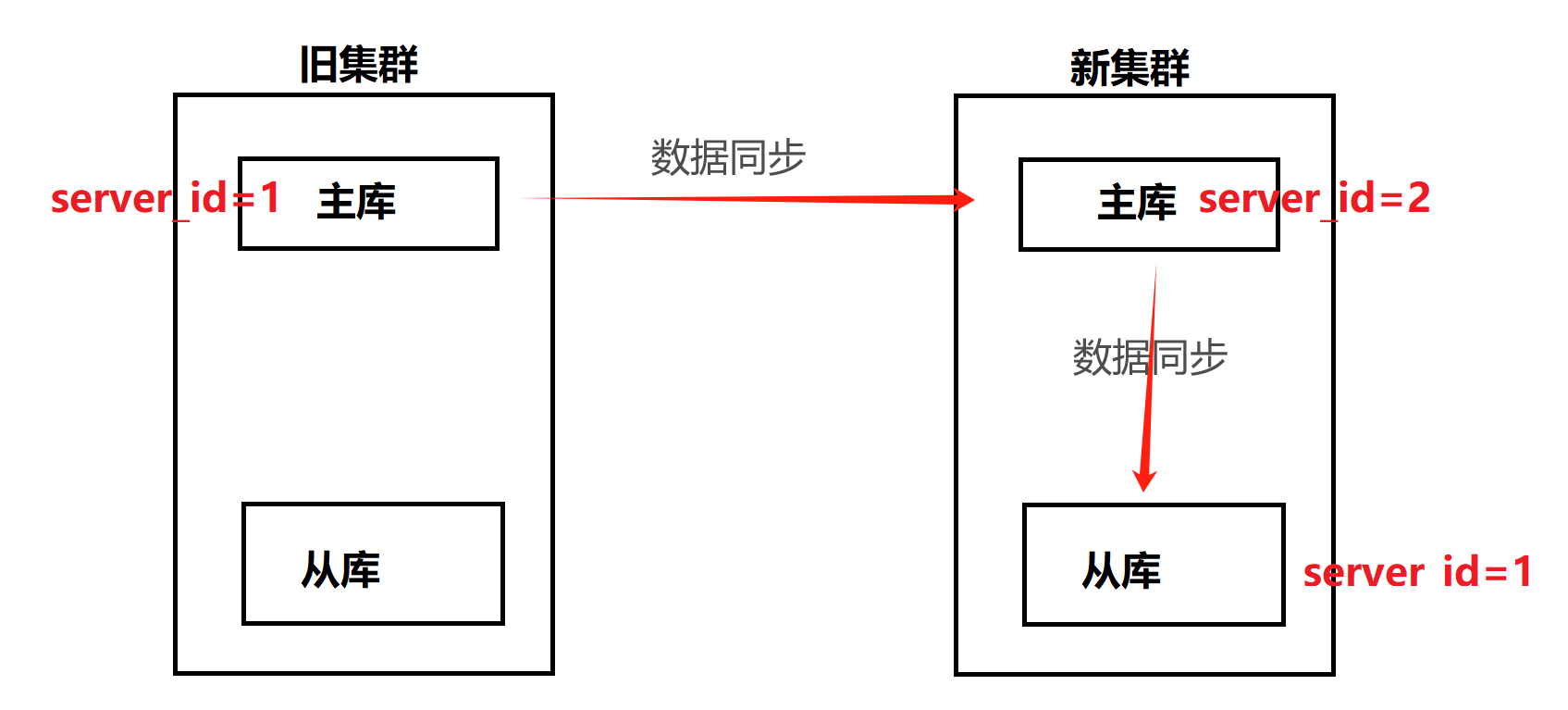
由于原先数据库采用的是主从复制架构,所以新搭建的数据库也要采用主从架构。跟旧数据库集群组成一套级联复制的 MySQL 数据库集群(旧集群的主库作为主,新集群的主库为旧集群主库的从,新集群从库还继续为新集群主库的从),先进行数据同步一段时间,再找时间点进行业务割接。
由此从 旧集群主库--->新集群主库--->新集群从库 之前形成了一条类似于链条式的同步关系,具体关系图如下:
![]()
问题的发现
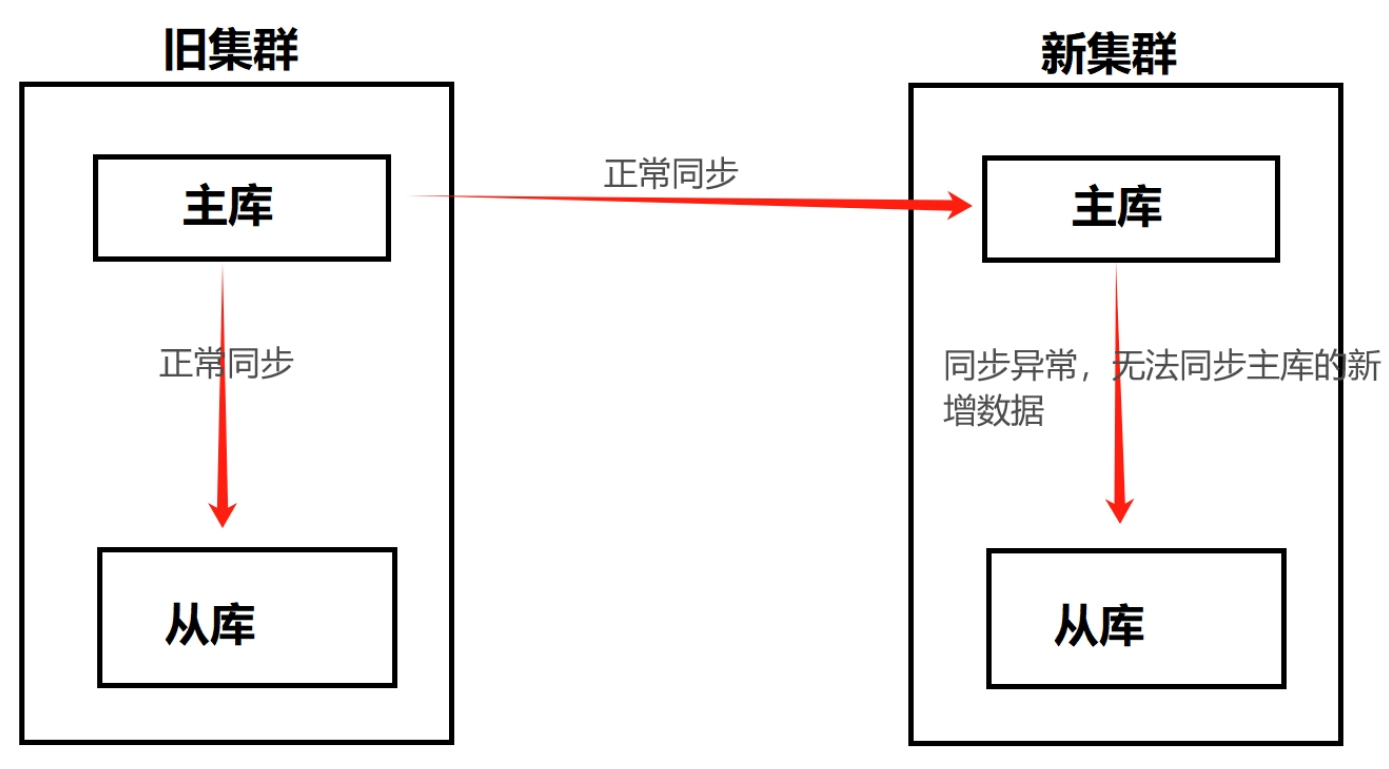
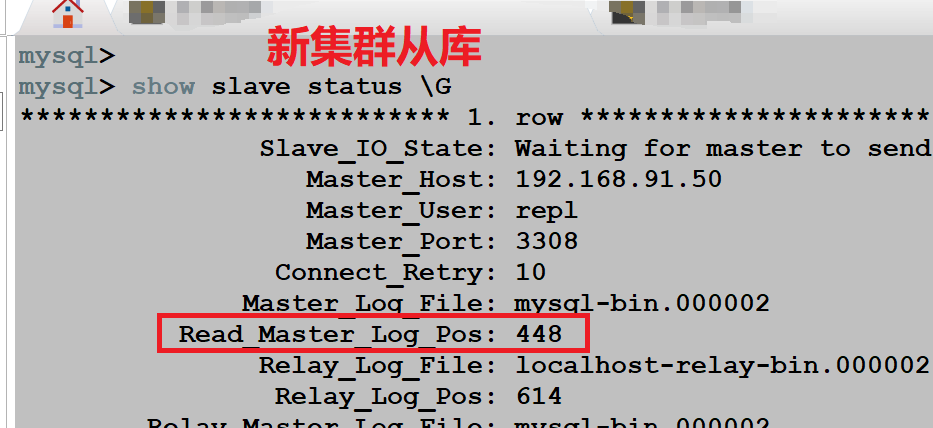
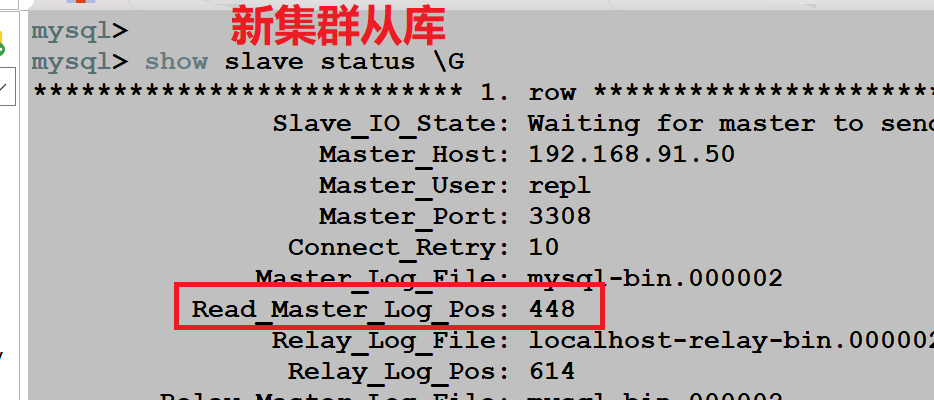
搭建完成新集群,做级联复制的时候,没有发现任何错误,数据同步也是正常的。大概过了 15 天进行数据比对的时候,发现了一个重要问题:新集群的主库可以正常同步旧集群主库的新增数据,但是新集群的从库无法同步新集群主库的新增数据。
如图所示:
![]()
问题分析
-
由于从新集群的主库到新集群从库无法正常同步,所以我们先分析了新集群主库的 binlog 日志是否开启,还有 log_slave_update 是否也开启了,只有开启了,才能产生 binlog 做主从同步。发现都是开启的,所以只能从其他方面去看。
-
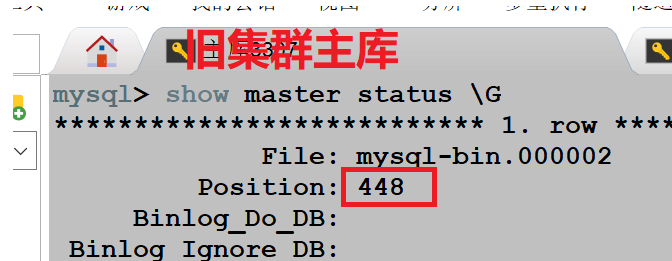
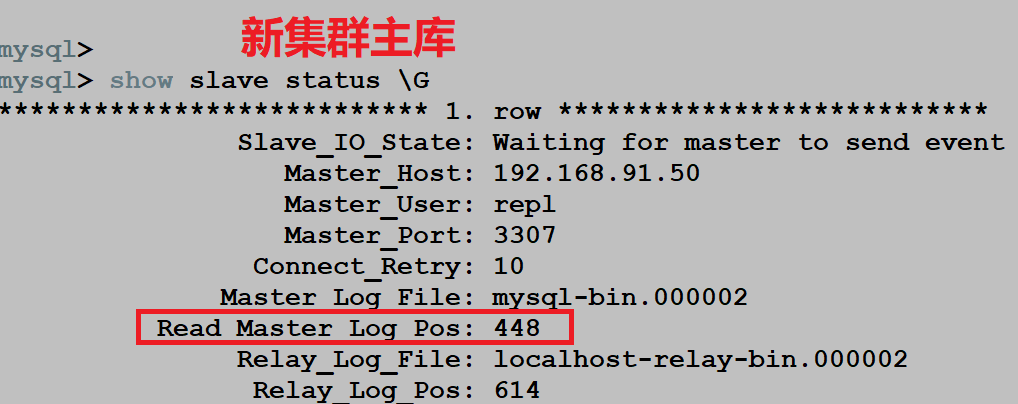
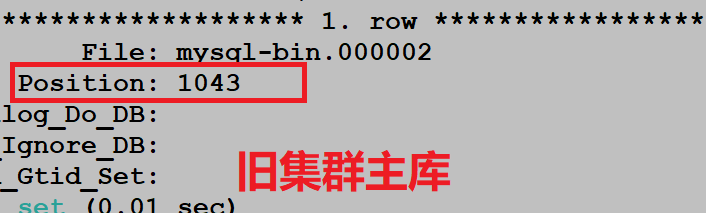
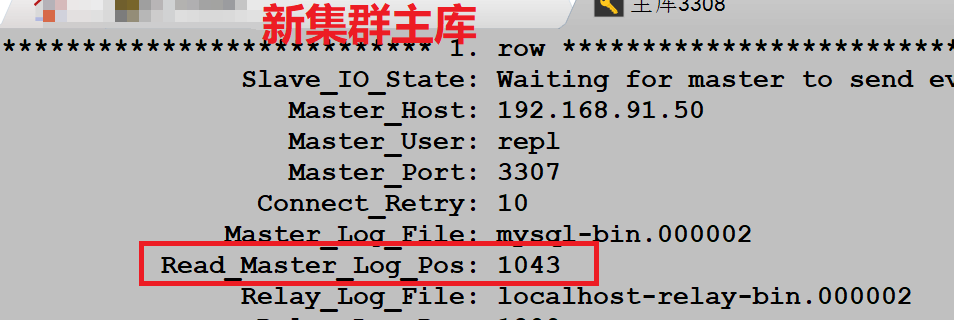
除此之外,我们还专门在旧集群主库上进行了创建库,插入数据操作,观察 positon 位置点的变化信息。
创建库,插入数据之前:
![]()
![]()
![]()
创建库,插入数据之后:
![]()
![]()
![]()
重要问题:发现插入数据的时候,旧集群主库和新集群主库的 binlog 位置点都发生了变化,只有新集群的从库的 binlog 位置点一直没变,这明显是不正常的。
-
前面也确认了 binlog 相关参数都是开启的。所以此时,我们只有把三台数据库的配置文件 my.cnf 拿出来对比一下了,检查一下是不是配置文件的相关参数出了问题。
经过对比确认参数,发现了一个主要的问题:旧集群的主库的 server_id 为 1,新集群的主库的 server_id 为 2,新集群的从库的 server_id 为 1。
这意味着什么?旧集群主库的 server_id 与新集群从库的 server_id 重复了。但是问题又来了,当时做主从的时候完全没有报错啊。那么,级联复制中,是不是也要保证所有的 server_id 不同呢?
![]()
- 带着这个疑问,我们专门在本地环境搭建了一套类似于生产环境的级联复制,并且随意改动
server_id,然后插入数据,观察一下数据同步情况。验证了一条重要信息:级联复制中,所有参与构建集群的 MySQL 数据库 server_id 不能相同,一旦相同,数据同步就会出现故障。
产生这一问题的根源
在项目中,数据集群众多,手动安装工作量较大,所以本次安装数据库也是采用自动化安装的,分配 server_id 的时候,也是 1 或者 2 随机分配。所以才导致了本次新集群从库 server_id 跟旧集群冲突了。
整改步骤
数据已经同步了 15 天了,但是我们的 binlog 只保存了 14 天,所以现在只有先修改一下 server_id,保证该级联复制中所有数据库的 server_id 都是不同的;然后再备份一下旧集群主库,恢复到新集群,重做级联复制。
带来的启示
- 使用级联复制,一定要保证所有参与数据库的
server_id 不同。
- 要确 binlog 日志以及相关参数是开启的。
- 由于级联复制存在各种小问题,所以日常生产中尽量少用级联复制。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
SQLE 获取