![]()
备受关注的 Milvus 2.4 正式上线!
作为向量数据库赛道的领军者,Zilliz 一直致力于推动向量技术的进步与创新。本次发布中,Milvus 新增支持基于 NVIDIA 的 GPU 索引—— CUDA 加速图形索引(CAGRA),突破了现有向量搜索的能力。
GPU 索引是向量数据库技术中的重要里程碑,其速度和性能远超传统的 CPU 索引(如 HNSW)。Zilliz 继 2023 年新增 GPU IVF-Flat 和 GPU IVF-PQ 索引后,又在 Milvus 2.4 版本中进一步增强了 GPU 索引能力。而众所周知,向量搜索速度对于 RAG 应用至关重要。Milvus 2.4 发布后,可以轻松助力用户生成式 AI 应用的开发。
不止如此,Milvus 2.4 还支持多向量检索、Grouping 搜索功能、稀疏向量等。为了方便大家了解新版本,3 月 26 日(周二)晚 8 点,Zilliz 产品经理张粲宇将为大家在直播间详细拆解 Milvus 2.4 的关键特性及答疑解惑。
以下是 Milvus 2.4 的几个重要更新:
🚀支持 CAGRA 索引
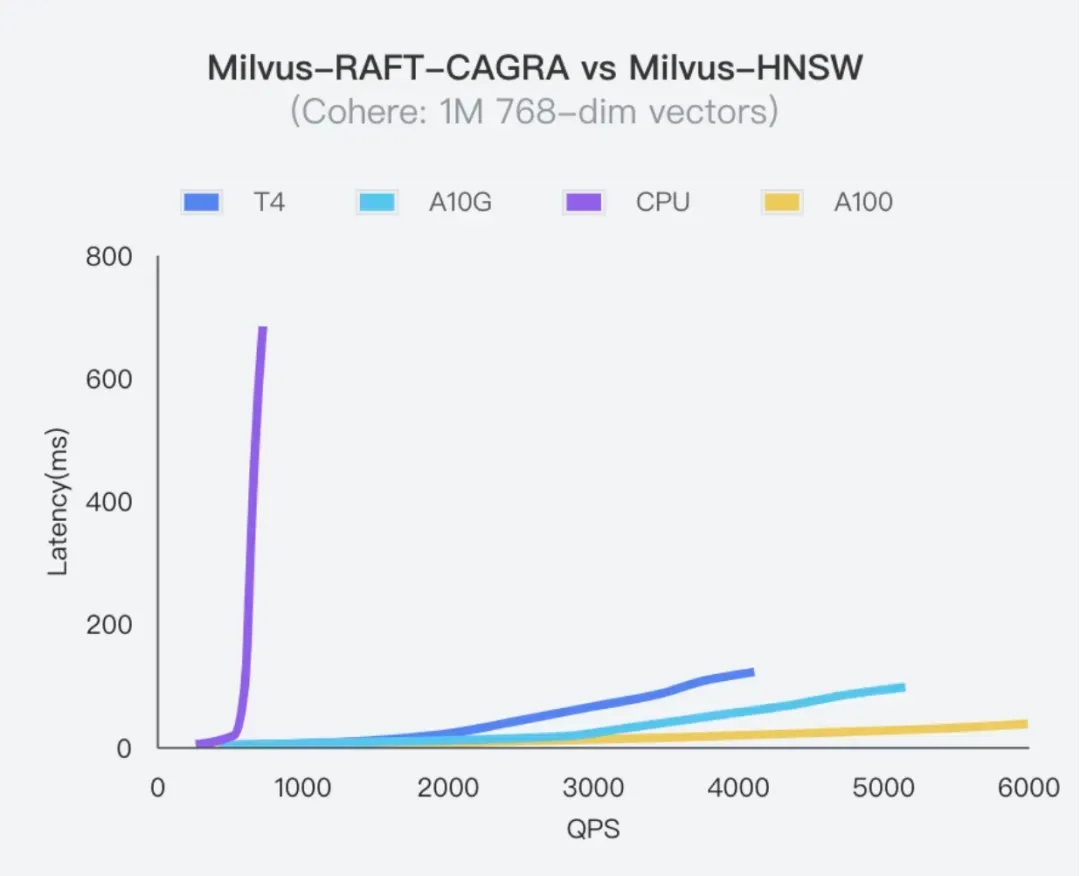
Milvus 2.4 新增支持 CAGRA 索引,我们要衷心感谢 NVIDIA 团队对 CAGRA 的宝贵贡献,CAGRA 是 NVIDIA RAFT 库中最先进的基于图形处理器的图形索引。与以前只在大批量下获得性能优势的图形处理器索引不同,CAGRA 即使在小批量查询中也表现出压倒性的优势,虽然这是 CPU 索引传统上擅长的领域。此外,CAGRA 在大批量查询和索引构建速度方面的性能确实是无与伦比的。除了 CAGRA,该版本 Milvus 还支持了 GPU 暴搜,性能有数十倍提升,进一步满足需要高召回率的场景。
![]()
🔍支持多向量搜索
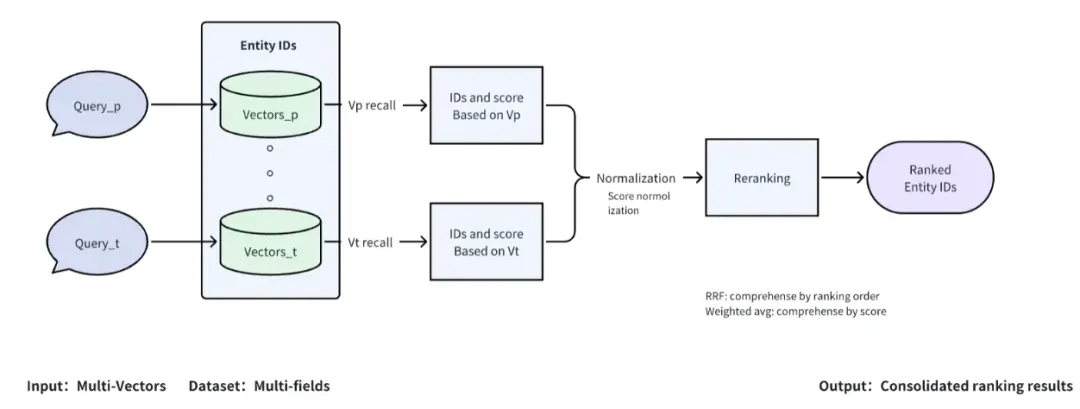
Milvus 2.4 支持多向量搜索,进一步为 AI 应用开发赋能。多向量搜索能力能够有效简化处理多模态搜索的流程,并提升检索召回率。Milvus 2.4 支持在 Collection 中存储和搜索多个向量列,从而满足用户在实际应用场景中的需求。
此外,该特性还简化了整合、优化自定义重排模型的流程,支持开发高级搜索功能,如利用多维度数据输入来做综合搜索的系统。
![]()
🧮Grouping 搜索
Milvus 2.4 的新增支持 Grouping 搜索功能,使得用户可以在搜索 vector 的基础上做分组聚合,返回的 TopK 是基于分组后的聚合结果而非简单的以向量为中心的片段信息。用户现在可以按特定标量字段中的值聚合搜索结果,这有助于RAG 应用程序实现文档级召回。考虑一个文档集合,每个文档拆分成各种段落。每个段落由一个向量嵌入表示,属于一个文档。要查找最相关的文档而不是分散段落,可以在 search() 操作中包含 group_by_field 参数,以按文档 ID 对结果进行分组。
![]()
🔮支持稀疏向量(beta)
Milvus 2.4 还支持稀疏向量。这一特性专为由 SPLADEv2 等神经模型和 BM25 等统计模型生成的向量设计,通过专注于语义相似性,在传统关键词搜索基础之上,进一步增强了语义搜索能力。具体而言,对稀疏向量的支持,进一步增强了 Milvus 的混合搜索能力——即将关键词搜索和向量搜索相结合,最终提高搜索准确性。当前该功能还处于内测阶段中。
➡️倒排索引和模糊匹配支持
在 Milvus 以前的版本中,基于内存的二进制搜索索引和 Marisa Trie 索引用于标量字段索引。然而,这些方法是内存密集型的。Milvus 2.4 采用了基于 Tantivy 的倒排索引,它可以应用于所有数字和字符串数据类型。这个新索引显著提高了标量查询性能,将字符串中关键字的查询减少了十倍。此版本还支持模糊匹配标量过滤使用前缀,中缀和后缀。
✨内存映射存储
Milvus 使用内存映射存储(MMap)来优化其内存使用。这种机制不是将文件内容直接加载到内存中,而是将文件内容映射到内存中。这种方法带来了性能下降的权衡。通过在具有 2 个 CPU 和 8 GB RAM 的主机上为 HNSW 索引集合启用 MMap,您可以加载 4 倍以上的数据,性能下降不到 10%。此外,此版本还允许对 MMap 进行动态和细粒度的控制,而无需重新启动 Milvus。
⬆️ 其他优化
Milvus 2.4 还包含其他新特性及功能优化,包括在元数据过滤中支持使用正则表达式对子字符串进行匹配、全新的标量倒排索引(由 Tantivy 贡献)以及用于检测并同步 Milvus Collection 中数据变化的 Change Data Capture 工具。所有上述新特性及功能优化都致力于提升 Milvus 性能和功能,帮助 Milvus 轻松应对更复杂的数据操作。
扫码预约直播,了解更多关于 Milvus 2.4 的细节:
![]()
阅读原文
- 如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。
- 欢迎关注微信公众号“Zilliz”,了解最新资讯。