model = CrossEncoder('cross-encoder/ms-marco-TinyBERT-L-2-v2', max_length=512) scores = model.predict([('How many people live in Berlin?', 'Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.'), ('How many people live in Berlin?', 'Berlin is well known for its museums.')]) scores
model = CrossEncoder('cross-encoder/stsb-TinyBERT-L-4') scores = model.predict([("The weather today is beautiful", "It's raining!"), ("The weather today is beautiful", "Today is a sunny day")]) scores
{'doi': '1910.01108', 'chunk-id': '0', 'chunk': 'DistilBERT, a distilled version of BERT: smaller,\nfaster, cheaper and lighter\nVictor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF\nHugging Face\n{victor,lysandre,julien,thomas}@huggingface.co\nAbstract\nAs Transfer Learning from large-scale pre-trained models becomes more prevalent\nin Natural Language Processing (NLP), operating these large models in on-theedge and/or under constrained computational training or inference budgets remains\nchallenging. In this work, we propose a method to pre-train a smaller generalpurpose language representation model, called DistilBERT, which can then be finetuned with good performances on a wide range of tasks like its larger counterparts.\nWhile most prior work investigated the use of distillation for building task-specific\nmodels, we leverage knowledge distillation during the pre-training phase and show\nthat it is possible to reduce the size of a BERT model by 40%, while retaining 97%\nof its language understanding capabilities and being 60% faster. To leverage the\ninductive biases learned by larger models during pre-training, we introduce a triple\nloss combining language modeling, distillation and cosine-distance losses. Our\nsmaller, faster and lighter model is cheaper to pre-train and we demonstrate its', 'id': '1910.01108', 'title': 'DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter', 'summary': 'As Transfer Learning from large-scale pre-trained models becomes more\nprevalent in Natural Language Processing (NLP), operating these large models in\non-the-edge and/or under constrained computational training or inference\nbudgets remains challenging. In this work, we propose a method to pre-train a\nsmaller general-purpose language representation model, called DistilBERT, which\ncan then be fine-tuned with good performances on a wide range of tasks like its\nlarger counterparts. While most prior work investigated the use of distillation\nfor building task-specific models, we leverage knowledge distillation during\nthe pre-training phase and show that it is possible to reduce the size of a\nBERT model by 40%, while retaining 97% of its language understanding\ncapabilities and being 60% faster. To leverage the inductive biases learned by\nlarger models during pre-training, we introduce a triple loss combining\nlanguage modeling, distillation and cosine-distance losses. Our smaller, faster\nand lighter model is cheaper to pre-train and we demonstrate its capabilities\nfor on-device computations in a proof-of-concept experiment and a comparative\non-device study.', 'source': 'http://arxiv.org/pdf/1910.01108', 'authors': ['Victor Sanh', 'Lysandre Debut', 'Julien Chaumond', 'Thomas Wolf'], 'categories': ['cs.CL'], 'comment': 'February 2020 - Revision: fix bug in evaluation metrics, updated\n metrics, argumentation unchanged. 5 pages, 1 figure, 4 tables. Accepted at\n the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing\n - NeurIPS 2019', 'journal_ref': None, 'primary_category': 'cs.CL', 'published': '20191002', 'updated': '20200301', 'references': [{'id': '1910.01108'}]}
#Let's store the IDs for later retrieval_corpus_ids = [hit['corpus_id'] for hit in hits]
# Now let's print the top 3 results for i, hit in enumerate(hits[:3]): sample = dataset["train"][hit["corpus_id"]] print(f"Top {i+1} passage with score {hit['score']} from {sample['source']}:") print(sample["chunk"]) print("\n")
Top 1 passage with score 0.6097552180290222 from http://arxiv.org/pdf/2204.05862: learning from human feedback, which we improve on a roughly weekly cadence. See Section 2.3. 4This means that our helpfulness dataset goes ‘up’ in desirability during the conversation, while our harmlessness dataset goes ‘down’ in desirability. We chose the latter to thoroughly explore bad behavior, but it is likely not ideal for teaching good behavior. We believe this difference in our data distributions creates subtle problems for RLHF, and suggest that others who want to use RLHF to train safer models consider the analysis in Section 4.4. 5 1071081091010 Number of Parameters0.20.30.40.50.6Mean Eval Acc Mean Zero-Shot Accuracy Plain Language Model RLHF 1071081091010 Number of Parameters0.20.30.40.50.60.7Mean Eval Acc Mean Few-Shot Accuracy Plain Language Model RLHFFigure 3 RLHF model performance on zero-shot and few-shot NLP tasks. For each model size, we plot the mean accuracy on MMMLU, Lambada, HellaSwag, OpenBookQA, ARC-Easy, ARC-Challenge, and TriviaQA. On zero-shot tasks, RLHF training for helpfulness and harmlessness hurts performance for small
Top 2 passage with score 0.5659530162811279 from http://arxiv.org/pdf/2302.07842: preferences and values which are difficult to capture by hard- coded reward functions. RLHF works by using a pre-trained LM to generate text, which i s then evaluated by humans by, for example, ranking two model generations for the same prompt. This data is then collected to learn a reward model that predicts a scalar reward given any generated text. The r eward captures human preferences when judging model output. Finally, the LM is optimized against s uch reward model using RL policy gradient algorithms like PPO ( Schulman et al. ,2017). RLHF can be applied directly on top of a general-purpose LM pre-trained via self-supervised learning. However, for mo re complex tasks, the model’s generations may not be good enough. In such cases, RLHF is typically applied afte r an initial supervised fine-tuning phase using a small number of expert demonstrations for the correspondi ng downstream task ( Ramamurthy et al. ,2022; Ouyang et al. ,2022;Stiennon et al. ,2020). A successful example of RLHF used to teach a LM to use an extern al tool stems from WebGPT Nakano et al. (2021) (discussed in 3.2.3), a model capable of answering questions using a search engine and providing
Top 3 passage with score 0.5590510368347168 from http://arxiv.org/pdf/2307.09288: 31 5 Discussion Here, we discuss the interesting properties we have observed with RLHF (Section 5.1). We then discuss the limitations of L/l.sc/a.sc/m.sc/a.sc /two.taboldstyle-C/h.sc/a.sc/t.sc (Section 5.2). Lastly, we present our strategy for responsibly releasing these models (Section 5.3). 5.1 Learnings and Observations Our tuning process revealed several interesting results, such as L/l.sc/a.sc/m.sc/a.sc /two.taboldstyle-C/h.sc/a.sc/t.sc ’s abilities to temporally organize its knowledge, or to call APIs for external tools. SFT (Mix) SFT (Annotation) RLHF (V1) 0.0 0.2 0.4 0.6 0.8 1.0 Reward Model ScoreRLHF (V2) Figure 20: Distribution shift for progressive versions of L/l.sc/a.sc/m.sc/a.sc /two.taboldstyle-C/h.sc/a.sc/t.sc , from SFT models towards RLHF. Beyond Human Supervision. At the outset of the project, many among us expressed a preference for
好极了!我们根据最高召回但低精度的双向编码器得到了最相似的切块。
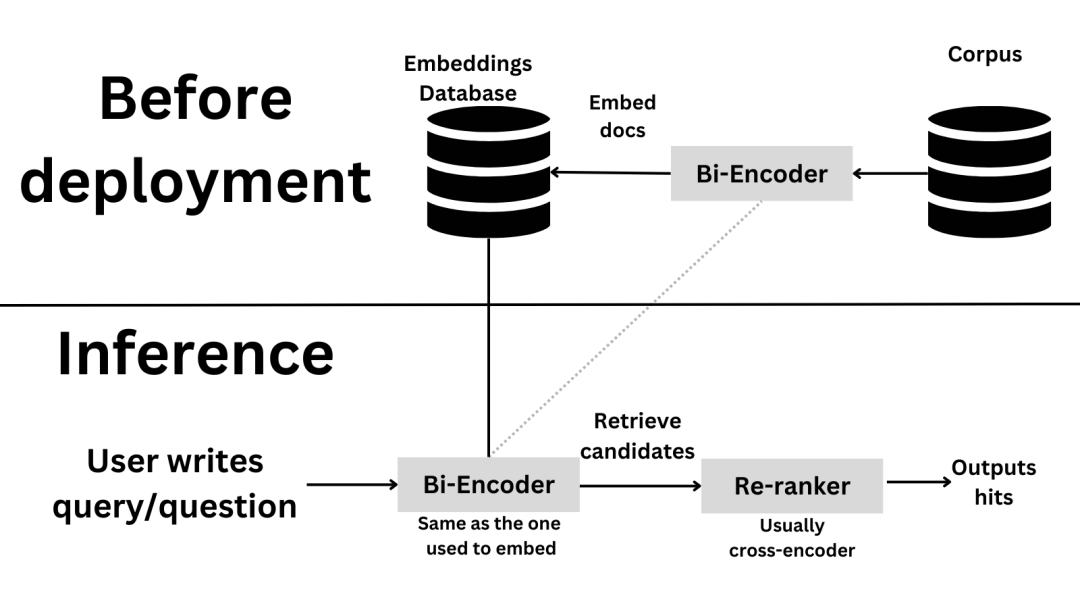
现在,让我们通过高精度的交叉编码器模型重排序。我们将使用 cross-encoder/ms-marco-MiniLM-L-6-v2 模型。这个模型是在 MS MARCO 数据集上微调的,它是一个大型真实问答信息检索数据集。这使得这个模型在进行问答时非常适合决策。
for idx in range(len(cross_scores)): hits[idx]['cross-score'] = cross_scores[idx] hits = sorted(hits, key=lambda x: x['cross-score'], reverse=True) msmarco_l6_corpus_ids = [hit['corpus_id'] for hit in hits] # save for later
for i, hit in enumerate(hits[:3]): sample = dataset["train"][hit["corpus_id"]] print(f"Top {i+1} passage with score {hit['cross-score']} from {sample['source']}:") print(sample["chunk"]) print("\n")
Top 1 passage with score 0.9668010473251343 from http://arxiv.org/pdf/2204.05862: Stackoverflow Good Answer vs. Bad Answer Loss Difference Python FT Python FT + RLHF(b)Difference in mean log-prob between good and bad answers to Stack Overflow questions. Figure 37 Analysis of RLHF on language modeling for good and bad Stack Overflow answers, over many model sizes, ranging from 13M to 52B parameters. Compared to the baseline model (a pre-trained LM finetuned on Python code), the RLHF model is more capable of distinguishing quality (right) , but is worse at language modeling (left) . the RLHF models obtain worse loss. This is most likely due to optimizing a different objective rather than pure language modeling. B.8 Further Analysis of RLHF on Code-Model Snapshots As discussed in Section 5.3, RLHF improves performance of base code models on code evals. In this appendix, we compare that with simply prompting the base code model with a sample of prompts designed to elicit helpfulness, harmlessness, and honesty, which we refer to as ‘HHH’ prompts. In particular, they contain a couple of coding examples. Below is a description of what this prompt looks like: Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful,
Top 2 passage with score 0.9574587345123291 from http://arxiv.org/pdf/2302.07459: We examine the influence of the amount of RLHF training for two reasons. First, RLHF [13, 57] is an increasingly popular technique for reducing harmful behaviors in large language models [3, 21, 52]. Some of these models are already deployed [52], so we believe the impact of RLHF deserves further scrutiny. Second, previous work shows that the amount of RLHF training can significantly change metrics on a wide range of personality, political preference, and harm evaluations for a given model size [41]. As a result, it is important to control for the amount of RLHF training in the analysis of our experiments. 3.2 Experiments 3.2.1 Overview We test the effect of natural language instructions on two related but distinct moral phenomena: stereotyping and discrimination. Stereotyping involves the use of generalizations about groups in ways that are often harmful or undesirable.4To measure stereotyping, we use two well-known stereotyping benchmarks, BBQ [40] (§3.2.2) and Windogender [49] (§3.2.3). For discrimination, we focus on whether models make disparate decisions about individuals based on protected characteristics that should have no relevance to the outcome.5 To measure discrimination, we construct a new benchmark to test for the impact of race in a law school course
Top 3 passage with score 0.9408788084983826 from http://arxiv.org/pdf/2302.07842: preferences and values which are difficult to capture by hard- coded reward functions. RLHF works by using a pre-trained LM to generate text, which i s then evaluated by humans by, for example, ranking two model generations for the same prompt. This data is then collected to learn a reward model that predicts a scalar reward given any generated text. The r eward captures human preferences when judging model output. Finally, the LM is optimized against s uch reward model using RL policy gradient algorithms like PPO ( Schulman et al. ,2017). RLHF can be applied directly on top of a general-purpose LM pre-trained via self-supervised learning. However, for mo re complex tasks, the model’s generations may not be good enough. In such cases, RLHF is typically applied afte r an initial supervised fine-tuning phase using a small number of expert demonstrations for the correspondi ng downstream task ( Ramamurthy et al. ,2022; Ouyang et al. ,2022;Stiennon et al. ,2020). A successful example of RLHF used to teach a LM to use an extern al tool stems from WebGPT Nakano et al. (2021) (discussed in 3.2.3), a model capable of answering questions using a search engine and providing
# Same code as before, just different model cross_encoder = CrossEncoder('BAAI/bge-reranker-base')
cross_inp = [[query, chunks[hit['corpus_id']]] for hit in hits] cross_scores = cross_encoder.predict(cross_inp)
for idx in range(len(cross_scores)): hits[idx]['cross-score'] = cross_scores[idx]
hits = sorted(hits, key=lambda x: x['cross-score'], reverse=True) bge_corpus_ids = [hit['corpus_id'] for hit in hits] for i, hit in enumerate(hits[:3]): sample = dataset["train"][hit["corpus_id"]] print(f"Top {i+1} passage with score {hit['cross-score']} from {sample['source']}:") print(sample["chunk"]) print("\n")
Top 1 passage with score 0.9668010473251343 from http://arxiv.org/pdf/2204.05862: Stackoverflow Good Answer vs. Bad Answer Loss Difference Python FT Python FT + RLHF(b)Difference in mean log-prob between good and bad answers to Stack Overflow questions. Figure 37 Analysis of RLHF on language modeling for good and bad Stack Overflow answers, over many model sizes, ranging from 13M to 52B parameters. Compared to the baseline model (a pre-trained LM finetuned on Python code), the RLHF model is more capable of distinguishing quality (right) , but is worse at language modeling (left) . the RLHF models obtain worse loss. This is most likely due to optimizing a different objective rather than pure language modeling. B.8 Further Analysis of RLHF on Code-Model Snapshots As discussed in Section 5.3, RLHF improves performance of base code models on code evals. In this appendix, we compare that with simply prompting the base code model with a sample of prompts designed to elicit helpfulness, harmlessness, and honesty, which we refer to as ‘HHH’ prompts. In particular, they contain a couple of coding examples. Below is a description of what this prompt looks like: Below are a series of dialogues between various people and an AI assistant. The AI tries to be helpful,
Top 2 passage with score 0.9574587345123291 from http://arxiv.org/pdf/2302.07459: We examine the influence of the amount of RLHF training for two reasons. First, RLHF [13, 57] is an increasingly popular technique for reducing harmful behaviors in large language models [3, 21, 52]. Some of these models are already deployed [52], so we believe the impact of RLHF deserves further scrutiny. Second, previous work shows that the amount of RLHF training can significantly change metrics on a wide range of personality, political preference, and harm evaluations for a given model size [41]. As a result, it is important to control for the amount of RLHF training in the analysis of our experiments. 3.2 Experiments 3.2.1 Overview We test the effect of natural language instructions on two related but distinct moral phenomena: stereotyping and discrimination. Stereotyping involves the use of generalizations about groups in ways that are often harmful or undesirable.4To measure stereotyping, we use two well-known stereotyping benchmarks, BBQ [40] (§3.2.2) and Windogender [49] (§3.2.3). For discrimination, we focus on whether models make disparate decisions about individuals based on protected characteristics that should have no relevance to the outcome.5 To measure discrimination, we construct a new benchmark to test for the impact of race in a law school course
Top 3 passage with score 0.9408788084983826 from http://arxiv.org/pdf/2302.07842: preferences and values which are difficult to capture by hard- coded reward functions. RLHF works by using a pre-trained LM to generate text, which i s then evaluated by humans by, for example, ranking two model generations for the same prompt. This data is then collected to learn a reward model that predicts a scalar reward given any generated text. The r eward captures human preferences when judging model output. Finally, the LM is optimized against s uch reward model using RL policy gradient algorithms like PPO ( Schulman et al. ,2017). RLHF can be applied directly on top of a general-purpose LM pre-trained via self-supervised learning. However, for mo re complex tasks, the model’s generations may not be good enough. In such cases, RLHF is typically applied afte r an initial supervised fine-tuning phase using a small number of expert demonstrations for the correspondi ng downstream task ( Ramamurthy et al. ,2022; Ouyang et al. ,2022;Stiennon et al. ,2020). A successful example of RLHF used to teach a LM to use an extern al tool stems from WebGPT Nakano et al. (2021) (discussed in 3.2.3), a model capable of answering questions using a search engine and providing
让我们比较一下三个模型的排名:
for i in range(25): print(f"Top {i+1} passage. Bi-encoder {retrieval_corpus_ids[i]}, Cross-encoder (MS Marco) {msmarco_l6_corpus_ids[i]}, BGE {bge_corpus_ids[i]}")
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。