![]()
本文介绍了 Databend 开放表格式引擎的支持情况,包括优势与不足、使用方法、与 Catalog 方案的对比。此外,还包含一个简单的 Workshop ,介绍如何利用 Databend Cloud 分析位于对象存储中的 Delta Table 。
Databend 近期发布 Apache Iceberg 和 Delta Table 两类表引擎,以提供对两种目前最受欢迎的开放表格式的支持,满足基于不同技术栈的现代数据湖方案面临的高级分析需求。
采用基于 Databend / Databend Cloud 的一站式解决方案,可以在不启用额外的 Spark / Databricks 服务的前提下,完成对开放表格式数据的洞见,简化部署架构与分析流程。此外,利用 Databend / Databend Cloud 在 Apache OpenDAL™ 之上构建的数据访问方案,可以便捷访问数十种存储服务,包括对象存储、HDFS 甚至 IPFS ,可以与现有技术栈轻松集成。
优势
不足
- 目前 Apache Iceberg 和 Delta Lake 引擎仅支持只读操作,也就是只能查询数据,无法向表中写入数据。
- 表的 Schema 是在表创建时确定的,如果对原始表的 Schema 进行了修改,为了保证数据的一致与同步,需要在 Databend 中重新创建表。
使用方法
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
小贴士: Databend 中使用 CONNECTION 管理与外部存储服务进行交互所需的详细信息,比如访问凭证、端点URL和存储类型。通过指定 CONNECTION_NAME ,可以在创建资源时复用 CONNECTION,简化存储配置的管理和使用。
与 Catalog 方案的对比
此前 Databend 已经通过 Catalog 提供 Iceberg 和 Hive 的支持,相比表引擎,Catalog 更加适合完整对接相关生态,一次性挂载多个数据库和表的情况。
而新增的开放表格式引擎在体验上更加灵活,支持在同一个数据库下汇总并混合来自不同数据源、不同表格式的数据,并进行有效地分析与洞见。
Workshop:使用 Databend Cloud 分析 Delta Table 中的数据
在这个示例将会展示如何利用 Databend Cloud 加载并分析位于对象存储中的 Delta Table 。
我们将会使用经典的企鹅体态特征数据集(penguins),将其转化为 Delta Table 并放置在 S3 兼容的对象存储中。该数据集一共包含 8 个变量,其中 7 个特征变量,1 个分类变量,共计 344 个样本。
- 分类变量为企鹅类别(species),属于硬尾企鹅属的三个亚属,分别是 Adélie ,Chinstrap 和 Gentoo 。
- 包含的三种企鹅的六个特征,分别是所在岛屿(island),嘴巴长度(bill_length_mm),嘴巴深度(bill_depth_mm),脚蹼长度(flipper_length_mm),身体体重(body_mass_g),性别(sex)。
如果你还没有 Databend Cloud 帐号,欢迎访问 https://app.databend.cn/register 注册并获取免费额度。或者也可以参考 https://docs.databend.com/guides/deploy/ 在本地部署 Databend 。
本文中还涉及对象存储的使用,也可以尝试使用具有免费额度的 Cloudflare R2 创建 Bucket 。
向对象存储中写入数据
我们需要安装对应的 Python 包,seaborn 负责提供原始数据,deltalake 负责将数据转换为 Delta Table 并写入 S3 :
pip install deltalake seaborn
然后,编辑下面的代码,配置对应的访问凭据,并另存为 writedata.py :
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
执行上面的 Python 脚本,以向对象存储中写入数据:
python writedata.py
使用 Delta 表引擎访问数据
在 Databend 中创建对应的访问凭据:
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
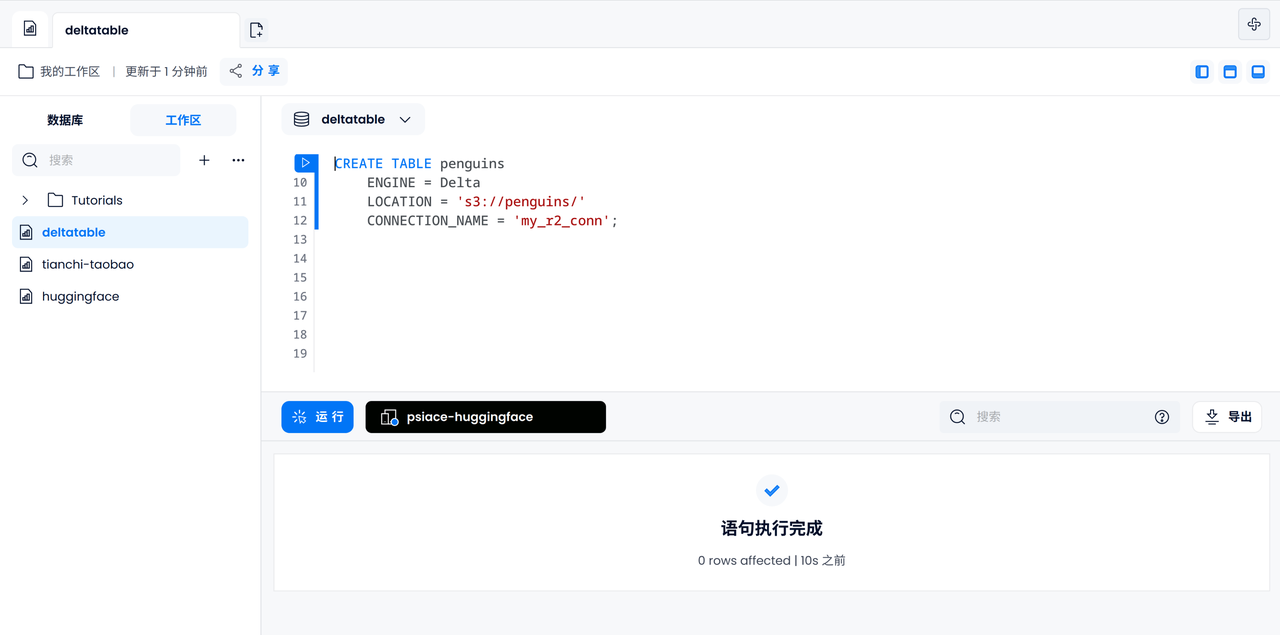
创建由 Delta 表引擎支持的数据表:
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
![]()
利用 SQL 查询和分析表中的数据
验证数据的可访问性
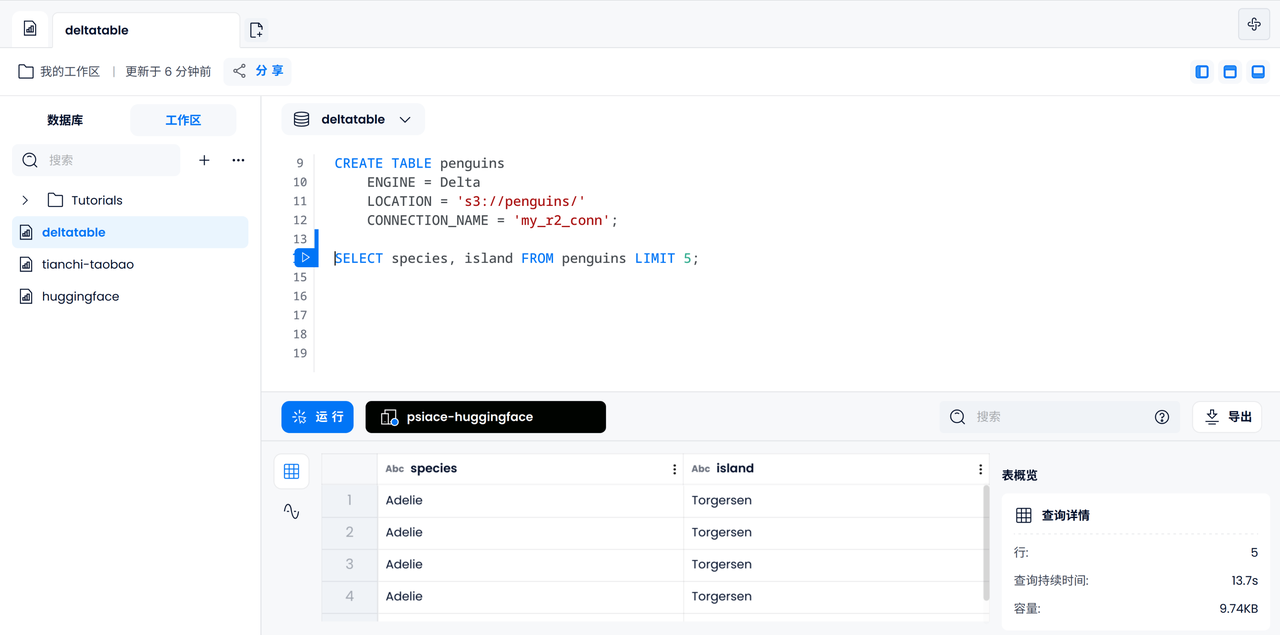
首先,让我们输出 5 个企鹅的种类和所在的岛屿,以检查是否能够正确访问到 Delta Table 中的数据。
SELECT species, island FROM penguins LIMIT 5;
![]()
数据过滤
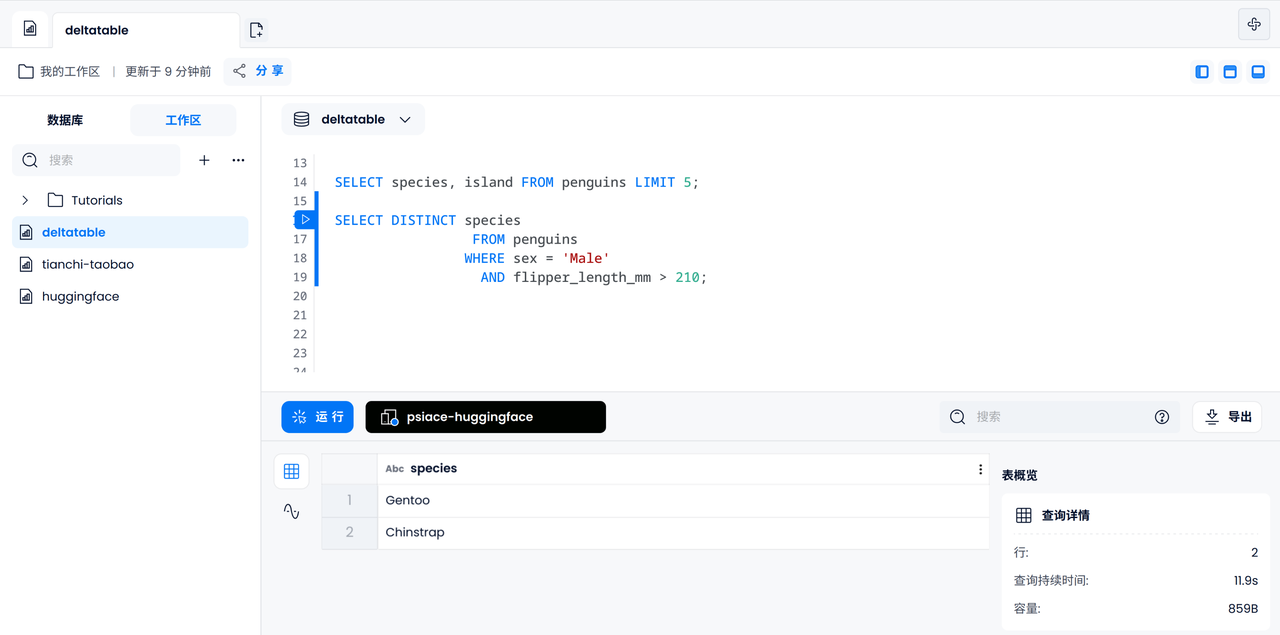
接下来,可以进行一些基本的数据过滤操作,比如找出脚蹼长度超过 210mm 的雄性企鹅可能属于哪一个亚属。
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
![]()
数据分析
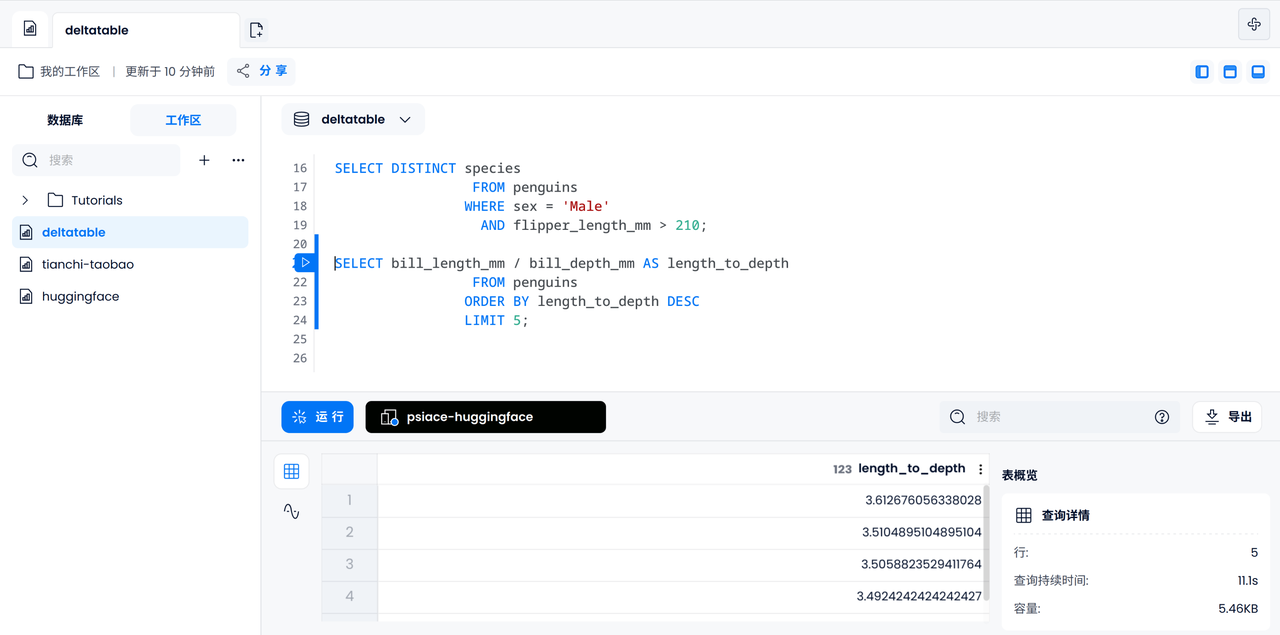
类似地,我们可以尝试计算每只企鹅嘴巴长度和深度的比例,并输出最大的五个数据。
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
![]()
混合数据源案例:企鹅观察日志
现在将会进入一个有趣的部分:假设我们发现了科考站的一份观察记录,让我们尝试在同一个数据库下录入这份数据,并且尝试进行一项简单的数据分析:某只特定性别的企鹅被某位科学家标记的概率是多少。
创建观察日志表
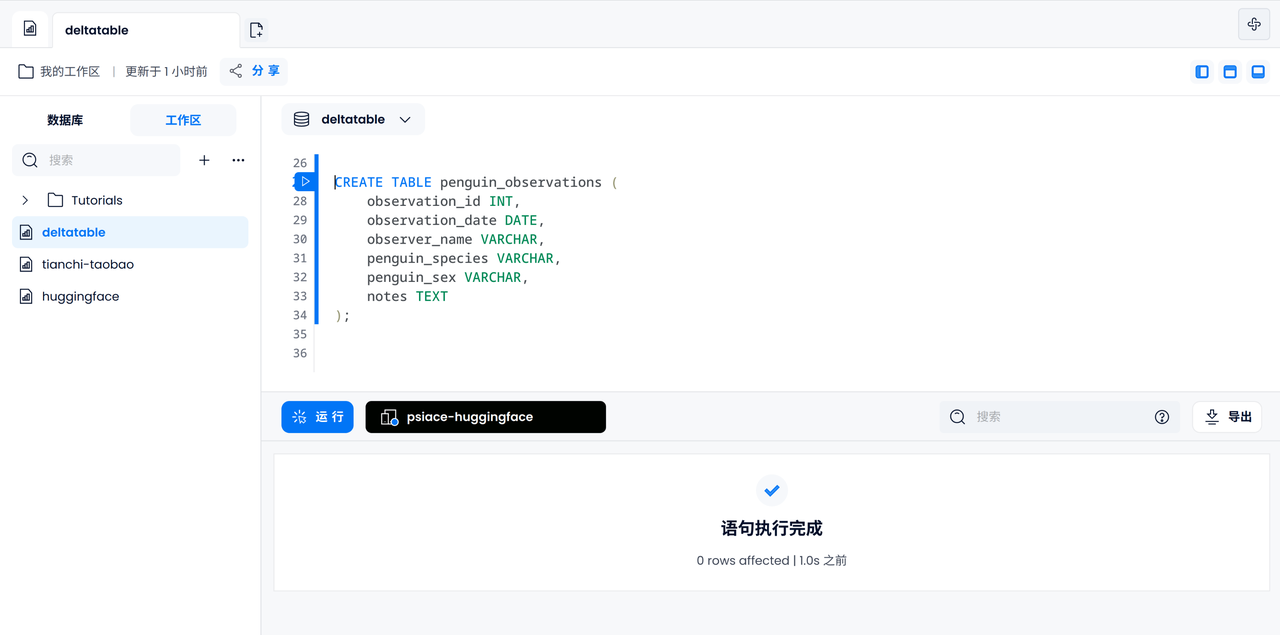
使用默认的 FUSE 引擎创建 penguin_observations 表,包含 ID、日期、姓名、企鹅种类与性别、备注等几类信息。
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
![]()
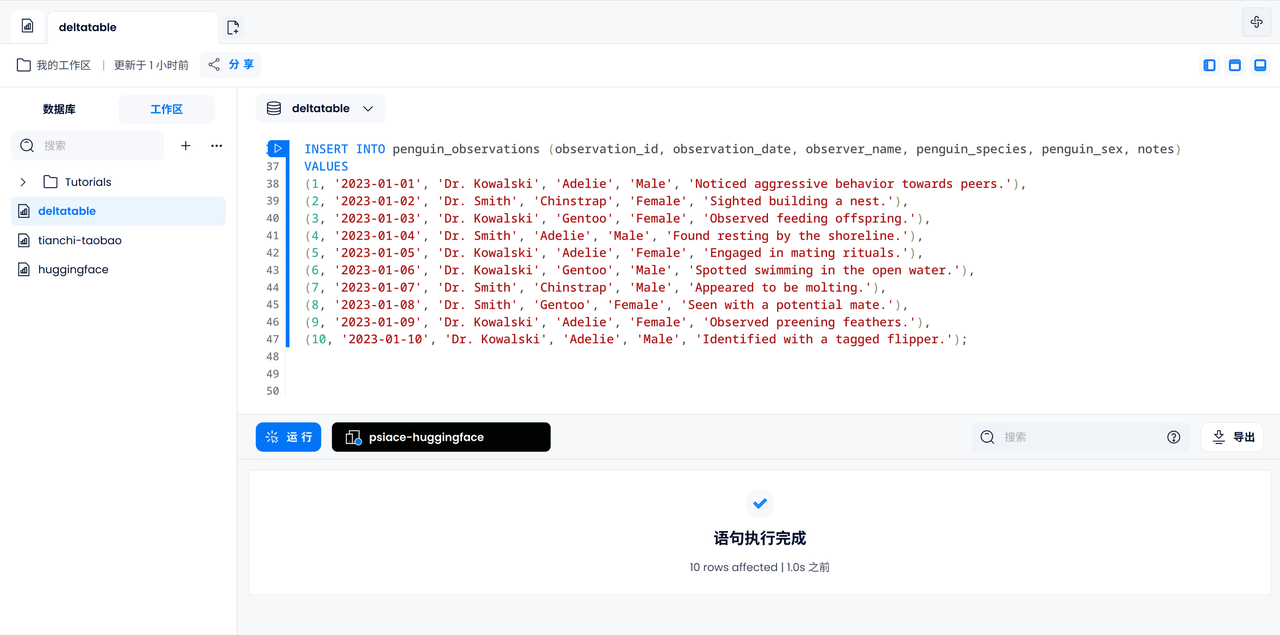
录入观察日志
让我们尝试手工录入全部 10 条日志。已知日志记录中出现的企鹅互不相同。
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
![]()
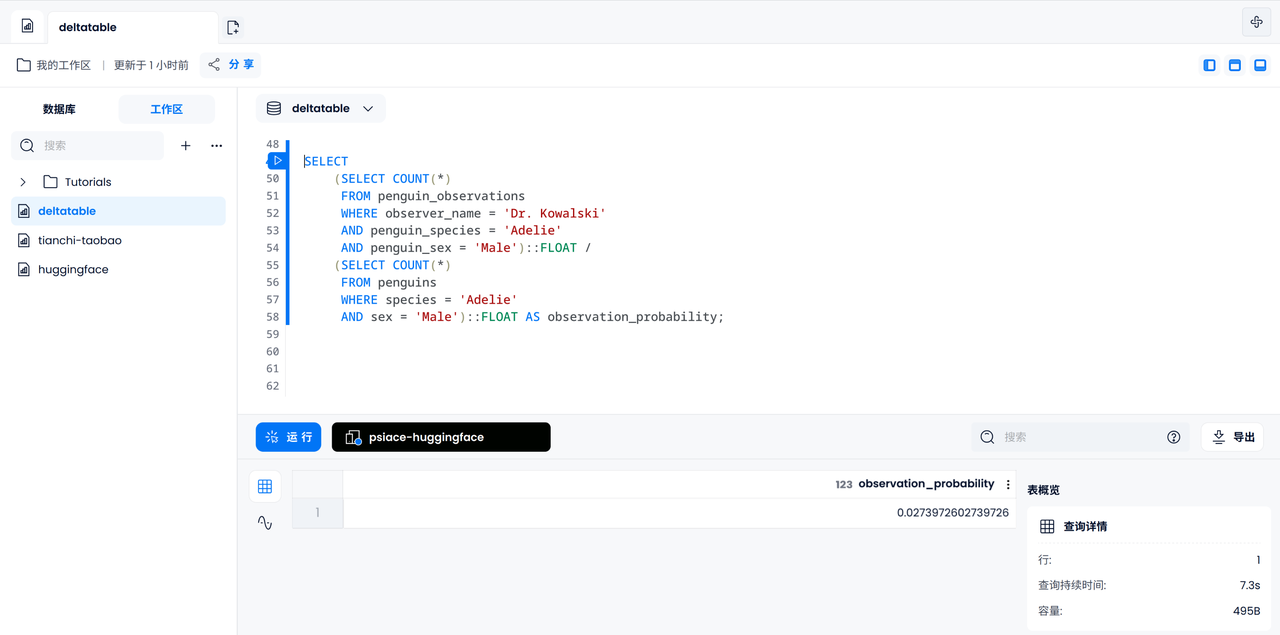
计算标记概率
现在让我们计算在所有企鹅中,某只雄性 Adelie 企鹅被 Dr. Kowalski 观察的概率。首先我们需要统计 Dr. Kowalski 观察到的雄性 Adelie 企鹅的个数,然后统计所有记录在案的雄性 Adelie 企鹅个数,最后相除得到结果。
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
![]()
总结
凭借组合不同表引擎进行查询,Databend / Databend Cloud 可以支撑在同一个数据库下混合不同格式的表,并进行分析与查询。本文只是提供一个基本的 Workshop 供大家体验功能和使用,欢迎大家基于这个案例进行拓展,探索更多组合 Iceberg 和 Delta Table 进行数据分析的场景,以及更多潜在的真实世界应用。
推荐阅读