What is High-Cardinality
基数(Cardinality) 在数学中定义是用来代表集合元素个数的标量,比如对于有限集合 A = {a, b, c} 的基数就是 3,对于无限集合也有一个基数概念,今天主要谈论计算机领域,就不在这里展开。
在数据库的上下文里面,基数并没有严格的定义,但大家对基数的共识也类似可借鉴数学中的定义:用来衡量数据列包含的不同数值的个数多少。比如说一个记录用户的数据表,通常有 UID, Name 和 Gender 这几个列,很显然,UID 的基数最高,因为每个用户都会被分配一个唯一的 ID, Name 也算高的,但由于会遇到重名的用户,就不如 UID 那么高,而 Gender 一列可能数值相对较少。所以在用户表这个例子里面,就可以称 UID 列属于高基,而 Gender 则属于低基。
如果再细分到时序数据库的领域,基数往往是特指时间线的个数,我们就以时序数据库在可观测领域的应用举例,一个典型场景是记录 API 服务的请求时间。举一个最简单的例子,针对不同 instance 的 API 服务各个接口的响应时间,就有两个 label: API Routes 和 Instance, 如果有 20 个接口,5 个 instance,时间线的基数就是 (20+1)x(5+1)-1 = 125(+1 是考虑到可以单独看某个 Instance 所有接口响应时间或某个接口在所有 Instances 的响应时间), 看上去数值不大,但要注意算子是乘积,所以只要某个 label 基数高,或者新增加一个 label,就会导致时间线的基数暴增。
Why it matters
众所周知,对于大家最熟悉的 MySQL 这类关系型数据库而言,一般都有 ID 列,还有比如像 email, order-number 等等常见的列,这些都是 high-cardinality 的列,很少听说过因为这样的数据建模而引起某些问题。事实也是这样的,在我们熟悉的 OLTP 领域,往往 high-cardinality 并不是一个问题,但在时序领域,因为数据模型的原因,往往会带来问题,在进到时序领域之前,我们还是先来讨论一下高基的数据集到底意味着什么。
在我看来,高基的数据集换个通俗的说法就是数据量大,那对于数据库而言,数据量的增加必然会对写入,查询和存储三个方面都带来影响,特别地,在写入时影响最大的还是索引。
传统数据库的高基数
以关系型数据库中采用的最常见的用来建立索引的数据结构 B-tree 为例,通常情况下,插入、查询的复杂度是 O(logN),空间的复杂度一般来讲是 O(N), 其中的 N 是元素个数,也就是我们谈到的基数。自然 N 越大会有一定影响,但因为插入和查询的复杂度是自然对数,所以数据量级不是特别大的情况下,影响并没那么大。
所以看起来高基数据并没有带来什么不可忽视的影响,反而在很多情况下,高基数据的索引比低基数据的索引选择性更强,高基索引通过一个查询条件就可以过滤掉大部分不满足条件的数据,从而减少磁盘 I/O 开销,在数据库应用方面,需要避免过多磁盘和网络的 I/O 开销。比如 select * from users where gender = "male";,得到的数据集就非常多,磁盘 I/O 和网络 I/O 都会很大,实践中,单独使用这个低基数索引的意义也并不大。
时序数据库的高基数
那么时序数据库究竟有什么不同的地方,使得高基的数据列会引起问题?在时序数据领域,无论是数据建模还是引擎设计,核心会围绕时间线进行。正如前面谈到的,时序数据库里面的高基问题,指的是时间线的数量大小,这个大小不仅仅是一个列的基数,而是所有 label 列的基数乘积,这样的扩散性就会非常大,可以理解成在常见的关系型数据库中,高基是隔离在某个列中,即数据规模是线性增长,而时序数据库中的高基是多列的乘积,是非线性增长。让我们具体来看看在时序数据库中的高基时间线是如何产生的,我们先看第一种场景:
Time-series 数量
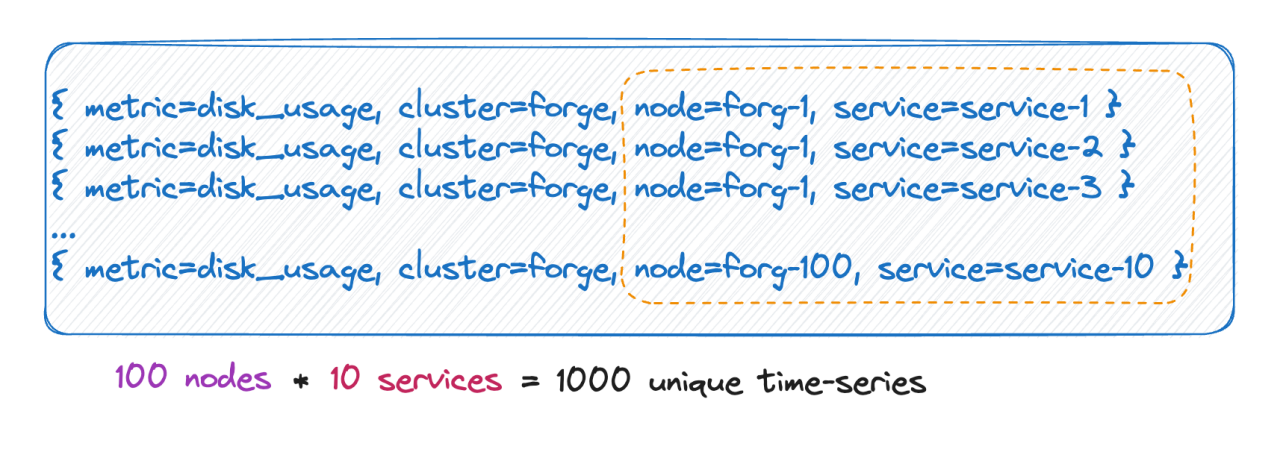
![]()
我们知道,时间线数量实际上就等于所有 label 基数的笛卡尔积。 如上图,时间线数量就是 100 * 10 = 1000 条时间线,如果给这个 metric 再加上 6 个 tag,每个 tag value 的取值有 10 种,时间线数量就是 10^9 ,也就是一亿条时间线,可以想象这个量级了。
Tag 拥有无限多的值
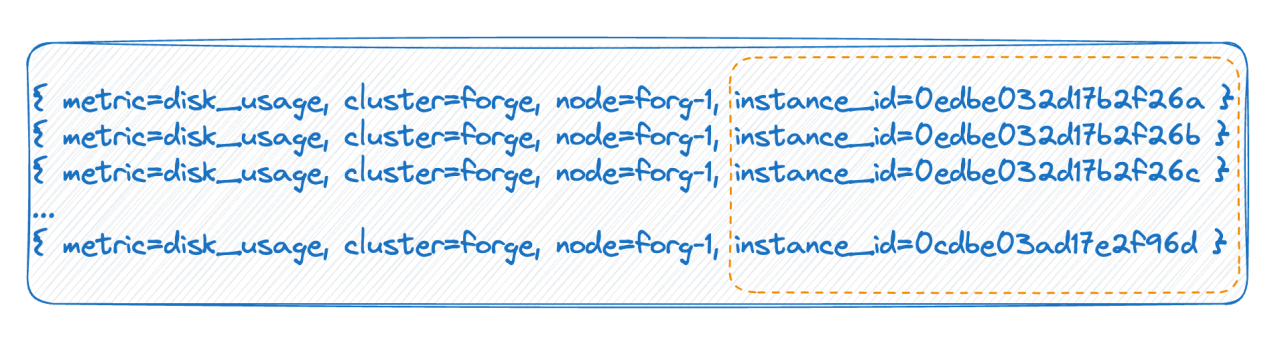
![]()
第二种情况,比如在云原生环境里,每个 pod 都有一个 ID,每次重启时实际上 pod 是删除再重建,它会生成一个新的 ID,这就导致这个 tag value 的值会非常的多,每次全量重启会导致时间线数量翻一倍。 以上两种情况,就是时序数据库所说的高基数产生的主要原因。
时序数据库如何组织数据
我们知道高基数是怎么产生的了,要理解它会导致什么问题,还要了解主流的时序数据库是怎么组织数据的。
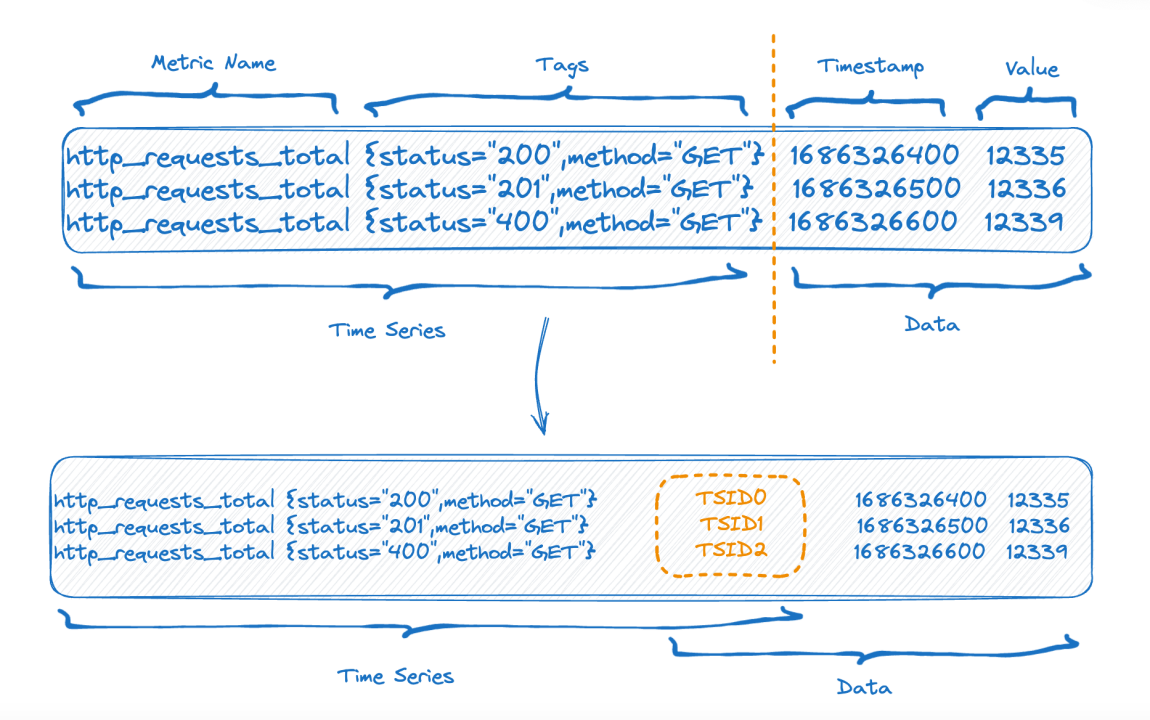
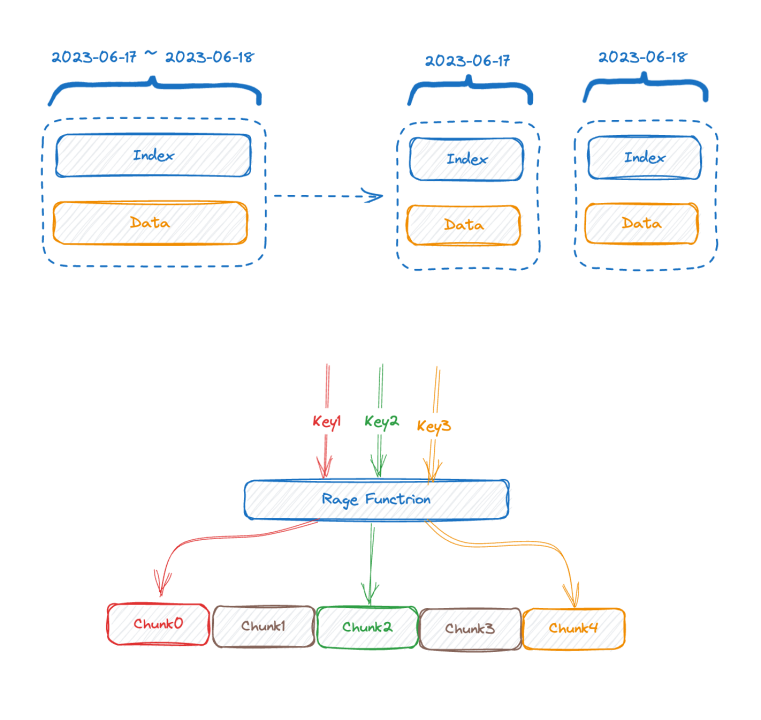
![]()
图中上半部分是数据写入前的表现形式,下半部分的图则是数据存储后的逻辑上的表现形式,左侧也就是 time-series 部分的索引数据,右侧则是数据部分。
每个 time-series 可以生成一个唯一的 TSID,索引和数据就是通过 TSID 关联起来的,这个索引,熟悉的朋友可能已经看出来了,它就是倒排索引。
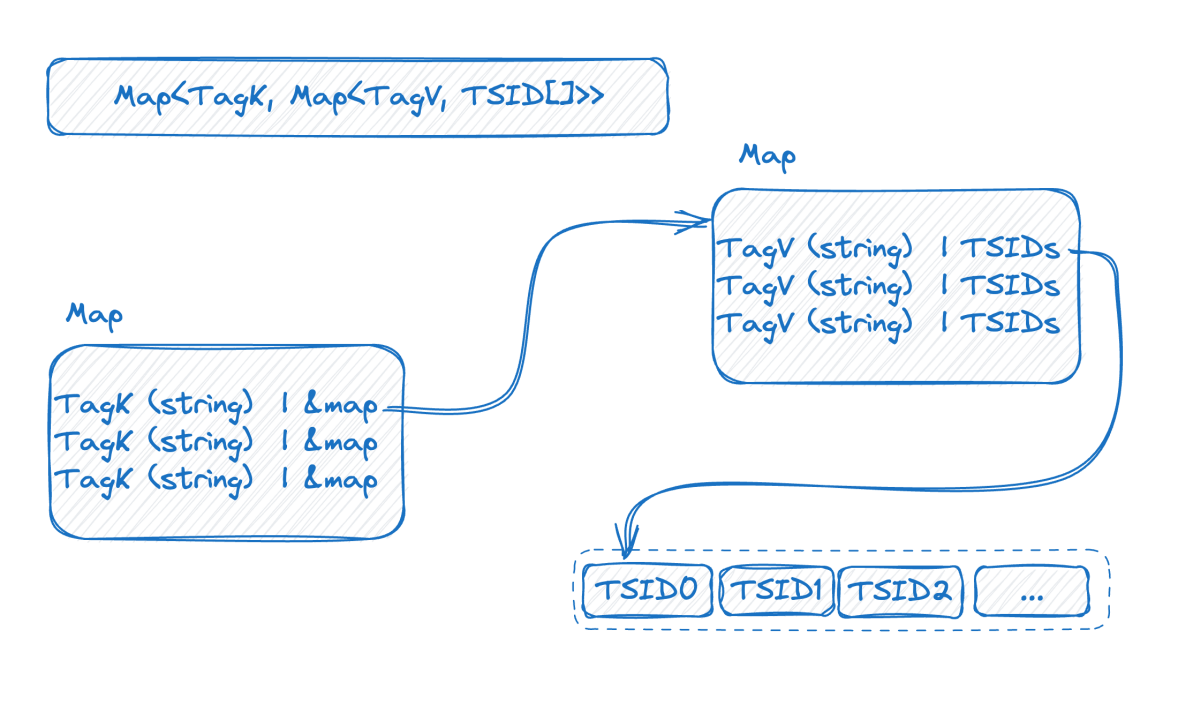
再来看下图,是倒排索引在内存中的一个表现形式:
![]()
这是一个双层的 map,外层先通过 tag name 找到内层 map,内层 map 的 K 是 tag value, V 是包含相应 tag value 的 TSID 的集合。
到这里再结合前面的介绍,我们可以看出来了,时序数据的基数越高,这个双层 map 就会越大。 明白索引结构了以后我们就可以试图去理解高基问题是如何产生的:
为了实现高吞吐的写入,这个索引最好能保留在内存中,高基数则会导致索引膨胀从而让你的内存中放不下索引。内存放不下就要交换到磁盘,交换到磁盘后就会因为大量的随机磁盘 IO 影响写入速度。 再来看查询,从索引结构我们是可以猜到查询的过程,比如查询条件 where status = 200 and method="get",流程是先去找 key 为 status 的 map,拿到内层的 map 再根据 "200" 获取所有 TSID 集合,同样的方式再去查下一个条件,然后两个 TSID 集合做交集后得到的新的 TSID 集合再去一个一个的按照 TSID 去捞数据。
可以看出,问题就核心在于数据是按照时间线来组织的,所以先要拿到时间线,再按照时间线去找数据。一次查询涉及到的时间线越多,查询就会越慢。
How to solve it
如果我们分析的是对的,知道了在时序数据领域下引起高基问题的原因,那也就好解决了,再来看一下引起问题的原因:
- 数据层面:C(L1) * C(L2) * C(L3) * ... * C(Ln) 引起的索引维护,查询挑战。
- 技术层面:数据是按照时间线来组织的,所以你先要拿到时间线,再按照时间线去找数据,时间线多就查询变慢。
那小编抛砖引玉一下分别从两个方面来探讨解法:
数据建模上的优化
1 去掉不必要的 labels
我们经常会不小心将一些不必要字段设定成 label,从而导致时间线膨胀。比如说我们在监控服务器状态时,经常会有 instance_name, ip, 其实这两个字段没有必要都成为 label, 有其中一个很可能就可以了,另外一个可以设定成属性。
2 根据实际的查询来做数据建模
拿物联网中的传感器监控为例子:
如果建模到一个 metric 里面,在 Prometheus 里面,就会导致有 10w * 100 * 10 = 1 亿的时间线。(非严谨计算) 思考一下,查询会按照这种方式进行么?比如说查询 某个某种类型设备在某个地区的时间线?这个似乎不太合理,因为一旦指定了设备,那种类也就确定了,所以这两个 label 之间其实是不需要做在一起,那可能就变成:
- metric_one: 10w 个设备
- metric_two:
- metric_three:(假设某个设备可能会换到不同的地区采集数据)
这样总计也就是 10w + 10010 + 10w100 ~ 1010w 的时间线,比起上述要少了 10倍。
3 将有价值的高基时间线数据单独管理
当然如果发现你的数据建模已经和查询非常符合了,由于数据规模太大,依然无法将时间线减少,那就把和这个核心指标有关的服务都单独放到一个更好的机器上吧。
时序数据库技术上的优化
![]()
- 第一个有效的解法是垂直切分,大部分业界主流时序数据库或多或少都采用了类似方法,按照时间来切分索引,因为如果不做这个切分的话,随着时间的推进,索引会越来越膨胀,最后到内存放不下,如果按照时间切分,可以把旧的 index chunk 交换到磁盘甚至远程存储,起码写入是不会被影响到了。
- 与垂直切分相对的,就是水平切分,用一个 sharding key,一般可以是查询谓词使用频率最高的一个或者几个 tag,按照这些 tag 的 value 来进行 range 或者 hash 切分,这样就相当于使用分布式的分而治之思想解决了单机上的瓶颈,代价就是如果查询条件不带 sharding key 的话通常是无法将算子下推,只能把数据捞到最上层去计算。
上面两个办法,属于传统的解决办法,只能一定程度缓解问题,并不能从根本上解决问题。 接下来两个方案不算是常规方案,是 GreptimeDB 在尝试探索的方向,这里只稍微提下不做深入的分析,仅供大家参考:
-
我们可能要思考一下,时序数据库是不是真的都需要倒排索引,TimescaleDB 采用 B-tree 索引, InfluxDB_IOx 也没有倒排,对高基数的查询,我们使用 OLAP 数据库常用的分区扫描结合 min-max 索引进行一些剪枝优化,效果会不会更好?
-
异步的智能索引了,要智能,就得先采集和分析行为,在用户的一次次查询中分析并异步构建最合适的索引来加速查询,比如对用户查询条件中出现频率非常低的 tag 我们选择不为它创建倒排。 上面两个方案结合起来看,在写入的时候,因为倒排异步构建了,所以完全不影响写入速度。
再来看查询,因为时序数据有时间属性,所以数据是可以按照 timestamp 来分桶,在最近的 time bucket 上我们不做索引,解决办法就是硬扫,结合一些 min-max 类索引进行剪枝优化,秒级扫描千万行上亿行还是可以做到的。
一个查询来了,先去预估会涉及多少时间线,涉及少的走倒排,多的不走倒排直接走 scan + filter 的方式。
以上这些想法,我们还在不断的探索当中,还不完善。
Conclusion
高基并不总是问题,有时候高基是必要的,我们需要做的是结合自身的业务情况以及所使用的工具性质,来构建自己的数据模型。当然有时候工具有一定场景局限性,比如 Prometheus 默认是为每个 metric 下的 label 建立索引,在单机场景下问题不大,同时还能方便用户使用,但放到了大规模数据下就会捉襟见肘。GreptimeDB 是致力打造在单机和规模化场景下的统一解决方案,对于高基问题的技术尝试,我们也在探索,也欢迎大家一起讨论。
Reference
关于 Greptime:
Greptime 格睿科技致力于为智能汽车、物联网及可观测等产生大量时序数据的领域提供实时、高效的数据存储和分析服务,帮助客户挖掘数据的深层价值。目前主要有以下三款产品:
-
GreptimeDB 是一款用 Rust 语言编写的时序数据库,具有分布式、开源、云原生和兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时降低长期存储成本。
-
GreptimeCloud 可以为用户提供全托管的 DBaaS 服务,能够与可观测性、物联网等领域高度结合。
-
GreptimeAI 是为 LLM 应用量身定制的可观测性解决方案。
-
车云一体解决方案是一款深入车企实际业务场景的时序数据库解决方案,解决了企业车辆数据呈几何倍数增长后的实际业务痛点。
GreptimeCloud 和 GreptimeAI 已正式公测,欢迎关注公众号或官网了解最新动态!对企业版 GreptimDB 感兴趣也欢迎联系小助手(微信搜索 greptime 添加小助手)。
官网:https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime