业内较为常见的高频短时 ETL 数据加工场景,即频率高时延短,一般均可归类为调用密集型场景。此场景有着高并发、海量调用的特性,往往会产生高额的计算费用,而业内推荐方案一般为攒批处理,业务实时性会有一定的影响。基于此痛点,函数计算 FC 推出定向减免方案,让 ETL 数据加工更简单、更自动化、容错能力更强,且业务实时性更高、计算费用更低。
自 2024 年 01 月 01 日 0 时起,函数计算定向减免来自阿里云消息类产品和云工作流(CloudFlow)的函数调用次数费用,即通过以上产品事件触发函数计算所产生的函数调用次数不再计入费用账单。定向减免函数调用次数费用的产品包括:
- 阿里云消息类产品:
- 消息服务 MNS
- 云消息队列 RocketMQ 版
- 消息队列 RabbitMQ 版
- 云消息队列 Kafka 版
- 云消息队列 MQTT 版
- 事件总线 EventBridge
- 云工作流(CloudFlow)
这样用 FC,ETL 场景可立省 87% 计算费用
某出行领域客户基于函数计算 FC 构建免运维、自动化的 ETL 数据加工场景如下:
每天处理 10 亿条 Kafka 消息数据,每次处理平均耗时 10 毫秒,算力规格 0.1c0.5g,其费用组成为:
- vCPU 使用量:0.1 * 1000000000 * 0.01 * 0.00009 = 90 元
- 内存使用量:0.5 * 1000000000 * 0.01 * 0.000009 = 45 元
- 函数调用次数费用:1000000000 / 10000 * 0.009 = 900 元
注意:以上均按照函数计算阶梯计费的阶梯0单价进行计价,忽略免费额度,定价参考:
![]()
若定向减免该 ETL 场景下的函数调用次数费用,则该 ETL 场景可立省 87% 计算费用!(不同场景的降本数字需结合实际业务需求进行测算。)
基于函数计算 FC 的热门 ETL 场景
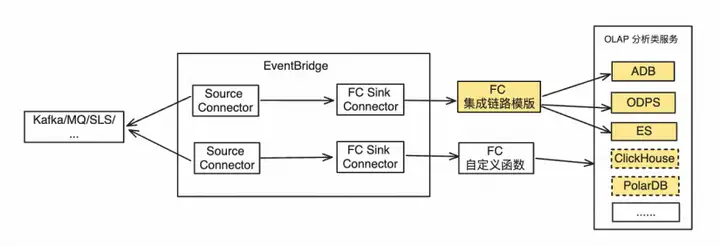
数据投递分析
在数据投递分析场景中,函数计算可以为用户的投递以及数据分析提供高自由度的模板能力和自定义能力,提供海量下游投递能力。
![]()
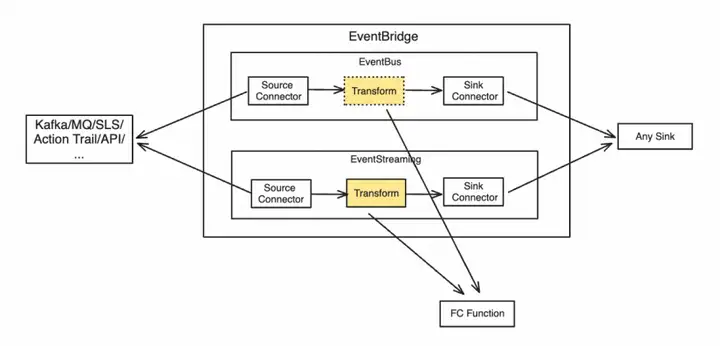
数据加工清洗转存
数据清洗加工和转存场景,函数计算可以提供数据 Transform 处理能力,供数据加工。
![]()
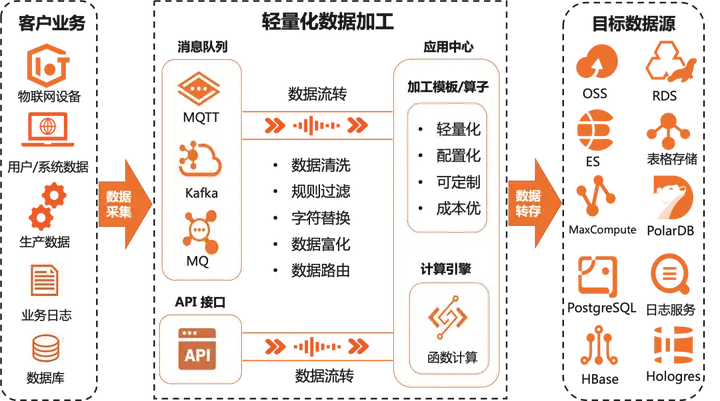
业务消息处理
函数计算 FC 有丰富的事件响应场景,消息作为事件驱动的重要数据源,可以驱动函数计算执行一系列业务逻辑,构建完整的事件驱动架构。
![]()
立即开始
阿里云消息类产品
函数计算 FC 和阿里云消息产品家族通过产品集成,只需要简单“点点点”即可实现自动化、高可用的弹性消息 ETL 方案,大幅简化了 ETL 任务的难开发、难运维的痛点。
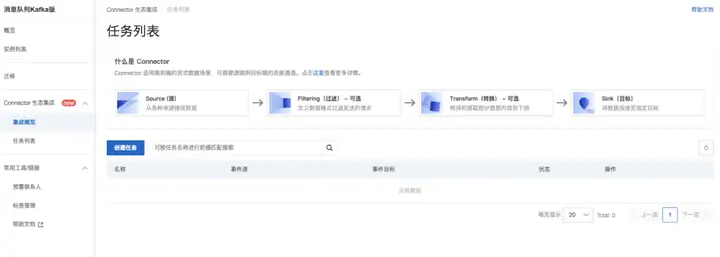
Connector 生态集成
在 Kafka、RocketMQ、RabbitMQ 控制台配置 Connector 实现消息 ETL 任务,选择函数计算 FC 模板即可实现预置过滤、转换、投递等基础需求。如若需要实现更自定义的转换需求,也可以在函数计算 FC 控制台创建事件函数进行定制开发,然后在 Connector 界面选择指定的函数即可运行特定 ETL 任务。
同时,也可以通过此类 ETL 任务实现消息数据快速投递至存储、大数据等,实现数据转储需求。
EventBridge 事件流
在 EventBridge 控制台配置事件流,快速创建消息队列、数据库等数据 ETL 任务,选择函数计算 FC 模板即可实现预置过滤、转换、投递等基础需求。如若需要实现更自定义的转换需求,也可以在函数计算 FC 控制台创建事件函数进行定制开发,然后在 Connector 界面选择指定的函数即可运行特定 ETL 任务。
同时,也可以通过此类 ETL 任务实现消息数据快速投递至存储、大数据等,实现数据转储需求。
![]()
云工作流 CloudFlow
云工作流(CloudFlow)是用来协调多个分布式任务执行的全托管 Serverless 云服务,简化开发、运行业务流程需要的任务协调、状态管理和错误处理等繁琐工作。云工作流配合函数计算 FC 支持简单拖放即可实现复杂业务流程,无需编写代码,即可编排 300+ 云服务实现工作流程自动化,实现流程式编程新范式。
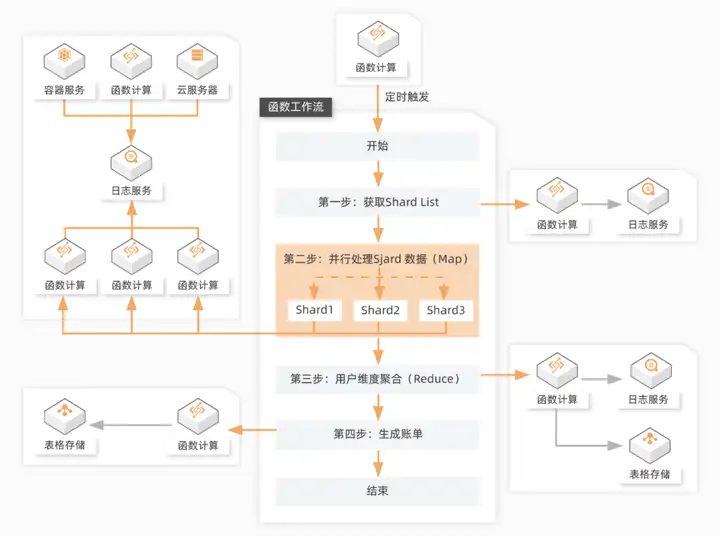
下面是云工作流,函数计算 FC 搭建一个高可用的数据处理流水线的最佳实践:
来自不同数据源的计量数据被收集到日志服务,函数计算 FC 的定时器每小时触发工作流,云工作流利用函数计算 FC 对多个 Shard 的计量数据做并行处理,并将结果分别写回日志服务服务;然后可以将所有 Shard 产生文件进行聚合,写入表格存储 OTS,最后为每个用户生成账单。工作流支持对流程中的单个步骤失败进行重试,降低流程失败概率。工作流支持动态并行任务执行,实现数据处理能力的高可扩展性。
![]()
铭师堂峰值流量破万后的实时 ETL 任务解决方案
业务背景
杭州铭师堂,一家在线教育高科技企业,成立十余年来一直致力于用“互联网+教育”的科技手段让更多的学生能享有优质的教育。学生做完作业后,会将作业拍照,然后上传到作业批阅系统,后端系统此时会有多个动作:
1. 将作业照片上传到 OSS;
2. 将用户作业信息落到数据库;
3. 发送消息到 Kafka,通过 Kafka Connector 驱动实时 ETL 任务。
该 ETL 任务承载了所有的处理逻辑,通过图像识别和数据分类算法,自动识别作业的完成情况。在一年的大多数时间里,业务流量都比较平稳,但在寒暑假时,一般会迎来一年中的高峰,在 2022 年暑假期间,平均每天需要处理 100 多万条作业图片处理,峰值流量更是达到了万级别。
业务痛点
铭师堂的 ETL 任务原先部署在 Kubernetes (简称 K8s),通过订阅 Kafka 的 topic,获取数据路径,从 OSS 获取数据进行处理,涉及到数据并发度的处理,主要存在两方面问题:
1. Kafka 消费端并发度受限于 topic partition,消费端数最多只能跟 partition 数齐平,超过时会导致部分消费端无法订阅数据;
2. 消费端将消费到的数据进行 ETL,K8s 方案铭师堂在实现时将消费端数和 partition 保持一致,但因为 K8s 的弹性策略相对滞后,平峰时问题不大,但高峰期因弹性不足会经常导致任务堆积,实时性无法保证。
为了保证 ETL 任务的实时性,铭师堂架构组一直在寻求一种弹性能力更强的新架构。经过实测对比,基于阿里云函数计算 FC 构建的实时 ETL 任务解决方案是最适配铭师堂业务需求,且弹性能力最强、成本最优的选择。
解决方案
![]()
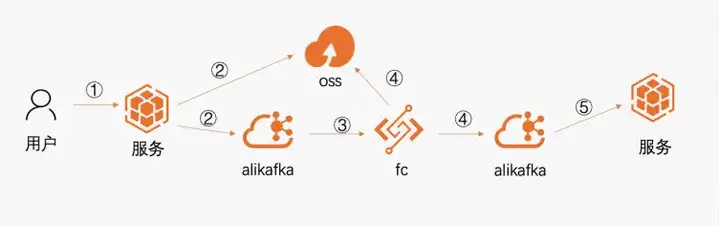
铭师堂基于函数计算构建的实时 ETL 任务解决方案步骤如下:
1. 用户提交作业出发提交流程,将请求打到后端服务;
2. 后端服务将用户提交的作业图片上传到 OSS,并将 OSS 地址作为一条消息发送到 Kafka;
3. 函数计算的 Kafka 触发器实时的感知 Kafka topic,当有新数据到达,实时触发函数处理;
4. 函数计算获取到事件数据,从 OSS 获取数据,并对数据进行处理,将处理结果发回到 Kafka topic;
5. 后端程序订阅 Kafka topic,对处理结果进行存储和下一步的展示。
业务收益
以上解决方案整体开发流程顺利,项目上线后有超出预期的收益:
业务高峰期,对比 K8s 方案,单请求响应时延 100~200ms,函数计算 FC 方案则维持在 50ms 左右,大大超出预期。经过分析,主要原因在于函数计算 FC 资源隔离,每个任务实例均独占计算资源,高峰期突发流量来临时也不会出现资源争抢,ETL 任务的执行性能得到保障;
K8s 方案依赖 metrics 数据“滞后”地执行 HPA 策略调度资源,而 FC 方案则依赖任务并发“提前”实时调度资源。业务高峰期,正在执行的 ETL 任务独占实例,而新任务则通过 FC 的“百毫秒弹性能力”实时拉起新实例,FC 会最大化地复用实例,减少因为“冷启动”而带来的实时性、利用率损耗;
对比 K8s 方案需要预留和管控资源水位,基于 FC 的实时 ETL 任务解决方案实现了按需调度、按量付费,没有任务时资源缩 0,高峰期按业务需求实时调度资源,利用率大大提升。且函数计算 FC 定向减免来自阿里云消息队列 Kafka 的函数调用次数费用,业务成本得到进一步优化。
铭师堂将业务上线到函数计算 FC 后,很好地解决了 K8s 方案高峰期的任务堆积问题,且通过函数计算 FC 内置的监控和日志服务,问题排查效率也得到提升。当然最重要的一点,铭师堂通过函数计算 FC 的实时弹性,不再需要提前规划资源、预留水位、冗余备份,资源成本大幅降低。
![]()
链接汇总:
计费详情
https://help.aliyun.com/zh/fc/product-overview/billing-overview
函数计算官网
https://www.aliyun.com/product/fc
作者:澈尔、墨飏
原文链接
本文为阿里云原创内容,未经允许不得转载。