作者,祝青平,华为云数据库内核高级工程师。 擅长数据库优化器内核研发,9年数据库内核研发经验,参与多个TP以及AP数据库的研发工作。
近日,华为云数据库社区下面有这样一条用户提问留言:请问,如何通过MySQL提升DISTINCT,尤其是多表连接下DISTINCT的查询效率?
在回答这个问题之前,我们先了解一下DISTINCT。
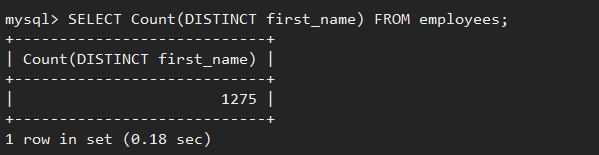
在SQL语句中,DISTINCT关键词用于返回唯一不同的值,使用场景多,应用频繁。它可以用于做单列数据去重,例如,对公司雇员按照”first_name”去重后,得到1275条记录。
![cke_138.png]()
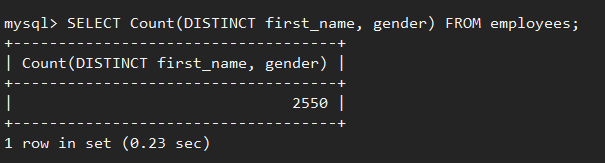
也可以做多列去重,即只有所有指定列的信息都相同时,才会被认为是重复的信息,例如,对公司雇员按照”first_name”和”gender”两列去重后得到2550条记录。
![cke_139.png]()
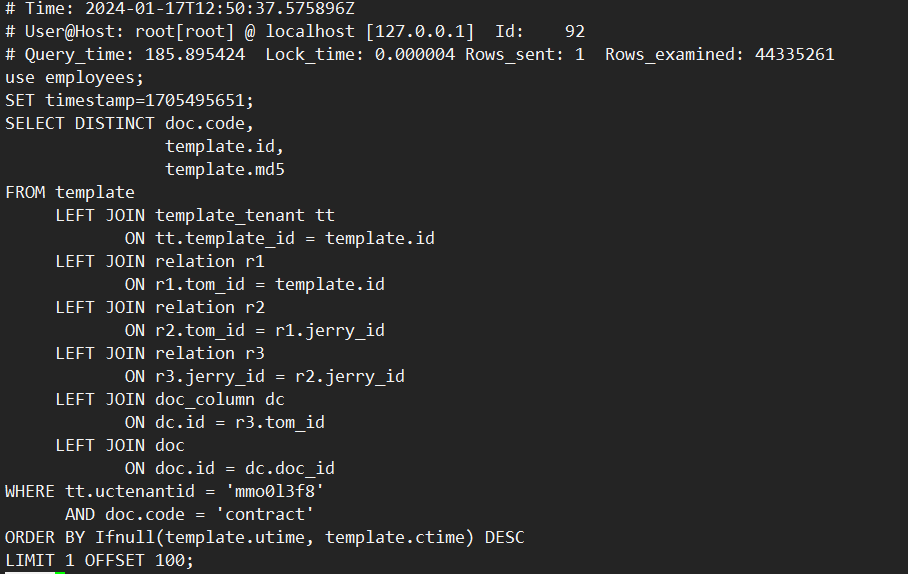
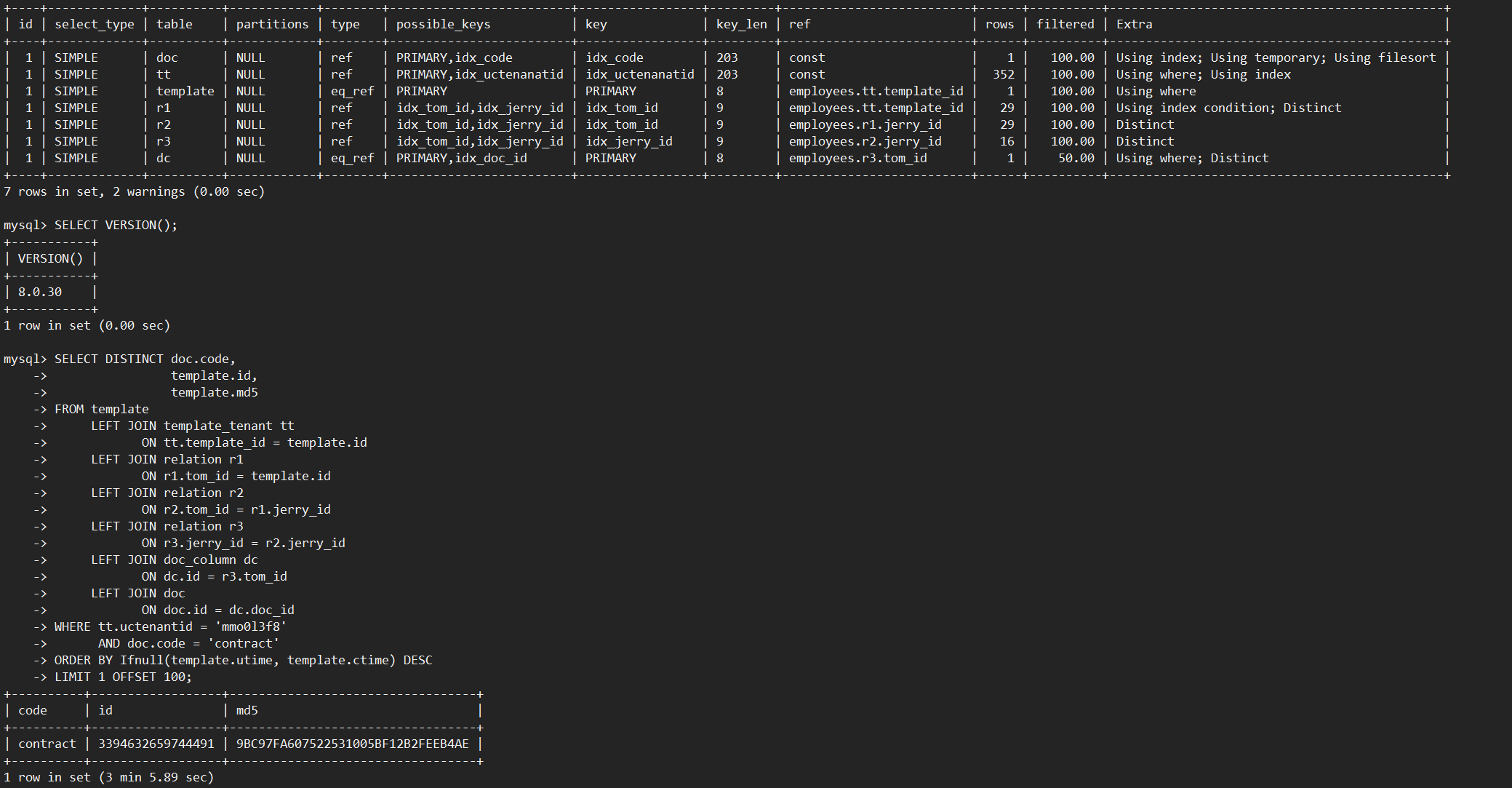
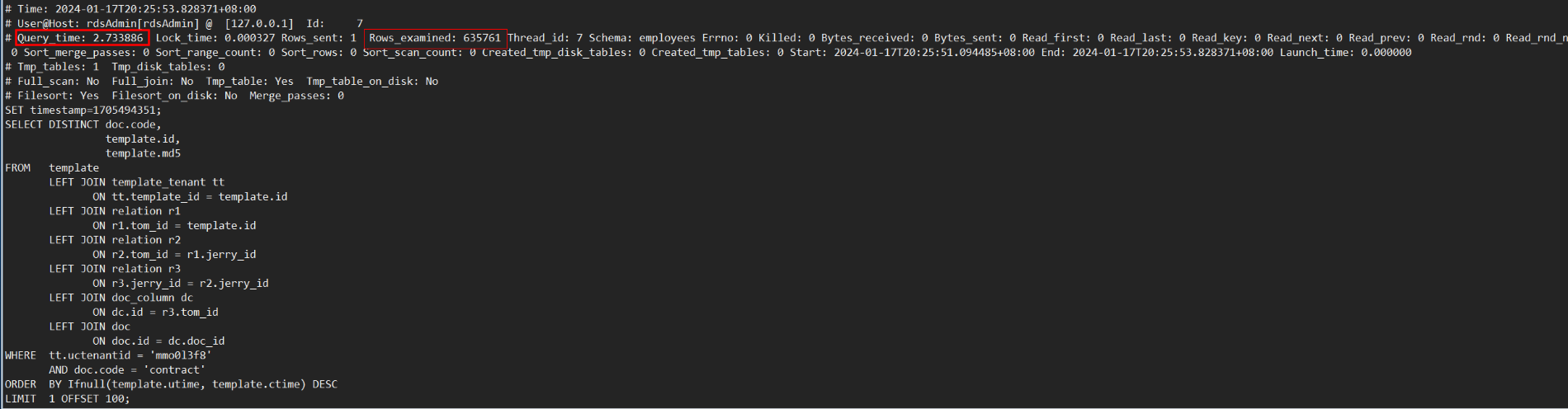
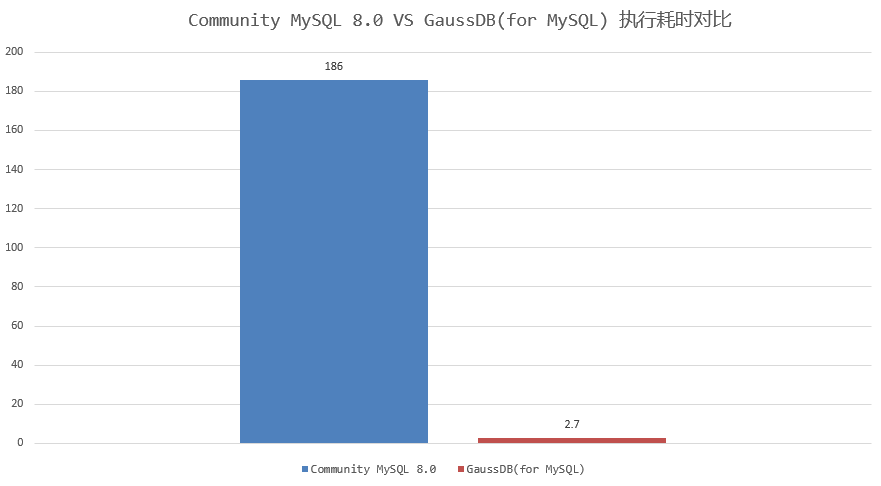
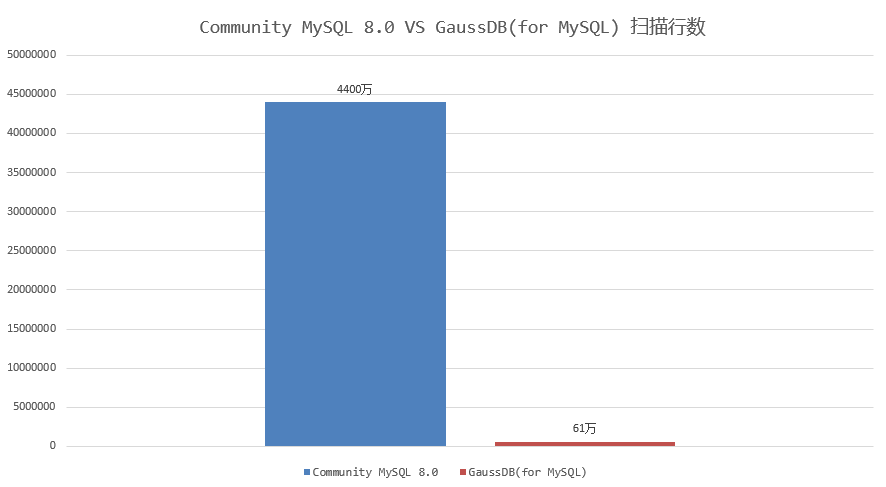
对于“多表连接+DISTINCT”场景,MySQL 8.0需要扫描表连接后的结果。当表连接数量多或基表数据量大时,扫描的数据量也会很大,会导致执行效率很低。如下示例,对7个表连接后的结果做DISTINCT,使用MySQL 8.0.30社区版本,执行耗时186秒,通过查看慢日志信息,发现扫描了约4400万行数据。
![cke_140.png]()
![cke_141.png]()
为了提升DISTINCT,尤其多表连接下DISTINCT的查询效率,GaussDB(for MySQL)在执行优化器中加入了剪枝功能,可以去除不必要的扫描分支,节省查询耗时。
GaussDB(for MySQL)剪枝方案
以下面的SQL执行为例,表t1有4行数据1,2,5,6。执行如下多表连接+DISTINCT:
![cke_142.png]()
表连接执行逻辑如下:
![cke_143.png]()
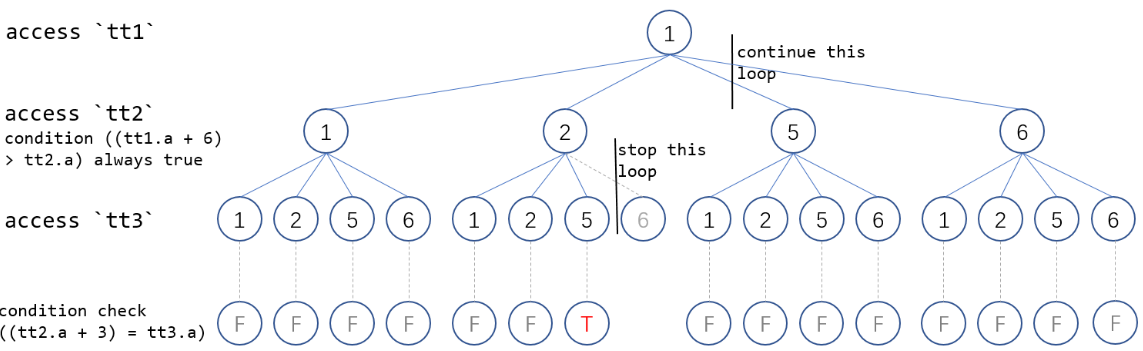
上述例子中,在MySQL 8.0.30社区版本执行器需要扫描60行数据才能获得结果集。找到满足条件的唯一结果{i=1,j=2,k=5}后,不会停止本轮扫描,而是继续扫描{i=1,j=5,k=1}及后续无用的数据,导致执行时间长。详细的执行流程参见下图:
![cke_144.png]()
针对如上的多表连接+DISTINCT执行效率慢的问题,GaussDB(for MySQL)在火山模型的执行器上实现了提前减枝优化,当找到满足的条件的DISTINCT值之后,通过全局变量判断是否可以提前结束本轮迭代,并层层退出,大幅减少了扫描工作量。
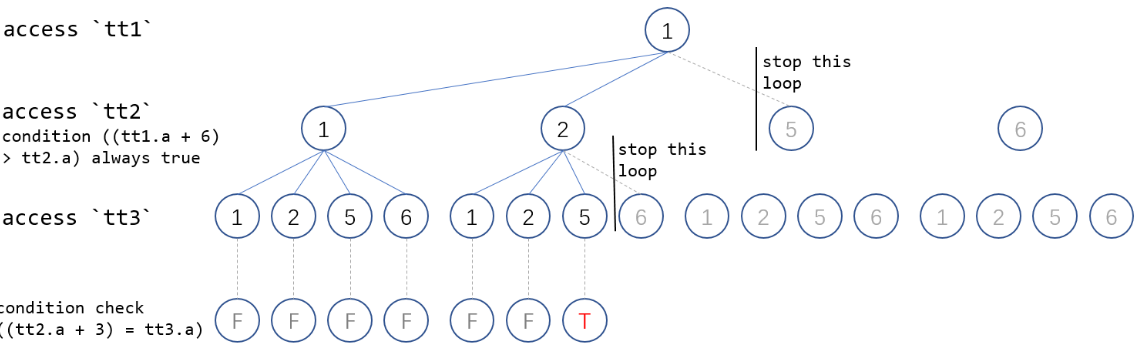
以上述SQL为例,在扫描{1,1,1},{1,1,2},{1,1,5},{1,1,8},{1,2,1},{1,2,2},{1,2,5} 7组数据后,找到满足DISTINCT 条件值 tt1.a "1",立即结束本轮迭代,并停止上一层迭代。该例子中只需要扫描28行数据就可获得最终结果集,相比MySQL 8.0社区版本扫描60行,GaussDB(for MySQL)性能显著提升。
![cke_145.png]()
GaussDB(for MySQL)剪枝特性使用方法
打开特性开关:SET rds_nlj_distinct_optimize=ON;
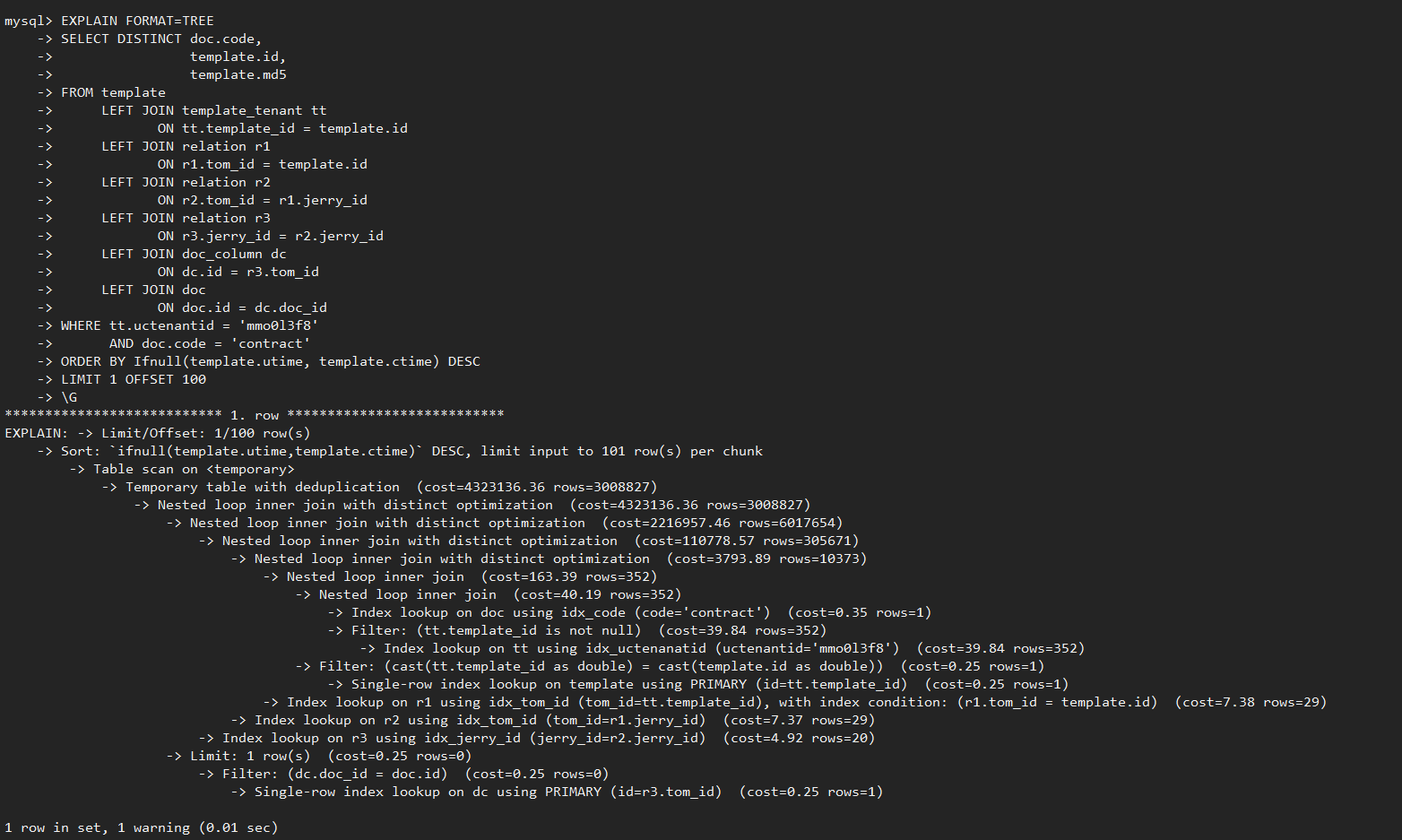
通过”EXPLAIN FORMAT=TREE”查看特性是否生效,执行计划中出现” join with distinct optimization”关键字说明特性生效,查询过程中可进行减枝优化,提升多表JOIN+DISTINCT执行效率。
![cke_146.png]()
![cke_147.png]()
GaussDB(for MySQL)剪枝典型场景测试对比
前面提到的测试样例中,GaussDB(for MySQL)执行耗时2.7秒完成,只需要扫描数据量约61万行;相比MySQL 8.0 社区版本执行耗时约186秒,扫描数据量4400万,执行耗时和扫描数据量减少近70倍,实现了执行效率飞跃式提升。如下图所示:
![cke_148.png]()
![cke_149.png]()
因此,针对“多表连接+DISTINCT”的场景,GaussDB(for MySQL)在执行过程中动态剪枝,裁剪掉大量无用数据,减少执行过程中扫描数据量,是提升查询效率的秘密武器。
总结:
以上通过对GaussDB(for MySQL)剪枝方案、剪枝特性使用方法、典型场景测试对比结果的详细呈现,剖析了“多表连接+DISTINCT”场景中,GaussDB(for MySQL)大幅提升查询效率的原因。如果对华为云GaussDB(for MySQL)更多功能感兴趣的话,可以查看官方产品文档,了解更多:https://support.huaweicloud.com/gaussdbformysql/index.html
点击关注,第一时间了解华为云新鲜技术~