
简单一招竟把nginx服务器性能提升50倍
需求背景
接到重点业务需求要分轮次展示数据,预估最高承接 9w 的 QPS,作为后端工程师下意识的就是把接口写好,分级缓存、机器扩容、线程拉满等等一系列连招准备,再因为数据更新频次两只手都数得过来,我们采取了最稳妥的处理方式,直接生成静态文件拿 CDN 抗量
架构流程大致如下所示:
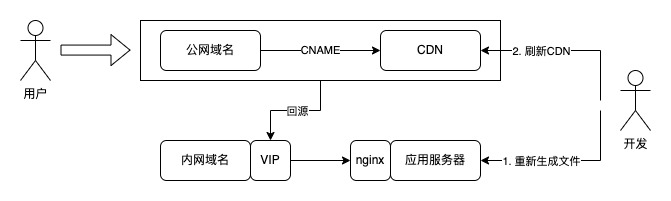
数据更新后会重新生成新一轮次的文件,刷新 CDN 的时候会触发大量回源请求,应用服务器极端情况得 hold 住这 9w 的 QPS
第一次压测
双机房一共 40 台 4C 的机器,25KB 数据文件,5w 的 QPS 直接把 CPU 打到 90%
这明显不符合业务需求啊,咋办?先无脑加机器试试呗
就在这时测试同学反馈压测的数据不对,最后一轮文件最大会有 125KB,雪上加霜
于是乎文件替换,机器数量整体翻一倍扩到 80 台,服务端 CPU 依然是瓶颈,QPS 加不上去了
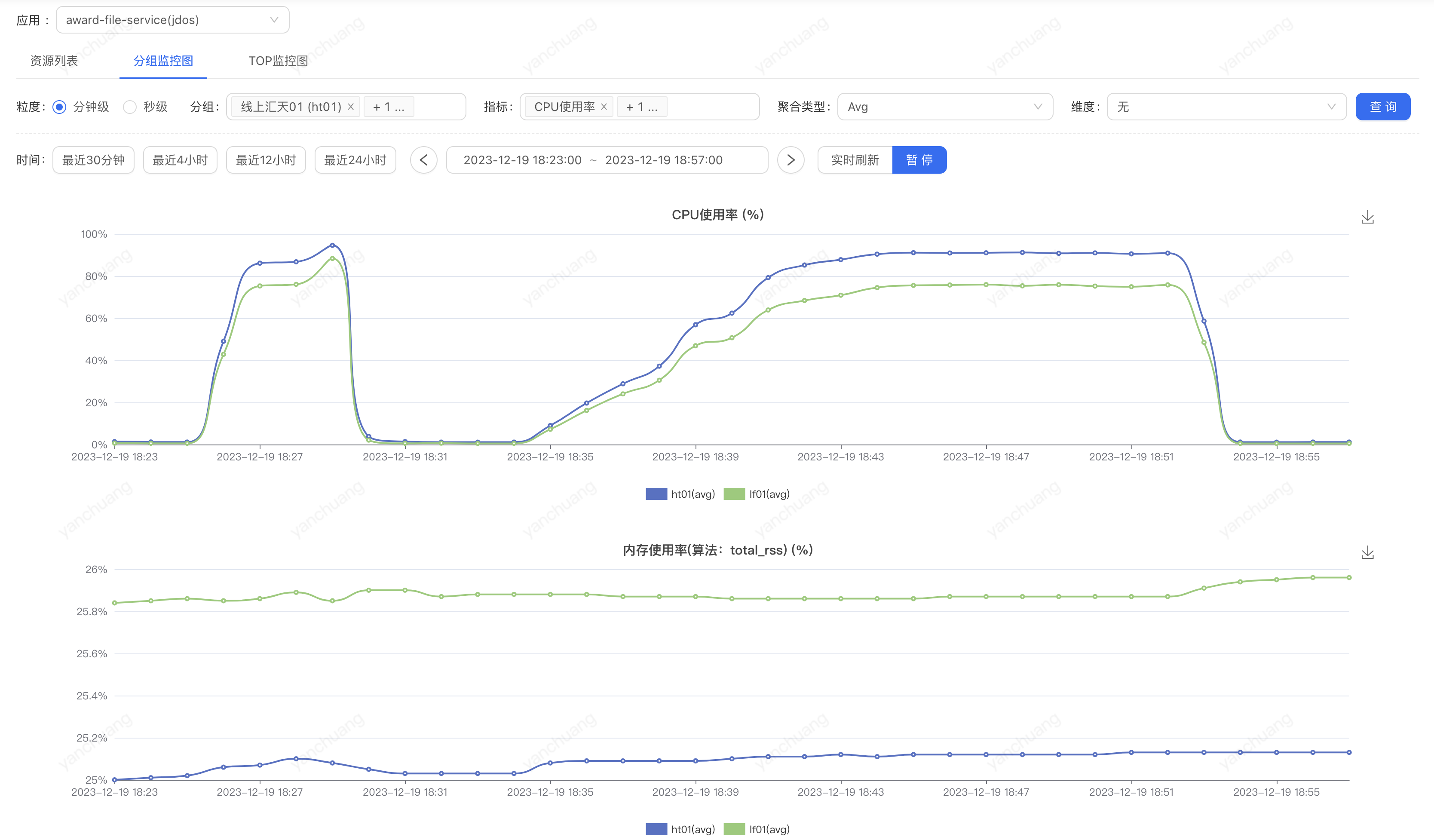
到底是哪里在消耗 CPU 资源呢,整体架构已经简单到不能再简单了
这时候我们注意到为了节省网络带宽 nginx 开启了 gzip 压缩,是不是这小子搞的鬼
server { listen 80; gzip on; gzip_disable "msie6"; gzip_vary on; gzip_proxied any; gzip_comp_level 6; gzip_buffers 16 8k; gzip_http_version 1.1; gzip_types text/plain application/css text/css application/xml text/javascript application/javascript application/x-javascript; ...... } 第二次压测
为了验证这个猜想,我们把 nginx 中的 gzip 压缩率从 6 调成 2,以减少 CPU 的计算量
gzip_comp_level 2;
这轮压下来 CPU 还是很快被打满,但 QPS 勉强能达到 9w,坐实了确实是 gzip 在耗 CPU
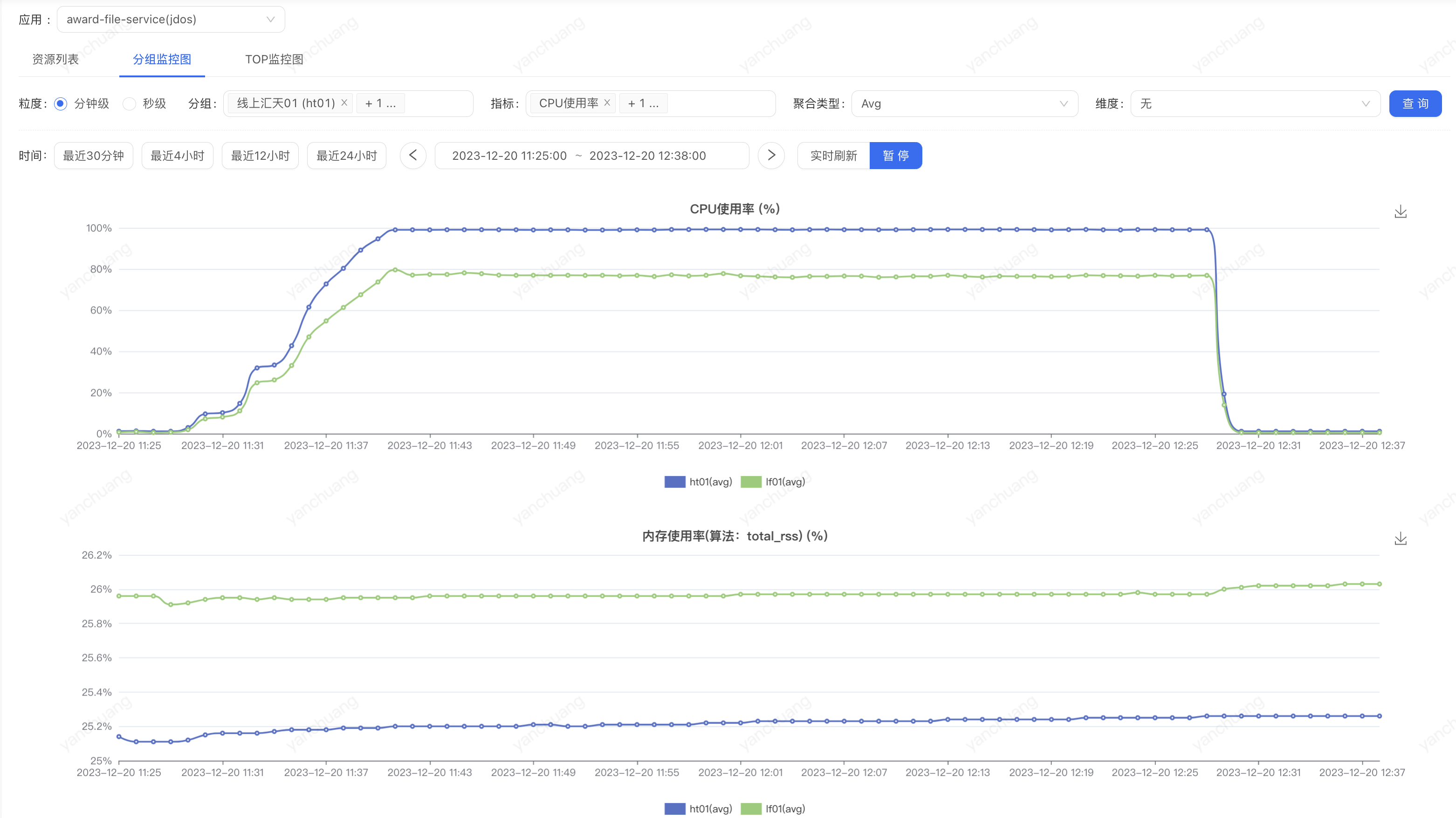
nginx 作为家喻户晓的 web 服务器,以高性能高并发著称,区区一个静态数据文件就把应用服务器压的这么高,一定是哪里不对
第三次压测
明确了 gzip 在耗 CPU 之后我们潜下心来查阅了相关资料,发现了一丝进展
html/css/js 等静态文件通常包含大量空格、标签等重复字符,重复出现的部分使用「距离加长度」表达可以减少字符数,进而大幅降低带宽,这就是 gzip 无损压缩的基本原理
作为一种端到端的压缩技术,gzip 约定文件在服务端压缩完成,传输中保持不变,直到抵达客户端。这不妥妥的理论依据嘛~
nginx 中的 gzip 压缩分为动态压缩和静态压缩两种
•动态压缩
服务器给客户端返回响应时,消耗自身的资源进行实时压缩,保证客户端拿到 gzip 格式的文件
这个模块是默认编译的,详情可以查看 https://nginx.org/en/docs/http/ngx_http_gzip_module.html
•静态压缩
直接将预先压缩过的 .gz 文件返回给客户端,不再实时压缩文件,如果找不到 .gz 文件,会使用对应的原始文件
这个模块需要单独编译,详情可以查看 https://nginx.org/en/docs/http/ngx_http_gzip_static_module.html
如果开启了 gzip_static always,而且客户端不支持 gzip,还可以在服务端加装 gunzip 来帮助客户端解压,这里我们就不需要了
查了一下 jdos 自带的 nginx 已经编译了 ngx_http_gzip_static_module,省去了重新编译的麻烦事
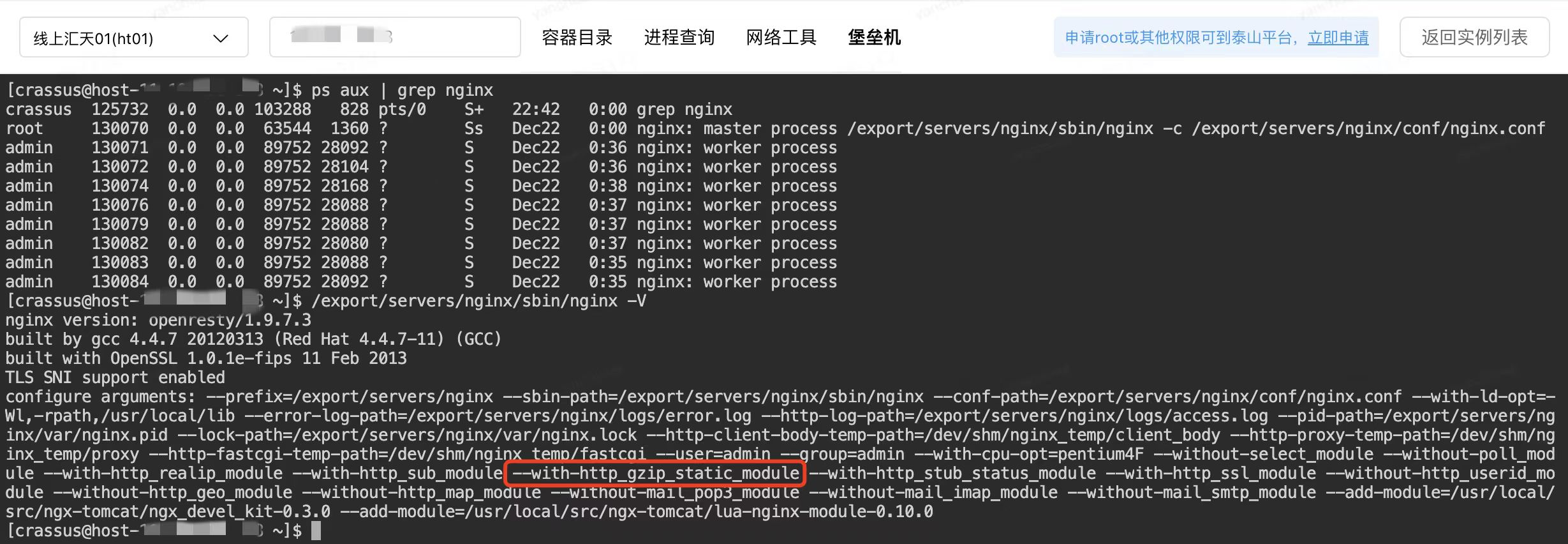
接下来通过 GZIPOutputStream 在本地额外生成一个 .gz 的文件,nginx 配置上静态压缩再来一次
gzip_static on;
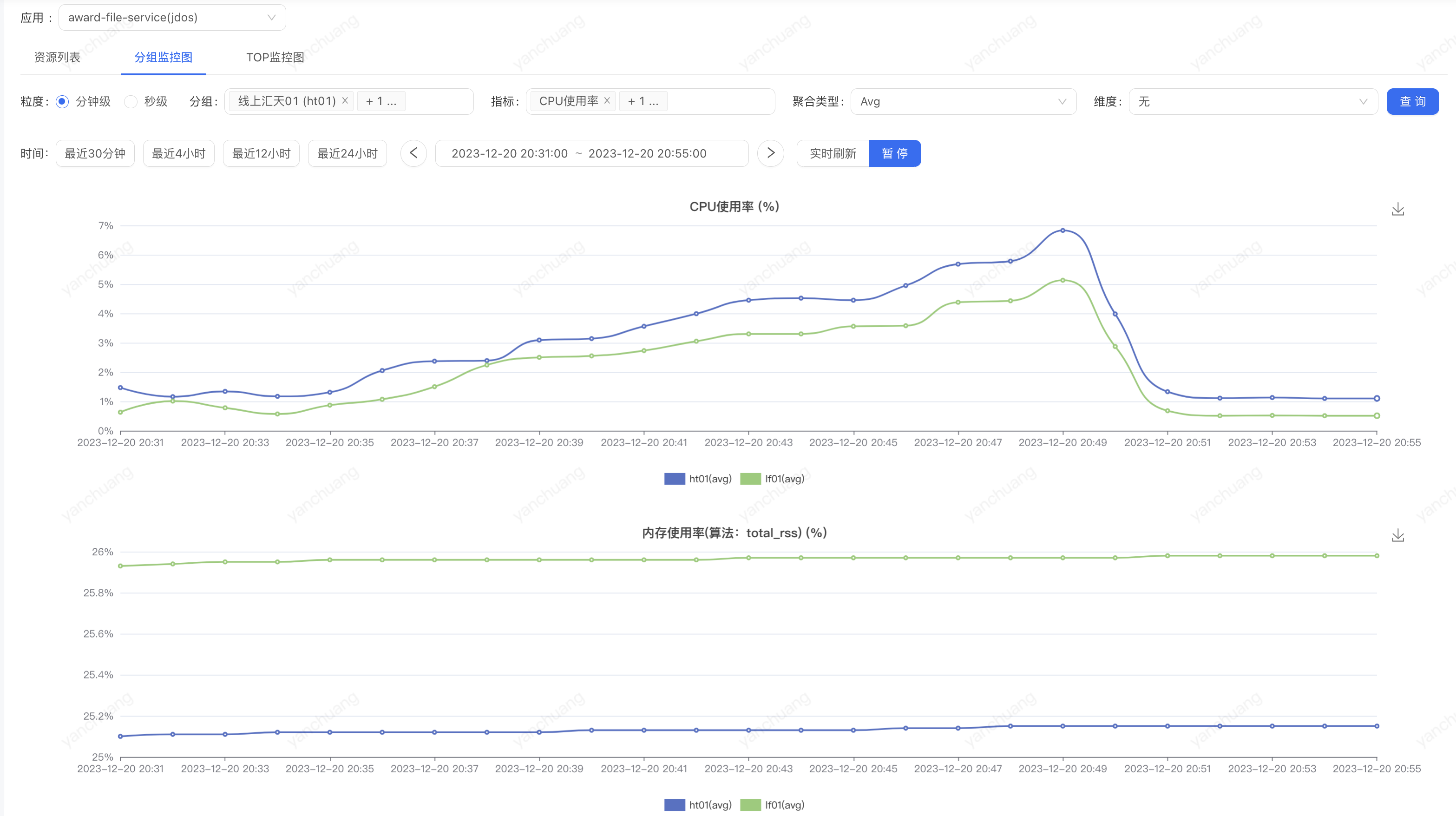
面对 9w 的QPS,40 台机器只用了 7% 的 CPU 使用率完美扛下
为了探底继续加压,应用服务器 CPU 增长缓慢,直到网络流出速率被拉到了 89MB/s,担心影响宿主机其他容器停止压力,此时 QPS 已经来到 27w
qps 5w->27w 提升 5 倍,CPU 90%->7% 降低 10 倍,整体性能翻了 50 倍不止,这回舒服了~
写在最后
经过一连串的分析实践,似乎静态压缩存在“压倒性”优势,那什么场景适合动态压缩,什么场景适合静态压缩呢?一番探讨后得出以下结论
纯静态不会变化的文件适合静态压缩,提前使用gzip压缩好避免CPU和带宽的浪费。动态压缩适合API接口返回给前端数据这种动态的场景,数据会发生变化,这时候就需要nginx根据返回内容动态压缩,以节省服务器带宽
作为一名后端工程师,nginx 是我们的老相识了,抬头不见低头见。日常工作中配一配转发规则,查一查 header 设置,基本都是把 nginx 作为反向代理使用。这次是直接访问静态资源,调整过程的一系列优化加深了我们对 gzip 的动态压缩和静态压缩的基本认识,这在 NG 老炮儿眼里显得微不足道,但对于我们来说却是一次难得的技能拓展机会
在之前的职业生涯里,我们一直聚焦于业务架构设计与开发,对性能的优化似乎已经形成思维惯性。面对大数据量长事务请求,减少循环变批量,增大并发,增加缓存,实在不行走异步任务解决,一般瓶颈都出现在 I/O 层面,毕竟磁盘慢嘛,减少与数据库的交互次数往往就有效果,其他大概率不是问题。这回有点儿不一样,CPU 被打起来的原因就是出现了大量数据计算,在高并发请求前,任何一个环节都可能产生性能问题
作者:京东零售 闫创
来源:京东云开发者社区 转载请注明来源
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

探索图像检索:从理论到实战的应用
本文深入探讨了图像检索技术及其在主流APP中的应用,涵盖了特征提取、相似度计算、索引技术,以及在电商、社交媒体和云服务中的实际应用案例。 关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人 一、引言 在当今数字化时代,图像成为了最直观、最丰富的信息载体之一。从社交媒体到电子商务平台,从云存储服务到内容发现应用,图像内容无处不在,它们的快速增长与管理已成为当代科技领域的一大挑战。在这个背景下,图像检索技术的发展与应用变得尤为重要。图像检索,即通过特定图像或图像特征,在大型数据库中查找并获取相关图像的技术,已成为智能信息检索领域的核心组成部分。 与传统的文本检索相比,图像检索面临着更多的挑战。图像的高维特性和视觉内容的多样性使得从海量图像数据中快速准确地提取信息成为一项复杂任务。这不仅要求算法能够处理高维数据,还需要具备理解图像内容和上下文的能力。为应对这些挑战,近年来,深度学习技术在图像检索领域的应用迅速发展。尤其是卷积神经网...
- 下一篇
GaussDB(for MySQL)剪枝功能,让查询性能提升70倍!
作者,祝青平,华为云数据库内核高级工程师。 擅长数据库优化器内核研发,9年数据库内核研发经验,参与多个TP以及AP数据库的研发工作。 近日,华为云数据库社区下面有这样一条用户提问留言:请问,如何通过MySQL提升DISTINCT,尤其是多表连接下DISTINCT的查询效率? 在回答这个问题之前,我们先了解一下DISTINCT。 在SQL语句中,DISTINCT关键词用于返回唯一不同的值,使用场景多,应用频繁。它可以用于做单列数据去重,例如,对公司雇员按照”first_name”去重后,得到1275条记录。 也可以做多列去重,即只有所有指定列的信息都相同时,才会被认为是重复的信息,例如,对公司雇员按照”first_name”和”gender”两列去重后得到2550条记录。 对于“多表连接+DISTINCT”场景,MySQL 8.0需要扫描表连接后的结果。当表连接数量多或基表数据量大时,扫描的数据量也会很大,会导致执行效率很低。如下示例,对7个表连接后的结果做DISTINCT,使用MySQL 8.0.30社区版本,执行耗时186秒,通过查看慢日志信息,发现扫描了约4400万行数据。 为了提...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- CentOS7设置SWAP分区,小内存服务器的救世主
- Docker快速安装Oracle11G,搭建oracle11g学习环境
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- Eclipse初始化配置,告别卡顿、闪退、编译时间过长
- CentOS7安装Docker,走上虚拟化容器引擎之路
- CentOS8安装MyCat,轻松搞定数据库的读写分离、垂直分库、水平分库
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- 设置Eclipse缩进为4个空格,增强代码规范
- SpringBoot2全家桶,快速入门学习开发网站教程
 微信收款码
微信收款码 支付宝收款码
支付宝收款码