事务的隔离级别
当数据库里有多个事务同时执行的时候,就可能会出现,幻读,脏读,不可重复读的问题,为了解决这些问题,就出现了隔离级别的概念。
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
串行:我的事务尚未提交,别人就别想改数据。
这4种隔离级别,并行性能依次降低,安全性依次提高。
我们重点说下读提交和可重复读
mysql> create table T(c int) engine=InnoDB;
insert into T(c) values(1);
![]()
我们看下在不同的隔离级别下,每个查询得到的值是多少
- 读未提交:V1=2,V2=2,V3=2,因为是读未提交,所以事务B的修改V1可以看见,所以V1的值就是2,V2,V3的值肯定也是2
- 读提交:V1=1,V2=2,V3=2,因为是读提交,数据的更新只有在事务提交以后才可以被其他事务看见,在进行V1查询的时候,事务B还没提交,所以这个时候V1的值还是1,但是V2的查询是在事务B提交以后查询的,所以V2的值就是2,V3的值也是2
- 可重复读:V1=1,V2=1,V3=2,因为是可重复读,所以A事务中的查询出的数据在事务之间从头到尾都是一样的,事务A在启动的时候查询出来的值是1,所以V1和V2的值都是1,V3是在事务A提交以后进行的查询,这个时候事务B也提交了,所以查询的值V3就是2,当然在这里的事务A中的查询V1和V2用的是"快照读",所以值都是1,如果用的是当前读,比如说select c from t for update,这个时候V1的值就是2,这是什么意思呢?就是说当你是单纯的读的时候给你查询出来的值是事务一开始的数据的值,但是当你需要修改的时候,也就是当前读的时候,就需要给你最新的数据版本的值,你需要在最新版本上的数据上进行修改
- 串行化:这个隔离级别下,事务B在执行“将1改成2”这个操作时,会被锁住,要一直等到事务A提交后才可以执行,所以这个时候对于事务A来说V1,V2的值都是1,V3的值是2
是实现上,数据库会创建一个视图,这里的视图不是sql语句的那个视图,在可重复读隔离级别下,会在事务启动的时候创建一个整库数据的视图,访问的时候以这个视图里面的数据为准,读提交下会在执行一个查询语句的时候,创建这个视图,读未提交下,会直接返回最新的数据,串行化直接用加锁的方法,避免了并行,所以这两个事务没有视图的概念。
事务隔离的实现
理解了事务隔离的概念,接下来我们看看事务隔离是如何实现的,这里我们展开说明可重复读
![]()
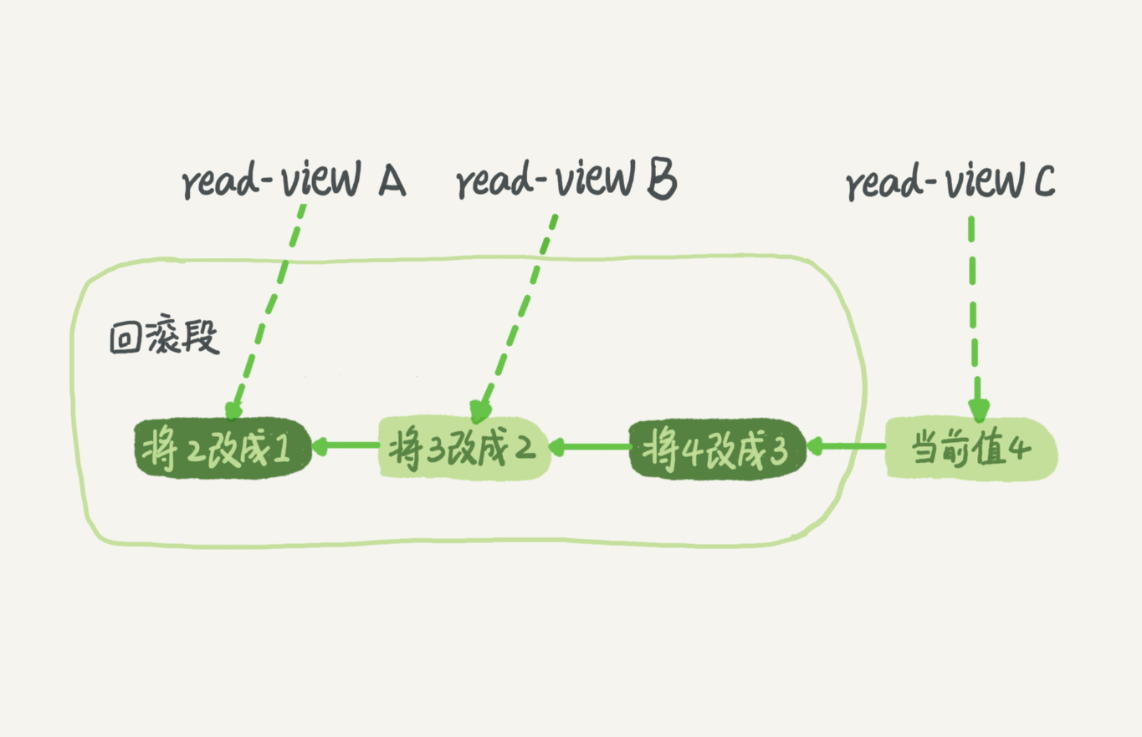
在mysql中每进行一个变更操作都会记录一条日志,不同的视图在同一时刻看到的值是不一样的,视图A,B,C看到的值分别是1,2,4,这就是数据库的数据多版本控制(MVCC),也就是说这个时候,如果视图C,想要把值改成2,那么就要依次执行将4改成3,将3改成2,这两个操作。
那么这些回滚日志在什么时候会被删除呢?就是当系统里没有比这个回滚日志更早的视图的时候。
接下来我们说说为什么数据库里尽量不要有长事务,当有一个长事务时,意味着系统里会存在很老的视图,所以这个事务提交之前,数据库里他所有可能用到的回滚记录到必须保留。
举个例子吧:
比如,在某个时刻(今天上午9:00)开启了一个事务A(对于可重复读隔离级别,此时一个视图read-view A也创建了),这是一个很长的事务……
事务A在今天上午9:20的时候,查询了一个记录R1的一个字段f1的值为1……
今天上午9:25的时候,一个事务B(随之而来的read-view B)也被开启了,它更新了R1.f1的值为2(同时也创建了一个由2到1的回滚日志),这是一个短事务,事务随后就被commit了。
今天上午9:30的时候,一个事务C(随之而来的read-view C)也被开启了,它更新了R1.f1的值为3(同时也创建了一个由3到2的回滚日志),这是一个短事务,事务随后就被commit了。
……
到了下午3:00了,长事务A还没有commit,为了保证事务在执行期间看到的数据在前后必须是一致的,那些老的事务视图、回滚日志就必须存在了,这就占用了大量的存储空间。
源于此,我们应该尽量不要使用长事务。
事务的启动方式
如上所述长事务有这些潜在风险,所以要尽量避免长事务,其实很多时候我们都是误用导致了长事务。
MySQL的事务启动方式有以下几种
- 显式启动,begin或start transaction,对应的语句是commit,回滚语句是rollback
- set autocommit = 0,这个命令会将这个线程的自动提交关闭,意味着如果你只执行一个select语句,这个事务就启动了,而且并不会自动提交,这个事务持续存在直到你执行commit或rollback语句,或者断开连接
有些客户端框架会默认连接成功后,执行一个set autocommit = 0命令,这就导致接下来的查询都在事务中,如果是长连接就导致了长事务。
你可以在informationschema库的innodb_trx表中查询长事务,比如这个语句聚会查询出持续时间超过60s的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60