一、前言 SQL是用于访问和处理数据库的标准计算机语言。GaussDB支持SQL标准(默认支持SQL2、SQL3和SQL4的主要特性)。
本系列将以《云数据库GaussDB—SQL参考》在线文档为主线进行介绍。
欢迎使用GaussDB数据库数组表达式。在本文中,我们将介绍GaussDB数据库中数组表达式的概念、语法和用法。GaussDB是一种高性能、高可扩展的分布式数据库,广泛应用于各种业务场景。数组表达式是GaussDB数据库中的一种强大功能,它允许用户在数据库查询中使用数组操作符和函数来处理数组类型的数据。通过学习本文,您将了解如何使用GaussDB数据库的数组表达式来简化数据处理流程,提高查询效率,从而更好地满足业务需求。
二、条件表达式的概念及GaussDB中的常见的数组表达式 GaussDB支持SQL语言以及一些扩展功能。在GaussDB中,数组表达式用于处理数组类型的数据。以下是一些常见的数组表达式:
1、IN :expression IN (value [, ...]) ![]()
使用IN运算符可以判断一个数组是否包含在一个给定的值列表中。如果数组包含所有在括号中指定的值,则返回true;否则返回false。
2、NOT IN :expression NOT IN (value [, ...])
![]()
使用NOT IN运算符可以判断一个数组是否不包含在一个给定的值列表中。如果数组不包含任何在括号中指定的值,则返回true;否则返回false。
3、ANY(array):expression operator ANY (array expression) ![]()
ANY运算符用于判断一个数组是否满足给定数组中的任何一个条件。其中,operator是比较运算符,如=、<、>等。如果左侧的数组满足右侧数组中的任何一个条件,则返回true;否则返回false。
4、SOME (array) :expression operator SOME (array expression) ![]()
SOME运算符用于判断一个数组是否满足给定数组中的至少一个条件。其中,operator是比较运算符,如=、<、>等。如果左侧的数组满足右侧数组中的至少一个条件,则返回true;否则返回false。 需要注意的是,SOME在GaussDB中的用法与ANY相同,因此上述例子同样适用于SOME。
5、ALL (array) :expression operator ALL (array expression)
![]()
ALL运算符用于判断一个数组是否满足给定数组中的所有条件。其中,operator是比较运算符,如=、<、>等。如果左侧的数组满足右侧数组中的所有条件,则返回true;否则返回false。
三、GaussDB中常用的数组表达式(语法 + 示例) 1、expression IN (value [, ...]) 右侧括号中的是一个数组表达式列表。左侧表达式的结果与表达式列表的内容进行比较。如果列表中的内容符合左侧表达式的结果,则IN的结果为true。如果没有相符的结果,则IN的结果为false。
使用in的时候,忽略为null的,不会查询出为null的数据。如果表达式结果为null,或者表达式列表不符合表达式的条件且右侧表达式列表返回结果至少一处为空,则IN的返回结果为null,而不是false。这样的处理方式和SQL返回空值的布尔组合规则是一致的。
示例:基础表:教师表、课程表
![]()
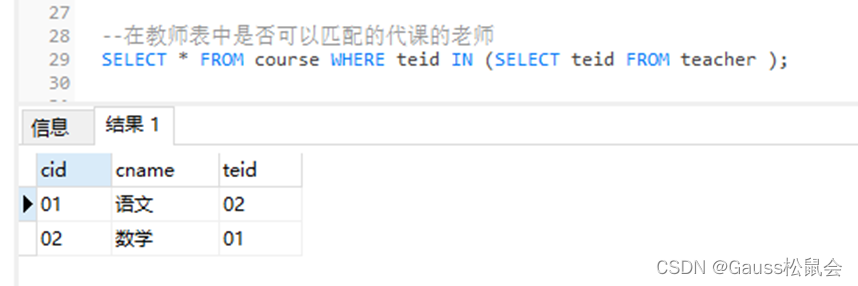
--在教师表中是否可以匹配到代课的老师
SELECT * FROM course WHERE teid IN (SELECT teid FROM teacher );
![]()
2、expression NOT IN (value [, ...]) 右侧括号中的是一个表达式列表。左侧表达式的结果与表达式列表的内容进行比较。如果在列表中的内容没有符合左侧表达式结果的内容,则NOT IN的结果为true。如果有符合的内容,则NOT IN的结果为false。
如果查询语句返回结果为空,或者表达式列表不符合表达式的条件且右侧表达式列表返回结果至少一处为空,则NOT IN的返回结果为null,而不是false。这样的处理方式和SQL返回空值的布尔组合规则是一致的。
示例(基础表course、teacher见上文截图):
--在教师表中是否可以匹配到代课的老师
SELECT * FROM course WHERE teid NOT IN (SELECT teid FROM teacher );
![]()
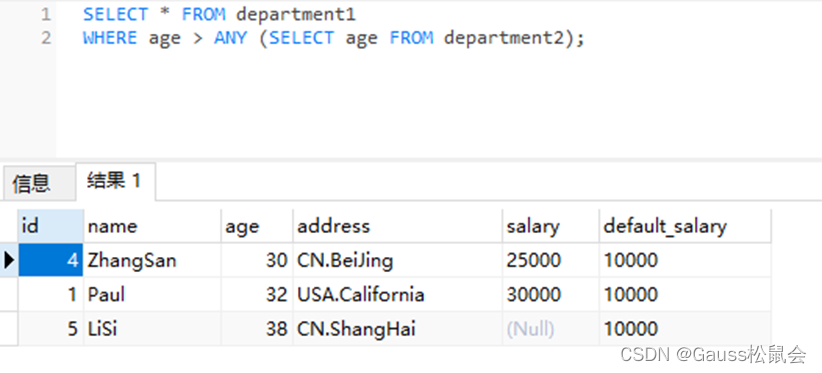
3、expression operator ANY/ SOME (array expression) 右侧括号中的是一个数组表达式,它必须产生一个数组值。左侧表达式的结果使用操作符对数组表达式的每一行结果都进行计算和比较,比较结果必须是布尔值。
如果对比结果至少获取一个真值,则ANY的结果为true。 如果对比结果没有真值,则ANY的结果为false。 如果结果没有真值,并且数组表达式生成至少一个值为null,则ANY的值为NULL,而不是false。这样的处理方式和SQL返回空值的布尔组合规则是一致的。 示例:基础表:部门1、部门2
![]()
![]() --查找部门1的员工年龄大于部门2的员工
--查找部门1的员工年龄大于部门2的员工
SELECT * FROM department1
WHERE age > ANY (SELECT age FROM department2); ![]()
![]()
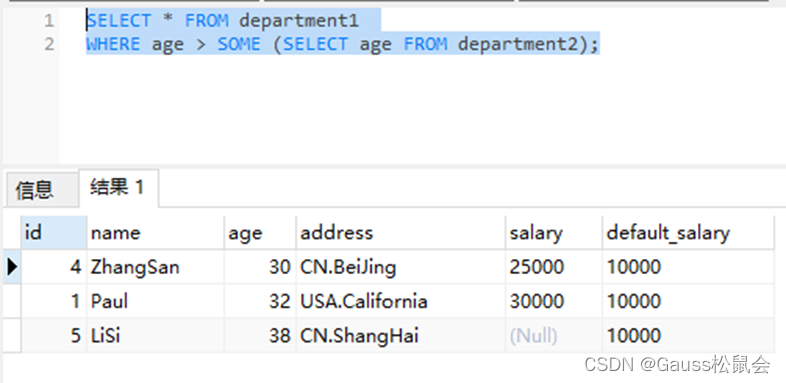
SOME跟ANY 类似:
--查找部门1的员工年龄大于部门2的员工
SELECT * FROM department1
WHERE age > SOME (SELECT age FROM department2);
![]()
补充说明:
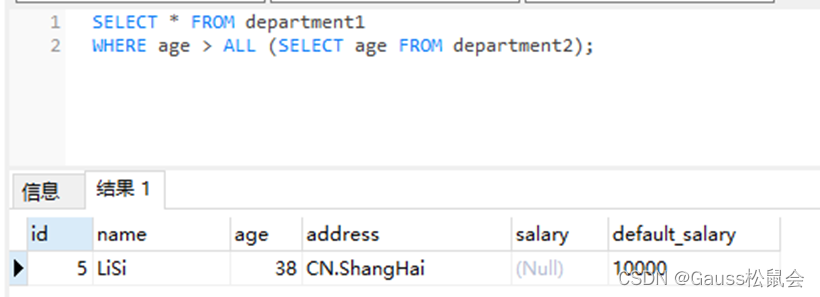
any 大于子查询结果中的某个值 < any 小于子查询结果中的某个值 = any 大于或等于子查询结果中的某个值 <= any 小于或等于子查询结果中的某个值 = any 等于子查询结果中的某个值,相当于IN != any 不等于子查询结果中的某个值 4、expression operator ALL (array expression) 右侧括号中的是一个数组表达式,它必须产生一个数组值。左侧表达式的结果使用操作符对数组表达式的每一行结果都进行计算和比较,比较结果必须是布尔值。
如果所有的比较结果都为真值(包括数组不含任何元素的情况),则ALL的结果为true。 如果存在一个或多个比较结果为假值,则ALL的结果为false。 如果数组表达式产生一个NULL数组,则ALL的结果为NULL。如果左边表达式的值为NULL ,则ALL的结果通常也为NULL(某些不严格的比较操作符可能得到不同的结果)。另外,如果右边的数组表达式中包含null元素并且比较结果没有假值,则ALL的结果将是NULL(某些不严格的比较操作符可能得到不同的结果), 而不是真。这样的处理方式和SQL返回空值的布尔组合规则是一致的。 示例:(基础表department1、department2见上文截图)
SELECT * FROM department1
WHERE age > ALL (SELECT age FROM department2); ![]()
补充说明:
all 大于子查询结果中的所有值 < all 小于子查询结果中的所有值 = all 大于或等于子查询结果中的所有值 <= all 小于或等于子查询结果中的所有值 = all 等于子查询结果中所有值 != all 不等于子查询结果中的任何一个值,相当于NOT IN 四、小结 通过本文的介绍,相信您已经对GaussDB数据库的数组表达式有了深入的了解。数组表达式是GaussDB数据库中非常实用的功能,它可以帮助您更高效地处理数组类型的数据,简化查询语句,提高查询效率。希望本文对您有所帮助。








 --查找部门1的员工年龄大于部门2的员工
--查找部门1的员工年龄大于部门2的员工