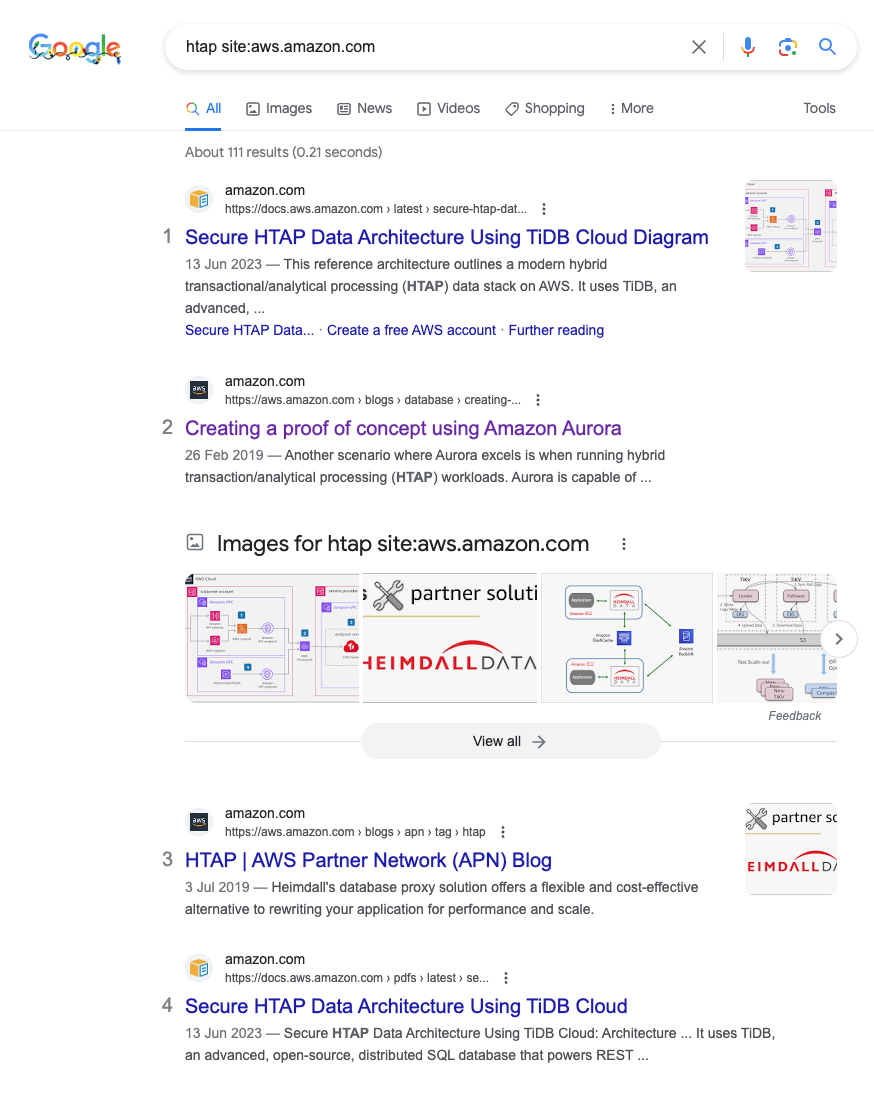
![file]()
在 AWS re:Invent 2023 掌门人 Adam Selipsky 的 Keynote 上,数据库方面最重磅的主题是 Zero-ETL,从 TP 数据库 (RDS, Aurora, DynamoDB) 同步数据到 AP 数据库 (Redshift)。 ![file]()
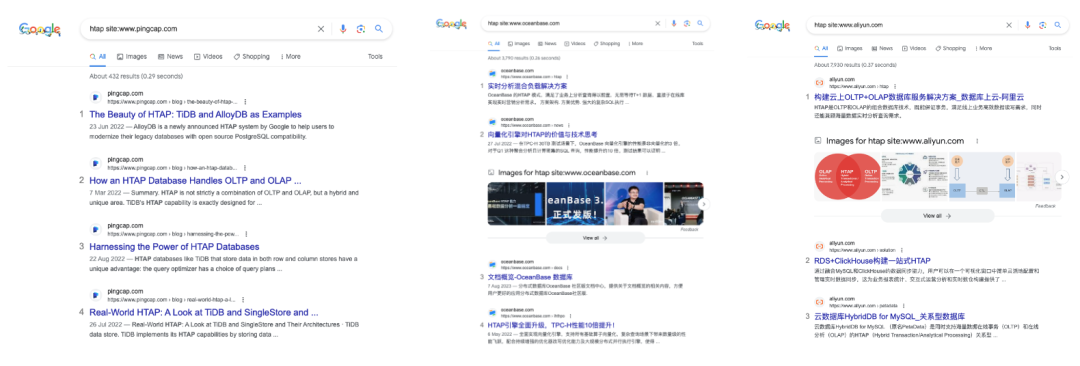
Zero-ETL 是 AWS 在去年 re:invent 2022 上推出的概念,今年则继续增强。这里 AWS 没有选择另一条路线 HTAP (Hybrid Transactional/Analytical Processing)。如果搜索 AWS 官网,反倒是 TiDB 的 HTAP 方案更显眼。 ![file]()
而 TiDB, OceanBase 还是阿里云官网上的 HTAP 内容则要多得多 ![file]()
TiDB 更进一步,还主办了 HTAP Summit ![file]()
AWS HTAP 的不选择
假设 AWS 要讲 HTAP 故事的话,首先会面临一个问题,到底是在 Aurora 里讲,还是在 Redshift 里讲。我们先来看一下 AWS 里数据库产品相关的组织架构。 ![file]()
大主管是 Swami 博士,统管了数据库,大数据以及AI/机器学习 ![file]()
数据库部门负责人 1,主要负责 Aurora + Redshift ![file]()
数据库部门负责人 2,主要负责 RDS + DynamoDB ![file]()
大数据部门负责人 ![file]()
AI / 机器学习部门负责人
Aurora 和 Redshift 两个产品都由同一个 VP 负责。但 Aurora 和 Redshift 都是 AWS 的拳头产品,可能也是 AWS 所有产品线里,综合营收和利润排在前五的两大产品。所以无论把 HTAP 放哪个,可能都会对另一个产生很大负面影响。
另外不仅是对于 Aurora 或者 Redshift 的影响,对于其他数据库产品也会有影响。如果讲了 HTAP,像 RDS, DynamoDB 这两个核心产品,它们同步到数仓的故事该怎么讲呢。
所以,综合下来,AWS 选择推出 zero-ETL 这个概念,打造一个连接器的品牌,这样让所有的数据库产品线都能获益。
TiDB, OceanBase HTAP 的选择
对于像 TiDB, OceanBase 这样的单一数据库厂商,推出一个 all-in-one 的 HTAP 方案也是比较合理的。毕竟手上就一个数据库产品,把它的能力做大做强。 ![file]()
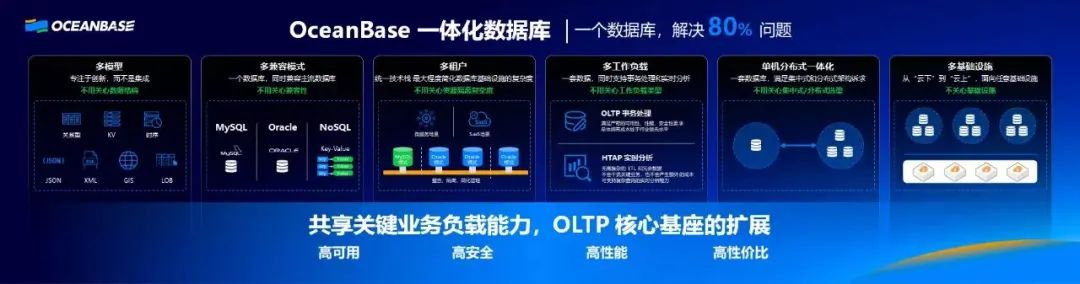
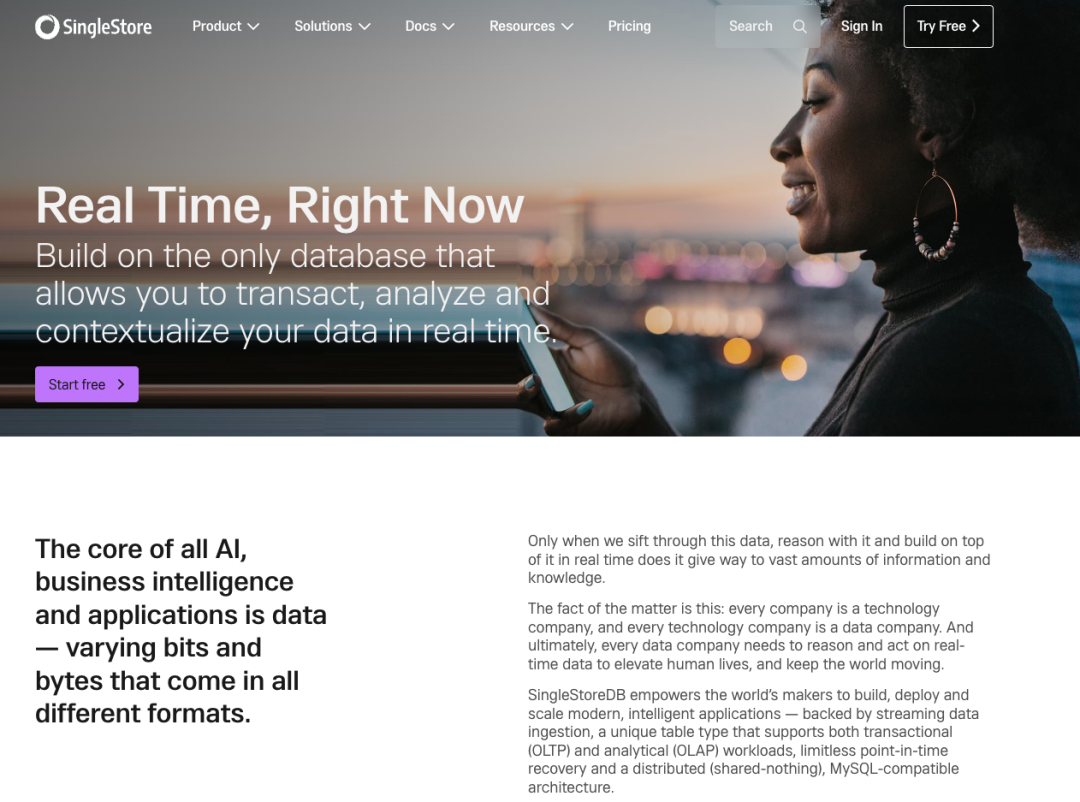
像 OceanBase 在前不久发布会上讲的一体化数据库,一个数据库,解决 80% 问题。国外对标这块的有 SingleStore ![file]()
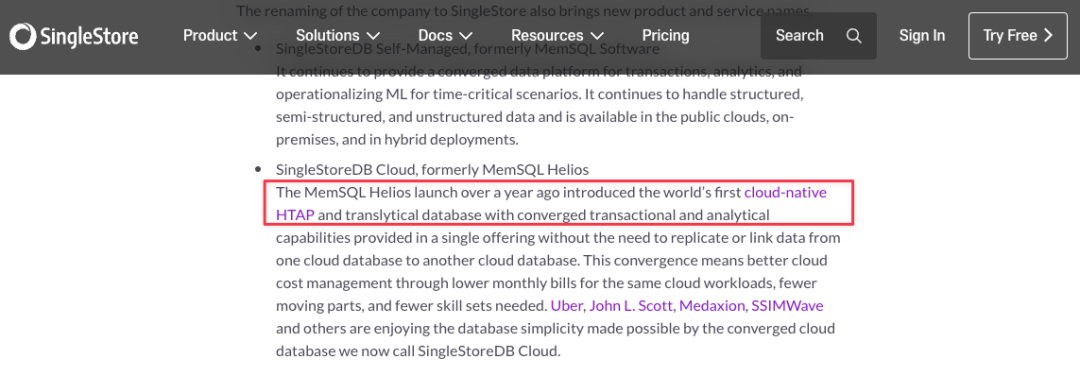
SingleStore 之前的名字叫 MemSQL,2020 年改名的时候号称是全球第一款云原生 HTAP 数据库。 ![file]()
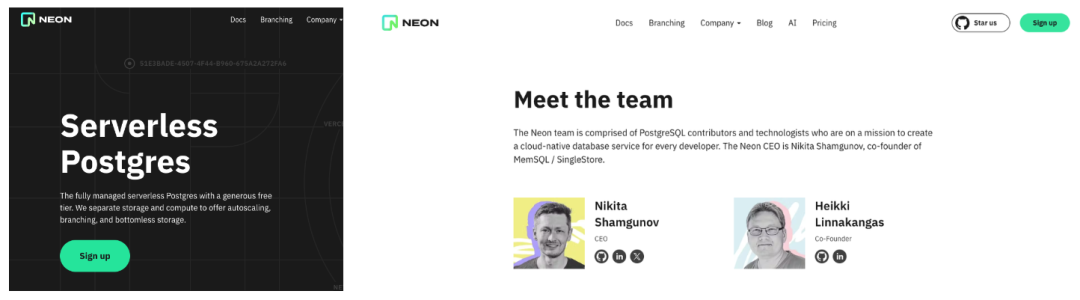
顺便提一嘴,当下很火的数据库 Neon 也是由 SingleStore 的联合创始人/CTO 创立的。 ![file]()
阿里云 HTAP 的选择
阿里云在许多方面都借鉴了 AWS,但在 HTAP 这个点上,看起来是选择了和 AWS 相反的道路。
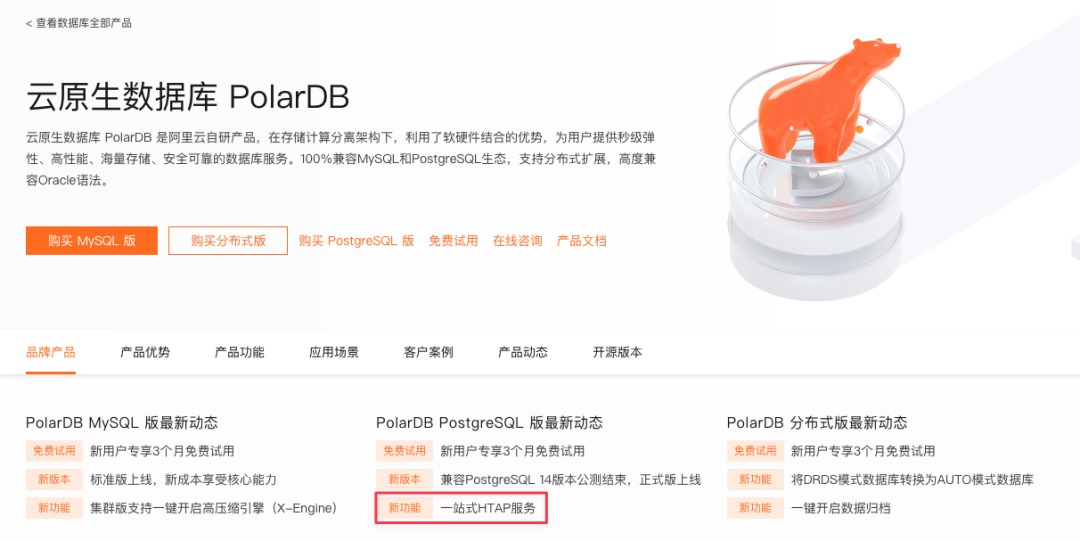
对标 AWS Aurora 的 PolarDB 讲 HTAP ![file]()
对标 AWS Redshift 的 ADB 也讲 HTAP ![file]()
之前还推出过一个 HybridDB,专门讲 HTAP,现在已经下线了。 ![file]()
还有 RDS + ClickHouse 构建一站式 HTAP 的解决方案 ![file]()
南橘北枳
![file]()
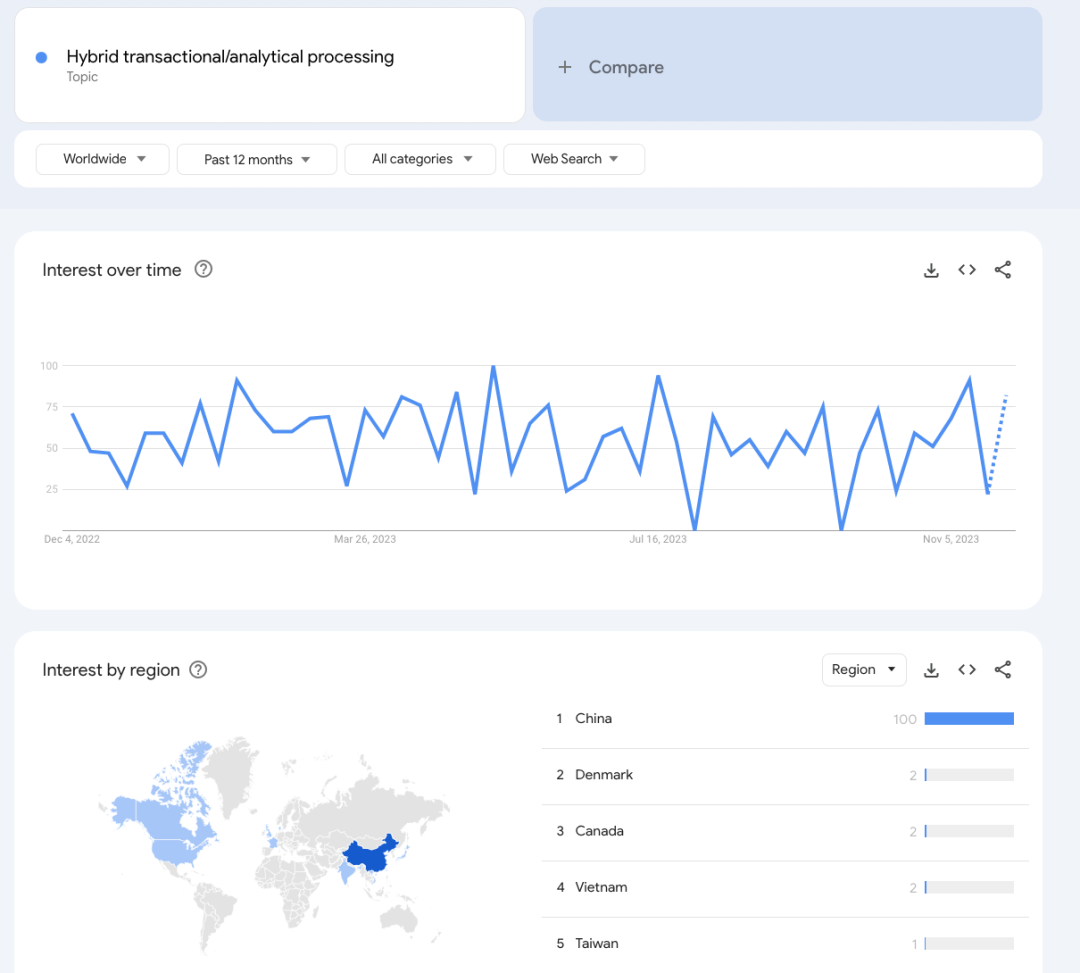
HTAP (Hybrid Transactional/Analytical Processing) 这个概念,其实国内远比国外要流行。可能这也确实和市场有关,国内大家想要一个大而全的东西,而国外大家更喜欢各自做好一块事情,然后连接起来。就像国内的飞书做成了 all-in-one 的庞然大物,国外 Slack 还是专注于 IM,Email/文档有 Google Workspace,HR 则有 Workday。
而即使是底层的数据库系统也不能免俗吧。
💡 更多资讯,请关注 Bytebase 公号:Bytebase