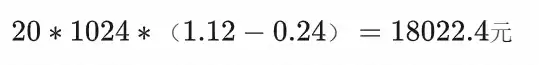背景
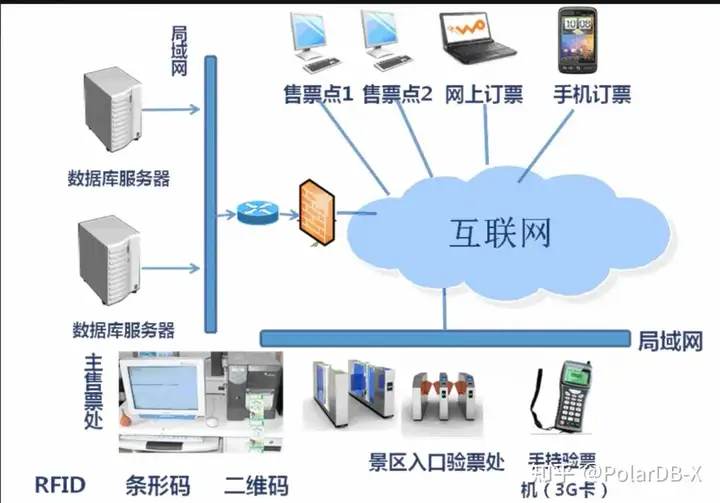
国内某家兼具投资理财、文化旅游、票务为一体的大型综合型集团公司,2015年成立至今,由于业务高速发展,业务数据增长非常快,数据库系统屡次不堪重负。该公司数据库运维总监介绍,他们目前业务压力比较大的是票务和订单系统,他们的平台每天新增几千万的订单数据,订单的数据来自于各个终端,近几年每个月以300G的数据规模在高速增长,由于数据不断增加,数据库系统迄今为止迭代过了3次。
![]()
第一阶段:自建单机MySQL,开始单机MySQL还能满足业务的增长,所有的票务数据都可以放在MySQL数据库里头,但是数据越来越多的时候,我们发现有些单表的数据早已超过2000w,熟悉MySQL的朋友应该知道,表数据超过2000w后,性能变差。数据库变慢,开始我们的业务方还能接受,到后来越来越慢,最终我们只能删数据,删数据后,必须做Optimize Table才会释放空间,每次操作都非常紧张。但后来公司的业务做了升级,要求保留过往所有的票务数据和订单数据,就意味着不能删除老数据了。所以我们在18年年底做了一次数据库系统升级。
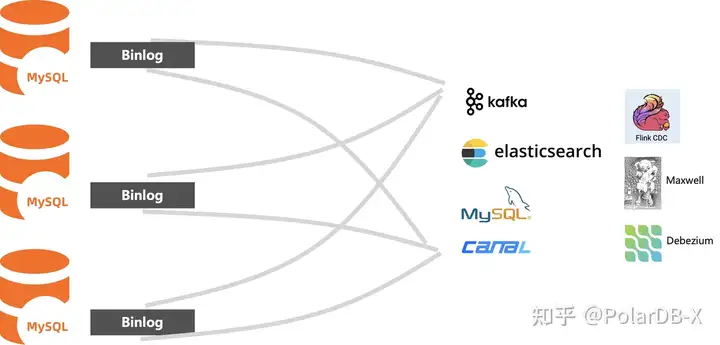
第二阶段:利用开源中间件+MySQL我们自建了一套分库分表的数据库,极大缓解了我们业务增长带来的压力。这套系统在我们线上运行还不错,唯一不足点就是这套数据库系统库没有一套完整的binlog日志,无法直接利用同步工具将数据同步给数仓系统。只能挨个将底下的MySQL做单独的数据同步,到数仓系统。
![]()
这套同步链路比较大的问题就是无法保证分布式事务的完整性,同时在同步过程中还不能做DDL操作。我们公司的业务其实也一直在调整,偶尔需要对表结构做变更的话,业务需要停服,我们挨个对底下的MySQL做表结构的变更,很麻烦。我们在18年-20年业务增长确实很快,到22年底我们的数据已经到达了20几个T了,这样每次做结构变更,业务的停服时间也越来越久了。期间我们还做了两次数据库的扩容,使用过分库分表中间件自建MySQL集群的人都知道,这个扩容相当于再自建一套更大规模的MySQL集群,然后将数据迁移过去,非常麻烦。所以到22年年底,我们就不得不考虑迁移到分布式数据库。
第三阶段:我们当时觉得自建MySQL集群的维护成本已经很高了,当时公司政策也是上云。所以在22年年底我们开始调研业界的分布式数据库,最终我们选型了PolarDB分布式数据库,这套系统经历了多次双11大促,是一套高性能云原生分布式数据库产品。但是我们当时对比了其他云产品,让我们下定决心迁移的主要是看中了以下三点:
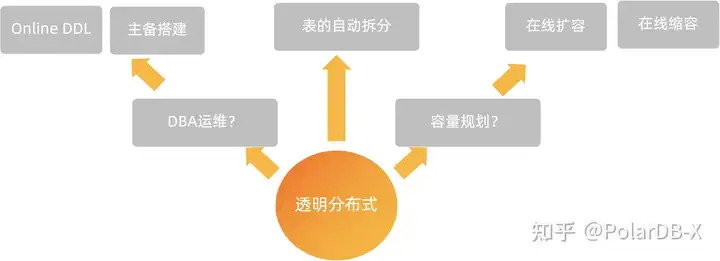
1.透明分布式特性:从连接、开发到管理行为均最大限度保留单机MySQL的使用体验,让用户的分布式改造周期大幅缩短,研发运维团队的原有技术栈最大限度保留。同时也支持Online DDL和在线扩容,在做数据库变更的时候,困扰我们几年的停服也得以解决。
![]()
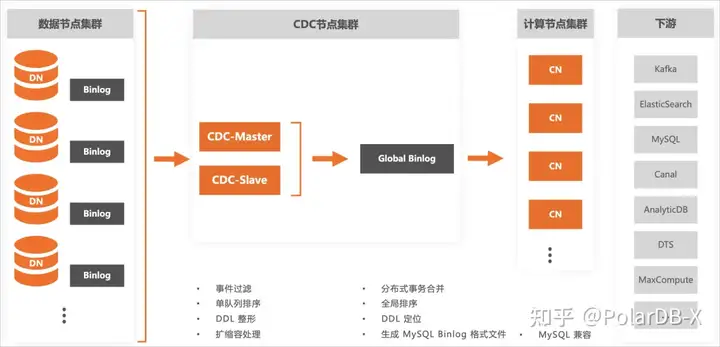
2.全局Binlog能力: PolarDB-X是兼容MySQL生态的分布式数据库。通过实例内PolarDB-X的CDC组件,能够提供与MySQL binlog格式兼容的变更日志,并且对外隐藏了实例扩缩容、分布式事务、全局索引等分布式特性,让您获得与单机MySQL数据库一致的使用体验。这个能力大大降低我们同步的运维成本,兼容MySQL Binlog的协议,让我们无缝对接开源同步工具。
![]()
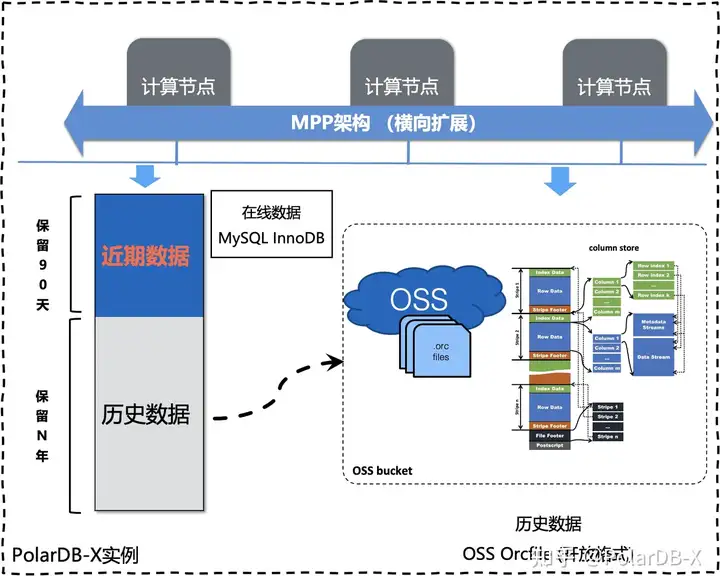
3.冷数据归档能力: PolarDB-X基于OSS存储服务,推出冷热数据分离存储这一新功能。在这一功能的基础上,可以便捷地将冷数据从源表中剥离出来,归档至更低成本的OSS中,形成一张归档表;归档表支持高效的主键与索引点查、复杂分析型查询,满足高可用、MySQL兼容性和任意时间点闪回等特性。您可以像访问MySQL表一样来访问归档表,也可以用开源大数据产品接入OSS的归档数据。
![]()
4.这个特性其实很适用我们这种票务和订单系统的业务,这类业务天然按照时间日期划分为冷热。好比我们公司的业务客户往往会查询最近3个月的订单数据,3个月之前的数据基本不查询,但是这些历史数据都必须保留下来,所以数据会非常大。我们在正式迁移之前,按照下面的表格计算了一笔账:
![]()
5.按照目前的数据规模,我们3个月之前的数据做了下估算,大概是20T。
![]()
这20T的数据可以归档到oss上,光一个月就帮我们节省了近2w的成本,整体的存储成本最高降低了原来的 5% ,所以当时我们非常有动力做这次数据库系统的升级。
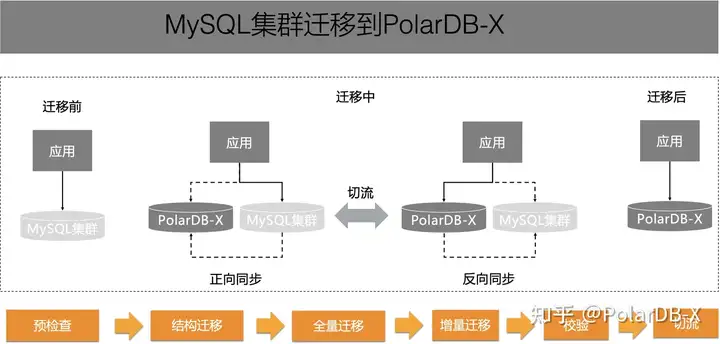
数据迁移与归档
得益于PolarDB-X高度兼容MySQL数据库,其开源开发的能力也充分兼容了MySQL的生态工具,整个过程异常的顺利。我们先做了全量的迁移,再做了增量迁移。前后过程中我们充分做了数据校验,确保数据万无一失,最后做了数据切流。
![]()
我们迁移之前的表结构导入到PolarDB-X其实没有做太大的变化,PolarDB-X的透明分布式提供了表自动按主键拆分的能力,这样我们迁移到PolarDB-X数据库的表默认都是分表,极大满足了我们分布式的分表需求。 但迁移后我们的表并不是TTL表,也无法做冷数据归档,所以我们需要首先将表改造成TTL表,然后将该表做归档表的绑定。
TTL(Time to Live,生存周期)功能,支持在创建表的DDL语句中指定local_partition_definition语法,创建一个TTL表。TTL表会将每个物理表按照时间进行分区,并通过定时任务进行管理,能够让冷数据在PolarDB-X中按照一定的策略归档到OSS 但是遇到的第一个问题是TTL表主键必须包含时间列,那就得先做主键变更,再为将表做TTL的转化。好在PolarDB-X的主键变更是Online的过程,整个过程其实对业务是无感的,只需要做两个DDL操作。
alter table t_orders drop primary key, add primary key(id,gmt_modified);
2. ALTER TABLE t_orders
LOCAL PARTITION BY RANGE (gmt_modified)
STARTWITH '2015-01-01'
INTERVAL 1 MONTH
EXPIRE AFTER 3
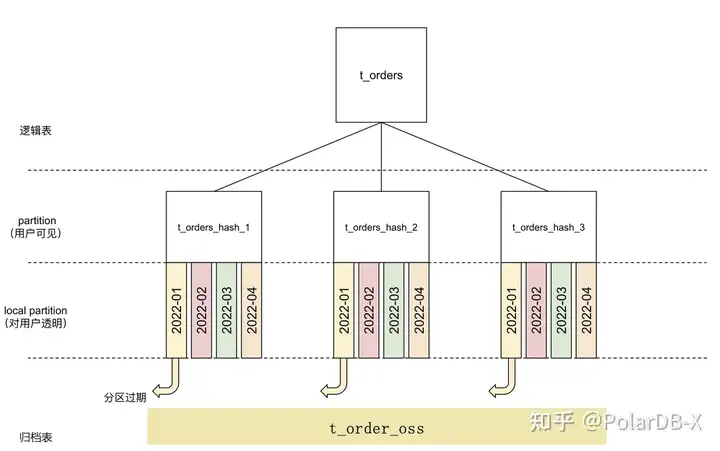
所以我们业务低峰期,做了下TTL表的转化,这部分还算顺利。但是此时的TTL表还不能定时归档,需要绑定到另外一张归档表。绑定过程很简单,如下图所示。
CREATE TABLE t_order_oss LIKE t_orders ENGINE = 'OSS' ARCHIVE_MODE = 'TTL';
将TTL表 t_orders 绑定到另外一张表t_order_oss,两者的表结构一致,这样定时将过期的冷数据从t_order迁移到 t_order_oss。只不过t_order_oss是更低成本的存储介质oss。
![]()
一张表变成了两者不同的表,对我们来说业务有改造成本的。但冷数据和热数据的适用场景和存储介质是不一样的,两者数据访问延迟也是有一定的差异。热数据经常需要高频访问,冷数据对我们来说很少查,也很少做变更。如果两者是一张表,会增加业务异常访问冷数据的风险,影响到了热数据的SLA。区分之后,对热表DDL操作由于数据有限,变更操作会非常友好。出于这样的考虑,我们接受这样的改造,实际证明改造成本也比较低,受益也明显。经过这一波的迁移后,我们热数据通常是指最近3个月的数据,意味着我们需要把过去几年的数据归档到oss上,整个数据量大概是20T。我们配置归档的窗口都是我们的业务低峰期(02:00~-5:00),由于数据量比较多,整个归档持续了1个多月。归档后上线半年,业务感受非常深,由于访问的数据更少了,业务访问性能也提升了。
![]()
可以看到归档前访问的数据量随着时间不断在增加,那么大的数据量添加一个索引都非常困难。而归档后,业务访问的数据量始终维持在1T左右,不再随时间而变化。其实降低的不仅仅是存储成本,之前数据都在数据库,对存储空间和资源要求比较高,我们需要配置比较大的MySQL集群,现在数据大部分迁移到了冷数据上,数据库本身存储的数据其实不多,所以现在数据库资源使用较之前也减少了很多。
冷表的结构变更
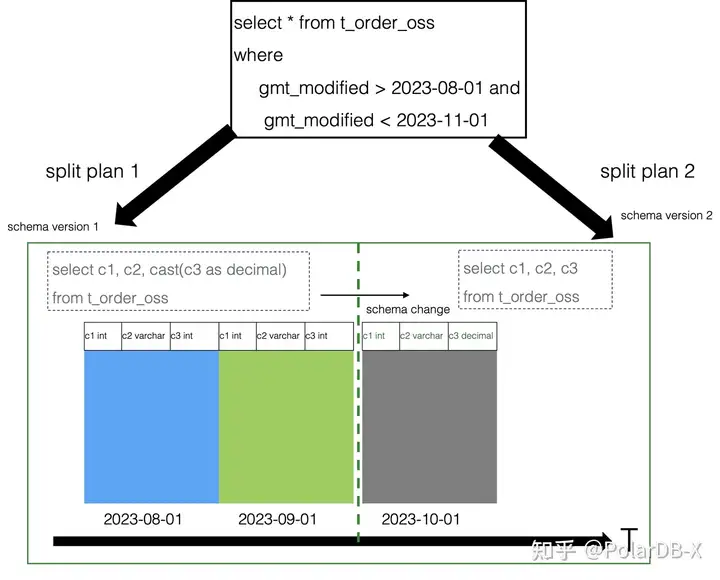
PolarDB-X数据库系统上线后,不管是性能和成本都达到了我们的预期。但是后来我们业务需要对表结构做变更,提示不允许做表结构的变更。由于PolarDB-X冷数据存储介质是对象存储,并且存储格式是ORC。这两者都不能直接对原生数据文件做变更,每次变更都要求对数据进行重写,对于庞大的冷数据数据量,这种方案是无法接受了。好在PolarDB-X第一时间采用了多版本的方案,改写SQL的方式做了支持。这个冷表的DDL过程,不涉及到数据重写过程,每次DDL变更,只是在元数据构建了一个新的版本,元数据层面做好历史数据和元数据版本的映射关系。在查询扫描过程中,做好transform read。这里我们以列类型变更为例:
![]()
对t_order_oss的c3列类型做了变更,从int 类型变成了decimal类型。在修改列类型后,整个过程非常快,不涉及到数据文件的重写。只是在元数据会记录之前的version1和更改后的version2.当用户发起查询的时候,优化器识别数据文件的元数据版本和最终的数据版本。如果查询的数据文件版本和最终的数据版本一致,则数据文件读取的数据不需要做任何project。如果查询的数据文件版本和最终版本有差异,那么数据文件读取的数据需要做project。如上图所示,将一条SQL拆分成了两条执行计划,两条执行计划结果做union all,就是我们的查询结果。这样对DDL本身没有任何代价,只是对查询有代价,考虑到冷数据本身主要查询频率低,对RT延迟要求也低,所以我们觉得这个设计是合理的。基于这套online schema change方案,PolarDB-X数据库对冷表支持了完备的DDL。
冷表的查询加速
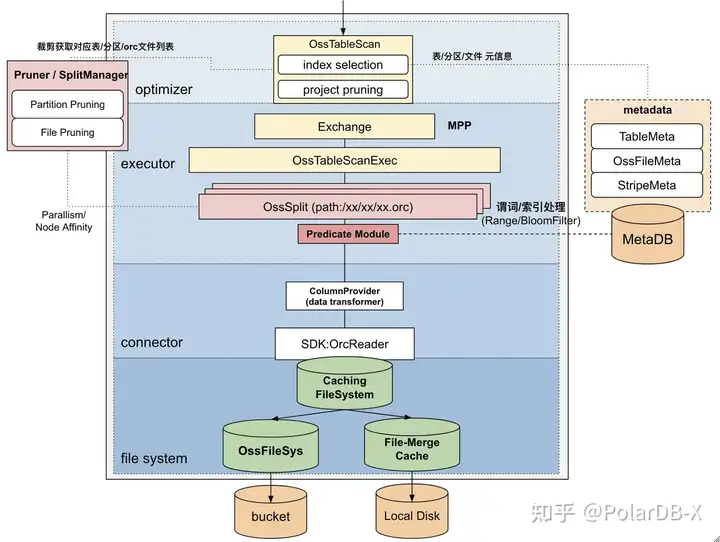
熟悉OSS的朋友都知道,OSS有带宽限制,对于大量的数据扫描并不友好;而且PolarDB-X采用的是列存存储格式(ORC),这种列存格式其实不太适用于TP数据库。虽然我们将冷数据归档到了OSS,但是这块票务系统在对账期间,难免会对冷数据进行大规模扫描或点查。我们开始其实比较担心冷数据归档的查询性能的,但实际效果还是不错的。
![]()
PolarDB-X在查询链路上引入了Local Cache的IO加速技术,并且基于元数据和统计信息构建了多级裁剪技术。
1、表分区级别:通过分区规则裁剪到目标分区
2、RuntimeFilter级别:通过构建MinMaxFilter并下推用于文件裁剪
3、文件级别:通过MinMax统计信息定位到唯一文件
4、Stripe级别:通过MinMax统计信息及BloomFilter定位到唯一Striple
5、RowIndex级别:通过MinMax统计信息及BloomFilter定位到唯一RowGroup
6、列级别:通过列裁剪定位到制定的列做扫描
可以很好的满足我们在冷数据的点查需求,在一些重吞吐的复杂查询中PolarDB-X也引入了Native MPP技术和向量化技术,大大提高了复杂查询的查询效率。
数据库系统迁移的总结
到目前为止,这次数据库系统迁移到PolarDB-X数据库还是很成功的,取得以下四种主要的收益:
1、PolarDB-X提供的透明分布式能力,大大降低我们的使用成本,业务上可以像使用单机MySQL数据库一样使用PolarDB-X。当空间不够的时候,其提供的在线扩容能力,也确保我们后面可以从容面对业务的高速发展;
2、PolarDB-X提供的全局Binlog能力,可以确保我们的业务数据更加方便同步到下游的数仓系统,降低了我们ETL链路的维护成本;
3、存储成本最高降至原来的5%,我们将大部分数据归档到了OSS上,极大的降低的我们的存储成本。由于业务数据量访问减少,数据库本身的规格也减少了,数据库部署成本也降低。PolarDB-X对冷表提供的Online Schema Change和查询加速的技术,也满足了我们业务需求。
4、PolarDB-X支持对冷数据对备份恢复,对,你没听错。PolarDB-X也支持对带有冷数据的实例做数据库备份,这种InnoDB+OSS一体化备份能力,是其他产品不具备的。这个也是我们后期在生产中比较看重的点。
但是该吐槽还得吐槽。目前冷数据归档的表要求主键必须包含时间列,也分区必须按照时间分区,过期粒度是分区级别。这些都限制了用户的使用。不过PolarDB-X数据库马上就要发布新的冷数据归档的解决方案,新的方案听说去除了主键必须包含时间列的限制,且支持行级的归档需求,那我们拭目以待吧!
原文链接
本文为阿里云原创内容,未经允许不得转载。