
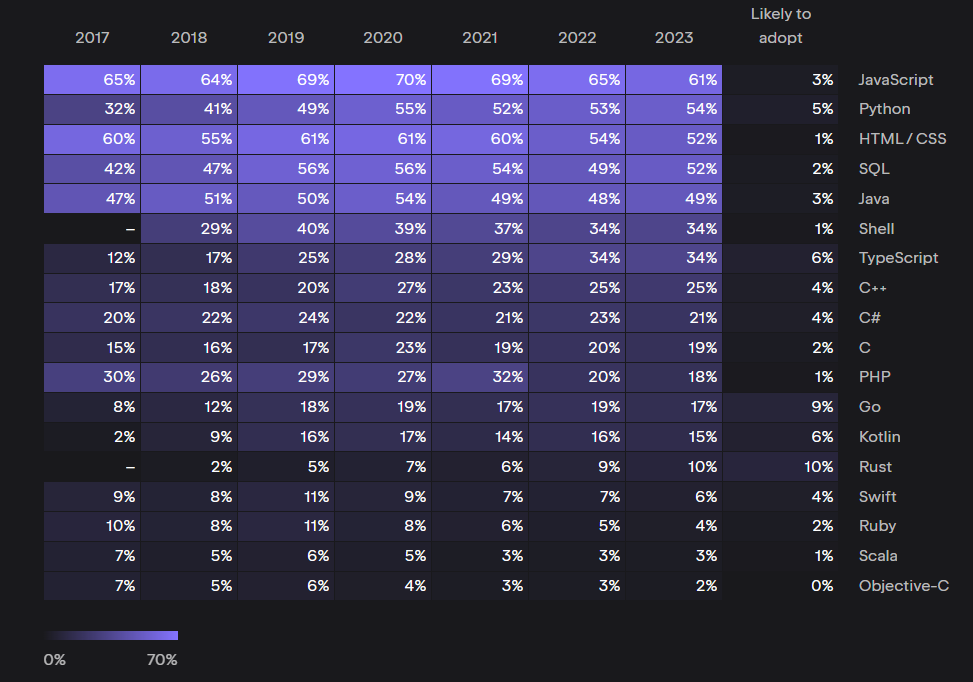
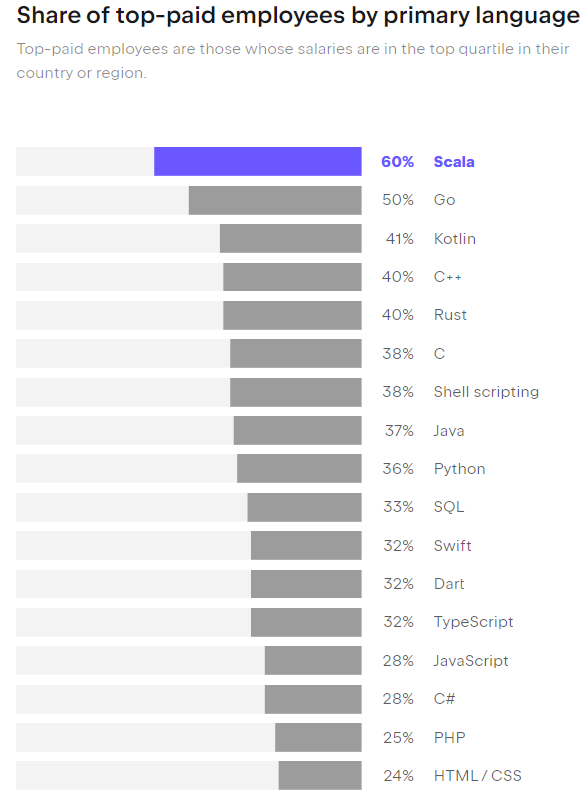


天工 Skywork-13B 开源模型的炼成和思考
前言 笔者6月下旬加入到昆仑万维天工大模型团队负责大模型预训练,第一个参与的项目就是13B模型的预训练。在此期间社区不断开源了很多优秀的大模型,如Llama-2系列,ChatGLM系列,Baichuan系列,Qwen系列。但这些模型大多是在Benchmark上跑跑分,秀一下肌肉,而对技术细节如:数据处理,数据配比,模型调优,评估方案则透露较少。社区正在从开放走向封闭,就Llama-1和Llama-2的tech report对比,Llama-2是更加封闭的,甚至连数据配比也没有透露。在笔者团队训练出一个还不错(可能是目前中文能力最强)的13B模型后,决定对我们的经验进行总结。一来希望启发社区,提升中文社区对预训练的认识,推动AGI在中国早日的实现。二来也是对我们自己的审视,通过开源收集反馈,帮助我们更好的完成之后的工作。三来我们认为目前的中文大模型社区可能在走一个弯路,就是太注重开源榜单的评分,这个弯路社区在BERT时代也走过,BERT时代过分看中CLUE,GLUE,SuperGLUE等榜单,正如目前过分看中MMLU,C-EVAL等榜单,而忽略对模型真实能力的测量。作为Skywork-1...