在之前的实时湖仓系列文章中,我们已经介绍了实时湖仓对于当前企业数字化转型的重要性,实时湖仓的功能架构设计,以及实时计算和数据湖结合的应用场景。
在本篇文章中,将介绍袋鼠云数栈在构建实时湖仓系统上的探索与落地实践,及未来规划。
数栈为什么选择实时湖仓
数栈作为一个数据开发平台,在未引入实时湖仓之前提供的是基于 Lambda 架构的开发模式,分了实时和离线两条链路,这种开发模式带来的问题在于:
· 复杂性高,需要维护流批双链路的不同组件
· 存储成本高,流批两个链路维护两份相同的数据
· 实时链路不可查,Kafka 中间数据查询困难,不支持随机查询,只支持顺序查询
· 数据口径一致性差,不同计算引擎难保证统一的数据口径
![file]()
而实时湖仓则能够节省存储成本,极大地提升开发效率,并更快更好地挖掘数据价值。
· 提供了多样化的分析能力,不限于批处理、流处理,在交互式查询和机器学习方面都很友好
· 提供了 ACID 事物能力,可以更好的保障数据质量,并提供增删改查等功能,传统数仓则缺乏这一能力
· 提供了完善的数据管理能力,包括数据格式、数据 Schema 等
· 提供了存储介质可扩展的能力,支持 HDFS、对象存储、云上存储等
数栈基于实时湖仓的实践
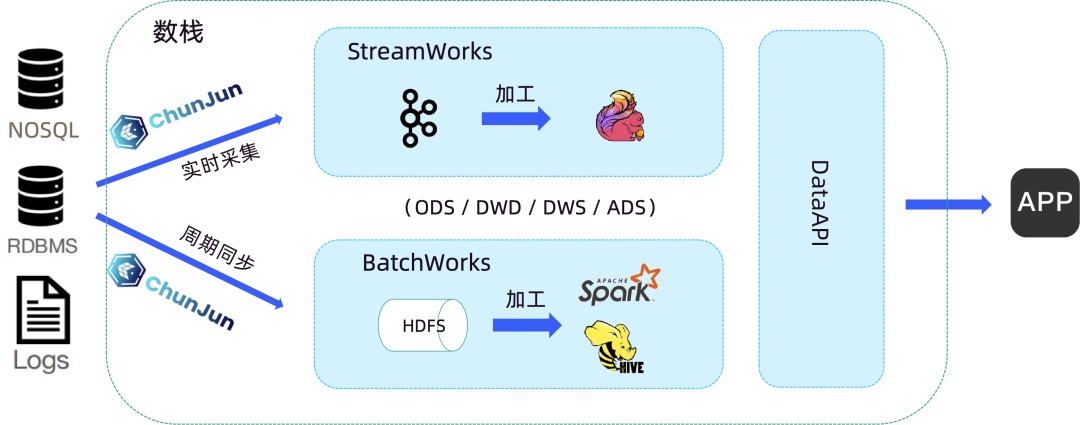
下图便是基于实时湖仓的数栈解决方案结构图:
![file]()
业务库中的数据我们通过自研的数据集成框架 ChunJun 进行实时采集和入湖,目前支持 Iceberg/Hudi 实时入湖。之后在数栈实时开发平台和离线开发平台中进行业务的开发,Flink 和 Spark 支持对接 Iceberg/Hudi,以及 Iceberg/Hudi source 指标展示。再通过 EasyLake 湖仓一体平台进行数据管理,如一键转表、湖表治理等。
基于此,实时湖仓很好地解决了上文提到的 Lambda 架构开发模式带来的痛点问题。实现了存储层和计算层的流批一体,实时链路中间数据可查,统一的数据口径,低成本存储,为企业带来更快、更灵活、更高效的数据处理体验,这就是数栈原则实时湖仓的原因。
下文将为大家重点带来实时入湖以及物化视图的介绍。
CDC 实时入湖
Flink CDC 是基于数据库日志的 CDC 技术,实现了全增量一体化读取的数据集成框架。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。不过 CDC 数据实时入湖也面临着不小的挑战:
· 实时性高:CDC 数据对实时性要求高,数据新鲜度越高,往往业务价值越高
· 历史数据量大:数据库的历史数据规模大
· 强一致性:数据处理必须要保证有序性而且结果需要一致性
· Schema 动态演进:数据库对应的 Schema 会随着业务不断变更
那么,数栈是怎么做的呢?
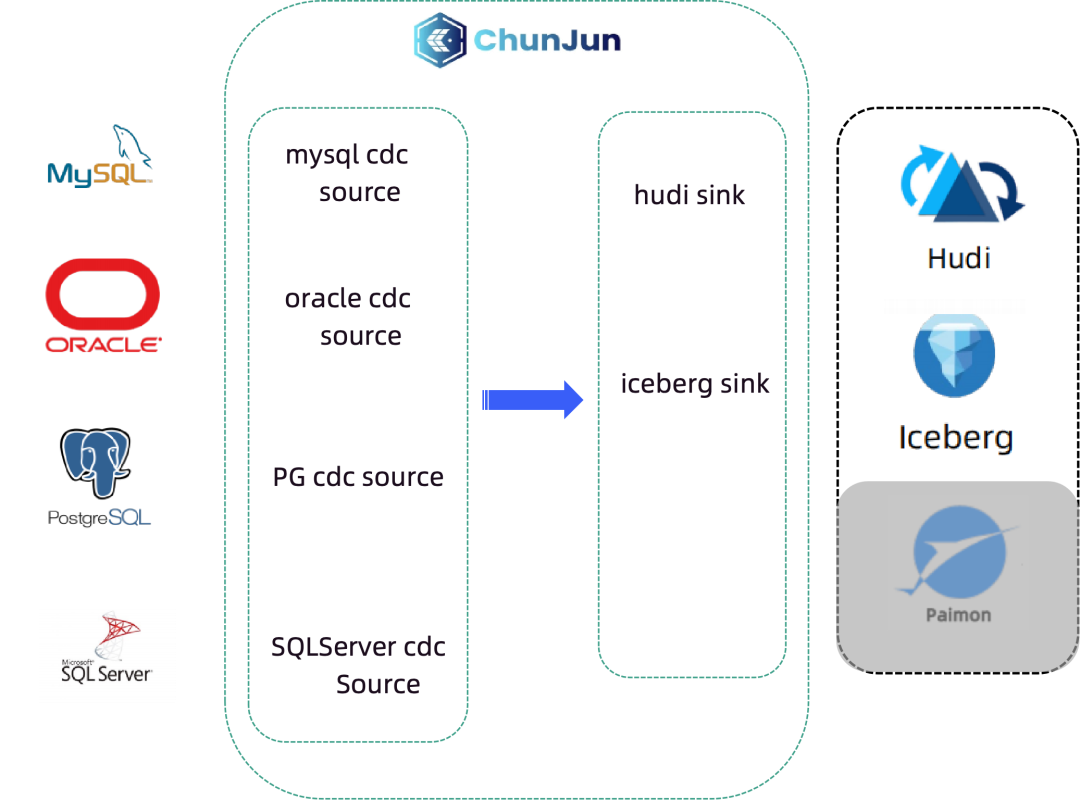
![file]()
袋鼠云自研的数据集成框架 ChunJun 支持 CDC 数据的采集,包括 MySQL CDC、Oracle CDC、PG CDC、SQLServer CDC。CDC 数据采集完之后,写到 Iceberg/Hudi Sink 中,完成实时入湖的工作。
这样下来的整条链路和架构都是袋鼠云自主研发、完全可控的,并且实现了全增量一体化、分钟级时延,对业务稳定性也不会造成任何影响。
ChunJun:https://github.com/DTStack/chunjun.git
实时入湖落地中的问题
在实时入湖落地的过程中,我们当然也遇到过问题和挑战:
· 小文件问题:小文件影响读写效率,导致 HDFS 集群稳定性变差
· Hudi 适配 Flink1.12:客户群体使用的 Flink 版本大多还停留在1.12
· 跨集群入湖:多套 Hadoop 集群的场景下存在跨集群的需求
数栈又是如何个个突破这些问题的呢?
● 小文件问题优化
· 合理设置 Checkpoint Interval
整个 Compaction 过程是一个 I/O 比较多的操作过程,假设一味的调小 Checkpoint Interval,会产生诸如小文件问题、导致 HDFS 压力变大、checkpoint 失败、任务不稳定等一系列问题。
在经过多方实践验证后,推荐将 Checkpoint Interval 设置为 1-5 分钟为优。
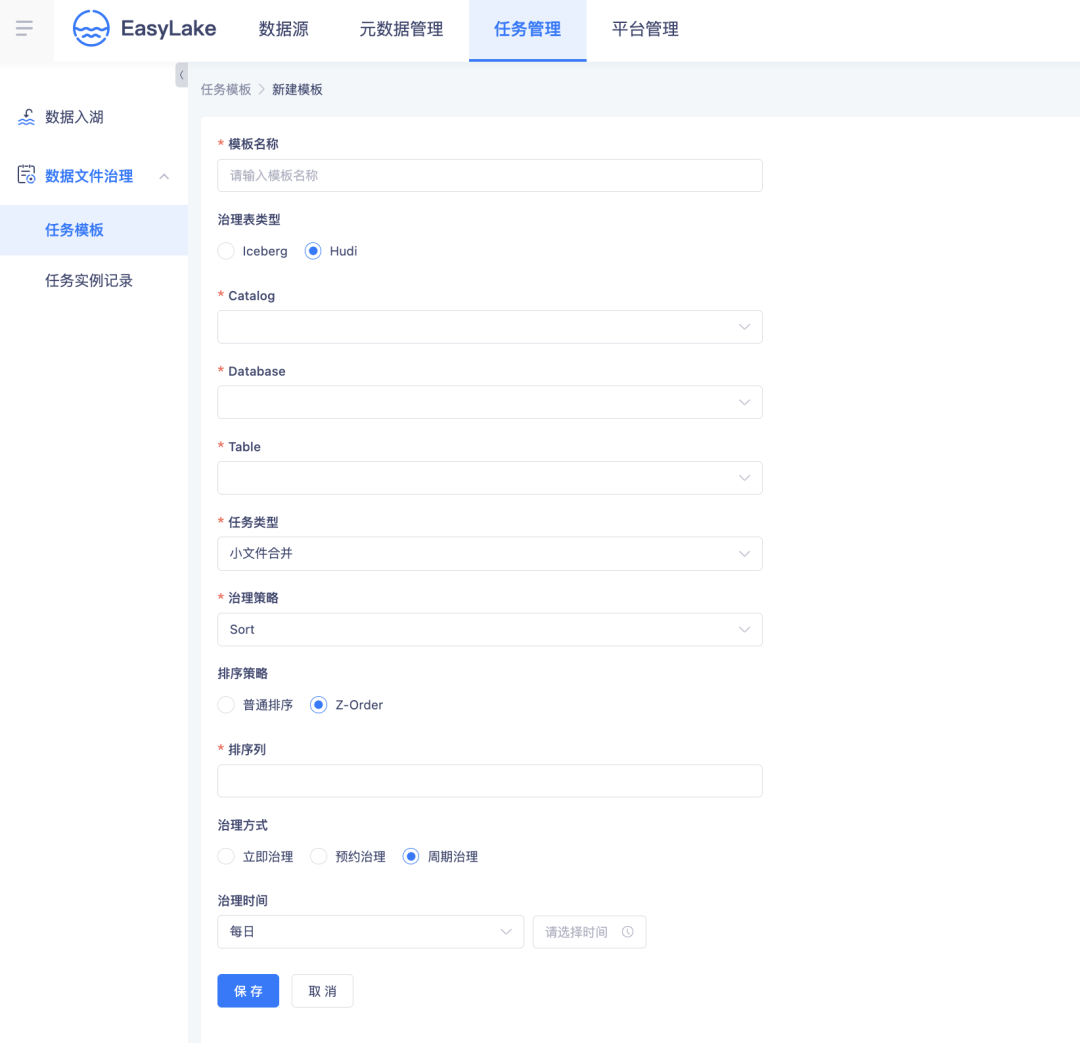
· 平台化小文件治理
调整 Checkpoint,能够缓解小文件的产生,之后还要进行平台化的小文件治理,从根本上解决问题。
EasyLake 湖表治理功能支持数据文件治理,支持快照文件治理,支持 Hudi MOR 增量文件合并,将小文件数量控制在一定的范围内,提升治理效率。
![file]()
● Hudi 适配 Flink 1.12 版本做法
数栈在这方面并不是一张白纸,首先我们基于 hudi-flink1.13.x 模块开发 hudi-flink1.12,将 Flink 版本修改成1.12.7,再针对不兼容的点逐个进行修复,最后进行完整的功能测试即完成了适配的工作。
![file]()
· 跨集群入湖方案
Hudi 和 Iceberg Sink 默认从 HADOOP_CONF_DIR 环境变量获取 core-site.xml 和 hdfs-site.xml 访问对应的 HDFS。
数栈基于自研的 ChunJun,在 ChunJun iceberg-connector 和 hudi-connector 中对 hadoop conf dir 的获取方式进行扩展,支持通过指定 hadoopConfig 自定义参数的方式。
如此便能够使集群之间的数据流动起来,打破数据孤岛,完成跨集群入湖的支持。
![file]()
ETL 加速探索-物化视图
在介绍数栈在物化视图方面的探索之前,必须先理清楚我们为什么需要物化视图?
在实时湖仓中包含三类任务,实时 ETL、离线 ETL 和 OLAP,以上三类任务在 ODS -> ADS 的加工过程中,都会出现聚合操作越来越多,IO 越来越密集,多个任务 SQL 中具有相同逻辑的 SQL 片段等现象。
物化视图可以将表连接或者聚合等耗时较多的结果进行预计算并将计算结果保存下来,在对复杂 SQL 进行查询的时候,直接基于上一步预计算的结果进行计算,从而避免耗时的操作,更快的得到结果。
而在实时湖仓中基于数据湖构建的物化视图可实现流、批和 OLAP 任务之间的共享,从而进一步降低实时数据湖中数据在整条链路中的延时。为实时加工链路加速,并节省计算成本,提高查询性能和响应速度。
● 实时湖仓中落地物化视图需要完成的内容
· 平台化数据湖物化视图管理
· Spark 支持基于数据湖表格式管理物化视图
· Trino 支持基于数据湖表格式管理物化视图
· Flink 支持基于数据湖表格式管理物化视图
目前数栈实时湖仓已经完成了 Spark 和 Trino 的部分,之后也会将这四部分内容都完成落地,充分发挥物化视图的作用。
● 物化视图实现原理
![file]() · 创建物化视图语法
· 创建物化视图语法
CREATE MATERIALIZED VIEW (IF NOT EXISTS)? multipartIdentifier
('(' colTypeList ')')? tableProvider?
((OPTIONS options=tablePropertyList) |
(PARTITIONED BY partitioning=partitionFieldList) |
skewSpec |
bucketSpec |
rowFormat |
createFileFormat |
locationSpec |
commentSpec |
(TBLPROPERTIES tableProps=tablePropertyList))*
AS query
· 示例
CREATE MATERIALIZED VIEW mv
AS SELECT
a.id,
a.name
FROM jinyu_base a
JOIN jinyu_base_partition b
ON a.id = b.id;
未来规划
袋鼠云基于实时湖仓的实践之路远不止于此,未来还将进行更多、更深层次的探索,为企业提供更高效、更灵活、更智能的数据处理解决方案。
· 易用性:增加平台湖表管理的易用性
· 引入 Paimon:平台支持对接 Paimon、增加基于 Paimon 的湖仓一体建设
· 提升入湖性能:深入并增强内核,提升入湖的的性能
· 安全性探索:实时湖仓提供数据共享、支持多引擎,探索实时湖仓的安全管理方案
本文根据《实时湖仓实践五讲第三期》直播内容总结而来,感兴趣的朋友们可点击链接观看直播回放视频及免费获取直播课件。
直播课件:
https://www.dtstack.com/resources/1054?src=szsm
直播视频:
https://www.bilibili.com/video/BV1Ee411d7Py/?spm_id_from=333.999.0.0&
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack


 · 创建物化视图语法
· 创建物化视图语法