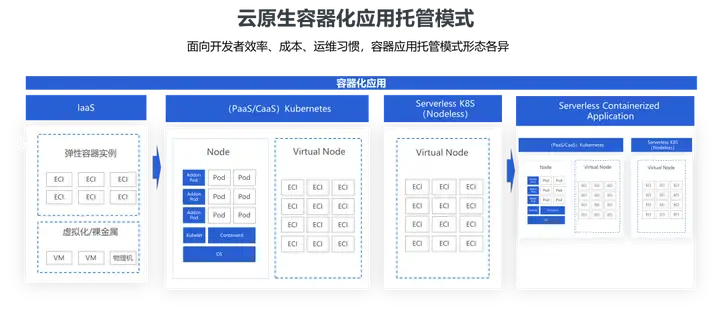
云原生容器化应用托管模式的演变
云原生这个概念从提出,到壮大,再到今天的极大普及,始终处于一个不断演进和革新的过程中。云原生体系下应用的托管形态是随着企业应用架构在不断演进的。最早的应用大多是集中式、单体式的,应用通过优雅的分层来实现领域模型的共享和更细致的模块拆分。随着互联网的爆炸式发展,分布式的架构逐渐取代集中式架构,云原生应用托管也经历了 4 个阶段的演进。
![]()
第一阶段:容器化
Docker 的出现和极大普及,通过集装箱式的封装,标准化开发和运维使得大规模、跨语言的分布式应用大规模落地成为现实。
第二阶段:全面拥抱 Kubernetes
在此之后,微服务架构得以更大规模的流行开来,随之而来的是企业需要运维的基础设施日益复杂、需要管理的容器数量呈现几何式增长。Kubernetes 一方面屏蔽了IaaS 层基础架构的差异并凭借优良的可移植性,帮助应用一致地运行在包括数据中心、云、边缘计算在内的不同环境; 另一方面,凭借优秀的开放性、可扩展性以及活跃开发者社区,在大规模容器编排之战中脱颖而出,成为分布式资源调度和自动化运维的事实标准。
第三阶段:Serverless Kubernetes
尽管 Kubernetes 带来了众多好处,但是在生产环境中落地 Kubernetes,持续保障系统的稳定性,安全性和规模化成长,对于绝大部分企业来说,依然充满挑战。在这样的背景下,Nodeless Kubernetes 进入大家视线:在保留完整 Kubernetes 能力的基础上,将复杂的运维和容量管理工作下沉到云基础设施底座。
第四阶段:Serverless 容器化应用托管
尽管 Serverless Kubernetes 极大的减轻了企业运维 Kubernetes 的负担,但 Kubernetes 自身的复杂性和陡峭的学习曲线依然让人望而生畏,如何让用户的应用跑在 Kubernetes上,既能享受到 Kubernetes 带来的诸多技术红利,又能尽可能 0 改造,成为又一个亟待解决的问题。
![]()
Serverless 应用引擎 SAE 诞生
Serverless 应用引擎 SAE 就是在这个背景下诞生的,它是一款零代码改造、极简易用、自适应弹性的应用全托管平台。SAE 让您免运维 IaaS 和 K8s,秒级完成从源代码/代码包/ Docker 镜像部署任何语言的在线应用(如 Web /微服务 /Job任务)到 SAE,并自动伸缩实例按使用量计费,开箱即用日志、监控、负载均衡等配套能力。
SAE 的出现解决了众多企业想用 K8s,但是又上手困难的问题,可以用非常低的门槛享受到 K8s 的技术红利,并且按需使用、按量计费的收费模式以及自适应的弹性能力,也为企业降本增效提供了强大助力。
![]()
Serverless 应用引擎 SAE2.0 全面升级
今年,Serverless 应用引擎 SAE 来到了 2.0 时代,实现了全面升级。首先是弹性能力方面:
弹的更快
在保障完全兼容企业开发习惯的基础上,SAE2.0 的弹性效率有了非常大的提升,从秒级到百毫秒级,并且开始支持缩短到 0 的能力。
缩容到 0
即在无业务流量情况下不产生费用,能够让资源利用率无限贴近请求资源的负载。
弹后更省
在做了大量的用户调研之后,我们发现很多企业的应用,在没有请求或者请求处理完成的时候,是没有必要保持大量资源的。那么我们就可以在请求处理完之后,释放掉它的 CPU 或者仅保留极低的 CPU 资源,并维持内存状态,达到资源的保活和实例的保活等目的,这就是闲置计费。
闲置计费最重要的目的,是利用 CPU 的释放来节省 CPU 的费用;并且通过保持内存,就可以在下次实例启动的时候实现毫秒级的恢复,做到最大限度的节省资源的同时,还能保证能够有很低的延时。
弹的更稳
通过平台侧全链路的优化,让延时降低了 45%,运行时性能波动下降至 7%。在弹得更细,弹得更稳的同时,稳定性也做到最佳。
![]()
SAE2.0 内置有流量网关,可以根据每个实例配置对应的单实例的并发度,类似于我们平常说的并发数。当并发上来的时候,可以根据他实际的请求数,去扩容对应的实例。
当我没有请求的时候,则不会对 CPU 进行计费,也就是上面说的闲置计费。而当请求来的时候,会根据实际的并发数先去分配 1 个实例,当这个实例填满之后,再去扩容下一个实例,这样就实现了在流量波动的时候,根据实际流量进行自动扩缩容的能力。
![]()
SAE2.0 为 Web 应用提供了多版本流量配置的能力。它可以对每个版本进行独立的网络配置。根据业务需要,可以动态配置多个版本对应的流量配比,并且不需要去指定它对应的实例个数,实例个数是根据配置的实例上限和流量配比,通过自动弹性能力扩缩出来的,这样就实现了多版本的并存。
除此之外,在开发体验方面,SAE2.0 无需任何编码改动即可将传统单体架构或微服务架构升级至 Serverless 应用架构。并凭借一键部署及秒级应用创建能力,实现应用的高效发布。同时,SAE2.0 还具备了 CLI、S2A 等平台工程能力,大大提升了用户的研发效能。此外,它还具备 Knative Adapter 功能,使得 Knative 的应用程序能够非常顺畅地在 SAE2.0 上发布。
作者:邵丹
原文链接
本文为阿里云原创内容,未经允许不得转载。