本文分享自华为云社区《GaussDB数据库SQL系列-行列转换》,作者:Gauss松鼠会小助手2。
一、前言
在构建数据仓库或做数据分析时,需要对原始数据的结构进行一定的处理,有时涉及到“行转列”,有时涉及到“列转行”,那么这两个转换的方式具体是什么,有什么差异,怎么实现,今天我们将以GaussDB数据库为例,给大家做一下讲解。
二、简述
1、行转列概念
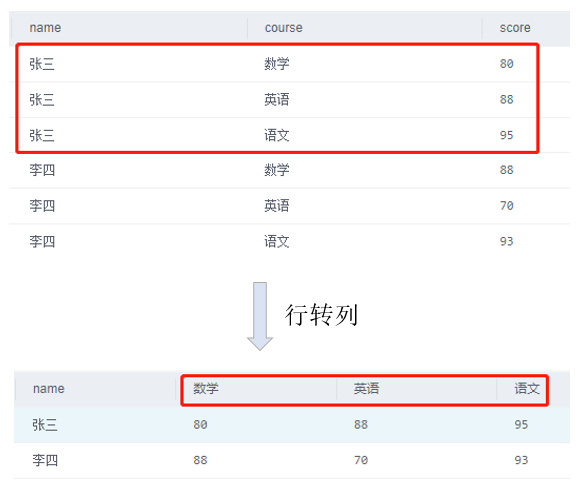
即将多行一列数据转为一行多列显示。通常转化后将某一列分类后的值作为新的列名,将此值对应的多行数据显示成一行。
![cke_130.png]()
2、列转行概念
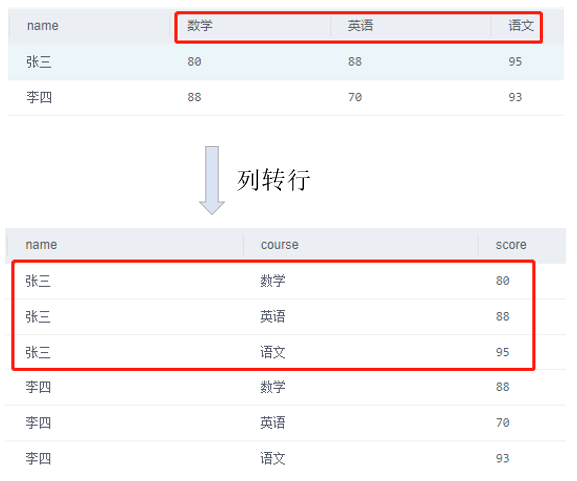
即将一行多列数据转成多行一列显示。通常将转化后的列名为某一行中某一列的值,来识别原先对应的数据。
![cke_131.png]()
三、GaussDB数据库的行列转换实验示例
用一张学生成绩来举例:从老师的角度,在录入成绩时,每科老师都会单独录入每个学生的本科成绩。而从学生的角度,学生只关心自己各科的成绩分别是多少。所以如果把老师录入数据作为原始表,那么学生查看自己的成绩时就要用到行转列,如果让学生上报自己各科的成绩,然后老师去查对应学科的学生考试成绩时,那就是列转行了。
1、行转列示例
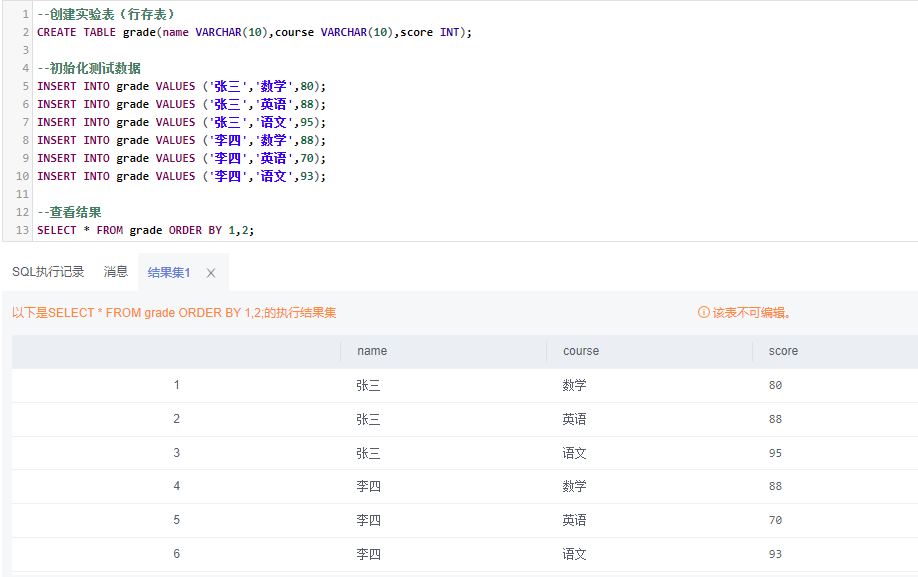
1)创建实验表(行存表)
--创建实验表(行存表)
CREATE TABLE grade(
name VARCHAR(10)
,course VARCHAR(10)
,score INT);
--初始化测试数据
INSERT INTO grade VALUES ('张三','数学',80);
INSERT INTO grade VALUES ('张三','英语',88);
INSERT INTO grade VALUES ('张三','语文',95);
INSERT INTO grade VALUES ('李四','数学',88);
INSERT INTO grade VALUES ('李四','英语',70);
INSERT INTO grade VALUES ('李四','语文',93);
--查看结果
SELECT * FROM grade ORDER BY course;
![cke_132.png]()
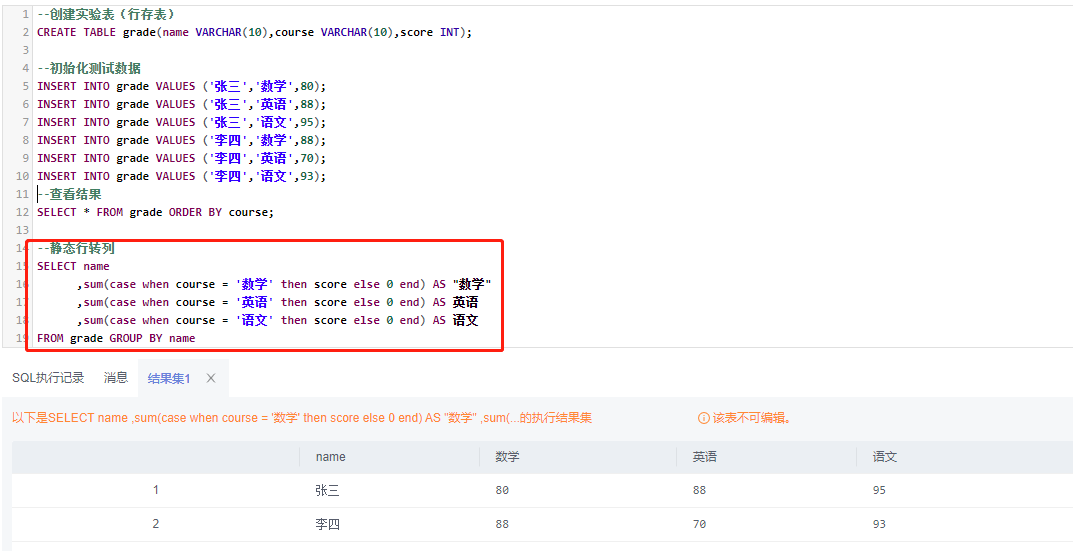
2)静态行转列
--静态行转列
SELECT name
,sum(case when course = '数学' then score else 0 end) AS "数学"
,sum(case when course = '英语' then score else 0 end) AS 英语
,sum(case when course = '语文' then score else 0 end) AS 语文
FROM grade
GROUP BY name;
使用sum、case when的方式:
![cke_133.png]()
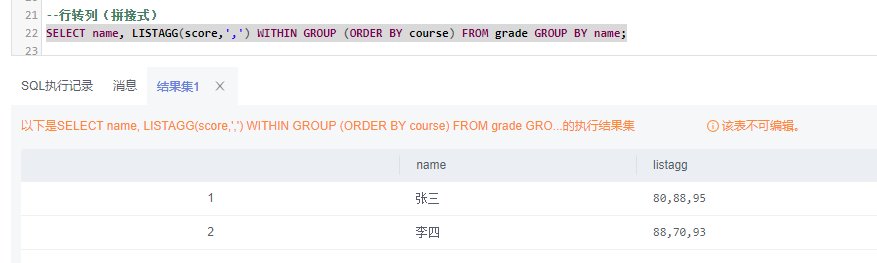
3)行转列(结果值:拼接式)
使用listagg within group:
--行转列(结果值:拼接式)
SELECT name, LISTAGG(score,',') WITHIN GROUP (ORDER BY course) FROM grade GROUP BY name;
![cke_134.png]()
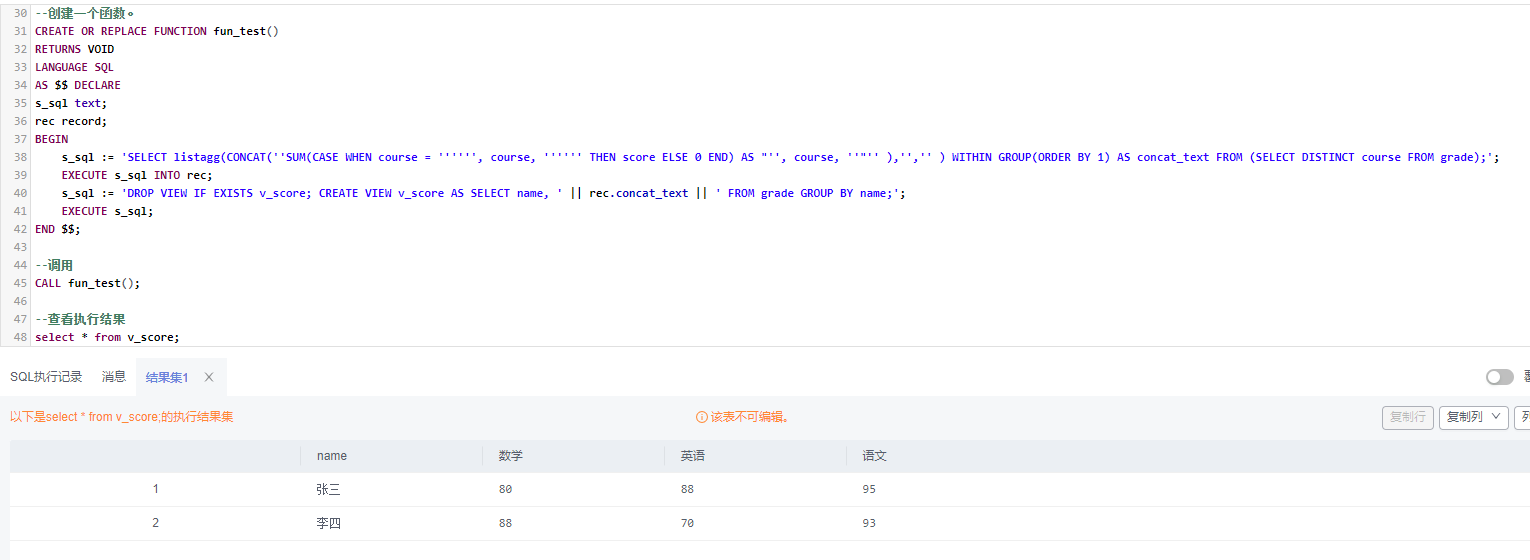
4)动态行转列(拼接SQL式)
通过“listagg + 创建FUNCTION + VIEW”的方式实现
--动态行转列(SQL拼接式)
SELECT listagg(concat('SUM(CASE WHEN course = ''', course, ''' THEN score ELSE 0 END) AS "', course,'"'),',') WITHIN GROUP(ORDER BY 1) AS concat_text FROM (SELECT DISTINCT course FROM grade);
--concat_text的结果:
SUM(CASE WHEN course = '数学' THEN score ELSE 0 END) AS "数学",SUM(CASE WHEN course = '英语' THEN score ELSE 0 END) AS "英语",SUM(CASE WHEN course = '语文' THEN score ELSE 0 END) AS "语文"
--创建一个函数。
CREATE OR REPLACE FUNCTION fun_test()
RETURNS VOID
LANGUAGE SQL
AS $$ DECLARE
s_sql text;
rec record;
BEGIN
s_sql := 'SELECT listagg(CONCAT(''SUM(CASE WHEN course = '''''', course, '''''' THEN score ELSE 0 END) AS "'', course, ''"'' ),'','' ) WITHIN GROUP(ORDER BY 1) AS concat_text FROM (SELECT DISTINCT course FROM grade);';
EXECUTE s_sql INTO rec;
s_sql := 'DROP VIEW IF EXISTS v_score; CREATE VIEW v_score AS SELECT name, ' || rec.concat_text || ' FROM grade GROUP BY name;';
EXECUTE s_sql;
END $$;
--调用
CALL fun_test();
--查看执行结果
select * from v_score;
![cke_135.png]()
Tip:请注意SQL拼写时的单引号、双引号。
2、列转行示例
1)创建实验表(复用前面的测试数据)
--创建实验表(复用前面的测试数据)
CREATE TABLE grade1 AS
SELECT name
,sum(case when course = '数学' then score else 0 end) AS "数学"
,sum(case when course = '英语' then score else 0 end) AS 英语
,sum(case when course = '语文' then score else 0 end) AS 语文
FROM grade
GROUP BY name;
--查看结果
SELECT * FROM grade1;
![cke_136.png]()
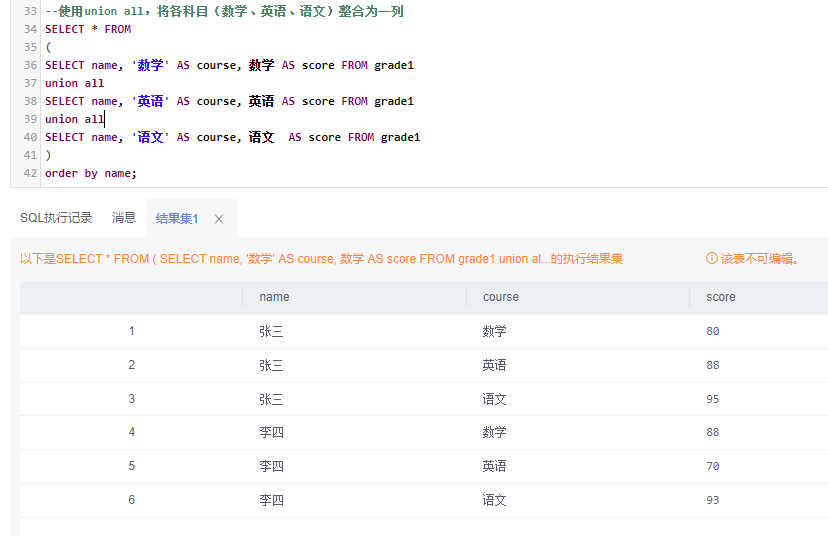
2)使用union all,将各科目(数学、英语、语文)整合为一列
--使用union all,将各科目(数学、英语、语文)整合为一列
SELECT * FROM
(
SELECT name, '数学' AS course, 数学 AS score FROM grade1
union all
SELECT name, '英语' AS course, 英语 AS score FROM grade1
union all
SELECT name, '语文' AS course, 语文 AS score FROM grade1
)
order by name;
![cke_137.png]()
四、小结
行列互转在一些数据库使用场景中经常用到,比如数据分析、数仓建设等。但不同的数据库软件有着不同处理方式,但是行列换的基本思路是一致的。本文主要是以GaussDB数据为平台,为大家做了简单的讲述 ,欢迎测试。
点击关注,第一时间了解华为云新鲜技术~