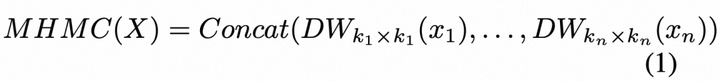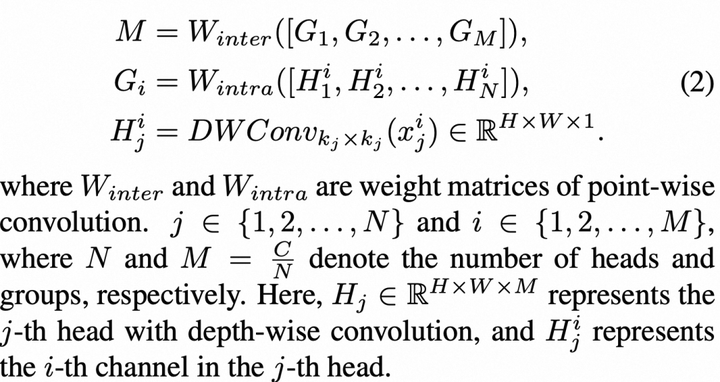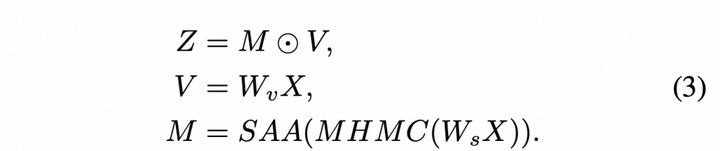作者 | AFzzz
![]()
1 文章介绍
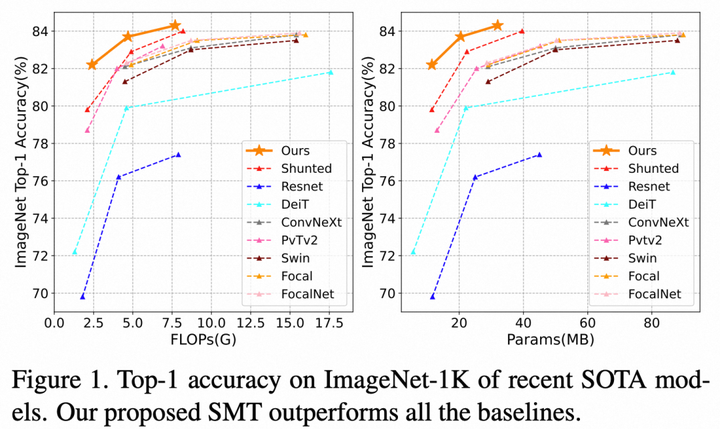
近年来,基于Transformer和CNN的视觉基础模型取得巨大成功。有许多研究进一步地将Transformer结构与CNN架构结合,设计出了更为高效的hybrid CNN-Transformer Network,但它们的精度仍然不尽如意。本文介绍了一种新的基础模型SMT(Scale-Aware Modulation Transformer),它以更低的参数量(params)和计算量(flops)取得了大幅性能的提升。
不同于其他CNN-Transformer结合的方案,SMT基于卷积计算设计了一个新颖的轻量尺度感知调制单元Scale-Aware Modulation(SAM) ,它能够捕捉多尺度特征的同时扩展感受野,进一步增强卷积调制能力。此外,SMT提出了一种进化混合网络Evolutionary Hybrid Network(EHN) ,它能够有效地模拟网络从浅层变深时捕捉依赖关系从局部到全局的转变,从而实现更优异的性能。在ImagNet、COCO以及ADE20k等任务上都验证了该模型的有效性。值得一提的是,SMT在ImageNet-22k上预训练后以仅仅80.5M的参数量在ImageNet-1k上达到了88.1%的精度。
![]()
2 出发点
-
对于多层级的网络架构来说,由于浅层特征图分辨率大的原因,自注意力的二次复杂性会带来严重的计算负担。因此,如何为浅层stage设计高效的attention计算机制是十分重要的。
回顾以往的大部分Hierarchical(Multi-scale)的模型,以Swin为代表,以及后续的CvT,PvT,Shunted Transformer等等,它们的主要贡献点都是设计出了一种更高效的attention计算单元,比如local attention,lightweight convolution attention等等。
-
ViT论文中提出,Transformer模型的注意力捕捉依赖关系为,浅层捕捉local信息,深层捕捉global信息,而这种特性在多层级网络架构上也会出现。
作者认为,模拟并建模这种捕捉依赖过渡是重要且有效的。
![]()
3 SMT框架算法
![]()
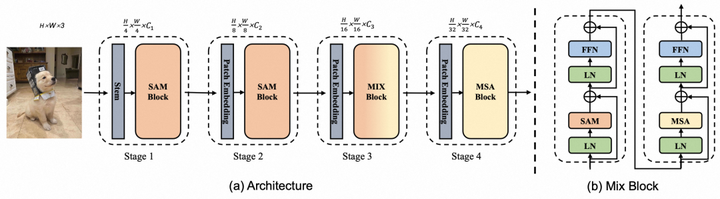
SMT的总体框架如图1所示。整个网络包括四个阶段,每个阶段的下采样率为{4, 8, 16, 32}。我们并非和FocalNet一样构建一个无注意力机制的网络,而是首先在前两个阶段采用文章提出的尺度感知调制(SAM),然后在倒数第二个阶段中依次堆叠一个SAM Block和一个多头自注意力(MSA) Block,以建模从捕捉局部到全局依赖关系的转变。对于最后一个阶段,我们仅使用MSA块来有效地捕捉长距离依赖关系。
3.1 Scale-Aware Modulation模块
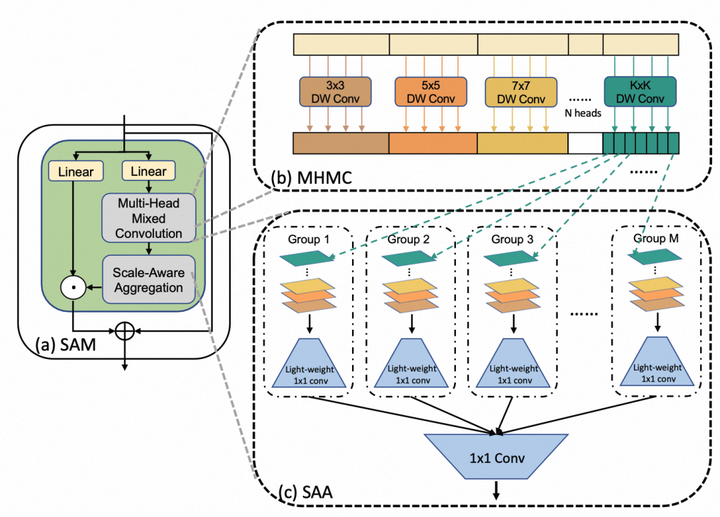
![]()
- 多头混合卷积MHMC(Multi-Head Mixed Convolution)
在MHMC中,我们引入了具有不同卷积核大小的多个卷积层,使其能够捕捉多个尺度上的空间特征。当我们将N head设置得较大时,能够引入大卷积核来扩大感受野,增强其建模长距离依赖关系的能力。如图2(b)所示,MHMC将输入通道分为N个头,对每个头应用独立的深度可分离卷积。我们将卷积核大小初始化为3x3,并逐头递增。这种方法使得我们能够人为的通过调整头的数量来调节感受野的范围和多粒度信息。
![]()
- 多尺度感知聚合SAA(Scale-Aware Aggregation)
为了增强MHMC中多个头之间的信息交互,我们引入了一种新的轻量化聚合模块,称为多尺度感知聚合(SAA),如图2(c)所示。SAA首先对MHMC生成的不同粒度的特征进行重组和分组。具体而言,我们从每个头中选择一个通道来构建一个组,然后在每个组内进行up-down的特征融合,从而增强多尺度特征的多样性。值得注意的是,Num_group = C / N_head,C为输入通道数,这意味着组的数量与MHMC中头的数量成反比,每个组里只包含N个特征通道。随后,我们使用1x1卷积进行组内-组间模式的跨组信息融合,从而实现轻量且高效的聚合效果。
![]()
如图3所示,我们可视化出SAA前和SAA后的特征图,可以观察到SAA模块加强了语义相关的低频信号,并准确地聚焦于目标物体最重要的部分。与聚合之前的卷积映射相比,SAA模块展示了更好的能力来捕捉和表示视觉识别任务的关键特征。
![]()
- 尺度感知调制器SAM(Scale-Aware Modulation)
如图2(a)所示,在使用MHMC捕捉多尺度空间特征并通过SAA进行聚合后,我们获得一个输出特征图,我们称之为调制器Modulator。然后,我们使用标量乘积采用这个调制器来调制value V。
![]()
3.2 混合进化网络Evolutionary Hybrid Network
![]()
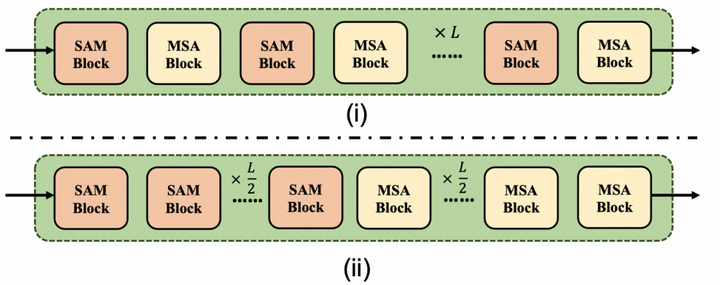
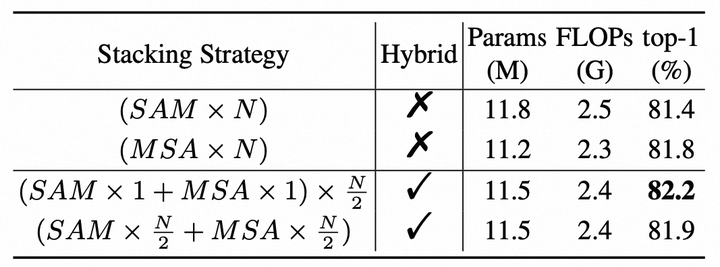
在本节中,我们提出根据网络的捕捉范围依赖关系的变化模式重新分配适当的计算模块,以实现更好的计算性能。我们提出了两种混合堆叠策略用于倒数第二个阶段,(i) 依次堆叠一个SAM块和一个MSA块。(ii) 在stage的前半部分使用SAM块,在后半部分使用MSA块。为了评估这两种混合堆叠策略的有效性,我们在ImageNet-1K上评估了它们的top-1准确率。可以看到,(i)混合堆叠策略更加有效。
![]()
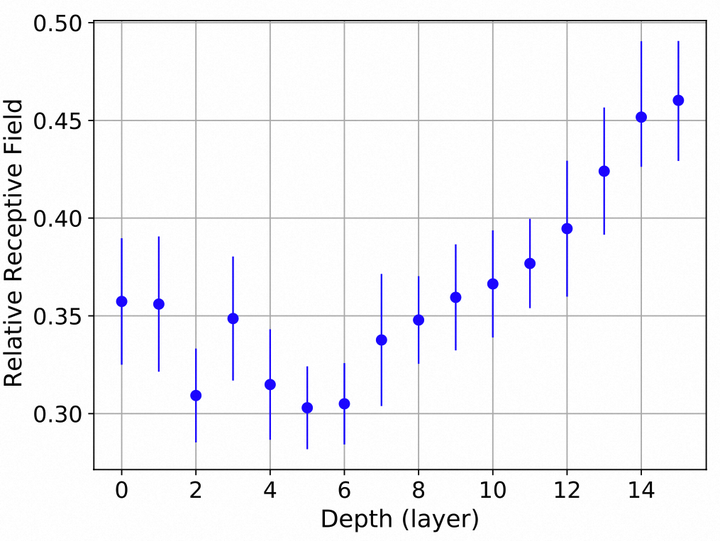
不仅如此,我们还计算了倒数第二个阶段中MSA块的相对感受野。值得注意的是,浅层layer的相对感受野开始阶段有一个轻微的下降趋势。作者认为这种下降可以归因于SAM对早期MSA Block的影响,我们将这种现象称为计算单元磨合适应期。而随着网络的加深,我们可以看到感受野呈平稳上升的趋势,这表明我们提出的进化混合网络有效地模拟了从局部到全局依赖捕捉的过渡。
![]()
4 实验
4.1 分类实验
![]()
![]()
![]()
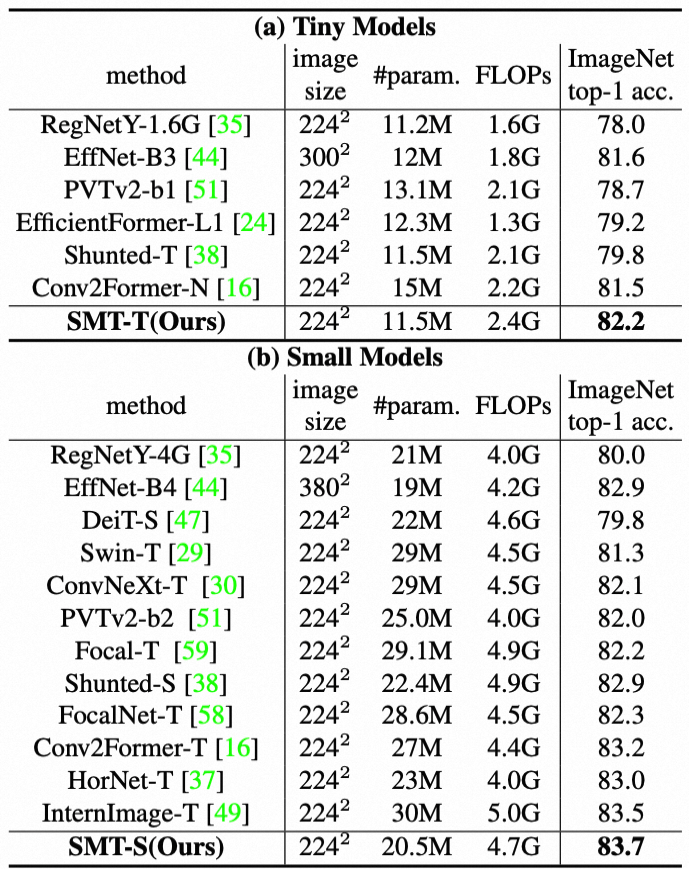
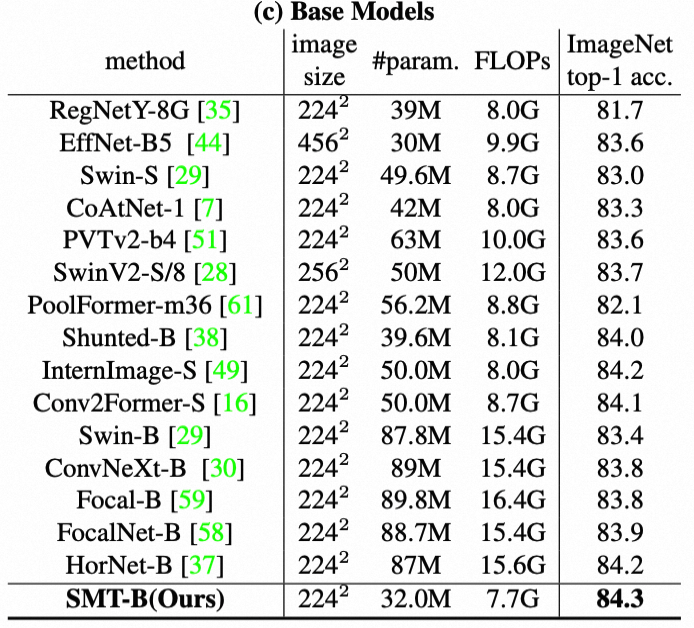
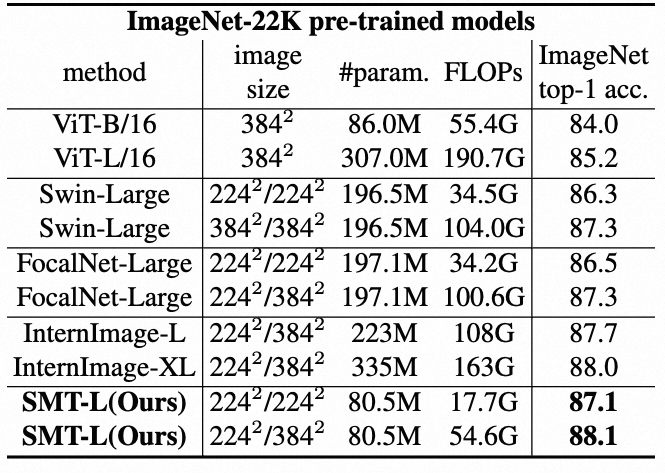
上表给出了不同模型大小在ImageNet-1k上的性能对比,从中可以看到:
- SMT在tiny、small和base规模上都以更低的参数量和计算量达到了更优的性能;
- SMT-B在仅仅32.0M和7.7GFlops下就取得了84.3%的精度,甚至比大多数80M和15G以上的模型更好。
- 当采用ImageNet-22k与大尺度数据预训练之后,SMT-L精度提升到87.1%和88.1%,优于现有的CNN和Transformer模型。特别地,SMT-L用4x低的参数量和3x低的计算量就超过了InternImage-XL(88.0%)
- 这些结果表明SMT是一个scalability能力很强的模型,在各种尺度参数下都具有优异的性能。
4.2 目标检测实验
![]()
![]()
![]()
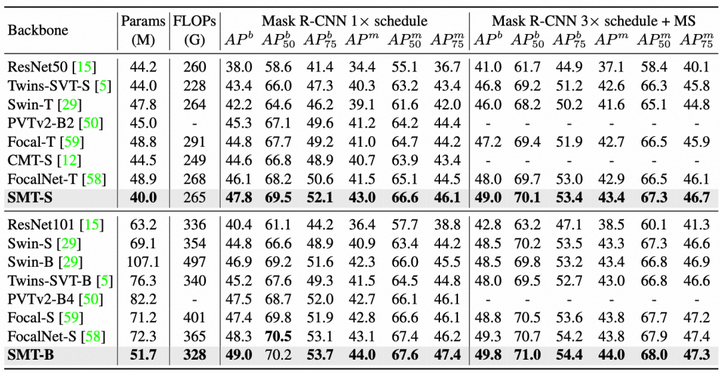
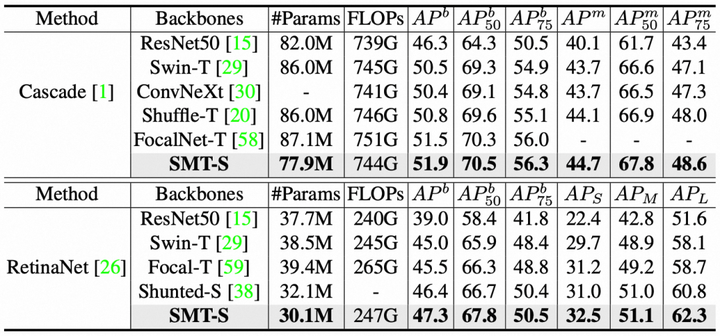
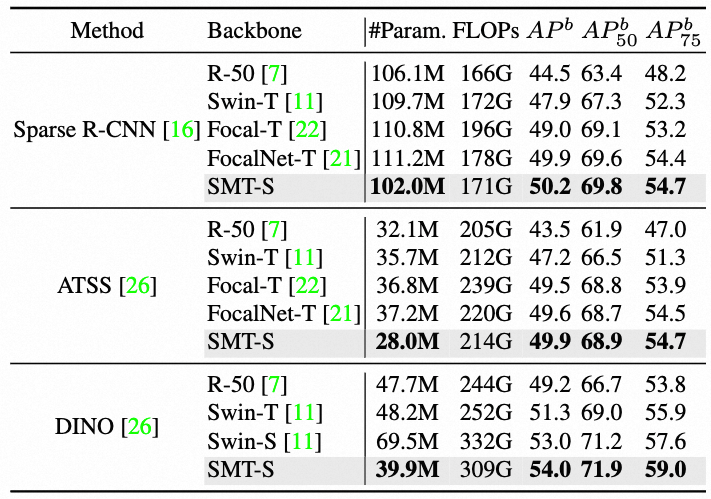
上述三个表格是在多个检测框架上的性能对比实验,可以看到
- 在多个检测框架上,包括Mask R-CNN、Cascade R-CNN、RetinaNet、Sparse R-CNN、ATSS和DINO中,SMT都获得了更优的性能。
- 对于Mask R-CNN,在1x和3x中,SMT-B分别比Swin-B高2.1mAP和1.3mAP,同时参数量只有Swin-B的一半。
- 对于DINO检测框架,SMT-S仅仅用39.9M的参数量就达到了54.0mAP,超越了现有同等规模大小的其他模型。
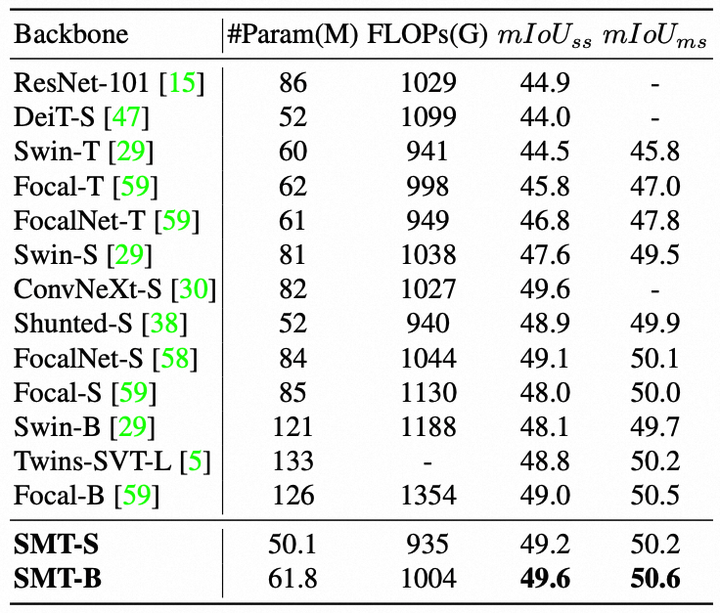
4.3 分割实验
![]()
上表给出了ADE20K分割任务上的性能对比,从中可以看到当我们使用uperNet框架时,SMT在不同尺度下拥有更低的参数量和计算量,同时精度也优于其他模型。
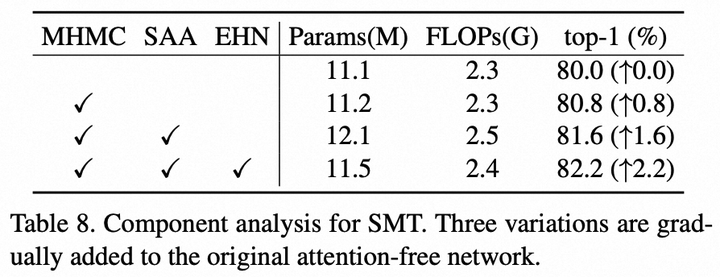
4.4 消融实验
![]()
5 总结与展望
总的来说,在视觉基础模型backbone的探索路程中,我们有着对未来的展望:
- 以视觉Transformer为例,除了在自监督学习等预训练中依旧用着ViT这种plain Vision Transformer,大部分视觉基础模型都以Swin和PvT这种Hierarchical架构为基础设计范式。而这种范式需要解决的问题就是如何在浅层stage中设计更高效的注意力机制计算来解决自注意力的二次复杂性带来的计算负担。是否有更优秀的计算模块能够代替SAM或者是MSA是我们后续需要继续探索的路。
- 2023年,更多的视觉Transformer模型和CNN基础大模型被提出,它们在各大榜单上你追我赶,可以发现CV领域中CNN依旧有着一席之地。如果Transformer不能够在CV领域完全替代cnn神经网络,那么将两者的优势结合起来是否是更好的选择?因此,我们希望SMT可以作为Hybrid CNN-Transformer方向新的baseline,推动该领域的进步和发展。
● Arxiv地址:
https://arxiv.org/abs/2307.08579
● Github地址:
https://github.com/AFeng-x/SMT
● modelscope地址:
https://modelscope.cn/models/PAI/SMT/summary
● 论文链接:
https://arxiv.org/pdf/2307.08579.pdf
● 代码链接:
https://github.com/AFeng-x/SMT
Reference
[1] Scale-Aware Modulation Meet Transformer[https://arxiv.org/abs/2307.08579]
[2] An image is worth 16x16 words transformers for image recognition at scale [https://arxiv.org/pdf/2010.11929.pdf]
[2] Focal Modulation Network [https://arxiv.org/abs/2203.11926]
[3] MixConv: Mixed Depthwise Convolutional Kernels [https://arxiv.org/abs/1907.09595]
[4] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [https://arxiv.org/abs/2103.14030]
[5] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions [https://arxiv.org/abs/2211.05778]
论文信息
● 论文标题:
Scale-Aware Modulation Meet Transformer
● 论文作者:
林炜丰、吴梓恒、陈佳禹、黄俊、金连文
● 论文PDF链接:
https://arxiv.org/pdf/2307.08579.pdf