昆仑万维天工大模型在腾讯优图实验室联合厦门大学开展的多模态大语言模型(Multimodal Large Language Model,简称“MLLM”)测评中,综合得分排名第一。公告称,“这标志着昆仑万维天工大模型在多模态方面跻身世界领先水平,未来将有力支撑公司旗下AI业务矩阵取得关键性突破。”
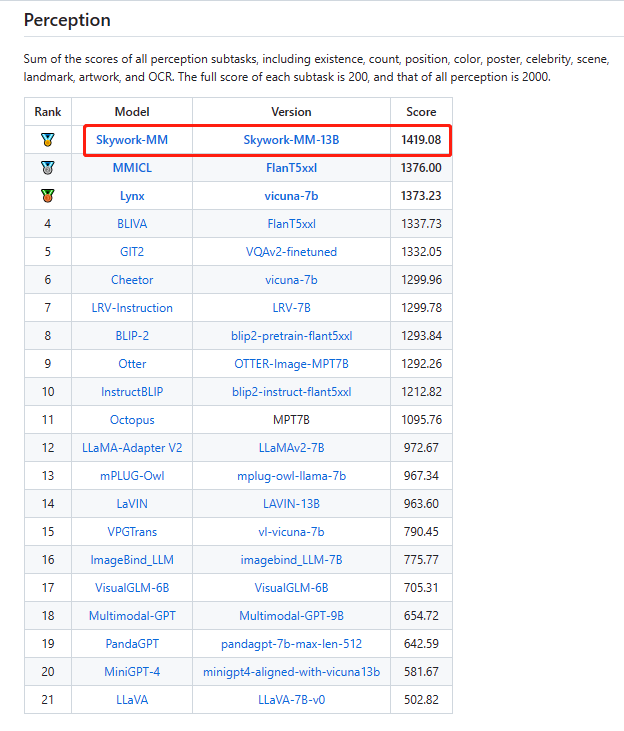
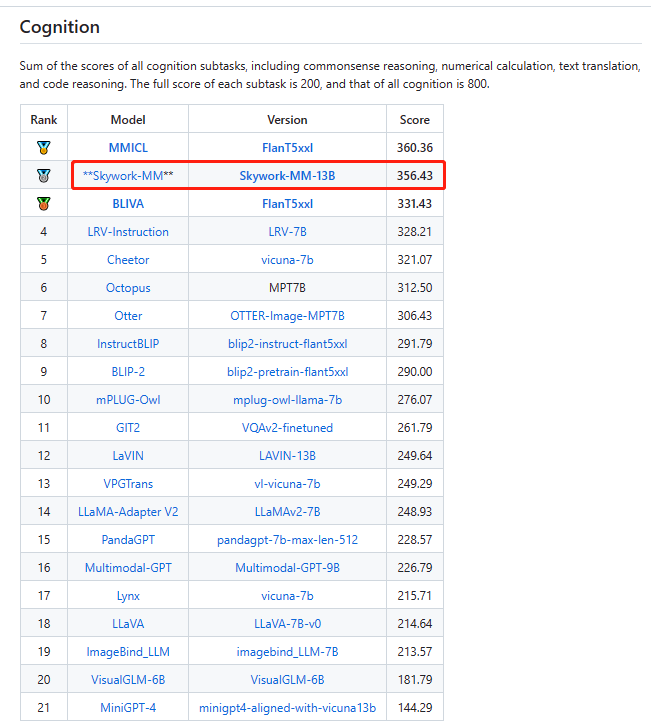
腾讯优图实验室联合厦门大学在新建的评测基准MME上首次对全球范围内MLLM模型进行了全面定量评测并公布了16个排行榜,包含感知、认知两个总榜单以及14个子榜单。MME数据集是一个最近发布的多模态语言模型测评基准。MME通过评估大型多模态语言模型在涵盖感知和认知任务的 14 个子任务上的表现来全面评估它们。昆仑万维天工大模型多模态团队的Skywork-MM模型位列综合榜单第一,其中,感知榜单排名第一、认知榜单排名第二。
![]()
感知榜单排名第一
![]()
认知榜单排名第二
昆仑万维天工大模型多模态团队最新一篇论文指出,在数据侧,为了解决幻觉问题,团队构造了更加多样和精细的微调数据,加强大模型对于图片特征的理解能力,增强多模态语言模型的指令跟随能力并减少“幻觉”。Skywork-MM在减少幻觉方面提升显著。
![]()
Skywork-MM还通过适当的数据构造,增强了中文的指令追随能力、中文相关场景的识别能力,减轻了文化偏差对于多模态理解的影响。例如,对于典型的中文场景中的电视节目《非诚勿扰》,现有大模型难以准确识别,但Skywork-MM中文场景识别能力很强。
![]()
在模型侧,在模型设计上团队将视觉模型和大语言模型完全冻结,保持视觉模型在前置CLIP训练中学习到的视觉特征不损失,大语言模型的语言能力不损失。同时为了更好的关联视觉特征和语言特征,模型整体包含了一个可学习的视觉特征采样器和语言模型的LoRA适配器。Skywork-MM模型的训练上,分为两个阶段,第一阶段使用双语的大规模图文pair数据进行图像概念和语言概念的关联学习;第二阶段使用多模态微调数据进行指令微调。
![]()
此外,Skywork-MM实际上使用的图文数据并不多(约50M),远远小于其他现有的MLLM使用的图文数据量(大于100M)。