背景
金融行业和运营商系统,业务除了在线联机查询外,同时有离线跑批处理,跑批场景比较注重吞吐量,同时基于数据库场景有一定的使用惯性,比如直连MySQL分库分表的存储节点做本地化跑批、以及基于Oracle/DB2等数据库做ETL的数据清洗跑批等。
分布式数据库使用多节点的设计,天然非常适合进行高并发的简单查询,但针对大规模的数据导入导出和分页查询等跑批场景,需要有更多面向并发导数的思考。
首先简单总结下,目前常见的业务跑批场景:
业务跑批处理
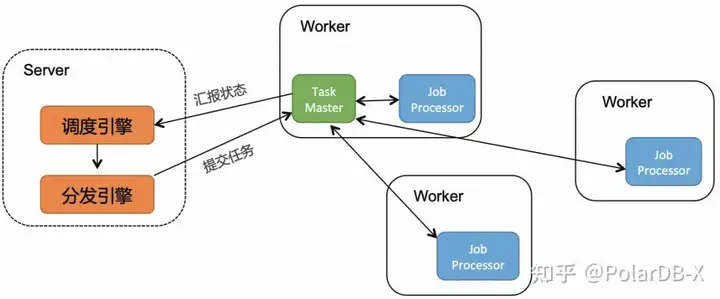
比如阿里的余额宝(亿级别的用户需要在每天进行利息结算)、淘宝收货自动确认(每天亿级别的用户订单需要定时确认),大致流程:
- 批量拉取用户列表,通过跑批框架按用户维度进行路由,分发需要处理的用户到应用的分布式多节点上
- 每个应用的跑批进程,会接收一定并发的用户处理,针对每个用户进行单独的select和业务计算,最后将结果写入数据库
- 跑批框架,针对分布式多节点各自的处理速度,进行动态调度和状态收集,确保所有用户结算任务均处理完毕
阿里云schedulerx文档: https://developer.aliyun.com/article/704121
![]()
数仓跑批处理
比如XX税务,在结算期开始会进行纳税信息的批量统计,大致流程:
- 大规模数据(亿级别),从在线数据库拖取全量数据到离线数仓(比如MaxCompute)
- 在离线数仓内部进行复杂的多阶段ETL计算
- 将最后的结果数据,批量回写到数据库,提供在线查询服务
特点:数据规模大,跑批过程中不需要关心事务 不足: 同时维护在线数据库和离线数仓两套系统,两套系统的数据同步延迟比较大,满足不了实时跑批的业务场景
数据库ETL批处理
数据库模式
比如电商订单业务,超时到期自动确认收货的批量更新,大致流程:
- 小规模数据(百万级别),直接通过在线数据库进行批量SELECT查询符合条件的数据
- 通过数据库的DML语句进行批量插入或者更新,业务计算过程中数据暂存会依赖临时表,同时会出现一定的大事务需求
特点:可支持事务场景,可满足实时跑批的业务场景;一套系统业务维护成本低,业务接入成本低 不足:支持的数据规模有限
中间件模式
比如很多广告计算系统,一般是是夜间做跑批校验,大致流程:
- 数据规模比较大(一般规模处于数仓和单机数据库容量之间),业务表已经按照业务模型做了拆分,业务上通过中间件方式直连各个拆分后的物理分表进行批量SELECT查询符合条件的数据;
- 通过中间件方式直接物理分表进行批量插入或者更新,计算过程中仍然可能通过数据暂存会依赖临时表(在拆分后的数据库中创建的);
- 在跑批过程中有一些大事务需求,或则事务内有跨拆分表的分布式事务,这种模式很难满足,往往会引入柔性事务,确保最终的一致性。
特点:可支持较大规模,也可满足最终一致性的跑批业务场景;业务接入成本低;相对于纯数据库方案,通过加存储节点,跑批性能可以做到完全线性扩展; 不足:有一定的开发成本,业务上需要感知DN的切换,自身要去维护DDL元数据一致性以及在扩缩容场景下的数据路由的一致性,只支持柔性事务
PolarDB-X 跑批实践
方案一:应用正常连接PolarDB-X CN节点
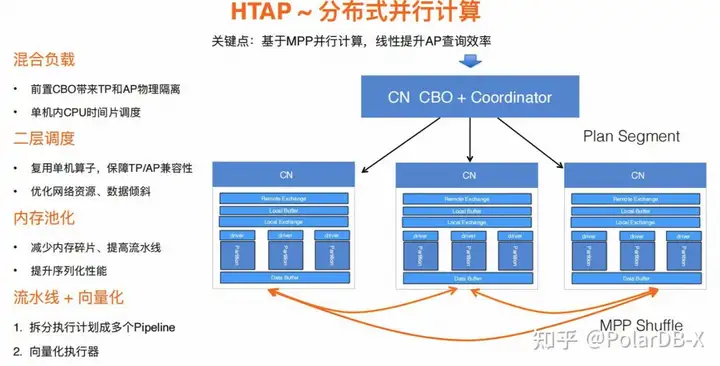
PolarDB-X的整个架构,分为CN/DN/GMS/CDC 4个核心组件,CN承担了业务流量的主要入口、以及承担串联分布式事务、DDL元数据、SQL执行路由等.
![]()
PolarDB-X作为分布式数据库,原生支持了MPP,支持跑批的大查询。同时业务正常访问CN链路,相比于直连DN的中间件模型跑批场景,可以有效规避以下架构问题:
- 屏蔽DN的多副本信息 (HA切换、读写分离)
- DDL元数据一致性 (业务动态加减列、ETL流程里建表)
- 数据路由的一致性 (在线扩缩容、热点迁移和均衡)
- 全局CDC的事务一致性 (事务顺序性、SQL闪回)
![]()
相当于单机数据库,PolarDB-X分布式数据库,可以支持更大规模的跑批场景。但分布式数据库由于其数据分片以及架构特点,在分页场景上往往很难做到跑批性能随着资源增加做到线性扩展。可参考《分布式数据库的分页场景的最佳实践》。
建议:用户对于小规模数据(百万级别),可以正常访问PolarDB-X当做单机库来做跑批处理。
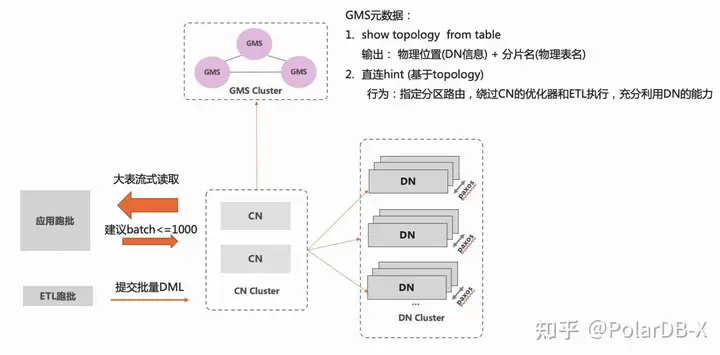
方案二:分区hint直连访问,线性提升跑批处理性能
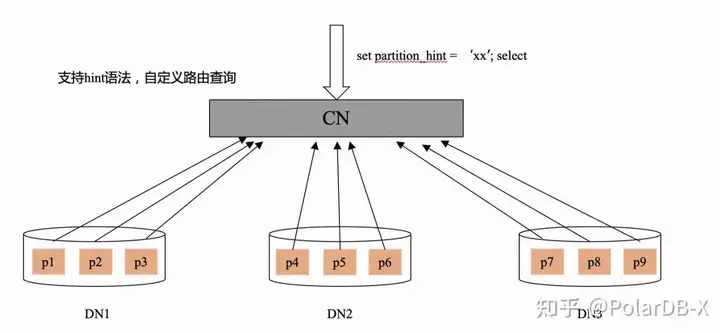
用户通过直连PolarDB-X CN进行跑批数据的读和写,需要最大化的利用分布式多节点资源的并行性,达到线性扩展的性能。 PolarDB-X提供了分区Hint直连访问的方案,例如:
select * from orders partition(p1) order by gmt_create,id desc
引入partition关键字,允许用户直接指定分区id进行直连访问,规避分布式下跨多数据分片场景的分页排序问题。
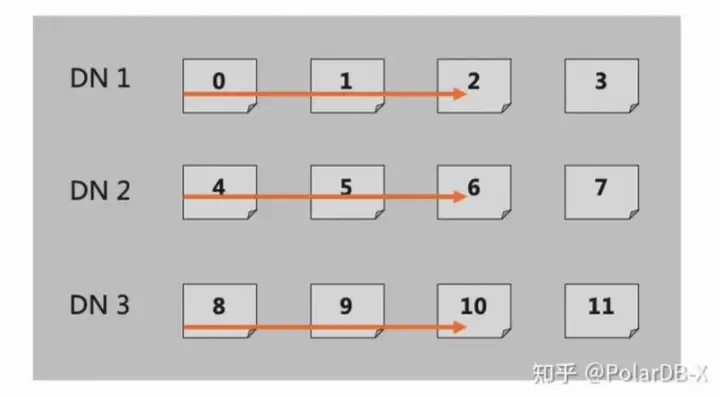
金融行业用户的跑批场景适配,在传统MySQL分库分表上的典型使用,比如:MySQL分库分表后分了128个分片,应用会启动128个并发,每个并发创建一个数据库连接,一个链接固定访问一个数据分片。 这种分库分表的并发拆分方案,很好的满足了吞吐量的并发需求,PolarDB-X 在 5.4.17 版本提供了兼容传统MySQL分库分表迁移到PolarDB-X的跑批使用,在分区hint直连访问的基础上,允许在链接session级别绑定访问分区(比如:1个链接要访问20张逻辑表,通过在session级别设置分区hint P1,可以让当前链接默认访问所有分布式表,都是直接访问分区P1,减少用户的改造成本)。
分布式线性扩展性的设计原则,需要逻辑和物理查询尽可能做到1:1,这样随着DN节点的在线扩容,整体容量和吞吐能力可以达到线性增加。
![]()
- 相较于直接CN的分布式数据库跑批方式
- 业务上更加灵活的配置并行策略:基于DN节点的物理拓扑,按DN维度均匀做并行处理,性能更好。
- 在完全兼容传统的中间件跑批模式,可以享受到分布式数据库下已有的能力
- 屏蔽DN的多副本信息 (HA切换、读写分离)
- DDL元数据一致性 (业务动态加减列、ETL流程里建表)
- 数据路由的一致性 (在线扩缩容、热点迁移和均衡)
- 全局CDC的事务一致性 (事务顺序性、SQL闪回)
- 支持分布式事务
![]()
建议:可支持较大规模,也可满足最终一致性的跑批业务场景。跑批过程中的DDL需要特殊处理(忽略分区hint)、以及数据分片要遵循相同的分区规则。
Session级别支持分区Hint 设计方案
概述
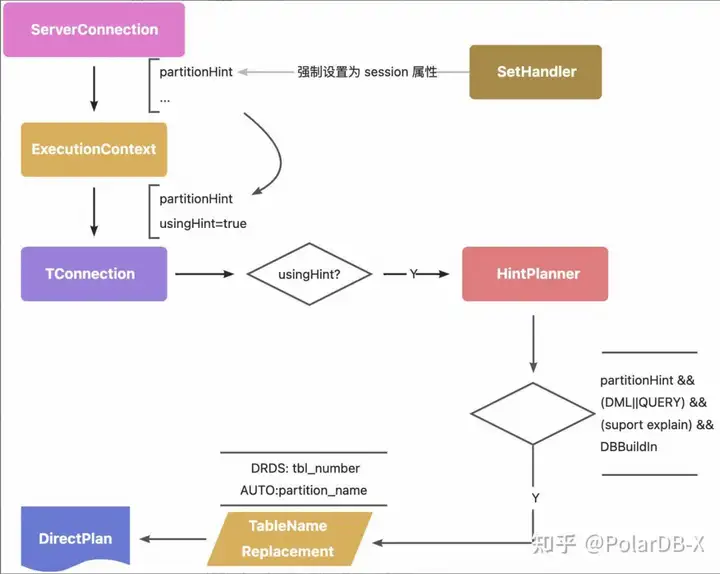
在 ServerConnection 中配置一个属性 partition_hint, 当属性不为空时,将 DML 请求进行特殊的下推处理.复用 HintPlanner 中的逻辑,并在强制下推时根据 partition_hint 的内容替换请求中的表名.
![]()
思路
partition hint 的作用域
通过设置非空串启用,设置空串使其无效
partition hint 一旦生效后,会影响 session 上面执行的所有 dml,因此需要将该配置严格限制在 ServerConnection 上面.避免作为一般的 CN 配置产生全局影响.
控制链路为 SetHandler -> ServerConnection 单向变更, 不受 meta.inst_config 的影响. 作用链路为 ServerConnection -> TConnection -> ExecutionContext -> HintPlannner ServerConnection 每次请求都会根据自身 partitionHint 属性刷新 ExecutionContext 中的 partition hint 配置
SQL 类型判断与 BuildInDB 识别
以下 SQL 类型不受 Session hint 影响
- Show 指令与 DAL: grant, kill, show tables, show topology 等指令可以正常工作,不受 hint 影响
- DDL 指令可以正常工作在逻辑层面,不受 hint 影响
- Information_schema/cdc/polardbx 等 buildin DB 不受 hint 影响
- 部分 Explain 指令不受影响,注意以下 explain 会忽略 partition hint
- Explain Optimizer :需要进入 cbo
- Explain Advisor :需要进入 cbo
- Explain Statistics :需要进入优化器
- Explain JsonPlan :需要进入优化器
- Explain Execute :执行路径与 direct mode 冲突
- Explain Sharding :需要进入优化器
物理表名替换逻辑
sharding 库针对分库不分表的 direct mode, 会自动进行物理表名替换; 针对分库又分表的情况会忽略,默认由请求发起方自行感知并处理物理表名 session hint 需要增加以下替换逻辑:
- drds 模式下,set partition_hint='group_name_0xx',其中0xx代表分库分表下的分表序号. 与 node hint 不同点在于, partition hint 本质上配置的是分表序号,请求发起端只需要感知需要访问的表有几个 group, 每个group 有几个分表
- auto 模式下,set partition_hint='分区名' . auto 模式目前一个 partition 中只有一个分表, 因此配置了 auto 表的 partition name, 相当于定位到了具体的分表
约束与行为
- partition hint 与原有的下推 hint 在设计上完全不同,因此需要避免下推 hint 对 partition hint 的影响. 如果发现下推 hint 与 partition hint 同时起作用则报错处理.
- drds 模式下访问的各个拆分表, 分表数量应该完全一致.
- partition hint sql 访问 braodcast 表时, 直接替换物理表名,不要求 hint 的 partition name 与 broadcast 表一致
- auto 模式下访问的所有非 broadcast 逻辑表, 必须处于相同的 tablegroup 下面
FLASH BACK
在跑批场景, 业务方有可能需要各个分库拖数据时确保数据的一致性.如有这种需求, 理论上可以通过 flash back 的时间戳来确保各分库处理数据时全局的一致性.
select * from T AS of TIMESTAMP '2022-03-11 09:00:00'
异常路径及错误码
- sharding 表, 在 partition hint 设置了 groupname, 但没有配置分表 index 的情况下, 如果涉及的拆分表有多个分表, 此时会因为无法找到对应分表而报错:
Unsupported to use direct HINT for part table that has multi physical tables in one partition
- sharding 表, 在 partition hint 设置的分表 index 超出最大分表数量的情况下会报错:
table index overflow in target group from direct HINT for sharding table
- sharding 表, 根据 partition hint 设置的 groupname 找不到对应的 group 时报错:
cannot find target group from direct HINT for sharding table
- sharding 表, 涉及到的各表在 partition hint 配置的 group 中, 分表数不同则会报错:
different sharding table num in partition hint mode
- auto 表, 请求涉及到的各表归属的 table group 不同则报错:
different table group in partition hint mode
- partition hint 模式下不支持跨 schema 访问,如果跨 schema 访问则会报错:
partition hint visit table crossing schema
- partition hint 不支持与其它下推 hint (/TDDL:node=0/ 等)同时使用, 如果同时使用则报错:
Unsupported to use direct HINT and session partition hint in the same time
- partition hint 模式下如果想执行 dml 变更数据内容, 如 insert/update/delete 等操作, 需要确保 ENABLE_FORBID_PUSH_DML_WITH_HINT 参数设置为 false, 该参数默认为 true. 否则会报错:
Unsupported to push physical dml by hint
- partition hint 模式下如果对 auto 表配置了不存在的 partition name, 则会报错:
ERR-CODE: [TDDL-4998][ERR_NOT_SUPPORT] Unsupported to use direct HINT for part table that has multi physical tables in one partition not support yet!
特殊场景及注意事项
partition hint 对 broadcast 表不起作用, partition hint 模式下访问 broadcast 表时,默认使用 default group.如果请求中有其它的非 broadcast 表, 则以其它表的 group 为准
partition hint 模式下不支持一条请求中仅访问物理表, 但是可以支持逻辑表与物理表在一条请求中的访问.注意物理表必须存在于逻辑表 partition hint 设置的 group 中
Session Hint 使用方式
使用语法
提供session级别的变量,控制路由。Polardbx 可以通过设置 partition hint, 直接访问某 DN 分片. 设置的方式为 set 指令,语法如下所示 :::info SET PARTITION_NAME=[PARTITION_NAME|GROUP_NAME|GROUP_NAME:TABLE_INDEX] :::
- PARTITION_NAME 指 auto db 中表的 partition_name 属性
- GROUP_NAME 指 drds db 中表所在的 GROUP_NAME
- drds db 中某 GROUP 存在多个分表时, TABLE_INDEX 指该分表在该 GROUP 中的 index,从 0 开始
示例:
set session PARTITION_HINT= [partion_info] #partion_info代表路由信息
在auto模式下, 可配置partition name
partion_info:
[p1|p2|p3...|pn]
在drds模式下,分库不分表下,可配置group name
partion_info:
[group1|group2|group3...|group4]
在drds模式下,分库分表下,可配置group name:index,其index表示分表的Table ID
partion_info:
[[group1:01]|[group1:02]|[group2:03]...|[groupn:04]]
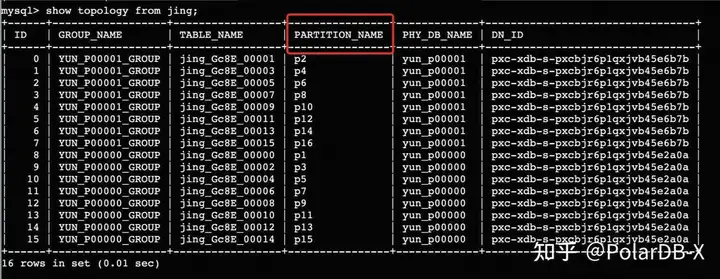
如何获取PolarDB-X物理拓扑,既partion_info
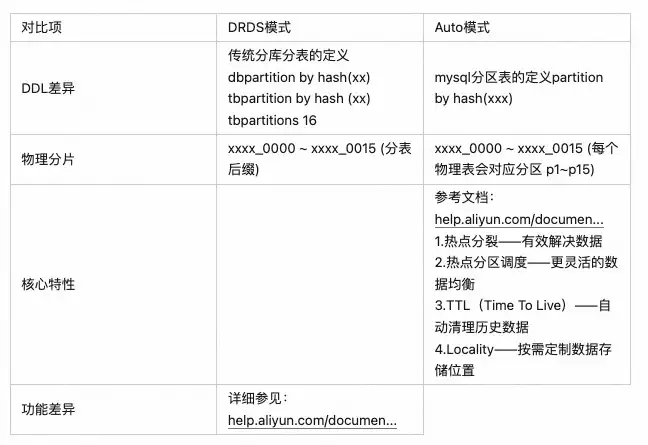
PolarDB-X提供两种分区模式,drds模式和auto模式。
![]()
相关指令:
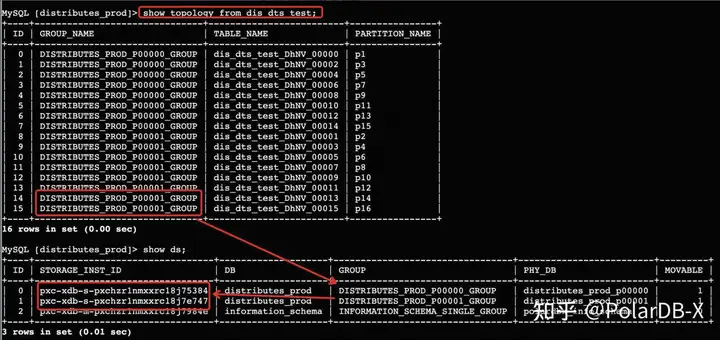
- show topology from table ,返回某张逻辑表下的物理拓扑,GROUP_NAME代表DN里的物理库,TABLE_NAME代表DN里某个库下的物理表名
- show ds,返回PolarDB-X实例下DN和GROUP物理库的对应关系
DRDS模式:
![]()
Auto模式:
![]()
如何配置连接池使用直连DN的session hint
步骤一:选择Druid连接池 参考文档:https://help.aliyun.com/document_detail/311220.html
httpsetail/311220.html
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<!-- 基本属性 URL、user、password -->
<property name="url" value="jdbc:mysql://ip:port/db?autoReconnect=true&rewriteBatchedStatements=true&socketTimeout=30000&connectTimeout=3000" />
<property name="username" value="" />
<property name="password" value="" />
.....
<!-- 设置物理连接创建后立即执行的初始SQL,多条语句可用分号分隔 -->
<property name="connectionInitSqls" value="set partition_hint=XXXX_000001_GROUP;"/>
</bean>
参数说明:connectionInitSqls,是Druid连接池提供的一个通用能力,可以设置物理连接创建后立即执行的初始SQL,多条语句可用分号分隔。
例子:connectionInitSqls="set partition_hint=XXXX_000001_GROUP;" 设置链接直连DN的session hint,参数解读:
- drds模式,格式为:partition_hint=:,对应GROUP_NAME为拓扑元数据DN里的物理库。目前1个连接仅能设置1个GROUP,如果有64个分库需要配置64个Druid连接池。TABLE_INDEX 是分表的在该 GROUP 中的下标.每个 GROUP 从 0 开始. 如果 GROUP 中只有一张分表则可以不配置
- auto模式,格式为:partition_hint=,对应的PARTITION_NAME为拓扑元数据里的partition_name信息。目前1个连接仅能设置1个Partition,如果有64个分片需要配置64个Druid连接池。
通过 show full connection 观察所有连接的 partition hint 启用情况
show full connection 会显示所有 connection 的 PARTITION_HINT 的设置情况。
mysql> show connection\G
*************************** 1. row ***************************
ID: 2
HOST: 127.0.0.1
PORT: 52027
LOCAL_PORT: 8527
SCHEMA: drds_polarx1_part_qatest_app
CHARSET: utf8mb4
NET_IN: 11238
NET_OUT: 728997
ALIVE_TIME(s): 152
LAST_ACTIVE(ms): 0
CHANNELS: 0
TRX: 0
NEED_RECONNECT: 0
1 row in set (0.01 sec)
mysql> show full connection\G
*************************** 1. row ***************************
ID: 2
HOST: 127.0.0.1
PORT: 52027
LOCAL_PORT: 8527
SCHEMA: drds_polarx1_part_qatest_app
PARTITION_HINT: P3
CHARSET: utf8mb4
NET_IN: 11238
NET_OUT: 728997
ALIVE_TIME(s): 152
LAST_ACTIVE(ms): 0
CHANNELS: 0
TRX: 0
NEED_RECONNECT: 0
1 row in set (0.01 sec)
使用例子
访问 auto模式 库下分区
mysql> create database if not exists partition_hint_test mode=auto;
mysql> use partition_hint_test
mysql> CREATE TABLE if not exists `partition_hint_test_tbl1` (
`a` datetime NOT NULL,
primary key(a)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
PARTITION BY RANGE(YEAR(a))
(PARTITION p0 VALUES LESS THAN (1990) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (2000) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (2010) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (2020) ENGINE = InnoDB);
mysql> insert into partition_hint_test_tbl1(a) values('1989-10-01'), ('1999-11-01'),('2001-08-19');
# 未设置 partition_hint 时, 正常访问逻辑表
mysql> select * from partition_hint_test_tbl1;
+---------------------+
| a |
+---------------------+
| 1999-11-01 00:00:00 |
| 2001-08-19 00:00:00 |
| 1989-10-01 00:00:00 |
+---------------------+
3 rows in set (0.04 sec)
# 设置了 partition_hint 之后, 只会访问配置分片的物理表
mysql> set partition_hint=p0;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from partition_hint_test_tbl1;
+---------------------+
| a |
+---------------------+
| 1989-10-01 00:00:00 |
+---------------------+
1 row in set (0.01 sec)
# 设置 partition_hint 为空串后, 恢复访问逻辑表的逻辑
mysql> set partition_hint='';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from partition_hint_test_tbl1;
+---------------------+
| a |
+---------------------+
| 1999-11-01 00:00:00 |
| 2001-08-19 00:00:00 |
| 1989-10-01 00:00:00 |
+---------------------+
3 rows in set (0.03 sec)
访问 drds模式 库下分库分表
mysql> create database if not exists partition_hint_test_drds mode=drds;
Query OK, 1 row affected (1.29 sec)
mysql> use partition_hint_test_drds
Database changed
mysql> CREATE TABLE if not exists multi_db_multi_tbl(
-> id bigint not null auto_increment,
-> bid int,
-> name varchar(30),
-> primary key(id)
-> ) dbpartition by hash(id) tbpartition by hash(bid) tbpartitions 3;
Query OK, 0 rows affected (1.37 sec)
mysql> show topology from multi_db_multi_tbl;
+------+---------------------------------------+---------------------------+----------------+
| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME |
+------+---------------------------------------+---------------------------+----------------+
| 0 | PARTITION_HINT_TEST_DRDS_000000_GROUP | multi_db_multi_tbl_tqyJ_0 | - |
| 1 | PARTITION_HINT_TEST_DRDS_000000_GROUP | multi_db_multi_tbl_tqyJ_1 | - |
| 2 | PARTITION_HINT_TEST_DRDS_000000_GROUP | multi_db_multi_tbl_tqyJ_2 | - |
| 3 | PARTITION_HINT_TEST_DRDS_000001_GROUP | multi_db_multi_tbl_tqyJ_0 | - |
| 4 | PARTITION_HINT_TEST_DRDS_000001_GROUP | multi_db_multi_tbl_tqyJ_1 | - |
| 5 | PARTITION_HINT_TEST_DRDS_000001_GROUP | multi_db_multi_tbl_tqyJ_2 | - |
| 6 | PARTITION_HINT_TEST_DRDS_000002_GROUP | multi_db_multi_tbl_tqyJ_0 | - |
| 7 | PARTITION_HINT_TEST_DRDS_000002_GROUP | multi_db_multi_tbl_tqyJ_1 | - |
| 8 | PARTITION_HINT_TEST_DRDS_000002_GROUP | multi_db_multi_tbl_tqyJ_2 | - |
| 9 | PARTITION_HINT_TEST_DRDS_000003_GROUP | multi_db_multi_tbl_tqyJ_0 | - |
| 10 | PARTITION_HINT_TEST_DRDS_000003_GROUP | multi_db_multi_tbl_tqyJ_1 | - |
| 11 | PARTITION_HINT_TEST_DRDS_000003_GROUP | multi_db_multi_tbl_tqyJ_2 | - |
+------+---------------------------------------+---------------------------+----------------+
mysql> insert into multi_db_multi_tbl(bid, name) values(1, 'a'),(2, 'b'),(3,'c');
Query OK, 3 rows affected (0.00 sec)
mysql> set partition_hint='';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from multi_db_multi_tbl;
+--------+------+------+
| id | bid | name |
+--------+------+------+
| 200009 | 3 | c |
| 200008 | 2 | b |
| 200007 | 1 | a |
+--------+------+------+
3 rows in set (0.03 sec)
mysql> set partition_hint='PARTITION_HINT_TEST_DRDS_000003_GROUP:1';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from multi_db_multi_tbl;
+--------+------+------+
| id | bid | name |
+--------+------+------+
| 200007 | 1 | a |
+--------+------+------+
1 row in set (0.02 sec)
访问 drds模式 库下分库不分表
mysql> create database if not exists partition_hint_test_drds mode=drds;
Query OK, 1 row affected (1.29 sec)
mysql> use partition_hint_test_drds
Database changed
mysql> CREATE TABLE if not exists multi_db_single_tbl(
-> id bigint not null auto_increment,
-> name varchar(30),
-> primary key(id)
-> ) dbpartition by hash(id);
Query OK, 0 rows affected (0.93 sec)
mysql> show topology from multi_db_single_tbl;
+------+---------------------------------------+--------------------------+----------------+
| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME |
+------+---------------------------------------+--------------------------+----------------+
| 0 | PARTITION_HINT_TEST_DRDS_000000_GROUP | multi_db_single_tbl_pccs | - |
| 1 | PARTITION_HINT_TEST_DRDS_000001_GROUP | multi_db_single_tbl_pccs | - |
| 2 | PARTITION_HINT_TEST_DRDS_000002_GROUP | multi_db_single_tbl_pccs | - |
| 3 | PARTITION_HINT_TEST_DRDS_000003_GROUP | multi_db_single_tbl_pccs | - |
+------+---------------------------------------+--------------------------+----------------+
4 rows in set (0.01 sec)
mysql> insert into multi_db_single_tbl(name) values('a'),('b'),('c');
Query OK, 3 rows affected (0.05 sec)
mysql> set partition_hint=PARTITION_HINT_TEST_DRDS_000003_GROUP;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from multi_db_single_tbl;
+--------+------+
| id | name |
+--------+------+
| 100003 | c |
+--------+------+
1 row in set (0.01 sec)
mysql> set partition_hint='PARTITION_HINT_TEST_DRDS_000003_GROUP:0';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from multi_db_single_tbl;
+--------+------+
| id | name |
+--------+------+
| 100003 | c |
+--------+------+
1 row in set (0.02 sec)
mysql> set partition_hint='';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from multi_db_single_tbl;
+--------+------+
| id | name |
+--------+------+
| 100003 | c |
| 100002 | b |
| 100001 | a |
+--------+------+
3 rows in set (0.04 sec)
典型场景的附加能力
跨分片写的分布式事务
在session hint直连场景,也支持分布式事务,满足数据的一致性
# 开启事务
mysql> begin;
# 设置了 partition_hint 之后, 操作物理表1
mysql> set partition_hint=p0;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into partition_hint_test_tbl1 values ("a", 1);
Query OK, 1 rows affected (0.01 sec)
# 设置了 partition_hint 之后, 操作物理表2
mysql> set partition_hint=p2;
mysql> insert into partition_hint_test_tbl2 values ("b", 1);
Query OK, 1 rows affected (0.01 sec)
# 提交事务
mysql> commit;
跨分片事务读的强一致性
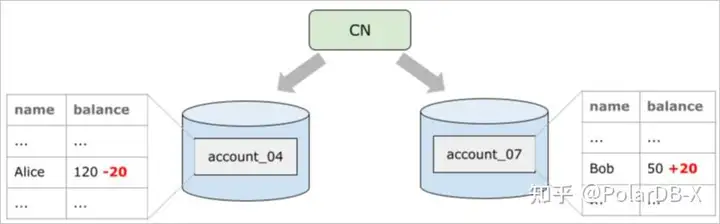
以转账场景为例,假设用户账户是一张分区表,那么同一笔转账交易的转入方和转出方很可能位于不同的数据节点上
BEGIN;
UPDATE account SET balance = balance - 20 WHERE name = 'Alice';
UPDATE account SET balance = balance + 20 WHERE name = 'Bob';
COMMIT;
![]()
通过多个物理链接,设置不同的直连hint来访问物理数据,会出现account_04 和 account_07在不同的数据库连接上,会导致这两个连接是两个独立的MVCC事务,会出现看到转账数据总和不一致的情况。 解决办法:
# 业务跑批开始
# 打开一个链接A
set autocommit=0;
mysql> set partition_hint=p0;
# 设置了 partition_hint 之后, 指定时间点T,扫描物理表1
mysql> select * from partition_hint_test_tbl1 AS of TIMESTAMP '2022-03-11 09:00:00'
# 打开一个链接B
set autocommit=0;
mysql> set partition_hint=p2;
# 设置了 partition_hint 之后, 同样指定时间点T,扫描物理表2
mysql> select * from partition_hint_test_tbl2 AS of TIMESTAMP '2022-03-11 09:00:00'
借助FLASH BACK语法,根据用户指定时间点的构建一致性视图。
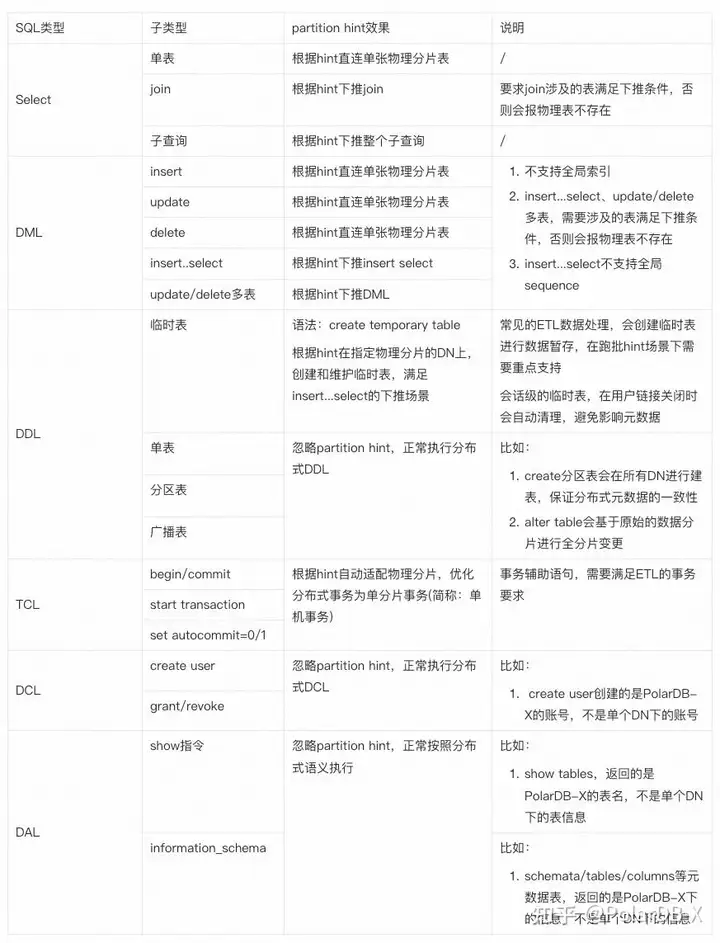
业务SQL操作总结
![]()
需要注意和理解的事项
路由一致性
常见的跑批SQL中,一般会有如下特征:
- 事务语句,比如set autocommit/commit等
- DML语句,比如批量insert、复杂update/delete等
- create tmp表 + Insert...select语句,暂存中间数据
- select语句,比如cursor流式查询一张大表
在直连hint的设计目标是基于数据分片的物理分布,最大化的提升吞吐量,尽可能将所有操作都直接下推到单个DN节点,比如:
- insert...select场景,全下推DN执行相比于分布式路由执行,会有2~3倍的提升
- 基于session hint,将所有的分布式事务自动优化为单机1PC事务,减少2PC的网络交互
基于直连hint的设计,会对业务有一定的约束和要求:
- DML语句,不能修改分片字段的值(比如常见的分片字段,一般为用户id),否则会导致数据和实际路由规则不一致
- insert...select语句,不能变更自增ID列的值,否则会导致自增ID不唯一,同时insert..select涉及的表分片规则和分片数要保持一致,同时都带上分片字段,确保数据路由的正确性
分布式元数据一致性
常见的ORM框架,会通过meta元数据自动构建SQL语句,比如
- 查询information_schema下的库表和字段等相关信息,比如schemata/tables/columns等
- 通过DAL查询库表和字段等相关信息,比如show databases/show tables/show columns/show create table等
存在的问题: 物理DN上对应的表名为orders_0001,如果直连DN访问元数据,会导致逻辑表和物理分片信息元数据对不齐,导致报错 解决办法:元数据不受直连hint的影响,直接访问分布式的元数据,确保多分片场景下的元数据对齐。
其他一些注意事项
- 物理表中的隐藏主键。PolarDB-X针对业务创建表不含主键,会自动为该逻辑表建立隐式主键, 此时通过 session hint 直接访问 db 分片的话, select * 会使隐式主键暴露, 需要注意此时的返回类型差异;
- Session hint 默认不支持 dml 变更数据。如果业务上确实需要通过 Session hint 直连 db 变更数据,可以设置set ENABLE_FORBID_PUSH_DML_WITH_HINT=false,设置该参数后直连DB变更数据有以下风险:
- 数据写入到错误的分片导致逻辑表的访问无法感知
- 带 gsi 的逻辑表会出现数据不一致
- 广播表会出现各表不一致
- 在parition变量的设置的前提下,不支持带了库名的查询,比如
# 设置test库的p0 hint
mysql> set partition_hint=p0;
#不支持
mysql> select * from test.t1;
- 在partition变量设置的前提下,不支持业务表和information_schema做关联查询,因为业务库表会被下推;而information_schema库不下推。
- 在drds/auto模式库下正常的扩缩容不会影响分区名或者GROUP名的变更,但在auto模式库下支持更灵活的分区变更能力(比如:分区rehash、热点分区、分裂合并等操作), 由于partition个数或名称发生了变化,业务上通过partition_hint指定的值需要同步做下修改。
云原生数据库PolarDB分布式版新增标准版形态,基于X-Paxos提供100%兼容MySQL的高可靠性集中式数据库服务。
作者:方物
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。