本篇文章主要介绍在实际的开发过程当中,如何使用GPT帮助开发,优化流程,恰逢今年京东20周年庆,文末会介绍如何与618大促实际的业务相结合,来提升应用价值。全是干货,且本文所有代码和脚本都是利用GPT生成的,请放心食用。
场景一:写代码
使用GPT进行代码开发是许多人做的最多的一件事,只要用自然语言把自己的需求描述清楚,就可以让GPT写出一段可执行的代码段,甚至是完整的应用。而且只要描述得足够明确清晰,产生的代码就不会有bug,非常高效。
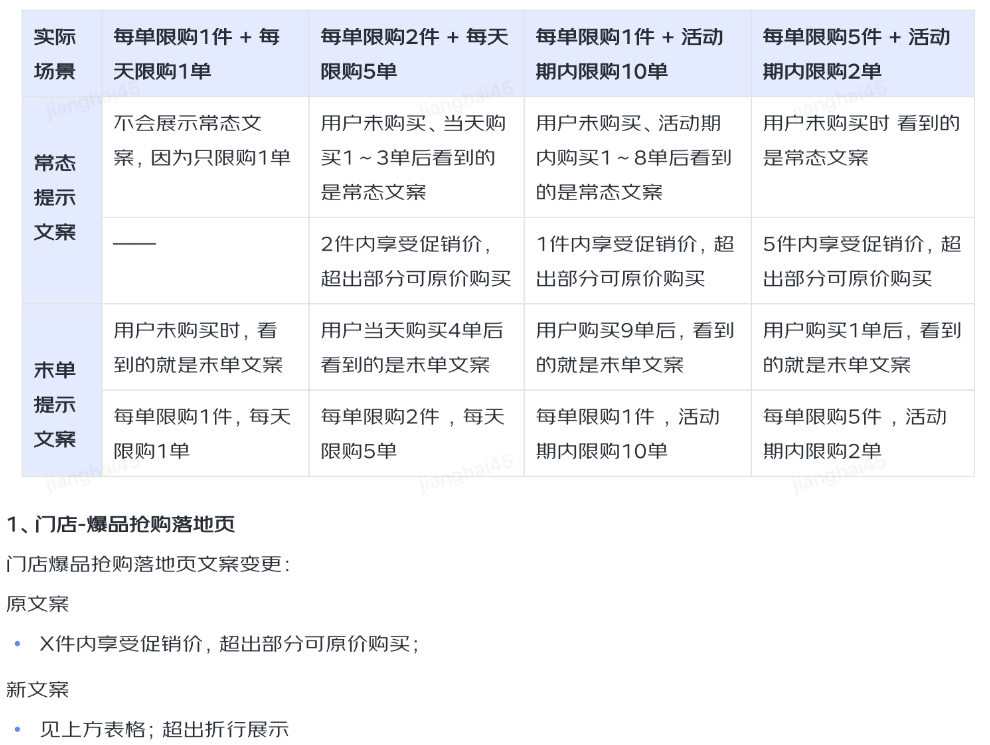
举个实际应用的例子,在先前的版本我们工程有一个需求,要求对落地页的提示黄条UI进行改版,具体的需求描述为:
![]()
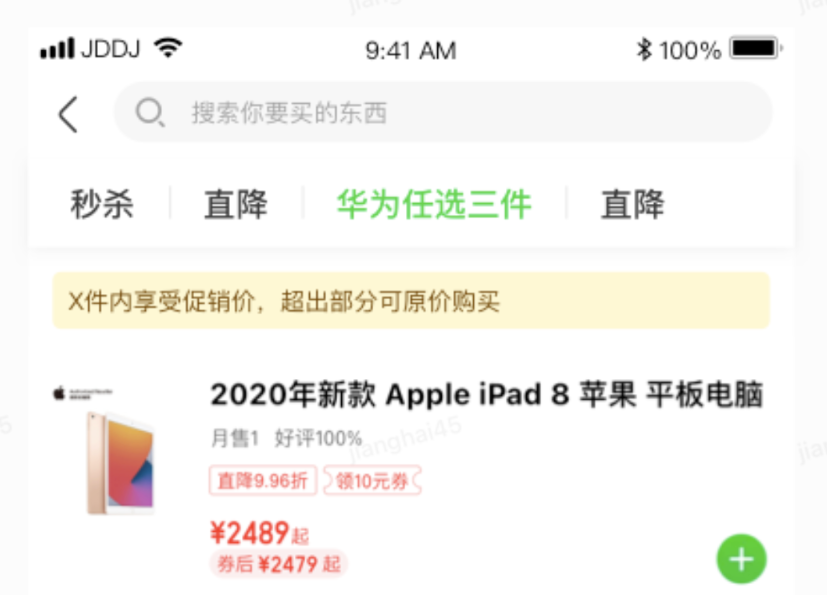
UI设计稿:
![]()
这是一个相当简单的需求,我们准备利用Flutter进行开发,现在假设我是一个对dart语言不是很了解的开发者,甚至是从没有Flutter开发基础的人,通过GPT我们也可以进行这种简单的开发工作。在对GPT进行描述的时候,要尽量用通顺的语言将自己的需求描述清楚,并且将关键的信息点名:
![]()
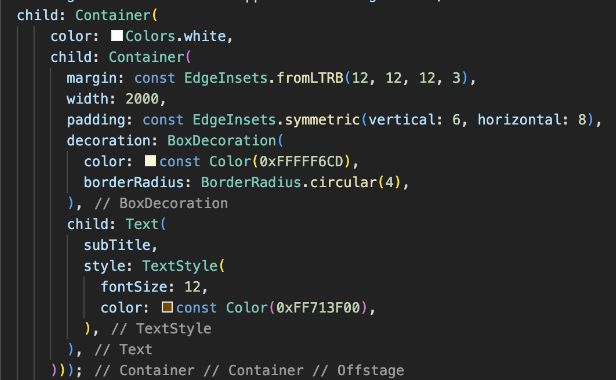
这样GPT就可以帮我们生成所需要的视图代码:
![]()
这对于没有接触过dart开发语言的开发者非常友好,由于可以任意指定编程语言,所以理论上,我们所有人都可以胜任全平台开发的工作。
我总结了在使用GPT进行代码开发时的重点:
1.主要信息一定要表达明确,如语言类型,目标类型,宽、高、颜色、字号,间距等数值。
2.想象自己是产品经理或者是设计师,不用拘泥于专业术语,例如UIview、Segment、标签等等,尽量使用自然语言表达。
3.不要存在自相矛盾的描述,100%会产生bug。
4.有些同学在描述需求的时候容易紧张,造成语句不通。在描述的时候完全可以不要着急,慢慢措辞。
5.不要涉密!不要涉密!不要涉密!GPT说到底是一个外部工具软件,不是一个什么问题都可以问的“树洞”,涉及到商业机密的问题都不可以拿来询问。
场景二:写脚本
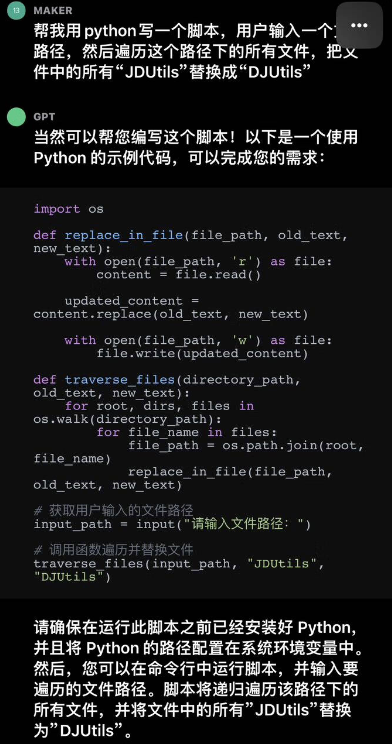
这是我本人经常拿来使用的应用场景,对于一些重复性较高的劳动,编写脚本显然是最好的选择,甚至我有的同事认为,未来的发展方向就是脚本编写代码。脚本的开发完全也可以交由GPT来进行。比如我们有一个需求,由于接入主站基础库,我们有一些工具类的类名产生了冲突,这种情况下需要进行全工程的类名替换,这种场景就很适合使用脚本。
![]()
一般情况下写这样一个脚本至少需要1~2个小时左右,熟练的大佬也需要半个小时左右,但是使用GPT,几秒钟就可以生成符合要求的脚本。我总结一下的几种应用场景非常适合使用脚本来处理:
1.全工程级别的名称替换
2.APP图片名称替换
3.单元测试
4.转换自然语言
这里说一下转换自然语言的作用,作为开发者,更习惯的是输入关键数值来得到结果,但是GPT需要的是自然语言的描述,毕竟叫“chat”嘛,所以我们可以耍个小心机:用一个简单的脚本,输入数值,输出自然语言描述,然后将描述转达给GPT。
width = int(input("请输入宽度:"))
height = int(input("请输入高度:"))
color = input("请输入颜色:")
view = '#' * width + '\n'
view += ('#' + ' ' * (width - 2) + '#\n') * (height - 2)
view += '#' * width
description = f"生成一个宽度为{width},高度为{height}的视图,使用{color}颜色填充。"
print(view)
print(description)
类似于这种转换脚本,可以让我们更高效的使用GPT。
场景三:与实际业务结合
我之前的文章最后曾提到几种将GPT与实际业务结合的设想:
导购
把ChatGPT的服务集成到搜索功能中,在用户进行搜索的时候,利用他强大的功能给出用户购买的意见,对于还没有想好买不买,买那个,甚至没有想好买什么的用户,给出导向性的意见,促进转化率。
软文创作
我们的项目中有软性广告文章展示的适用场景,相比起人工创作写作,ChatGPT不仅更为高效,还能结合大数据趋势,给出用户更感兴趣的文章类型。创作优惠活动推荐,商品评价,新品新闻等等文章,使用ChatGPT大有可为。
反向活动推荐
我们不能决定用户询问ChatGPT时,他会给出什么样的答案,但是我们可以根据她的答案做反向推演,他推荐什么,我们就顺势做什么活动,这样我们既能利用ChatGPT带来的红利,又可以省去预测用户兴趣点带来的开销和风险。
售后
ChatGPT本质上是一个对话型的人工智能,使用他接入售后系统实际上最为合适,有了他的帮助,可以预见:用户抱怨机器人客服答非所问,无法解决问题,以及人工客服成本高昂的问题,将成为历史。
我认为这几种设想每一个都是可以投入实际应用并落地的,也都有相当的使用价值。接下来我主要介绍如何利用GPT进行618大促导购。
首先,用户对某种商品进行搜索,主要是通过搜索栏,我们在要将GPT接入搜索进行引导,就要自己搭建一套基础环境,将用户输入的关键词传递给GPT,再把GPT输出的结果展示给用户,基础环境的作用除了作为调用GPT的“服务器”,最后可以对用户的输入,以及GPT的输出进行“加工”,包装上“京东20周年庆”、“618大促”的相关信息,最终实现“大促导购”的目的。
第一部分:对用户的输入进行包装,比如对用户的关键词包上一层“用京东搜索”的外衣:
def search_keyword(keyword):
url="https://search.jd.com/Search?keyword={keyword}"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
#提取相关介绍
introduction = soup.select_one(".p-parameter").get_text(strip=True)
return introduction
#用户输入关键词
user_input = input("请输入关键词:")
#调用函数进行搜索和提取介绍
result = search_keyword(user_input)
prompt="打开京东网站,618大促活动商品里搜索 {user_input},并给出其相关介绍"
#这里的prompt既为向GTP提问的问题,由于GPT接受的是自然语言,所以这里我们可以任意的添加我们想要的导向性描述,例如“618大促活动商品”、“618精选活动”、“京东20周年庆优惠”等等
第二部分:将包装好的文案作为入参,调用GPT的API进行请求
api_endpoint = "https://api.openai.com/v1/chat/completions"
access_token = "你的access_token"
params = {
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7,
"model": "gpt-3.5-turbo"
}
headers = {
"Authorization": "Bearer {access_token}",
"Content-Type": "application/json"
}
response = requests.post(api_endpoint, headers=headers, json=params)
第三部分:对GPT返回的结果进行解析,并按照我们的需求进行展示
if response.status_code == 200:
response_text = json.loads(response.text)["choices"][0]["message"]["content"]
# 输出结果
print("为您在京东推荐了如下结果: {response_text}")
print("您商品的相关介绍:{result}”)
else:
print(f"error: {response.status_code} - {response.text}")
发散思维:GTP接受的是自然语言询问,所以在向他提问的问题中,我们可以任意的添加想要的限定信息,甚至可以结合配置系统,将“618大促活动商品”、“618精选活动”、“京东20周年庆优惠”等活动作为配置信息组合进prompt参数字段,实现动态配置活动导购。
作者:京东零售 姜海
来源:京东云开发者社区