摘要:本期结合示例,详细介绍华为云数字工厂平台的数据分析模型和数据图表视图模型的配置用法。
本文分享自华为云社区《数字工厂深入浅出系列(六):数据分析与图表视图模型的配置用法》,作者:云起MAE 。
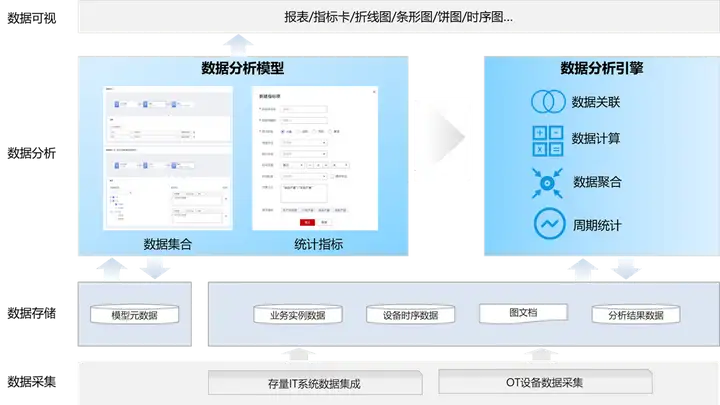
华为云数字工厂平台基于“数据与业务一体化”理念,提供统一的制造全域数据平台底座,内置轻量级制造数据分析引擎与可视化工具,支持IT/OT全域多模态数据的动态建模、采集、存储、分析和可视化应用,提供图形化的数据分析模型配置器,自动读取数字工厂平台的9类业务信息模型及其数据关联关系,能够让不懂技术的业务人员也可以自助式完成数据分析建模。数据分析模型,可搭配平台提供的视图模型配置器,快速搭建数据图表与看板,实现数据分析结果的可视化呈现。
![]()
华为云数字工厂平台的数据分析模型目前支持两类:
- 数据集:用于关联聚合多个业务模型的数据,支持多层关联、数据计算和多维度聚合统计;也支持手工创建外部数据集,来存储从外部系统采集的数据,以及进一步实现数据可视化或者与数字工厂平台的业务模型数据进行关联分析;
- 统计指标:用于实时统计或者周期性统计业务数据,业务数据可来自原始业务模型的实例数据字段值,也可来自分析模型的某个数据集字段;支持复合指标建模,即引用已有的统计指标进行组合计算。
本期结合示例,详细介绍华为云数字工厂平台的数据分析模型和数据图表视图模型的配置用法。
(一)示例场景说明
本期通过配置实现以下3个数据分析建模示例,来详细介绍分析模型的使用方法:
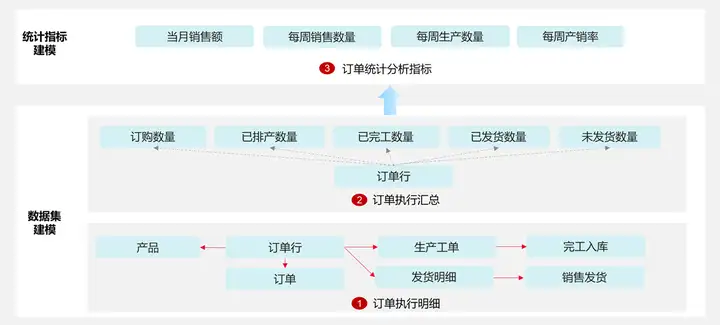
(1)“订单执行明细”数据集:以销售订单行为主线,串联后续生产工单、完工入库、销售发货等业务环节数据,透视订单的执行进度明细。通过该分析模型示例,介绍分析数据集模型的“关联分析”节点组件的用法;
(2)“订单执行汇总”数据集:基于订单行数据串联生产工单、完工入库和销售发货数据,然后以销售订单和订购产品为维度,汇总统计工单排产数量、完工入库数量、销售发货数量,并计算未发货数量。通过该分析模型示例,介绍分析数据集模型的“聚合分析”和“计算分析”节点组件的用法;
(3)“订单统计分析”指标集:基于订单和生产工单数据,实时统计当月销售额,按周统计每周销售数量、生产数量、产销率。通过该分析模型示例,介绍“实时统计”、“周期性统计”和“复合性”指标模型的配置用法。
(二)详细步骤说明
1.“订单执行明细”数据集建模
使用华为云数字工厂企业平台的“建模工作台>分析模型”系统功能,可创建与配置数据分析模型。
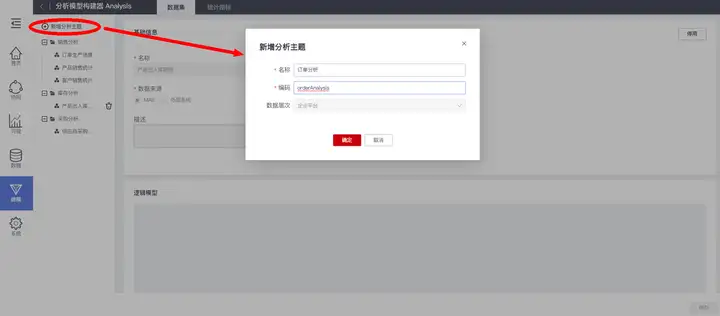
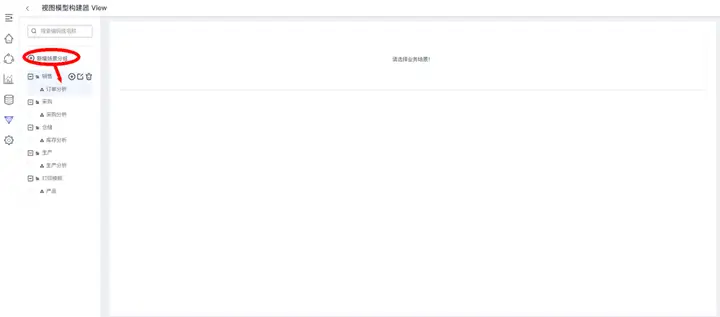
首先新建分析主题“订单分析”,方便分组管理与使用检索:
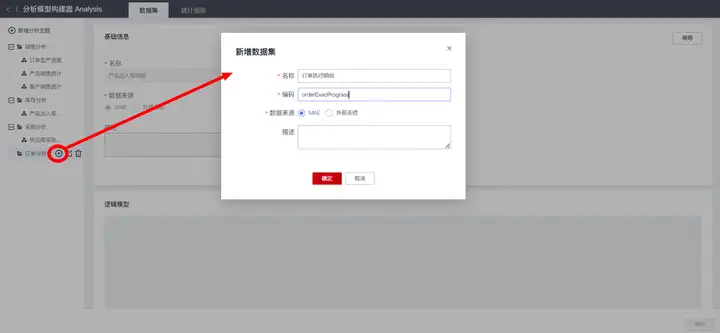
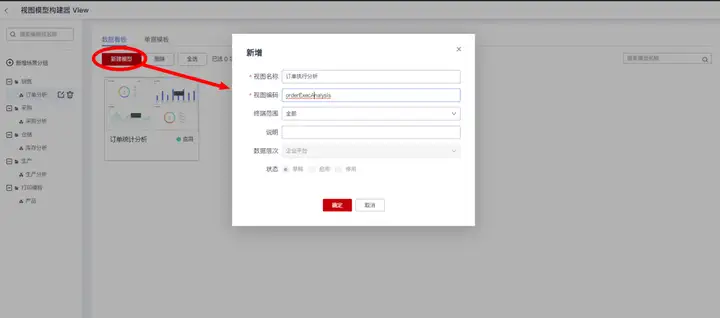
然后在“订单分析”主题下,创建数据集“订单执行明细”:
接下来需要编排数据集的取数逻辑模型:
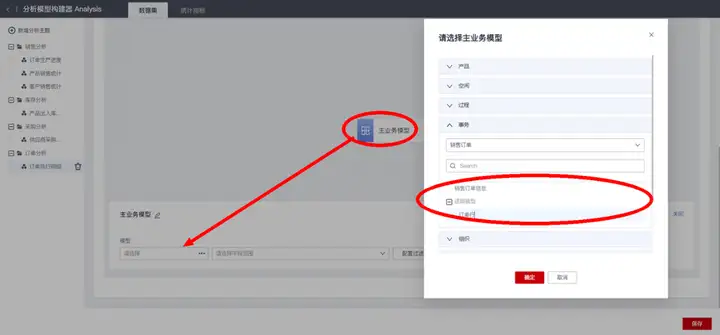
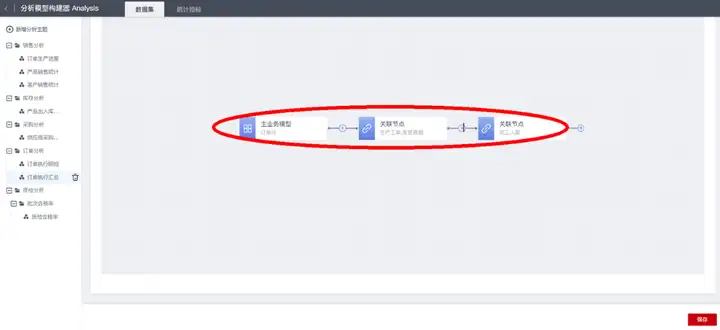
“主业务模型”是数据集的数据逻辑起点,用于指定数据集的数据主线维度,即指定以哪个模型的数据为基准来关联分析相关数据,比如我们需要以订单行数据为基准,来串联透视后续业务环节数据,则数据集的“主业务模型”选择“订单”事务模型的子模型“订单行”:
选择主业务模型后,进一步勾选配置所需的数据字段范围以及数据过滤规则。
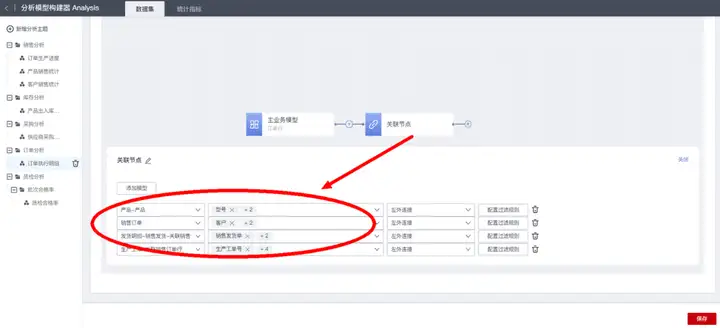
在当前主业务模型节点后面可添加“关联分析”节点,用来串联获取与当前模型存在“关联或者被关联关系”的相关模型数据。“关联分析”节点可配置多个关联模型,实现同时串联到多个相关数据。
当前示例中,主业务模型“订单行”需要:
a.关联“订单”模型获取“订单金额”、“客户”、“交货日期”等字段信息;
b.关联“产品”模型获取“规格”、“库存量”等字段信息;
c.关联“生产工单”模型获取“生产工单号”、“计划产量”、“实际产量”等字段信息;
d.关联“销售发货明细”模型获取“发货数量”等字段信息。
其中配置关联模型时,默认使用“左外连接”的关联类型,即在返回的数据集结果中关联模型数据无论是否存在不影响主业务模型数据,可按需切换为“全连接”,即在返回的数据集结果中如果主业务模型数据的关联模型数据不存在,则相应的主业务模型数据会一并丢弃。
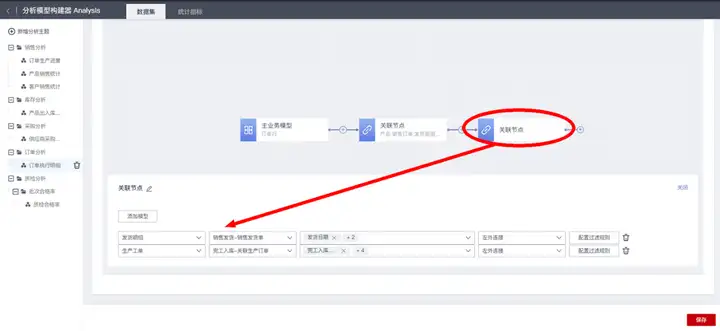
在某个关联节点之后,可再添加关联节点,实现数据多级关联与追溯。
当前示例中,主业务模型“订单行”关联“生产工单”模型数据后,需要进一步:
a.通过“生产工单”关联追溯“完工入库”模型获取“入库数量”、“入库日期”等字段信息;
b.通过“销售发货明细”关联追溯“销售发货”模型获取“发货日期”等字段信息。
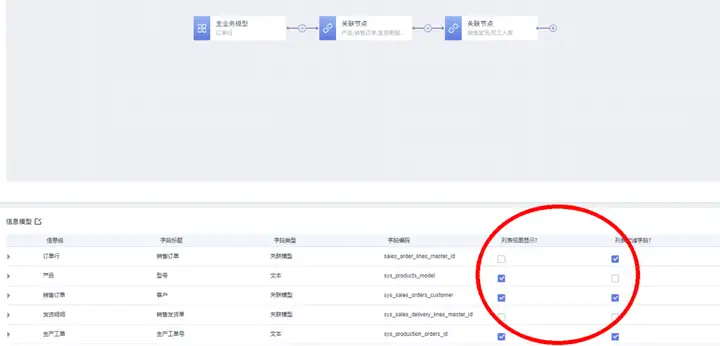
数据集配置完成后,点击右上角的“发布”按钮,自动生成相应的数据分析模型:
其中分析信息模型的“列表视图显示”和“列表过滤字段”两列支持编辑,用来设置分析模型在被报表视图组件使用时,相应字段是否作为报表显示列字段和查询字段。
2.“订单执行汇总”数据集建模
在“订单分析”主题下,创建数据集“订单执行汇总”,然后编排数据集的逻辑模型:
编排逻辑模型,准备订单执行汇总数据集所需的明细数据,即通过订单行串联生产工单、完工入库和销售发货数据:
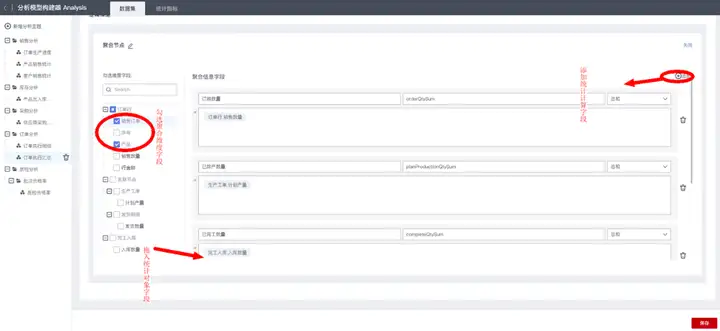
通过添加“聚合分析”节点,实现以销售订单和产品为维度,汇总统计工单排产数量、完工入库数量和销售发货数量,配置示例如下:
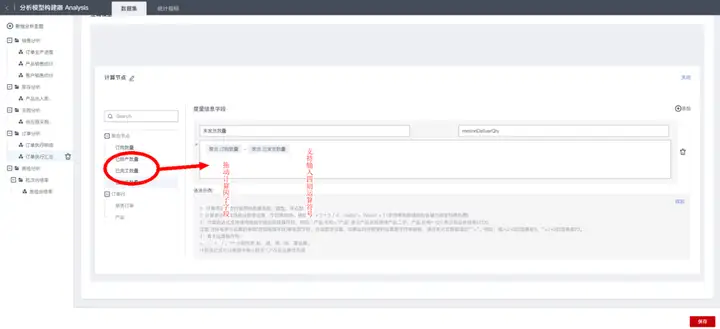
通过添加“计算分析”节点,实现计算未发货数量=订购数量-已发货数量,配置示例如下:
“订单执行汇总”数据集的逻辑模型配置结果如下:
数据集配置完成后,点击右上角的“发布”按钮,自动生成相应的数据分析模型。
3.“订单统计分析”指标集建模
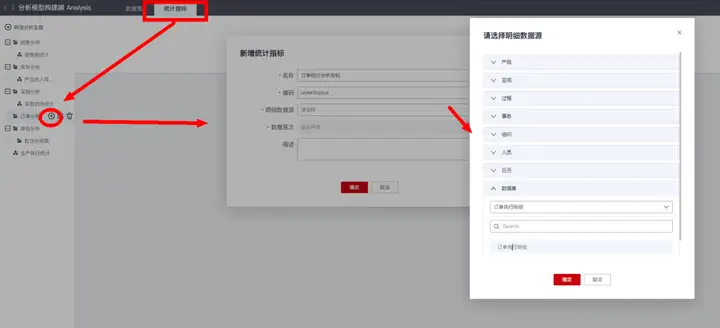
在“订单分析”主题下,切换到“统计指标”页签,然后创建指标集“订单统计分析指标”:
“统计指标集”需要指定统计的来源明细数据模型,可选择原始业务模型,也可选择已发布的分析“数据集”模型,示例这里选择前面步骤创建的分析数据集模型“订单执行明细”。
接下来,在统计指标集下新建与配置所需的指标项:
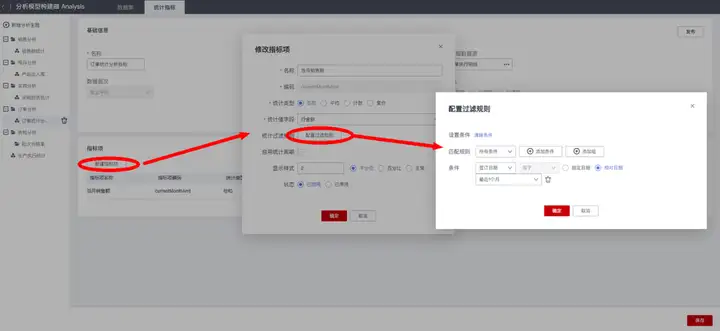
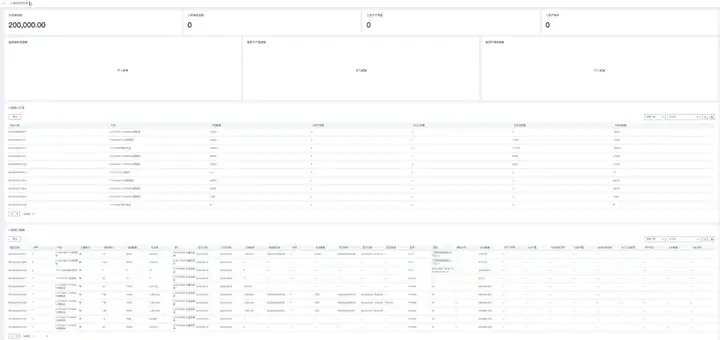
对于“当天”、“当月”等实时性统计指标,在新建指标项时需要取消勾选“启用统计周期”,然后选择“统计类型”和“统计值字段”(即统计对象字段),最后配置“统计过滤规则”的条件:条件字段选择统计依据的日期字段,条件值类型选择“相对日期”,最后选择相应的日期区间,比如当天、昨天、最近1周(当周)、最近1个月(当月)等。
当前示例“当月销售额”的配置结果如下:
- 周期性统计指标:“每周销售数量”、“每周生产数量”
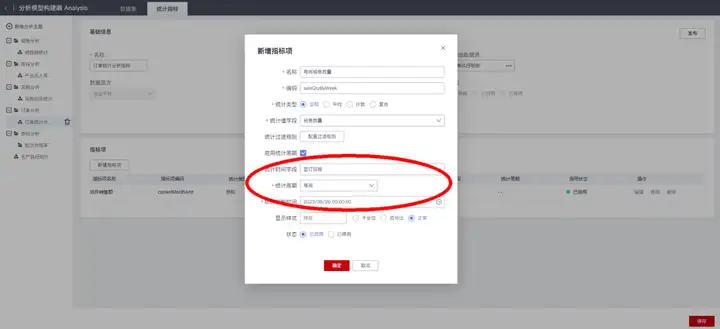
对于“每天”、“每周”、“每月”等周期性统计指标,在新建指标项时默认勾选“启用统计周期”,然后选择“统计类型”、“统计值字段”(即统计对象字段)、“统计时间字段”(即统计周期依据的日期字段)、“统计周期”(每小时/每天/每周/每月/每季度/每年)和“统计起始时间”(即统计指标第一个统计周期的起始时间,通常与“统计周期”有关,比如统计周期是“每周”,则统计起始时间通常选第一个统计周的周一的某个工作起始时间)。
当前示例“每周销售数量”的配置结果如下:
“每周生产数量”统计指标的配置方法同上,不再赘述。
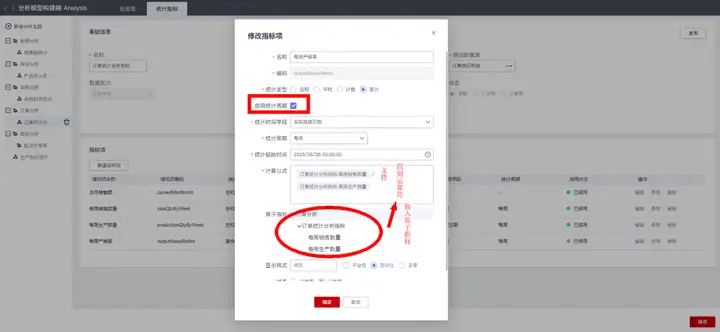
在新建指标项时,“统计类型”选择“复合”,即可创建复合性统计指标。复合指标用于引用已发布的统计指标项作为原子指标进行组合计算,计算公式支持四则运算符。
复合性统计指标也分为两类:
a.周期性的复合指标:需要勾选“启用统计周期”,然后进一步选择“统计时间字段”(即统计周期依据的日期字段)、“统计周期”(每小时/每天/每周/每月/每季度/每年)和“统计起始时间”(即统计指标第一个统计周期的起始时间,通常与“统计周期”有关,比如统计周期是“每周”,则统计起始时间通常选第一个统计周的周一的某个工作起始时间);
b.实时性的复合指标:取消勾选“启用统计周期”即可。
对于比率性的复合指标,支持配置其数据显示样式:百分比或者常规数值。当前示例“每周产销率”的配置结果如下:
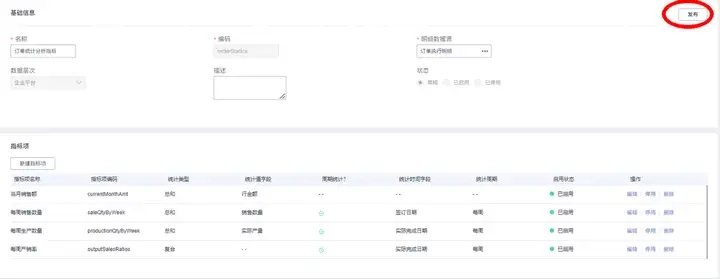
“订单统计分析”指标集的最终配置结果如下:
统计指标集配置完成后,点击右上角的“发布”按钮,自动生效相应的数据分析模型。
(三)配置数据图表视图,验证数据分析结果
1.创建视图模型
使用华为云数字工厂企业平台的“建模工作台>视图模型”系统功能,可创建与配置数据视图模型。
首先新建场景分组和业务场景“销售>订单分析”,在可视工作台会根据场景分组和业务场景来动态构建相应的数据应用卡片:
选中业务场景“销售>订单分析”,然后在“数据看板”页签下,新建视图模型“订单执行分析”:
其中“终端范围”用来设置视图模型在哪些终端展示,可选项为全部/PC端/移动端,默认选择“全部”。
2.配置数据报表:展示订单执行明细与汇总数据集
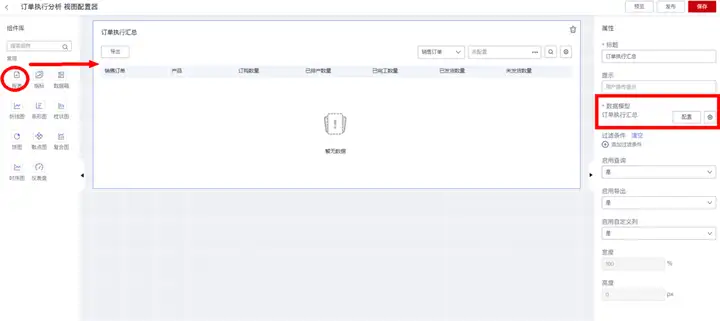
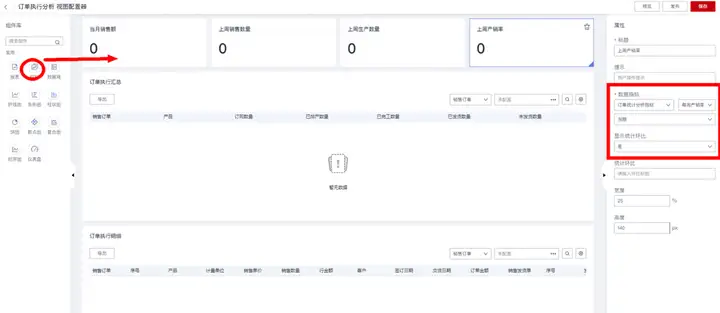
从左侧“组件库”拖动“报表”组件到中间看板画布区,然后在右侧“属性栏”配置报表组件属性,其中:
“标题”:用来设置报表卡片的前端展示标题;
“数据模型”:用来选择报表的数据来源模型,当前示例选择前面步骤创建的数据集“订单执行汇总”或者“订单执行明细”。选定数据模型后,在右侧可进一步配置在数据报表中需要展示的字段列及其顺序;
“过滤条件”:用来设置所展示数据的过滤条件。
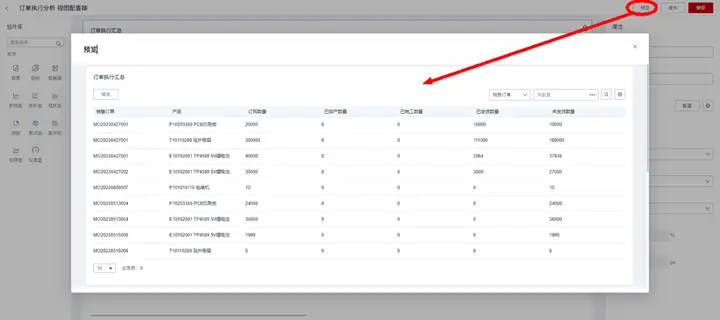
报表配置完成后,可点击右上角的“预览”按钮,查看与验证运行效果:
3.配置指标卡:展示订单统计分析指标集
从左侧“组件库”拖动“指标”组件到中间看板画布区,然后在右侧“属性栏”配置报表组件属性,其中:
“标题”:用来设置指标卡片的前端展示标题;
“数据指标”:用来选择指标卡片的数据来源指标,当前示例选择前面步骤创建的数据集“订单统计分析指标”下的相应指标项;
“显示统计环比”:针对“数据指标”选择了周期性统计指标项的情况,用来设置指标卡片上是否显示统计指标当期值与上期值的环比。
拖动指标卡片的边框可以调整其前端显示的宽度和高度,或者手工填写属性栏中的“宽度”、“高度”配置项来调整。
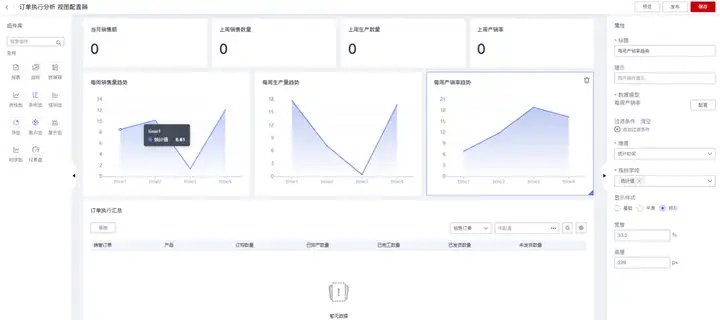
4.配置数据图表:每周产销率趋势图
从左侧“组件库”拖动“折线图”组件到中间看板画布区,然后在右侧“属性栏”配置报表组件属性,其中:
“标题”:用来设置折线图卡片的前端展示标题;
“数据模型”:用来选择折线图的数据来源模型,当前示例选择前面步骤创建的统计指标集“订单统计分析”;
“过滤条件”:用来设置所展示数据的过滤条件;
“维度”:用来选择折线图的X轴维度坐标值字段;
“指标字段”:用来选择折线图的Y轴指标坐标值字段;
“显示样式”:支持三种显示样式风格:普通折线、平滑线和梯形阴影折线。
拖动折线图卡片的边框可以调整其前端显示的宽度和高度,或者手工填写属性栏中的“宽度”、“高度”配置项来调整。
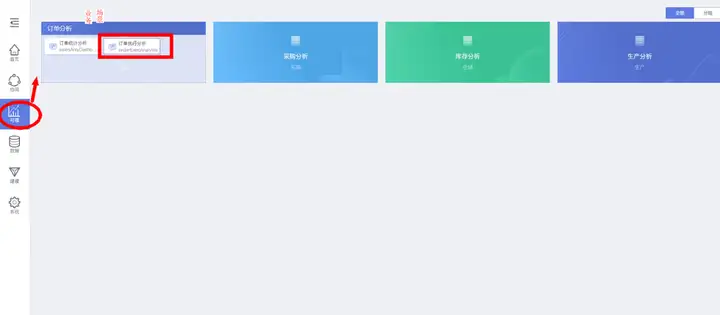
5.在可视工作台,使用数据图表看板
数据图表视图模型发布后,业务用户在 “可视工作台”的相应业务场景卡片下,可使用数据视图看板:
查看并验证前面配置的数据视图的使用效果:
数据视图模型也支持IoT设备时序数据可视化分析,提供时序趋势图和时间状态图两种组件:
华为云数字工厂平台,内置轻量级制造数据分析引擎与数据可视化工具,能够对制造过程的全域数据进行统一管理和分析,支持业务人员自助式开发数据可视化图表,满足中小型企业制造业务运营分析与洞察需求,实现基于数据持续驱动业务流程优化。
号外
7月7日,华为开发者大会2023 ( Cloud )将拉开帷幕,并将在国内30多个城市、海外10多个国家开设分会场,诚邀您参加这场不容错过的年度开发者盛会,让我们一起开启探索之旅!
我们将携手开发者、客户、合作伙伴,为您呈现华为云系列产品服务与丰富的创新实践,并与您探讨AI、大数据、数据库、PaaS、aPaaS、媒体服务、云原生、安全、物联网、区块链、开源等技术话题,展开全面深入的交流。
大会将汇聚全球科学家、行业领袖、技术专家、社区大咖,开设200多场开发者专题活动,为全球开发者提供面对面交流与合作的机会,共同探讨技术创新和业务发展。
大会官网:https://developer.huaweicloud.com/HDC.Cloud2023.html
参会购票:https://www.vmall.com/product/10086352254099.html?cid= 211761
点击参与开发者社区活动,观赏技术大咖秀、玩转技术梦工厂,有机会赢取4000元开发者礼包!
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。
点击关注,第一时间了解华为云新鲜技术~