作者:邰翀
(https://github.com/TCeason) Databend 研发工程师
![]()
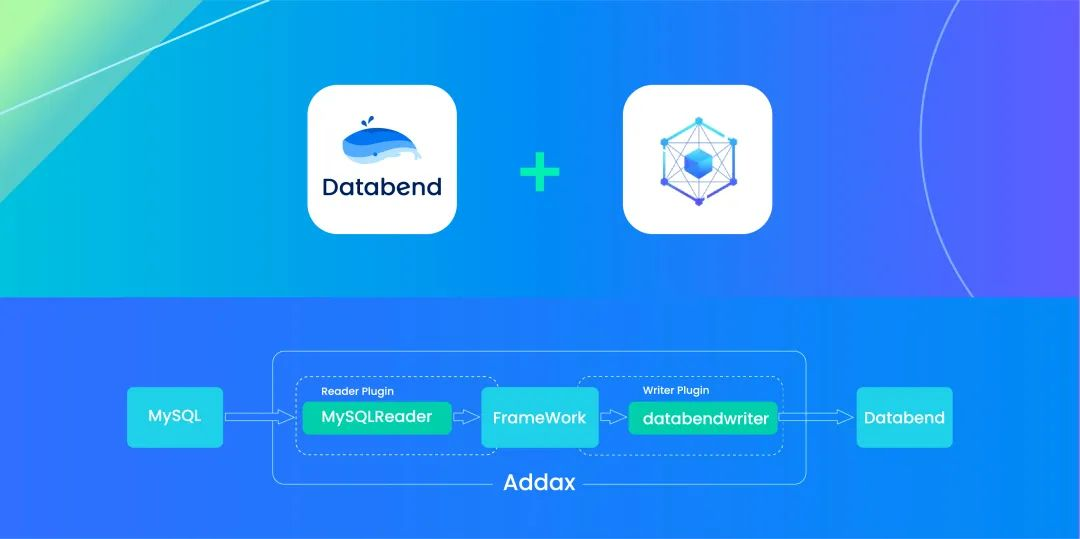
现在互联网应用越来越复杂,每个公司都会有多种多样的数据库。通常是用最好的硬件来跑 OLTP,甚至还在 OLTP 中进行分库分表来足业务,这样对于一些分析,聚合,排序操作非常麻烦。这也有了异构数据库的数据同步需求,今天重点给大家介绍两个利器 :异构数据迁移:Addax 结合云原生数仓 Databend 实现异构数据库数据合并及分析。
Addax (https://github.com/wgzhao/Addax) 是一个异构数据源离线同步工具,最初来源于阿里的 DataX ,致力于实现包括关系型数据库(MySQL、PostgreSQL、Oracle等)、HDFS、Hive、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
Databend (https://github.com/datafuselabs/databend) 是一个开源、弹性、负载感知的现代云数仓库,赋能企业降本增效。在之前的文章中介绍了 如何快速部署 Databend (https://www.databend.cn/blog/deploy-databend-on-minio)。
为什么是 Addax 没有选用 Datax, 实际这次发起这个项目的原因是一个用户原来的环境中有 Clickhouse, Datax 不支持 Clickhose 读取和写入,所以我们优先支持了 Addax 这个异构迁移工具。下面我们通过一个简单练习,让你学习使用 Addax , 另外通过几个进阶案例给你展示一下 Addax 的魅力。
本文中仅以 Addax 的 mysqlreader plugin 为例进行实验,databendwriter 支持所有 Addax 提供的 reader plugin。
1. Addax 基本使用
1.1. 安装 Addax
# more info https://wgzhao.github.io/Addax/4.0.11/
wget https://github.com/wgzhao/Addax/releases/download/4.0.11/addax-4.0.11.tar.gz;
tar xvf addax-4.0.11.tar.gz;
Addax 也支持 Docker 安装 (https://github.com/wgzhao/Addax#use-docker-image)和编译安装 (https://github.com/wgzhao/Addax#compile-and-package)。
1.2. Demo (from MySQL to Databend)
在 MySQL Server 中建立迁移用户。(本例中待迁移的表为 db.tb01)
mysql> create user 'mysqlu1'@'%' identified by '123';
mysql> grant all on *.* to 'mysqlu1'@'%';
mysql> create database db;
mysql> create table db.tb01(id int, col1 varchar(10));
mysql> insert into db.tb01 values(1, 'test1'), (2, 'test2'), (3, 'test3');
在 Databend 中建立对应的表结构。(将 MySQL 的 db.tb01 数据迁移至 Databend 的 migrate_db.tb01)
databend> create database migrate_db;
databend> create table migrate_db.tb01(id int null, col1 String null);
进行如下配置后,即可开始迁移。
$ cd addax-4.0.11/bin;
$ cat <<EOF > ./mysql2databend.json
{
"job": {
"setting": {
"speed": {
"channel": 4
}
},
"content": {
"writer": {
"name": "databendwriter",
"parameter": {
"preSql": [
"truncate table @table"
],
"postSql": [
],
"username": "u1",
"password": "123",
"database": "migrate_db",
"table": "tb01",
"jdbcUrl": "jdbc:mysql://127.0.0.1:3307/migrate_db",
"loadUrl": ["127.0.0.1:8000","127.0.0.1:8000"],
"fieldDelimiter": "\\x01",
"lineDelimiter": "\\x02",
"column": ["*"],
"format": "csv"
}
},
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "mysqlu1",
"password": "123",
"column": [
"*"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/db"
],
"driver": "com.mysql.jdbc.Driver",
"table": [
"tb01"
]
}
]
}
}
}
}
}
EOF
$ ./addax.sh -L debug ./mysql2databend.json
1.3. 校验数据
databend> select * from migrate_db.tb01;
+------+-------+
| id | col1 |
+------+-------+
| 1 | test1 |
| 2 | test2 |
| 3 | test3 |
+------+-------+
更多使用方式参见:https://wgzhao.github.io/Addax/4.0.11/writer/databendwriter/
1.4. 小结
上面的例子是通过 Addax 跑通一个表的迁移到 Databend , 通过一个简单的例子也可以感受一下 Addax 大概的流程。
但 Addax 远比这个 Demo 强大。另外 Addax 强大之处可能通过参数来控制配置文件,这样比轻松地实现一个配置迁移, 甚至可以传入 SQL 这样来读取指定区间做数据的迁移。
2. Addax 进阶使用
Addax 配置框架可以参考:https://wgzhao.github.io/Addax/4.0.11/setupJob/
如果只是使用源端和目标,这块在配置中主要需要关注:
"content": {
"reader": {},
"writer": {},
}
另外 Addax 参考了 DataX 的设计和使用习惯,对于 DataX 支持语法在 Addax 都可以使用。
下面我举几个生产中可能会用到例子,来给大家参考一下:
Case1: 生产中 10 张表的数据合并到 Databend 中一张表
Case2: 把 MySQL 中所有的表都迁移到 Databend 中
Case3: 指定 SQL 读取原表的数据,迁移到指定的表中
Case 1: 生产中 10 张表的数据合并到 Databend 中一张表
这个需求在生产中比较常见,需要把线上的数据汇聚一个地方进行分析, 这块正好可以利用 Databend 基于对象存储及高压缩的能力。假设源端是 MySQL 数据库, 目标端是 Databend, 下面是一个简化的配置:
"reader": {
"name": "mysqlreader",
...
"connection": [
...
"table": [
'${dst_table}'
]
]
},
"writer": {
"name": "databendwriter",
...
"table": '${src_table}',
...
}
基于这配置我们需要写一个脚本来调用, 例如要迁移的前缀是 sbtest 从 1 到 10 ,最终合并为 sbtest 调用方法如下:
pre_tb="sbtest"
dst_tb="sbtest"
for t in `seq 1 10`
do
tb=$pre_tb$t
echo $tb
./bin/addax.sh ./job/my2databend.json -p "-Dsrc_table=$tb -Ddst_table=$dst_tb"
done
mysql2databend.json 配置参考:databend-workshop/mysql2databend.json at main · wubx/databend-workshop (https://github.com/wubx/databend-workshop/blob/main/addax_mysql2databend/mysql2databend.json)
Case 2: 把 MySQL 中所有的表都迁移到 Databend 中
基于上面的案例,估计大概已经明白其中的套路了。如果 MySQL 到 Databend 还可以基于上面的配置文件,只需要把要迁移的表整理成一个 list 控制。全库迁移难点在于表结构生成,对于 Databend 表结构的生成只需要字段名和类型即可。
表结构生成的脚本参考:https://github.com/wubx/databend-workshop/blob/main/addax_mysql2databend/mysql_str2databend.py
调用方法:
#python3 g_mysql.py -H MySQL_IP -P MySQL_PORT -u MySQL_User -p mysql_password -d dbname |mysql -h databend_ip -Pdatabend_port -udatabend_user dbname
python3 g_mysql.py -H 172.21.16.9 -P 3306 -u root -p vgypH8nc -d wubx |mysql -h 127.0.0.1 -P3307 -uroot wubx
定制迁移配置
"reader": {
"name": "mysqlreader",
...
"connection": [
...
"table": [
'${src_table}'
]
]
},
"writer": {
"name": "databendwriter",
...
"table": '${src_table}',
...
}
调用方式
pre_tb="sbtest"
for t in `seq 1 10`
do
tb=$pre_tb$t
echo $tb
./bin/addax.sh ./job/mysql2databend.json -p "-Dsrc_table=$tb"
done
Case 3: 指定 SQL 读取原表的数据,迁移到指定的表中
这种场景适合定期小批量迁移的,但原始表里需要有时间字段,比如订单类数据迁移。这里我们要使用到 Addax 数据读取中指定 querySQL 这个特性
"content": {
"reader": {
"name": "mysqlreader",
"parameter": {
...
"connection": [
{
"querySql": ["$DS"],
...
}
]
}
},
"writer": {
"name": "databendwriter",
...
"table": '${DT}',
...
}
![]()
调用方法:
# 利用 DS 传入读取的 SQL ,通过 DT 指定写入的表名
python3 ./bin/addax.py job/msql.json -p "-DDS='select * from sbtest1 limit 10' -DDT=sbtest"
小结
本部分通过几个案例分展示了 Addax 的数据读取能力,通过灵活的组合基本可以满足生产中的各种需求。实际使用中如果为了提速,需要调整任务的配置和 autoPK 的这个功能。另外也可以使用 Addax 和 Databend 也可以担负起数据库的归档需求。
Databend 兼容 MySQL 协议 (https://databend.rs/doc/integrations/api/mysql-handler),如果使用 Databend 做 ODS 层,又想结合原来的大数据生态使用,也可以使用 Addax 直接使用 mysql (https://wgzhao.github.io/Addax/4.0.11/reader/mysqlreader/) reader (https://wgzhao.github.io/Addax/4.0.11/reader/mysqlreader/) 插件读取 Databend 中的数据。
3. 使用中注意事项
Addax 使用中对于具体的数据库,建议多阅读官方的 reader 或是 writer 的说明,根据实际情况决定合理的配置。这里的案例中 Databend 使用的是 Streaming_load 接口进行的数据写入,如果单节点 databend-query 有压力的情况下,也可以考虑配置多个 databend-query ,Addax 也是支持多个 databend-query 写入。
以上都是参考,如果还有不能满足你的使用,或是你对 Addax 和 Databend 有进一步需求,也可以 wx 小D : Databend 约一些线上的交流。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。