小编:本文由 WebInfra 团队姚忠孝、杨文明、张地编写。意在通过深入剖析常用的内存分配器的关键实现,以理解虚拟机动态内存管理的设计哲学,并为实现虚拟机高效的内存管理提供指引。
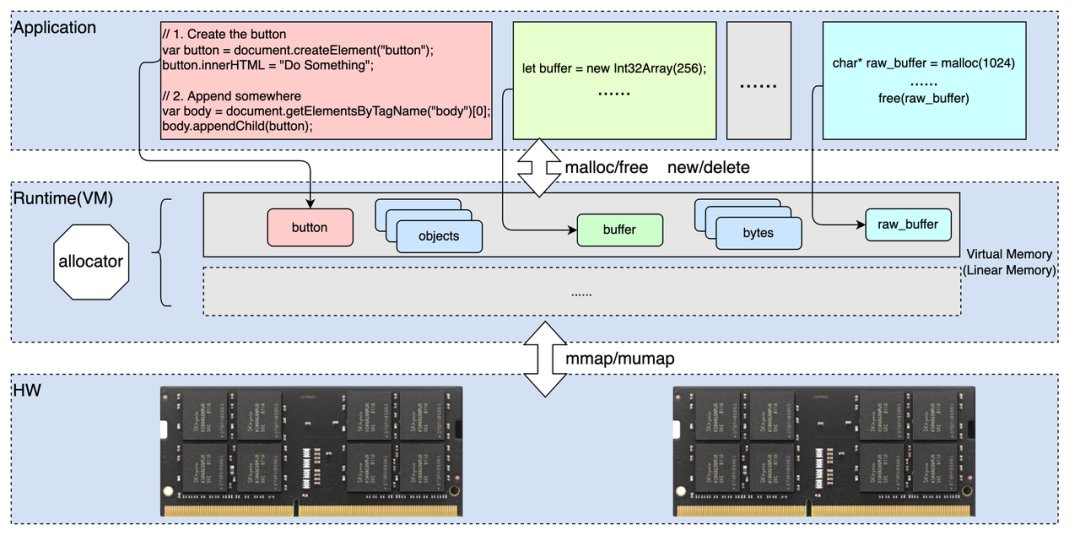
在现代计算机体系结构中,内存是系统核心资源之一。虚拟机( VM )作为运行程序的抽象"计算机",内存管理是其不可或缺的能力,其中主要包括如内存分配、垃圾回收等,而其中内存分配器又是决定"计算机"内存模型,以及高效内存分配和回收的关键组件。
如上图所示,各种编程都提供了动态分配内存对象的能力,例如创建浏览器 Dom 对象,创建 Javascript 的内存数组对象( Array Buffer 等),以及面向系统编程的 C / C++ 中的动态分配的内存等。在应用开发者角度看,通过语言或者库提供的动态内存管理(分配,释放)的接口就是实现对象内存的分配和回收,而不需要关心底层的具体实现,例如,所分配对象的实际内存大小,对象在内存中的位置排布(对象地址),可以用于分配的内存区域,对象何时被回收,如何处理多线程情况下的内存分配等等;而对于虚拟机或者 Runtime 的开发者来说,高效的内存分配和回收管理是其核心任务之一,并且内存分配器的主要目标包括如下几方面:
内存分配需要通过内核分配虚拟地址空间和物理内存,频繁的系统调用和多线程竞争显著的降低了内存分配的性能。内存分配器通过接管内存的分配和回收,无论在单线程还是多线程场景下都可以很好的起到提升性能的作用。
随着系统和应用对安全性的关注度提升,默认的内存分配机制无论在内存数据布局,还是对硬件安全机制的使用上都无法最大化的满足应用诉求,因此自定义内存分配器可以针对特定的系统和应用充分的利用硬件安全机制( MTE )等,同时也能够在实际系统中引入内存安全性检测机制来进一步提升安全性。
-
检测线性溢出, UAF 等多种内存非法访问异常
-
内存加固(地址随机化, MTE , etc .)
因此,本文通过深入分析常用的内存分配器的关键实现( dlmalloc , jemalloc , scudo , partition-alloc ),来更好的理解背后的设计考量和设计哲学,以为我们实现高效,轻量的运行时和虚拟机内存分配器,内存管理模型提供指引。
1. dlmalloc [1]
* Key Points ( salient points )
-
从操作系统分配( sbrk , mmap )一大块内存 " Segment " ( N * page_size ),多个 Segment 通过链表相互连接," Segment "可以为不同大小。
-
每次申请内存,从 Segment 中分配一块内存" chunk "的内存地址(如果当前 Segment 不满足分配需求,进入步骤 a. 从操作系统分配 Segment )," chunk "可以为不同大小。
-
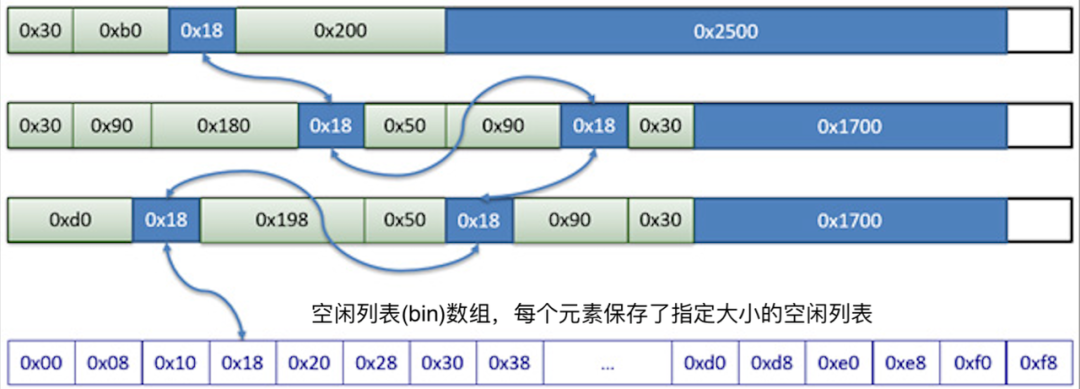
dlmalloc 中切分出的各中大小的 chunk 需要通过" bin "来统一管理," Bin "用于记录最近释放的可重复使用的块(缓存)。有两种类型的 Bin :" small bin "和“ tee bin ”。Small bins 用于小于 0x100 字节的块。每个 small bin 都包含相同大小的块。" tree bin "用于较大的块,并包含给定大小范围的块。" small bin "被实现为简单的双向链表," tree bin "被实现 chunk 大小为 key 的 tries 树。
实际的内存分配需要按照所申请的内存大小分别处理,如下所述:
小内存( Small < 0x100 bytes )
小内存通过空闲链表管理空闲内存的使用状态;下图是某一时刻可能的内存快照情况,每个内存大小( size )都可作为空闲链表数组的下标访问对应大小的空闲链表。
![]()
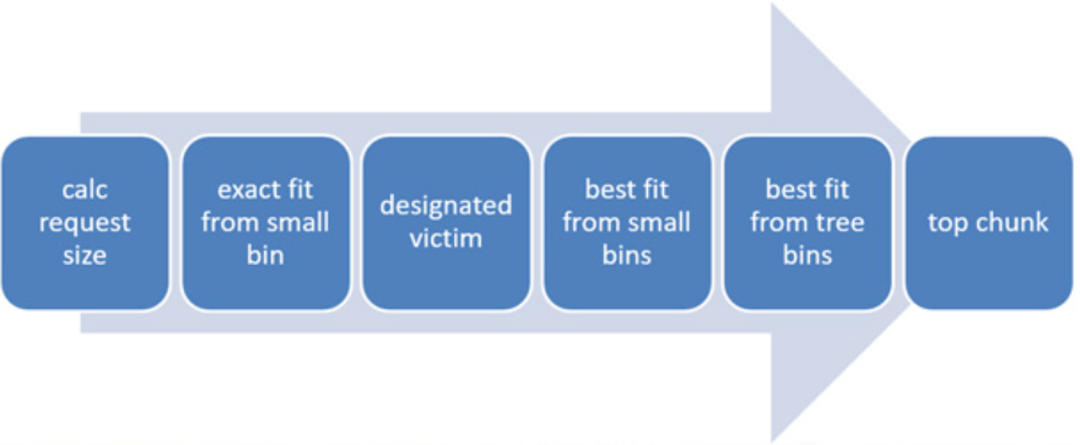
基于空闲链表维护的空闲内存状态,采用如下的分配顺序和分配策略进行实际内存分配。
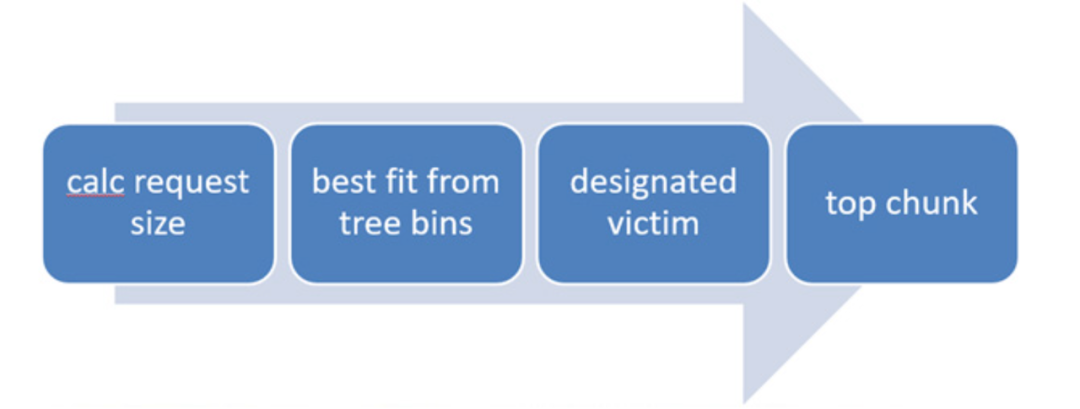
大内存不采用空闲链表数组进行管理(虚拟机地址空间方范围大,时间和空间效率均低),采用 trie-tree 作为大内存的状态维护结构,每次内存分配和释放在 trie-tree 上进行高效的搜索和插入。
大内存采用如下的分配顺序和分配策略进行实际内存分配。
![]()
对于超大内存,直接通过 mmap 从操作系统分配内存。
* Weakness
2. jemalloc ( Android 5.0.0 ~ )
该内存管理器的主要目标是提升多线程内存使用的性能( efficiency 、 locality )和较少内存碎片(最大优势是强大的多线程分配能力)
* Key Points ( salient points )
![]()
-
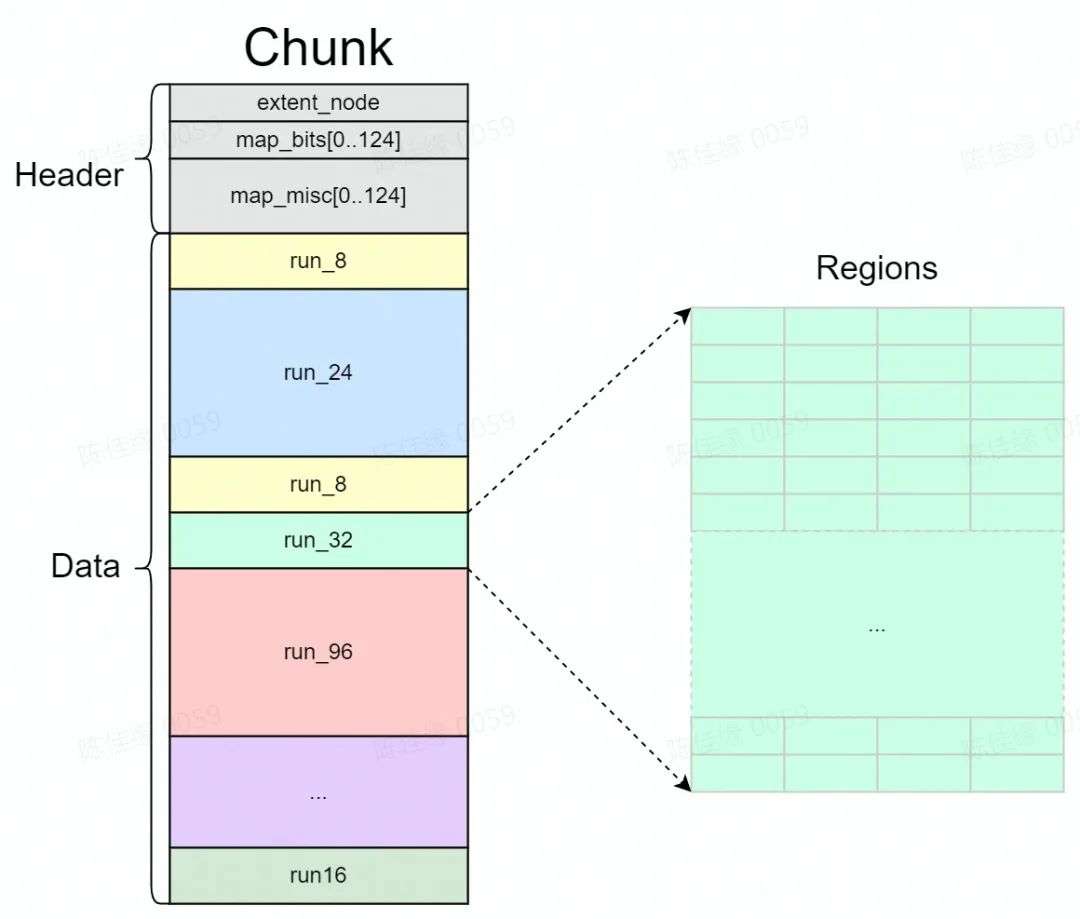
调用 mmap 从操作系统分配一整块大内存 " Chunk ", Chunk 为固定大小( 512k ),可以被分割成两部分:头信息区域和数据区域。数据区域被分割成若干个 Run 。
-
在 Chunk 的数据区中一个或者多个页会被分成一个组,用于提供特定大小的内存分配,被称为" Run "(相同大小内存所在的页组),相同大小 Region 对应的 Run 属于同一个 Bin ( bucket )进行管理(如下图所示)。
-
" Run "中的内存会被切分为固定小的内存块" Region ",作为最小的内存分配单元,作为实际内存地址返回给内存分配申请。
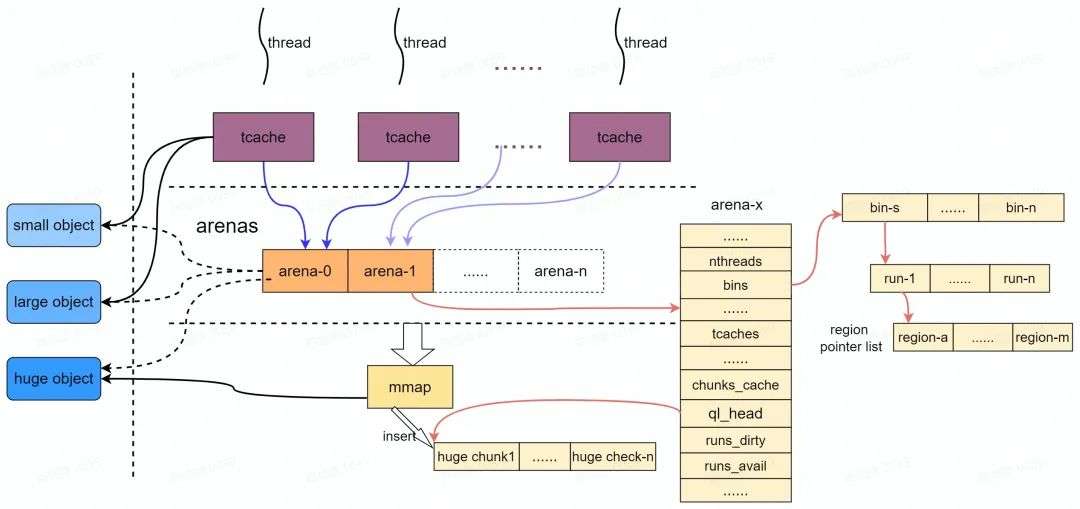
上图展示了内存分配的主要流程及数据结构。 jemalloc 通过 areans 进行内存统一内存分配和回收, 由于两个arena在地址空间上几乎不存在任何联系, 就可以在无锁的状态下完成分配。同样由于空间不连续, 落到同一个 cache-line 中的几率也很小, 保证了各自独立。理想情况下每个线程由一个 arena 负责其内存的分配和回收,由于 arena 的数量有限, 因此不能保证所有线程都能独占 arena , Android 系统中默认采用两个 arena ,因此会采用负载均衡算法( round-robin )实现线程到 arena 的均衡分配并通过内部的 lock 保持同步。
多个线程可能共享同一个 arena , jemalloc 为了进一步避免分配内存时出现多线程竞争锁,因此为每个线程创建一个 " tcache ",专门用于当前线程的内存申请。每次申请释放内存时, jemalloc 会使用对应的线程从 tcache 中进行内存分配(其实就是 Thread Local 空闲链表)。
每个线程内部的内存分配按如下3种不同大小的内存请求分别处理:
-
小对象( Small Object ) 根据 Small Object 对象大小,从 Run 中的指定 " region " 返回。
-
大对象( Large Object ) Large Object 大小比 chunk 小,比 page 大,会单独返回一个 " Run "(1或多个 page 组成)。
-
超大对象( Huge Object ) > 4 MB huge object 的内存直接采用 mmap 从 system memory 中申请(独立" Chunk "),并由一棵与 arena 独立的红黑树进行管理。
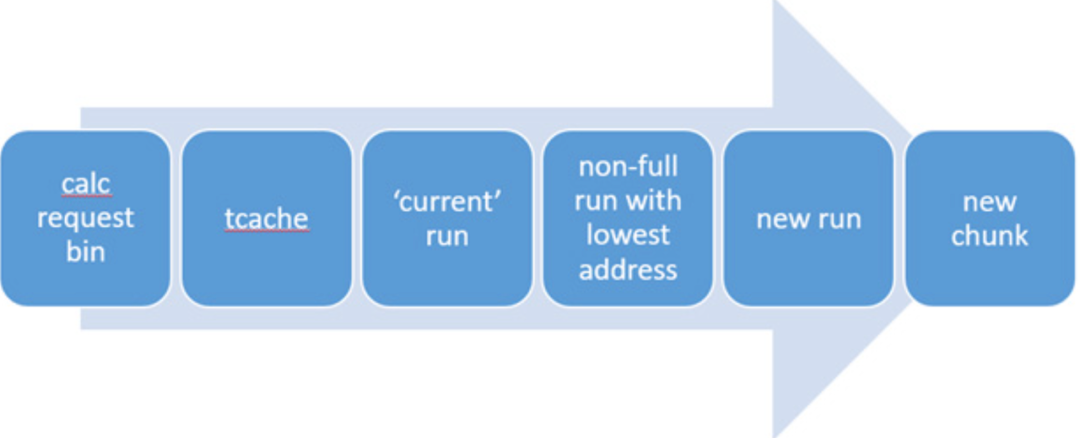
基于以上的核心数据结构,内存分配流程大致流程如下图所示:
* Summary
-
jemalloc 的核心是一个基于桶分配器( bin )。每个 arena 都有一组逻辑 bin ,每个 bin 都服务于特定的尺寸等级。分配是从具有足够大以适应分配请求的最小尺寸的 bin 进行的,它们之间的步长很小,可以减少碎片。
-
每个 arena 都有自己的锁,所以不同 arena 上的操作不会争抢锁。
-
临界区很短,仅当从 arena 中分配内存(共享 arena 线程间内部锁),或者分配 runs 的时候才需要保持锁定。
-
线程特定的内存缓存进一步减小数据竞争。
3. scudo ( Android 11 ~)
Scudo 这个名字源自 Escudo ,在西班牙语和葡萄牙语中表示“盾牌”。为了安全性考虑,从 Android 11 版本开始,Scudo 会用于所有原生代码(低内存设备除外,其仍使用 jemalloc )。在运行时,所有可执行文件及其库依赖项的所有原生堆分配和取消分配操作均由 Scudo 完成;如果在堆中检测到损坏情况或可疑行为,该进程会中止。(以下内容以 Android-11 64位系统实现为分析目标)
* Key Points ( salient points )
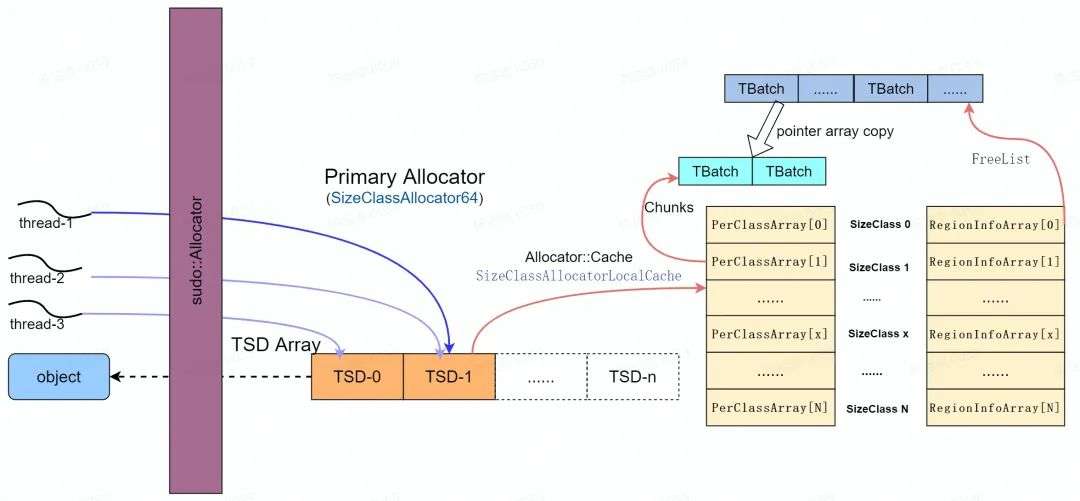
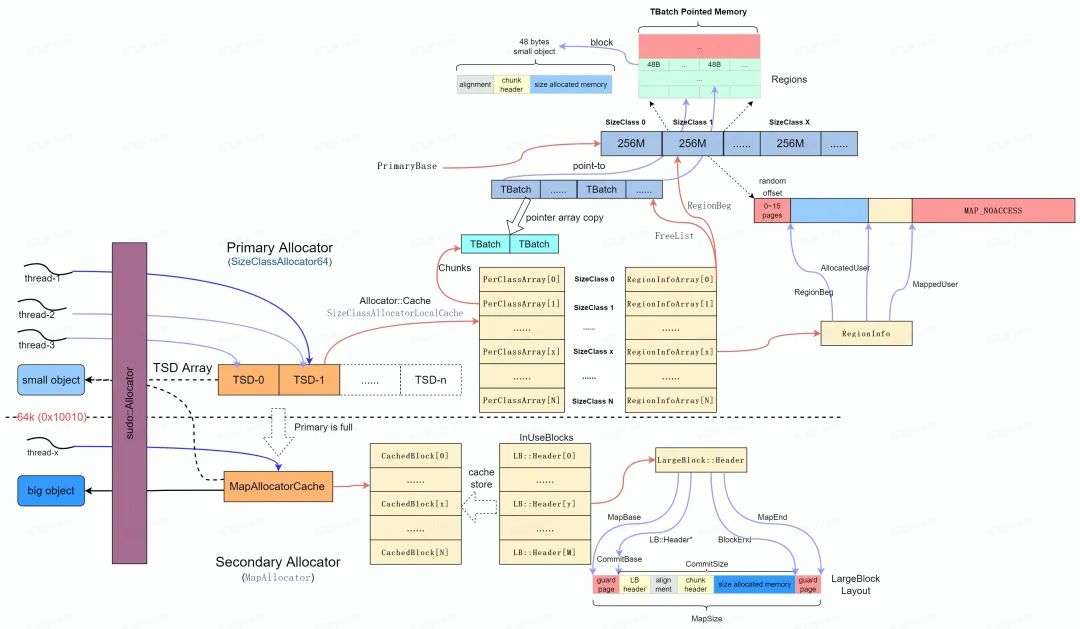
Scudo 定义了 Primary 和 Secondary 两种类型分配器[4],当需求小于 max_class_size ( 64 k )时使用 Primary Allocator ,大于 max_class_size 时使用 Secondary Allocator 。
struct AndroidConfig {
using SizeClassMap = AndroidSizeClassMap;
#if SCUDO_CAN_USE_PRIMARY64
// 256MB regions
typedef SizeClassAllocator64<SizeClassMap, 28U, 1000, 1000,
/*MaySupportMemoryTagging=*/true>
Primary;
#else
// 256KB regions
typedef SizeClassAllocator32<SizeClassMap, 18U, 1000, 1000> Primary;
#endif
// Cache blocks up to 2MB
typedef MapAllocator<MapAllocatorCache<32U, 2UL << 20, 0, 1000>> Secondary;
template <class A>
using TSDRegistryT = TSDRegistrySharedT<A, 2U>; // Shared, max 2 TSDs.
};
* Primary Allocator
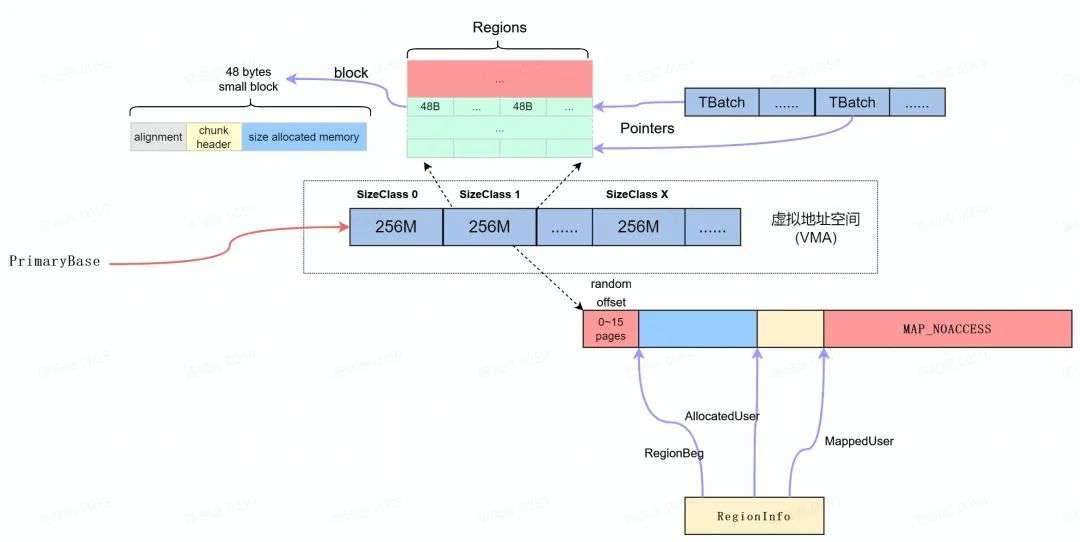
Primary Allocator [5]首先会根据 AndroidSizeClassConfig [6]中的配置申请一个完整的虚拟内存空间,并将虚拟内存空间分成不同的区域( sizeClass ),每块区域只能分配出固定空间,区域1只能分配32 bytes (包含 header ),区域2只能分配48 bytes 。
Primary Allocator 从操作系统申请" PrimaryBase "指向的虚拟内存区域后,按照如下的配置为虚拟内存区域划分为 32 个 256 M 的内存区域( SizeClass )。
每个 SizeClass 提供特定大小的内存分配,其内存区域按照 RegionInfo 结构布局,其中" randon offset "是0~16页的随机值,以使随机化 ReginBeg 地址降低定向攻击的风险。
每个 SizeClass 区域初始分配内存为 MAP_NOACCESS ,当收到内存分配请求时, ClassSize 会分配出一块可用的内存区域( MappedUser ),并以 SizeClass 指定的 block 大小切分成可用使用的 Regions 。当进行 Regions 的分配的同时,每个可用的 Region 均通过 TranferBatch 进行管理( TBatch ), 这样 TBatch 的链表就可以作为 FreeList 供内存分配使用。
为了安全性的考虑,最终返回的内存按照上图" block "所示的内存布局组织。其中" chunk-header "[7]是为了保证每一个 chunk 区域的完整性, Checksum 用的是较为简单的CRC算法,此外,内存释放过程中 Scudo 增加了 header 检测机制,一方面可以检测内存踩踏和多次释放,另一方面也阻止了野指针的访问。
struct UnpackedHeader {
uptr ClassId : 8;
u8 State : 2;
u8 Origin : 2;
uptr SizeOrUnusedBytes : 20;
uptr Offset : 16;
uptr Checksum : 16;
};
struct AndroidSizeClassConfig {
static const uptr NumBits = 7;
static const uptr MinSizeLog = 4;
static const uptr MidSizeLog = 6;
static const uptr MaxSizeLog = 16;
static const u32 MaxNumCachedHint = 14;
static const uptr MaxBytesCachedLog = 13;
static constexpr u32 Classes[] = {
0x00020, 0x00030, 0x00040, 0x00050, 0x00060, 0x00070, 0x00090, 0x000b0,
0x000c0, 0x000e0, 0x00120, 0x00160, 0x001c0, 0x00250, 0x00320, 0x00450,
0x00670, 0x00830, 0x00a10, 0x00c30, 0x01010, 0x01210, 0x01bd0, 0x02210,
0x02d90, 0x03790, 0x04010, 0x04810, 0x05a10, 0x07310, 0x08210, 0x10010,
};
static const uptr SizeDelta = 16;
};
Scudo Primary Allocator 使用了 Thread Local Cache 机制来加速多线程下内存的分配,如下图所示。当一个线程需要分配内存时,它会通过各自对应的 TSD ( Thead Specific Data )来发起对象的申请,每个 TSD 对象通过各自的 Allocator::Cache 及其 TransferBatch 来寻找合适的空闲内存。但 TransferBatch 的大小是有限的,如果没有可用的内存会进一步利用 Primary Allocator 进行分配。
理想情况下每个线程由一个 TSD 负责其内存的分配和回收,由于 TSD 的数量有限, 因此不能保证所有线程都能独占 TSD , Android 系统中默认采用两个 TSD ,因此会采用负载均衡算法( round-robin )实现线程到 arean 的均衡分配并通过内部的 lock 保持同步。
![]()
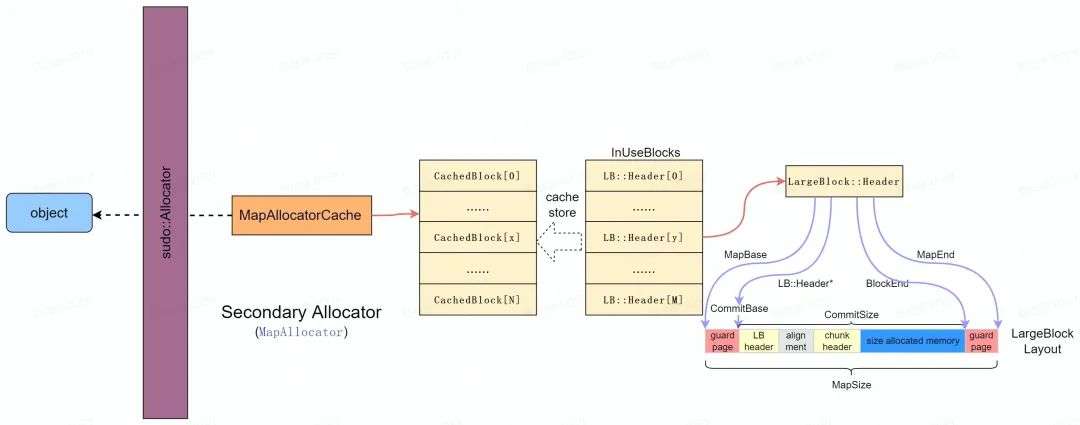
* Secondary Allocator
Secondary Allocator [8]主要用于大内存的分配(> max_size_class ),直接采用 mmap 分配出一块满足要求的内存并按照 LargeBlock::Header 进行组织, 并统一在 InUseBlocks 链表中统一管理,如下图所示。
为了安全性考虑, LargeBlock 采用如下图 LargeBlock Layout 进行组织,其中:
-
在 LargeBlock 的前后都增加了保护页以检测 heap-overflow 错误;
-
LargeBlock Header 域主要记录了 LargeBlock 的内存布局信息以便于数据存取和管理;
-
剩余内存结构和 small block 布局一致,安全性考量和设计也一致(统一性)。
此外,为了提高效率效率, LargeBlock 在释放的时候会通过 MapAllocatorCache 将可被复用的空闲内存进行缓存,在大内存分配中优先从 Cache 中进行分配。其中 CachedBlock 和 LargeBlock::Header 基本一致,都是对 LargeBlock 内存布局信息的记录和管理。
![]()
* Scudo内存分配和回收
Scudo Android R 内存分配核心流程如下所示。
NOINLINE void *allocate(uptr Size, Chunk::Origin Origin,
uptr Alignment = MinAlignment,
bool ZeroContents = false) {
initThreadMaybe(); // 初始化TSD Array 和 Primary SizeClass地址空间
// skip trivials.......
// If the requested size happens to be 0 (more common than you might think),
// allocate MinAlignment bytes on top of the header. Then add the extra
// bytes required to fulfill the alignment requirements: we allocate enough
// to be sure that there will be an address in the block that will satisfy
// the alignment.
const uptr NeededSize =
roundUpTo(Size, MinAlignment) +
((Alignment > MinAlignment) ? Alignment : Chunk::getHeaderSize());
// skip trivials.......
void *Block = nullptr;
uptr ClassId = 0;
uptr SecondaryBlockEnd;
if (LIKELY(PrimaryT::canAllocate(NeededSize))) {
// 从 Primary Allocator分配small object
ClassId = SizeClassMap::getClassIdBySize(NeededSize);
DCHECK_NE(ClassId, 0U);
bool UnlockRequired;
auto *TSD = TSDRegistry.getTSDAndLock(&UnlockRequired);
Block = TSD->Cache.allocate(ClassId);
// If the allocation failed, the most likely reason with a 32-bit primary
// is the region being full. In that event, retry in each successively
// larger class until it fits. If it fails to fit in the largest class,
// fallback to the Secondary.
if (UNLIKELY(!Block)) {
while (ClassId < SizeClassMap::LargestClassId) {
Block = TSD->Cache.allocate(++ClassId);
if (LIKELY(Block)) {
break;
}
}
if (UNLIKELY(!Block)) {
ClassId = 0;
}
}
if (UnlockRequired)
TSD->unlock();
}
// 如果分配的是大内存,或者Primary 无法分配小内存,
// 则直接在Secondary Allocator进行分配
if (UNLIKELY(ClassId == 0))
Block = Secondary.allocate(NeededSize, Alignment, &SecondaryBlockEnd,
ZeroContents);
// skip trivials.......
const uptr BlockUptr = reinterpret_cast<uptr>(Block);
const uptr UnalignedUserPtr = BlockUptr + Chunk::getHeaderSize();
const uptr UserPtr = roundUpTo(UnalignedUserPtr, Alignment);
void *Ptr = reinterpret_cast<void *>(UserPtr);
void *TaggedPtr = Ptr;
// skip trivials.......
// 根据返回内存地址,设置chunk-header对象数据
Chunk::UnpackedHeader Header = {};
if (UNLIKELY(UnalignedUserPtr != UserPtr)) {
const uptr Offset = UserPtr - UnalignedUserPtr;
DCHECK_GE(Offset, 2 * sizeof(u32));
// The BlockMarker has no security purpose, but is specifically meant for
// the chunk iteration function that can be used in debugging situations.
// It is the only situation where we have to locate the start of a chunk
// based on its block address.
reinterpret_cast<u32 *>(Block)[0] = BlockMarker;
reinterpret_cast<u32 *>(Block)[1] = static_cast<u32>(Offset);
Header.Offset = (Offset >> MinAlignmentLog) & Chunk::OffsetMask;
}
Header.ClassId = ClassId & Chunk::ClassIdMask;
Header.State = Chunk::State::Allocated;
Header.Origin = Origin & Chunk::OriginMask;
Header.SizeOrUnusedBytes =
(ClassId ? Size : SecondaryBlockEnd - (UserPtr + Size)) &
Chunk::SizeOrUnusedBytesMask;
// 设置chunk-header,CheckSum用于完整性校验
Chunk::storeHeader(Cookie, Ptr, &Header);
// skip trivials.......
return TaggedPtr;
}
-
当有线程通过 malloc 请求内存分配时,会通过符号重定向调用 scudo::allocator 的 allocate 函数。
-
进入 allocate 函数后,首先调用初始化函数,以完成 TSD 和 Primary 虚拟地址空间初始化。
-
根据 malloc 内存 size 判定是否可以通过 Primary Allocator 进行分配。
-
如果 Primary Allocator 分配的内存符合要求,计算 malloc size 对应的 SizeClass ,当前线程采用 TSD 的 Allocator::Cache 分配内存, Allocator::Cache 为每个 SizeClass 维护了一个 TransferBatch 链表,其中 TransferBatch 中是指向实际 Block 区域的指针。
-
如果 Allocator::Cache 无法分配内存,那么请求 Allocator 从对应 SizeClass 的 FreeList 中获取内存并 refill 到 Allocator::Cache 中。
-
如果 FreeList 中没有可用的内存, Allocator 需要从对应 SizeClass 的 class region 扩充空闲区域(调整MappedUser),并将内存区域切分为固定的 Block 大小,将可用的 Block 内存组织成 TransferBatch 添加到 FreeList ,并进一步 refill 到 Allocator::Cache 中供分配使用。
-
当我们分配小内存时,首先会检查最合适区域中是否有空闲位置,如果没有,则会去高一级区域中分配。例如在32 Bytes SizeClass Region 无法内存出内存,那么会逐步尝试从48 Bytes ,64 Bytes SizeClass Region 中进行分配(小内存区域耗尽)。
![]()
以上介绍了内存分配的大致流程,内存释放可以按照上述流程做反向数据流推演,不再详细展开(对Quarantine的延迟释放机制可以自行分析)。
* Summary
Scudo 虽然它的分配策略更加简化,安全性上得到了很大的改进,但为了安全性引入 chunk header 等元数据管理,内存随机化和对齐引入内存碎片一定程度上降低了内存的使用效率;此外,基于 chunk header 的内存校验以及内存安全性保障也一定程度上降低了效率(性能)。
-
内存
-
Primary Allocator 会在独立划分的一块虚拟地址空间( RegionSize* ClassNums ~ 2G )中采用随机化策略分配,为了安全性的同时引入了内存碎片。
-
Primary 分配的内存中, chunk header 记录用于内存检查的信息,有效数据比例较低(特别是小内存对象,32 bytes 有效数据为 50% )。
-
Secondary 分配的内存区前后都有保护页,内存空间使用率较低。
-
性能
以上的分析主要参照了 Android R 中的实现,最初来源于 LLVM 中 scudo 的实现, LLVM 中有 scudo_allocator [9] 和 standalone [10] 2份实现,具体内容可以从[9][10]作为入口进行源码的分析。
4. PartitionAlloc
PartitionAlloc 是 Chromium 的跨平台分配器,优化客户端而不是服务器工作负载的内存使用,并专注于有意义的最终用户活动,而不是在实际使用中并不重要的微基准[16]。
* Key Points ( salient points )
* Central Partition Allocator [16]
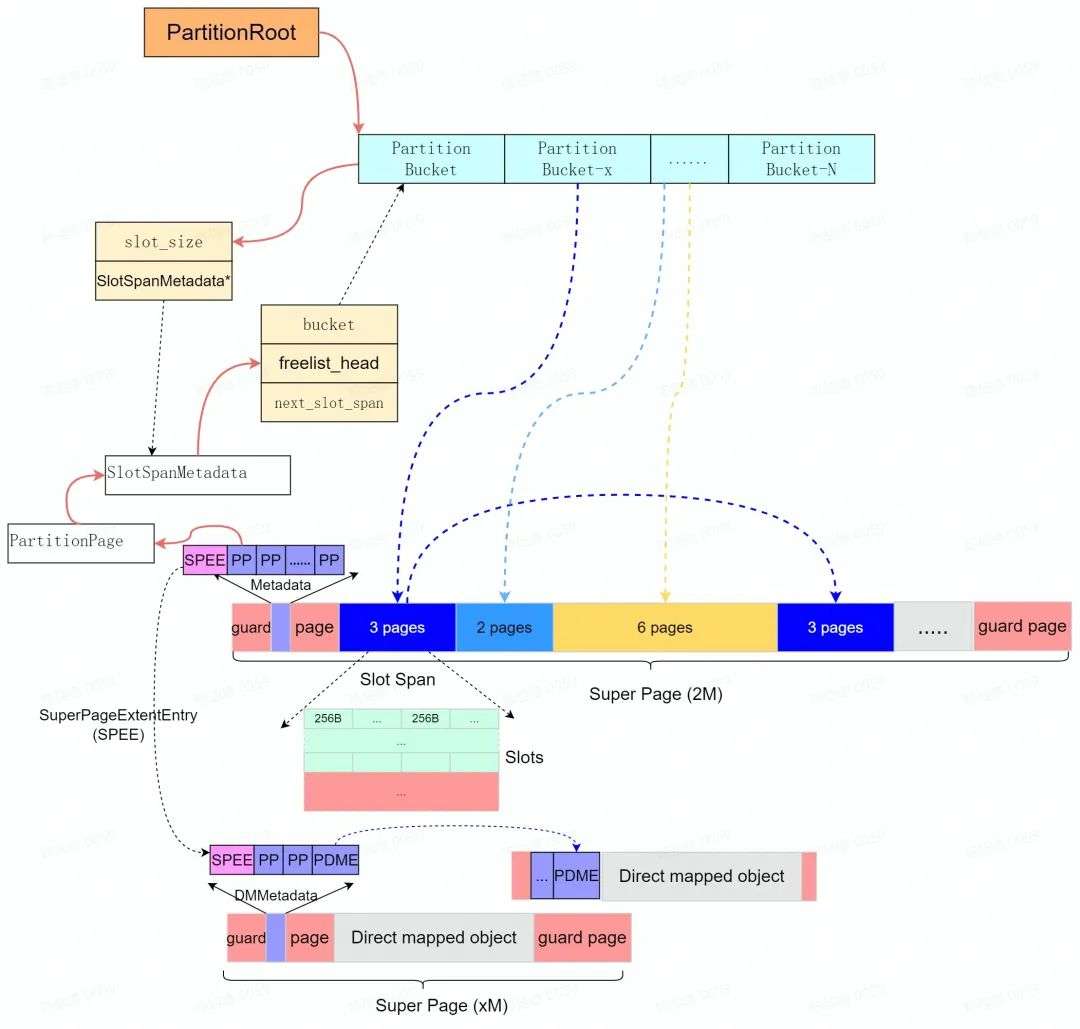
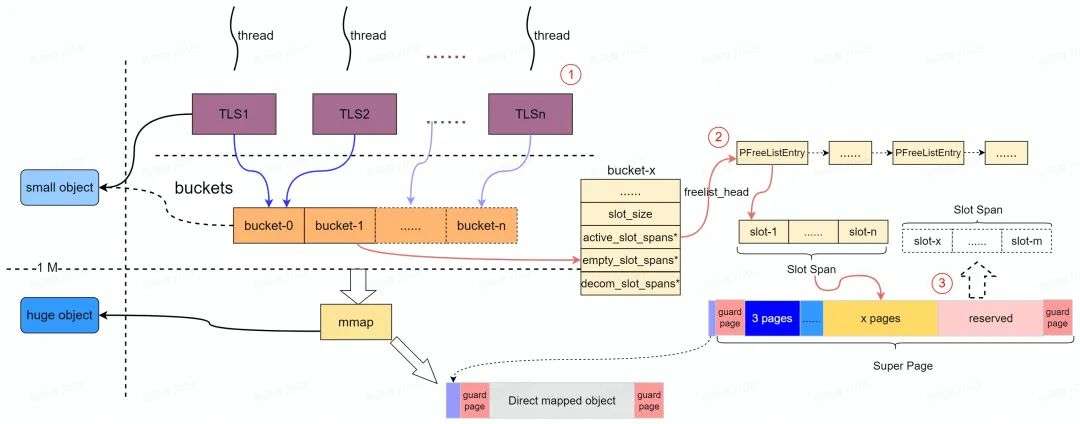
PartitionAlloc 通过分区( Partition )来隔离各内存区域。其中每个分区都使用基于 slab 的分配器来分配内存, PartitionAlloc 预先保留" Super Page "作为分区虚拟地址空间( Slab )。每个"Super Page"( Slab )按照实际可分配的最小内存单元大小( Slot )分成各自独立的" Slot Span ",每个 Slot Span 包含多个 Partition Page 并归属于特定的桶( Partiton Bucket )用于提供中小内存的分配。
PartitionAlloc 针对大内存分配(> kMaxBucketed )是通过直接内存映射( direct map )实现的(特殊的 bucket 管理),为了保证和小内存分配结构上的统一性,直接内存映射内存结构采用(伪装)和小内存分配类似的 Super Page 进行管理,并且保留了类似的内存布局布局(如下图所示)。
如上图所示, PartitionAlloc 中每个分区的内存通过一个 PartitionRoot 进行管理," PartitionRoot "中维护了一个 Bucket 数组;每个 Bucket 维护了" slot span "的集合;随着分配请求的到来, slot span 逐渐得到物理内存( Commit ),并按照所关联桶的可分配内存的大小,将物理内存切分为 slot 的连续内存区域。PartitionAlloc 除了支持多个独立的分区来提升安全性外;每个" Super Page "被分割成多个" Partition Page ",其中第一个和最后一个" Partition-Page "主要作为保护页使用( PROT_NONE )。( Super Page 选择 2 MB 是因为 PTE 在 ARM 、 ia 32 和 x 64上对应的虚拟地址是2 M )。
* Partition Layer
PartitionAlloc 虽然通过分区来隔离各区域,但在同一分区内多线程访问受单个分区锁的保护。为了缓解多线程的数据竞争和扩展性问题,采用如下三层架构来提高性能:
为了缓解多线程内存分配的数据竞争问题,每个线程的数据缓存区( TLS )保存了少量用于常用中小内存分配的 Slots 。因为这些 Slots 是按线程存储的,所以可以在没有锁的情况下分配它们,并且只需要更快的线程本地存储查找,从而提高进程中的缓存局部性。每个线程的缓存已经过定制以满足大多数请求,通过批量分配和释放第二层的内存,分期锁获取,并在不捕获过多内存的情况下进一步改善局部性。
Slot span free-lists 在每线程缓存未命中时调用。对于每个对应的 bucket size,PartitionAlloc 维护与该大小相关联的 Slot Span ,并从 Slot Span 的空闲列表中获取一个空闲 Slot 。这仍然是一条快速路径( fast path ),但比每线程缓存慢,因为它需要锁定。但是,此部分仅适用于每个线程缓存不支持的较大分配,或者作为填充每个线程缓存的批处理。
最后,如果桶中没有空闲的 slot ,那么 Slot span management 要么从 Super Page ( slab )中挖出空间用于新的slot span,要么从操作系统分配一个全新的Super Page ( slab )。这是一条慢速路径( slow path ),很慢但非常不经常操作。
以上简单介绍了 PartitionAlloc 中分区的关键结构, PartitionAlloc 在 Chromium 中主要维护了四个分区,针对每种分配器的用途采取不同的优化方案,并根据实际对象的类型在四个分区中任意一个上分配对象。
-
Buffer 分区:主要分配变长对象或者是内容可能会被用户脚本篡改的对象,如 Vector 、 HashTable 、 ArrayBufferContent 、 String 等容器类对象;
-
Node分区(之前版本叫 model object 分区):主要分配 dom 节点对象,通过重写 Noded 的 new / delete 运算符实现;
-
LayoutObject 分区:主要分配 layou 相关对象,如 LayoutObject 、 PaintLayer 、双向字体 BidiCharacterRun 等对象;
-
FastMalloc 分区:主要分配除其他三种类型之外的对象(通用对象分配器),大量功能逻辑的内部对象都归于此分区;
PartitionAlloc 在 Node 分区和 LayoutObject 分区上分配时不会获取锁,因为它保证 Node 和 LayoutObject 仅由主线程分配。PartitionAlloc 在 Buffer 分区和 FastMalloc 分区上分配时获取锁。PartitionAlloc 使用自旋锁以提高性能。
* 安全性
安全因素的考虑也是PartitionAlloc最重要的目标之一,这里利用虚拟地址空间来达到安全加固的目的:不同的分区存在于隔离的地址空间;当某个分区内存页上所有对象都被释放掉之后,其物理内存归还于系统后,但其地址空间仍被此分区保留,这样就保证了此地址空间只能被此分区重用,从而避免了信息泄露;PartitionAlloc的内存布局,提供了以下安全属性:
-
线性溢出不会破坏分区 - guard page。
-
元数据记录在专用区域(不是每个对象旁边)。线性上溢或下溢不会破坏元数据。
-
大内存分配在开始和结束时被保护分页 - guard page。
-
桶有助于在不同地址上分配不同大小的对象。一页只能包含类似大小的对象。
* Summary
传统内存分配器( jemalloc , etc.)调用 malloc 为对象分配内存时,无法指定分配器将在哪里存储什么样的数据,并且无法指定要存储它的位置。C++ 类对象可能紧挨着包含密钥的字符串,该密钥可能与函数指针的结构相邻。在所有这些数据之间是分配器用来管理堆的元数据(通常为双向链表和标志存储的指针),这为漏洞寻找要覆盖的数据目标时为他提供了更多选择。例如,当利用释放后使用漏洞时,我们希望将类型 B 的对象放置在先前分配类型 A 的对象的位置。然后我们可以触发类型 A 的过时指针的取消引用,该指针反过来使用类型 B 对象中的位。这通常是可能的,因为两个对象都分配在同一个堆中[43],而 PartitionAlloc 具有如下特性可以满足分配需求。
-
调用者可以根据需要创建任意数量的分区。分区的直接内存成本是最小的,但碎片导致的隐含成本不可低估。
-
PartitionAlloc 保证不同的分区存在于进程地址空间的不同区域。当调用者释放了一个分区中一个页面中包含的所有对象时, PartitionAlloc 将物理内存返回给操作系统,但继续保留地址空间区域。PartitionAlloc 只会为同一个分区重用一个地址空间区域。但在一定程度上,它会浪费虚拟空间( virtual address space )。
由于 PartitionAlloc 是面向 Chromium 特定应用场景的高效内存分配器,为特定内存使用场景的定制化能力能够提供高效的内存分配和回收(例如, layout 分区, node 分区),但面向通用的内存分配场景及高安全场景如果能够和 jemalloc, secudo 能力进行有效的融合( porting ),可能会是一个可行的路径和方向( MTE 等)。
5. Overview
从如上的分析可以看出,分配器的整体性能和空间效率取决于各种因素之间的权衡,例如缓存多少、内存分配/回收策略等,实际的时间和空间效率需要根据具体场景衡量并针对性的优化。如下从性能,空间效率,以及 benchmark 方面提供一些总结和参考。
|
|
|
|
|
https://github.com/ARMmbed/dlmalloc· 非线程安全,多线程分配效率低· 内存使用率较低(内存碎片多)· 分配效率低· 安全性低
|
|
|
https://github.com/jemalloc/jemalloc/blob/dev/INSTALL.md· 代码体积较大,元数据占据内存大· 内存分配效率高(基于run(桶) + region)· 内存使用率高· 安全性中
|
|
|
https://android.googlesource.com/platform/external/scudo/· 更注重安全性,内存使用效率和性能上存在一定的损失· 内存分配效率偏高(sizeclass + region, 安全性+checksum校验)· 内存使用率低(元数据,安全区,地址随机化内存占用多)· 安全性高( 安全性+checksum校验,地址随机化,保护区)
|
|
|
https://source.chromium.org/chromium/chromium/src/+/main:base/allocator/partition_allocator/PartitionAlloc.md· 代码体积小· 内存使用率偏高(相比于jemalloc多保护区,基于range的分配)· 安全性偏高(相比sudo少安全性,完整性校验,地址随机化)· 内存分配效率高(基于bucket + slot,分区特定优化)· 支持"全"平台 PartitionAlloc Everywhere (BlinkOn 14) :https://www.youtube.com/watch?v=QfY-WMFjjKA
|
NOTE:Benchmark alternate malloc implementations:
|
|
|
Max RSS (lower is better)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
6. Rererence
[1] A Tale of Two Mallocs: On Android libc Allocators – Part 1–dlmalloc
[6] AndroidSizeClassConfig:
[18] partition_alloc_constants:
[19] Unified allocator shim: