如今,数据的时效性会真正影响到一个企业的生存。
一直以来,以传统 BI 报表、数据大屏、标签画像等为代表的分析型业务(OLAP),都是企业数据资源的重点应用场景。但 AP 型业务并不是企业的全部,同时还存在对数据实时性要求更高的新一代的运营型分析(Operational Analytics)以及越来越多的交互型业务场景(OLTP 或 Operational Applications),更是企业的核心命脉。
本期分享将从企业当前的实时场景需求出发,围绕以下几个要点,具体解析实时数据的内涵与新时期的方案选择:
一、企业为什么越来越需要实时数据?
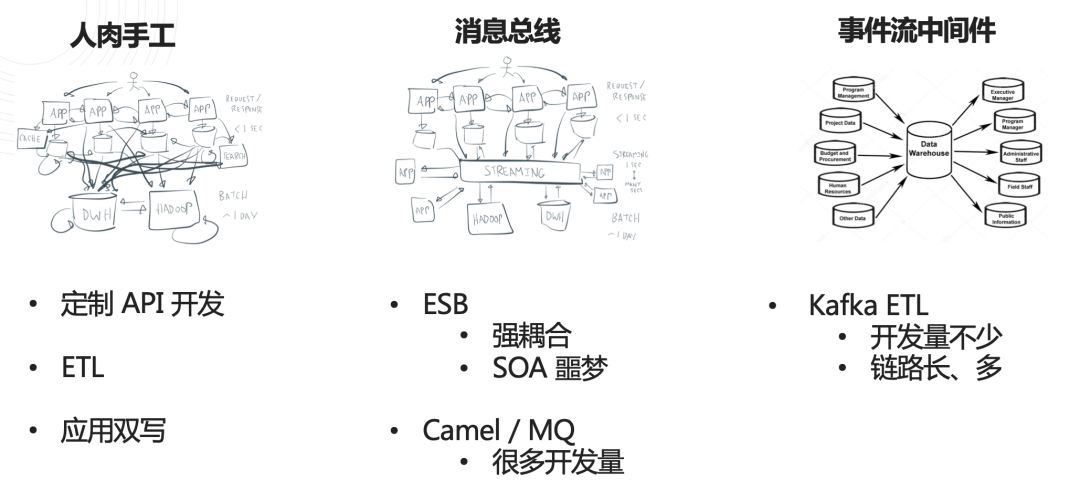
从依赖“人肉手工”写代码,到消息总线开始出现,再升级到后来的事件流中间件……数据集成架构在演进的过程中,解决了一些旧的问题,又逐渐遇上一些新的问题。对数据实时性要求的提高,就是眼下很多企业遇到的一个新的挑战。
企业数据现状与实时数据场景
以制造业和零售行业真实环境下的典型场景为例:
① 高端制造业:影响工厂产能
不同于常规生产流水线,半导体制造的无人实验室生产模式,高度依赖机械臂作业对复杂性与精密性任务的完成度,而这整个生产调度过程,又要通过 MES 系统来完成。因此,MES 系统数据推送或信号下发的时间间隔,直接关系到机械臂空转时间,继而影响整个实验室的产能。这个间隔一般是10分钟。
反过来说,如果能成功缩短数据推送间隔,就相当于提升了机械臂的利用率;如果间隔能达到秒级实时,生产速度则有望百倍增长,这其中蕴含的商业价值与竞争优势不言而喻。对于企业而言,最直接获益就是产能升级,充分挖掘实时数据优势也一跃成为加速发展的迫切需求。
② 高端零售:阻碍销售开单
不同于常规快消品,珠宝由于自身客单价较高、交易频率较低、更多依赖线下门店的独特属性,在零售行业的细分领域中更偏向传统、高端一类。也正是因为这样的特殊属性,对高端零售行业而言,单笔订单的成败,对销售额的影响也相对较大,对门店销售服务的准确、快速响应也有更高的要求。
在商品信息存储在多套系统的情况下,门店一线销售人员就很难准确、实时地获取完整的订单信息以及每一件商品的最新状态。如果不能在顾客提出需求后,第一时间反馈商品是否有库存、是否需要调货,以及调货所需时间等信息,就非常容易在信息查询与确认的“等待时间”里,导致潜在订单流失,对成交率造成不小的打击。这也是高端零售行业特别关注数据实时性的重要原因。
产能之于制造业;销量之于零售业——结论就是,实时数据,切实关乎企业的生死存亡。
不同数据集成方案在企业中的现状
数据集成的解决方案演进史
① API 集成:开发太繁琐,对源端性能侵入影响高
② ETL:实时性不够,无法有效复用,造成意大利面的摊子
③ Kafka:架构复杂,开发成本不低,关键数据排错很困难
综上所述,随着新目标业务系统的不断拓展,对源端业务的核心数据诉求越来越高,这三大类数据集成方案在企业中长期运行沉淀的过程中,也产生了大量链路,而链路的复杂度、开发和维护成本,以及管理压力也逐渐变得不可控起来。摊子越拉越大,任务难度不断升级——新的需求由此产生。这不是面向一个研发团队或是一个企业的挑战,这是新时期对数据集成解决方案的变革提出的要求。
二、矛盾决定需求:如何简化数据集成链路,实现快速交付?
已知:实时场景普遍存在,对实时数据的需求很明确,挖掘并充分利用实时数据来创造价值的目标也非常清晰。在这样的背景下,我们要做的就是优化调整中间的实现过程。假设存在这样一个数据平台,能够解决当下数据集成面临的各种问题与实时需求,它应该如何设计?
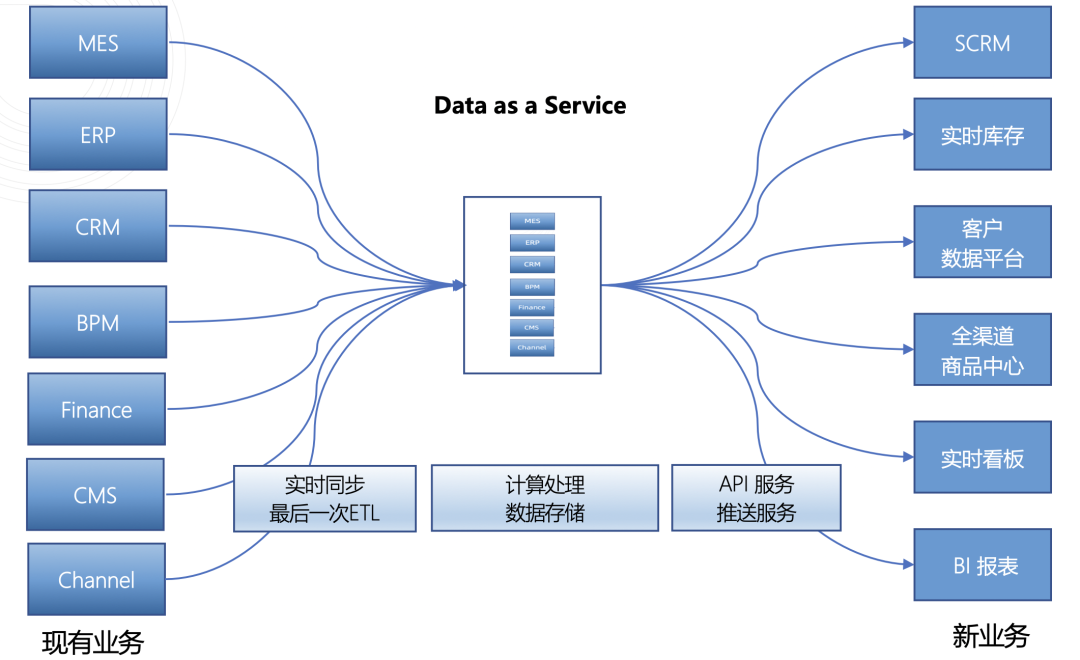
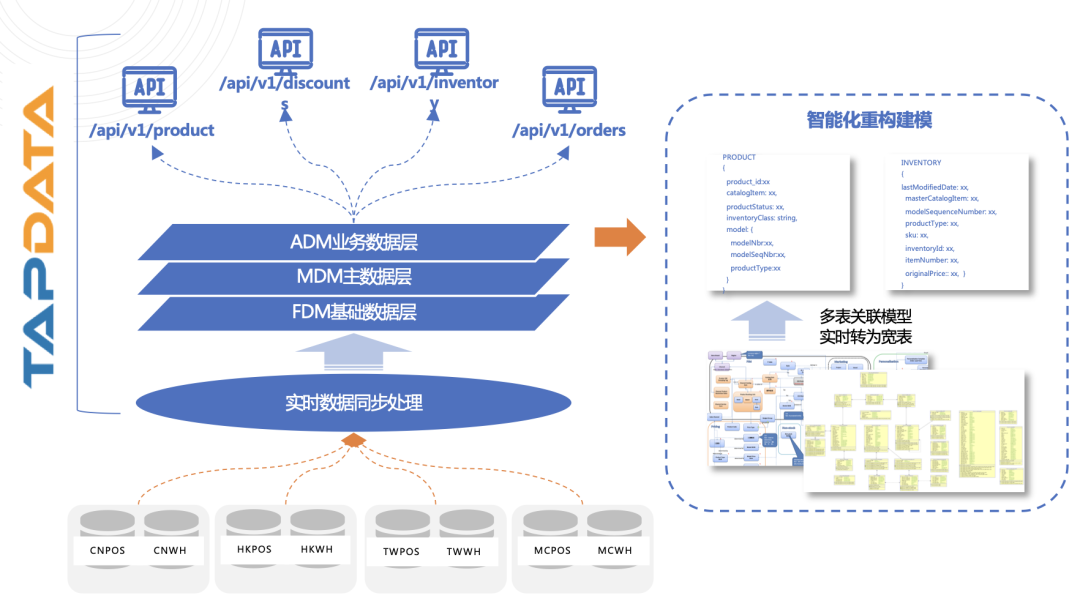
新一代企业级数据集成平台:以服务化方式为下游业务提供数据
数据即服务的架构理念
形成一个数据集成平台,让企业能够在这个平台里快速完成一系列的数据具加工、清洗工作,从而得以更专注于业务开发本身,减少大量繁琐的数据连接、数据重试等数据层面的开发工作。
IT 服务化是一个非常明确的趋势,从 20 年前亚马逊把基础架构作为服务开始(IaaS, Infrastructure as a Service),到十多年前把数据库中间件作为服务(PaaS, Platform as a Service),再到近几年特别火热的 SaaS(Software as a Service),“服务化”的发展非常快,服务化价值也得到了历史的证明。
在这一趋势的启发下,我们尝试将数据即服务的概念引入新一代数据集成解决方案,主张以服务化的方式来解决数据集成的问题。本质是将数据抽象为服务,为下游的所有业务提供极易用的数据能力。目的是以中央化的能力替代传统方案中的复杂链路,更专注于计算处理环节。
基于这样的方案设想,我们设计了一套 全新的数据架构:
新一代数据集成平台的工作机制
如上图所示,从左至右,是这个数据集成平台的数据流向:左侧包含各种各样的业务系统,在分析型业务之外,更多的还是企业的关键业务系统,例如 ERP、MES、供应链等企业核心命脉。右侧代表数据目标,平台要做的,就是将所需数据从左侧的业务系统中实时采集、推送过来。
实时数据平台的核心技术路线
在推进新方案落地的过程中,我们在技术层面遇到了如下四点挑战:
① 重中之重:异构数据的实时同步(CDC)
实时数据同步方式盘点
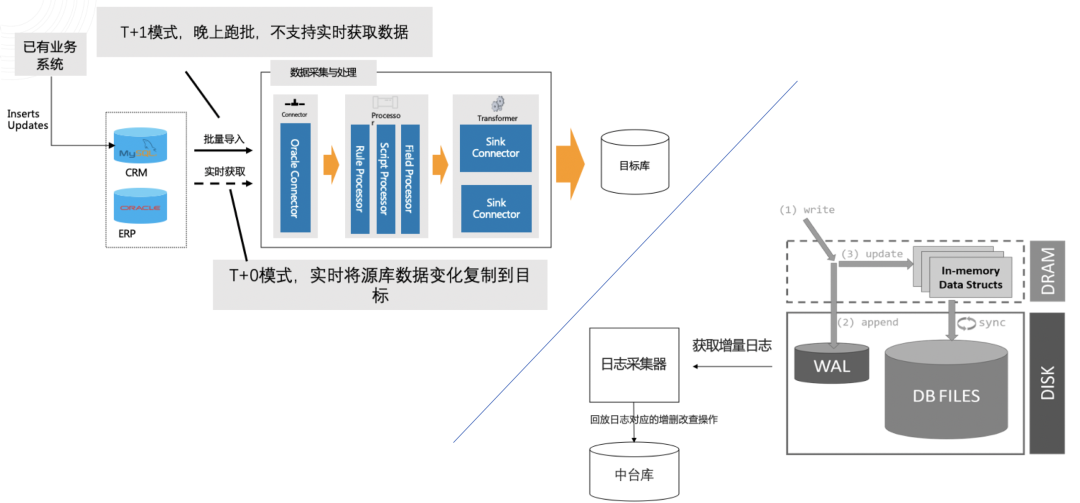
CDC,即 Capture Data Change,捕捉事件变化,不同于传统 ETL 定期执行轮询的方式,已经完全脱离了数据 SQL 的查询方式本身,直接监听日志变化,实时追踪数据记录的增删改。在实现 CDC 能力之前,其实已经有很多实时同步的技术架构出现,像是基于时间戳或者增量字段的采集方式,以及 Trigger 推送等,但或多或少都存在一些局限性。在这些挑战中,首要一点就是连接层(Connector)的问题。
核心技术:异构数据实时复制
如上图所示,Connector 层是数据实时同步的第一步,数据源不同,Connector 也不同。字段大小写转换、数据类型转换、清洗、计算、加工……对于不同的数据对象,在将数据推送至目标库之前,还需要进行大量处理操作。而 CDC 本质是 WAL 日志的解析方式,其实已经脱离了数据库类型的限制,是一种回归数据库日志本身的方案。
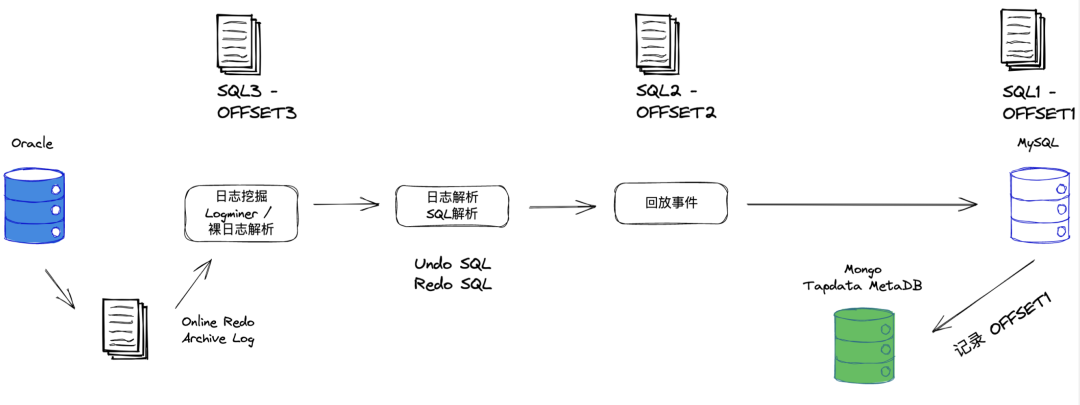
以 Oracle 为例,解析 CDC 工作原理
以数据源是 Oracle,数据目标是 MySQL 为例:如上图所示,写入 Oracle 的数据,最先会进入 Online Redo Log,即落入 Memory Buffer 中,这时就可以对这些数据进行挖掘了。刚写入就抓取,像这样基于数据库事件的挖掘,无疑是最实时的方式,比起轮询要快得多。
挖掘之后,再对这些事件进行日志解析,解析出来的日志无非就是 Undo 和 Redo 两条 SQL,分别代表 delete 和 insert。再经过数据对象转换,匹配 Oracle 与 MySQL 的数据类型,完成整个事件流的回放,成功将 Redo 日志推送到目标库。出于对数据平台集成能力的整体考量,在事件回放过程中,断点续传的能力也不容忽视。上图中的 OFFSET 就是用来记录事件偏移量的,是数据同步的准确性和正确性的重要保障。
② 最易用的数据开发体验:面向开发者、面向数据工程师
数据开发:低代码+Open API
③ 中央化存储方案:DaaS
中央化存储方案:DaaS
中央化存储面临的关键问题就是数据能否落地,因为落地代表着数据可复用,如果不能落地,本质就还是一个同步工具而非数据平台。为此,我们将数据落在一个集中化的管理中,而不是像一些传统方案一样直接推到目标端。这样的好处是:一方面可以将对源库的压力降到最低,另一方面更便于数据的复用。
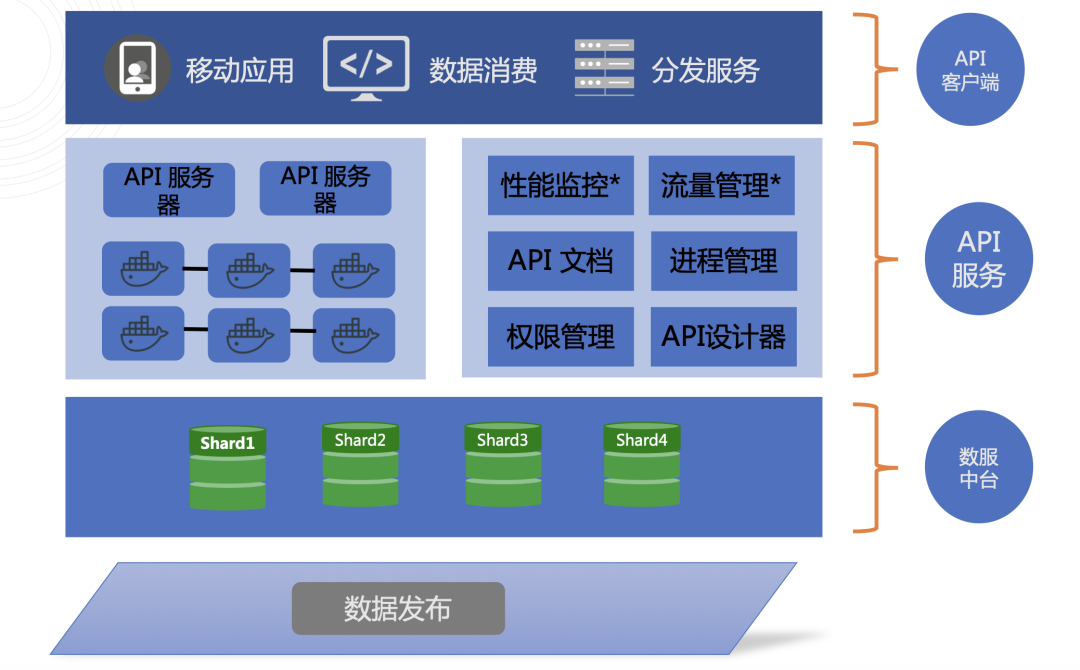
④ 数据发布 API
数据发布 API
支持将各库各表的数据以 API 的形式发布,并作为一种资源供不同的业务方调用,在统一数据接入层的同时,也大大降低了运维的压力和工作负载。
物理架构追求:简单、低运维成本
|
服务
|
功能模块
|
HOST
|
硬件配置
|
|
Tapdata Management
Tapdata API Server
Tapdata Flow Engine
|
数据治理引擎
管理模块
API 发布节点
|
tapdata-01
tapdata-02
|
CPU: 16c
RAM: 64GB
DISK: 100GB
|
|
MongoDB
|
Tapdata MetaDB
|
mongodb-01
mongodb-02
mongodb-03
|
CPU: 16c
RAM: 64GB
DISK: 1TB
|
分部/总部单点架构说明:
-
Tapdata Management:负责软件各模块调度和网页控制台展现
-
Tapdata API Server:负责数据发布及 API 网关
-
Tapdata Flow Engine:负责数据同步、清洗、多表关联、聚合计算等。
-
MongoDB:Tapdata 数据库,中间缓存结果。
2 节点可支持 负载均衡及 高可用,保证单点故障后的 任务自动接管及 断点续传
三、设想照进现实:Tapdata Live Data Platform
Tapdata:自带 ETL 的实时数据平台
DNA 品质:全链路实时的能力,支持 TP+AP 场景,发挥更大的数据价值
Tapdata 全程面向具有最高价值的 TP 和实时分析的 AP 场景,旨在发挥更大的实时数据价值,主要体现在三个方面:
Tapdata 最佳实践
-
当前挑战
-
商品、订单、库存数据分布在多套系统,数据冗余
-
上新活动周期长
-
无法获得最准确的商品库存
-
已有系统过于陈旧,更新、维护困难
-
诉求(希望达到的目标)
-
全渠道商品中心:提供更好的客户体验
-
快速响应业务(线上线下活动)
-
成功指标
-
搭建基于 MongoDB 的 DaaS 平台
-
开发主数据模型,包括:商品模型、订单库存模型
-
发布主数据 API
实时数据服务平台案例
Tapdata:Make Your Data on Tap
-
以全自动化的实时数据集成能力为基础,连接并统一企业的数据孤岛,成为企业的主数据底座,为企业的数据驱动业务 "Warehouse Native" 提供全面,完整,准确的数据支撑——这便是 Tapdata 的愿景与追求。
还有更多有关实时数据集成的问题亟待解答?想要真正上手体验新一代实时数据平台?欢迎扫描上方二维码或
点击这里,注册成为
Tapdata LDP 首批体验官,获取体验官专属服务。
我们期待与您共创一个更加优雅易用的新一代实时数据平台,见证实时数据的更多可能。
原文链接:https://tapdata.net/enterprise-data-status-analysis.html