leetcode-5 最长回文子串
题目
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。
示例 2:
输入: "cbbd"
输出: "bb"
分析
初步分析
首先能想到的就是暴力解法,遍历每一个字符,寻找以该字符为中心或者以该字符和下一个字符为中心的最大的回文子串,时间复杂度O(n2),具体见下面代码。
第一个问题:暴力解法有哪些地方是可以优化的?
其实要回答这个问题并不简单,有些题目的可优化点是容易看到的,而有些并非轻易看到,比如本题,要回答这个问题还是要从题目给出的线索中寻找。题目说回文串,我们就要充分利用到这个回文串的特性,回文串的特性比较简单(为了简单起见下文先考虑bab这种长度为奇数的回文子串):
假设对称中心为id,x、y是关于id对称的,即x+y=2*id,那么arr[x]=arr[y]
除此之外无其他本质特性了。其他特性就是再根据一些场景和上述本质特性推导出来的特性,这种无非就是利用对称对等关系,利用多组对称对等关系可以得出一些其他结论。例如如下场景:
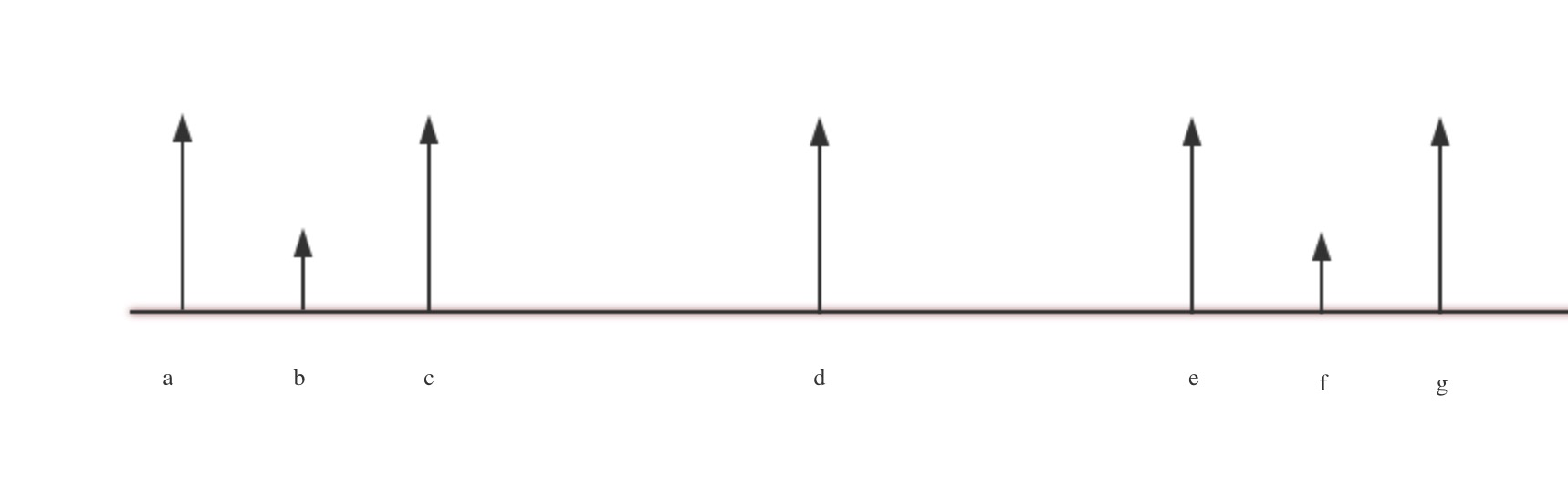
![回文特性]()
描述如下:
- arr是字符数组,图中a~g的下标是对应字符在数组中的位置
- a~g是一个关于d对称的回文串,b和f关于d对称,有arr[a]=arr[g]
- a~c是一个关于b对称的回文串,有arr[a]=arr[c]
- e和g关于f对称,我们来推算arr[e]和arr[g]的关系
a和g关于d对称,b和f关于d对称,a和c关于b对称,e和g关于f对称,可以得到c和e关于d对称,由于a~g是一个回文子串,那么就有arr[c]=arr[e]
再根据上述已知条件,得知arr[c]=arr[a]=arr[g],那么arr[e]=arr[g],即e~g也是一个关于f对称的回文串,并且这个回文串跟以b为中心的回文串是一样的。也就可以得到如下推导结论:
- 在一个回文串内,b和f对称,那么以b为对称中心的回文子串和以f为对称中心的回文子串是一模一样的
根据上述推导结论来重新看待上述暴力解法,以上述例子为例,我们在遍历到d后,找到了它的最大回文子串a~g,那么对于求解以d~g之间的字符为中心的回文子串时可以充分利用到他们的对称点的回文子串而不必再从0开始一个一个从对称点开始比较了(仅限包含在a~g大串内部的,因为一旦超出a~g上述推导结论就不能成立了)
利用推导结论进行优化
总结下上述优化的一些关键点:在一个回文串中,可以优化该回文串中右半部分字符的求解过程。所以需要尽量找到一个右临界点最大的回文串,这样就容易将很多字符纳入到优化中。留一个思考点:右临界点最大一定是最优的吗?
前面说的优化有一个大前提,必须在一个回文串内部,仍以上图为例:
以b为中心的最长回文串可能在a~g内部,也可能超出a,我们只能得出在以b为中心的最长回文子串在a~g内部这一部分和以f为中心的最长回文子串在a~g内部这一部分是一模一样的,即可以省去对比过程,但是对于超出a~g的部分是无法判断的,只能按照老办法一个一个去匹配
所以我们需要记录字符b对应的最长回文子串的半长度p,那么减少的判断个数就是min(p,b-a),后续仍要继续匹配,具体来说就是如下代码
int targetId = 0;
int targetLen = 0;
int maxRight = 0;
int id = 0;
int[] pLens = new int[newArr.length];
for (int i = 0; i < newArr.length; i++) {
pLens[i] = maxRight > i ? Math.min(pLens[2 * id - i], maxRight - i) : 1;
int left = i - pLens[i];
int right = i + pLens[i];
while (left >= 0 && right < newArr.length && newArr[left] == newArr[right]) {
pLens[i] = pLens[i] + 1;
left--;
right++;
}
int newRight = i + pLens[i] - 1;
if (newRight > maxRight) {
maxRight = newRight;
id = i;
}
if (pLens[i] > targetLen) {
targetId = i;
targetLen = pLens[i];
}
}
总体来说仍然是遍历每个字符,优化就是一旦该字符在最右临界点的回文子串内,可以减少一些判断次数,假如不在最右临界点内,则还是老老实实一个一个匹配。
上述Math.min(pLens[2 * id - i], maxRight - i),前者是最长i的对称点的最长回文子串的长度,maxRight-i则是将回文子串长度局限在了回文子串内,只有这样才能利用推导结论来优化
讨论回文串长度的奇数和偶数
上面优化的思路就是马拉车算法的核心,但是马拉车算法提出需要对每个字符串之间插入特殊字符来规避回文串长度的奇数和偶数的问题,是否真的有必要?
前面为了简化分析,只讨论了回文串长度为奇数的情况,那么对于abba这样的回文串,会对上述分析产生什么样的影响?
对于上述推导结论并不产生实质性的影响,还是以上图为例,b和f关于某个中心对称,那么以f为对称中心的回文串和以b为对称中心的回文串是符合上述推导结论的,并且以f+0.5为对称中心的回文串和以b+0.5为对称中心的回文串仍然是符合上述推导结论的,那就意味着不管回文串的长度是奇数还是偶数,都可以采用上述优化思路来进行优化,完全可以做到一视同仁
只需要在遍历每个字符时,除了要求解以每个字符为对称中心的最长回文串还要求解以每个字符+0.5为对称中心的最长回文串,具体见下面代码。也就是说马拉车算法的预处理其实就是画蛇添足,还额外增加了2N的存储,还额外多遍历了一遍N。同时相比我的方案,还有很多多余的判断比如判断#是否等于#
代码
暴力解法如下,时间复杂度O(n2):
private int maxStart;
private int maxLen;
public String longestPalindrome(String s) {
if (s.length() <= 1) {
return s;
}
char[] arr = s.toCharArray();
for (int i = 0, len = arr.length - 1; i < len; i++) {
findLen(i, i + 1, arr);
findLen(i - 1, i + 1, arr);
}
if (maxLen > 0) {
return s.substring(maxStart, (maxStart + maxLen));
} else {
return s.substring(0, 1);
}
}
private void findLen(int start, int end, char[] arr) {
while (start >= 0 && end < arr.length && arr[start] == arr[end]) {
start--;
end++;
}
int currentLen = end - start - 1;
if (currentLen > maxLen) {
maxLen = currentLen;
maxStart = start + 1;
}
}
无需预插入的Manacher‘s Algorithm改进版,时间复杂度O(n)
public String longestPalindrome(String s) {
if (s.length() <= 1) {
return s;
}
char[] arr = s.toCharArray();
int targetId = 0;
int targetLen = 0;
int maxRight = 0;
int id = 0;
int[] pLens = new int[arr.length * 2];
for (int i = 0, len = 2 * arr.length; i < len; i++) {
int index = i / 2;
boolean real = i % 2 == 0;
pLens[i] = maxRight > index ? Math.min(pLens[2 * id - i], maxRight * 2 - i) : 1;
int left;
if (real) {
left = index - pLens[i];
} else {
left = index - pLens[i] + 1;
}
int right = index + pLens[i];
while (left >= 0 && right < arr.length && arr[left] == arr[right]) {
pLens[i] = pLens[i] + 1;
left--;
right++;
}
int newRight = index + pLens[i] - 1;
if (newRight > maxRight) {
maxRight = newRight;
id = i;
}
if (pLens[i] > targetLen || (real && pLens[i] == targetLen)) {
targetId = i;
targetLen = pLens[i];
}
}
targetLen--;
int mid = targetId / 2;
int start, end;
if (targetId % 2 == 0) {
start = mid - targetLen;
end = start + targetLen * 2 + 1;
} else {
start = mid - targetLen + 1;
end = start + targetLen * 2;
}
return s.substring(start, end);
}
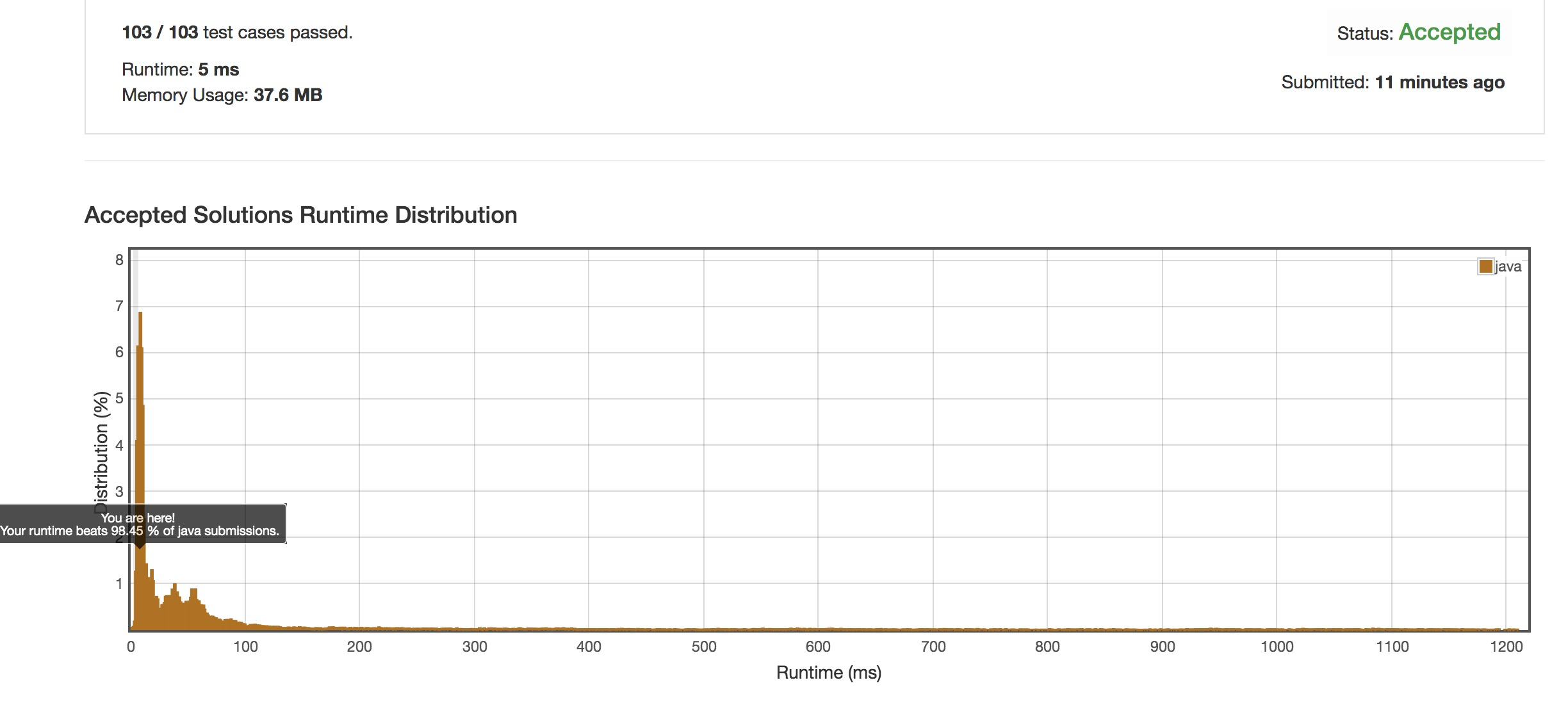
跑分
![]()
欢迎关注微信公众号:乒乓狂魔