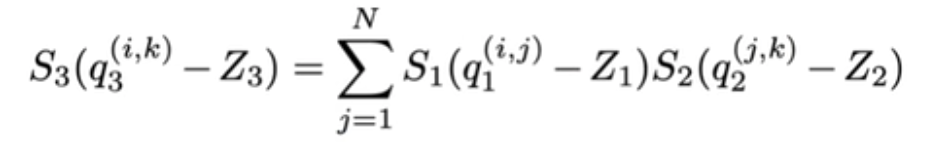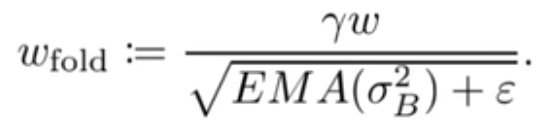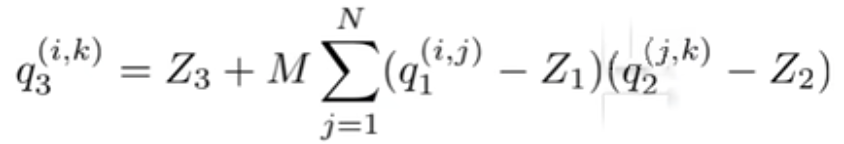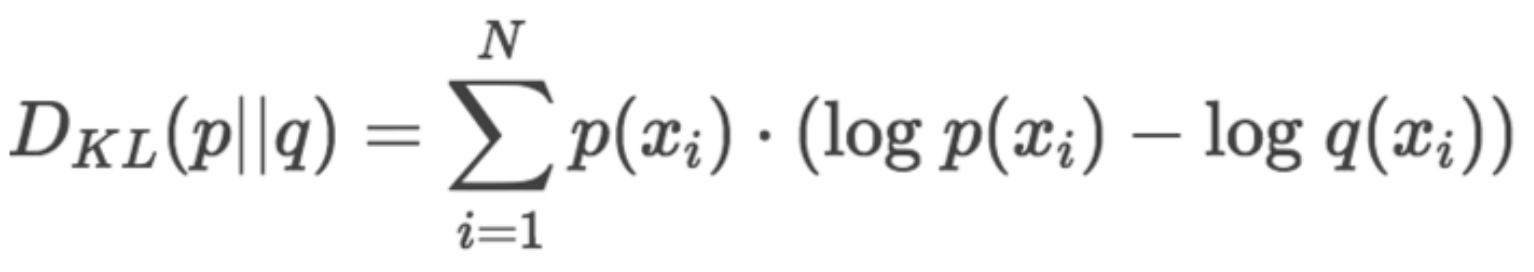服务器部署
Flask
Flask是一个使用Python编写的轻量级Web应用框架。
安装Flask
pip install Flask
现在我们开始一个Hello World。
from flask import Flask, request
app = Flask(__name__)
@app.route("/hello")
def helloword():
return "<h1>Hello World</h1>"
if __name__ == '__main__':
app.run(host='192.168.0.138', port=8090, debug=True)
运行后显示
* Serving Flask app "flask_web" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://192.168.0.138:8090/ (Press CTRL+C to quit)
* Restarting with fsevents reloader
* Debugger is active!
* Debugger PIN: 235-830-661
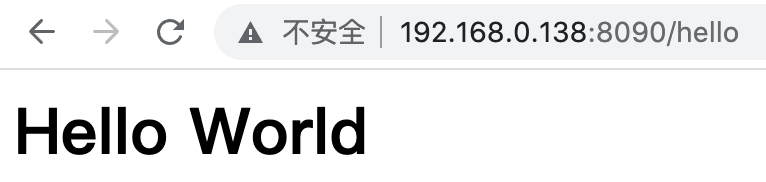
我们在浏览器中输入http://192.168.0.138:8090/hello,得到
![]()
现在我们再增加一个非常重要的方法,图片上传,提供给模型进行前向推理。
from flask import Flask, request
import os
app = Flask(__name__)
@app.route("/hello")
def helloword():
return "<h1>Hello World</h1>"
@app.route("/upload", methods=['POST', 'GET'])
def upload():
f = request.files.get('file')
print(f)
upload_path = os.path.join("/Users/admin/Documents/tmp/tmp." + f.filename.split('.')[-1])
print(upload_path)
f.save(upload_path)
return upload_path
if __name__ == '__main__':
app.run(host='192.168.0.138', port=8090, debug=True)
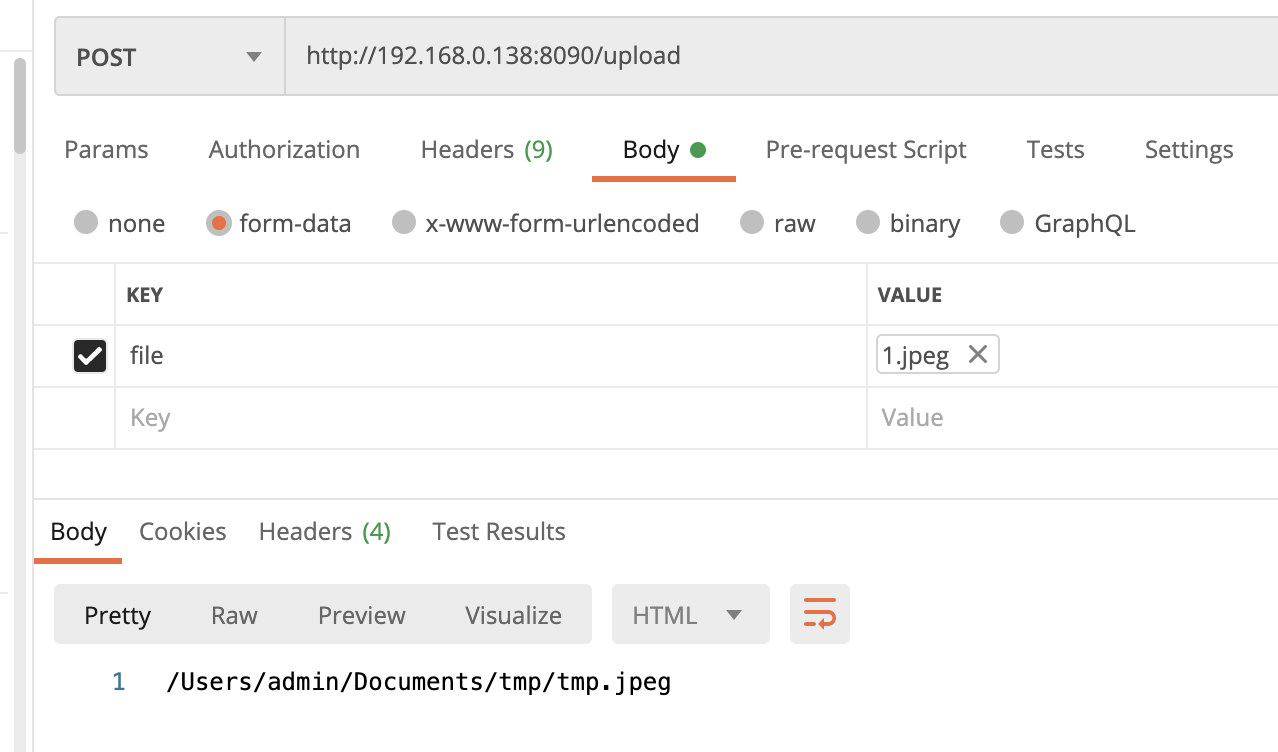
重新启动后,我们使用postman来上传文件
![]()
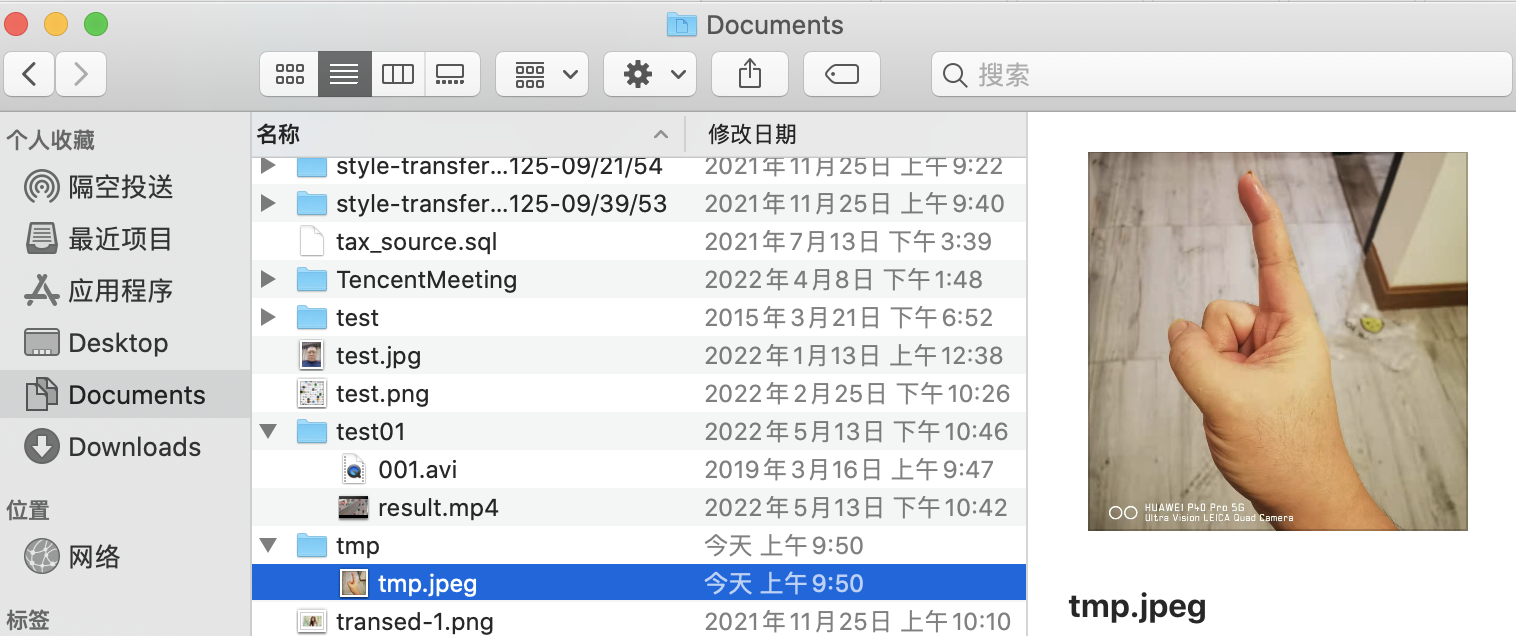
并在我们编辑的路径中找到该文件
![]()
运行结果
<FileStorage: '1.jpeg' ('image/jpeg')>
/Users/admin/Documents/tmp/tmp.jpeg
192.168.0.138 - - [02/Jun/2022 09:50:55] "POST /upload HTTP/1.1" 200 -
动态启动服务
安装gunicorn
pip install gunicorn
进入flask python文件的目录,我这里是
cd Downloads/PycharmProjects/untitled1/flask-web/
运行命令
gunicorn -b 192.168.0.138:8000 -w 2 flask_web:app
这里使用的端口号不需要跟代码中的相同,可以任意定义
运行日志
[2022-06-02 10:31:12 +0800] [1980] [INFO] Starting gunicorn 20.1.0
[2022-06-02 10:31:12 +0800] [1980] [INFO] Listening at: http://192.168.0.138:8090 (1980)
[2022-06-02 10:31:12 +0800] [1980] [INFO] Using worker: sync
[2022-06-02 10:31:12 +0800] [1983] [INFO] Booting worker with pid: 1983
[2022-06-02 10:33:40 +0800] [1980] [CRITICAL] WORKER TIMEOUT (pid:1983)
[2022-06-02 10:33:40 +0800] [1983] [INFO] Worker exiting (pid: 1983)
[2022-06-02 10:33:40 +0800] [1989] [INFO] Booting worker with pid: 1989
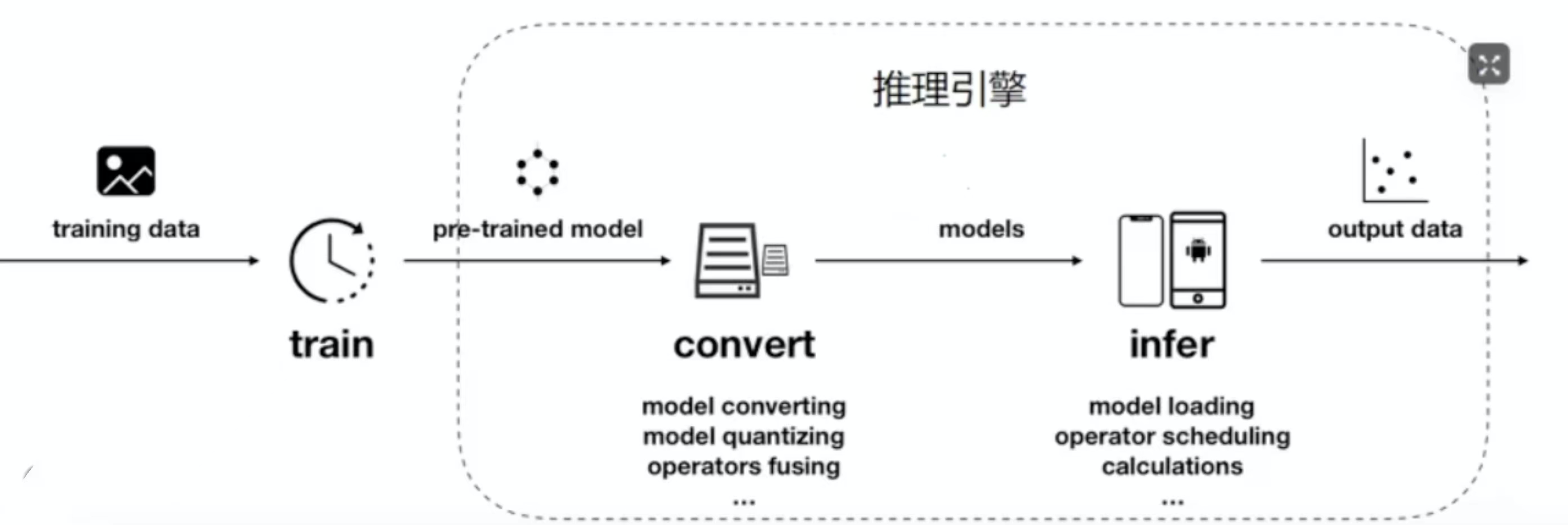
Android部署(MNN)
![]()
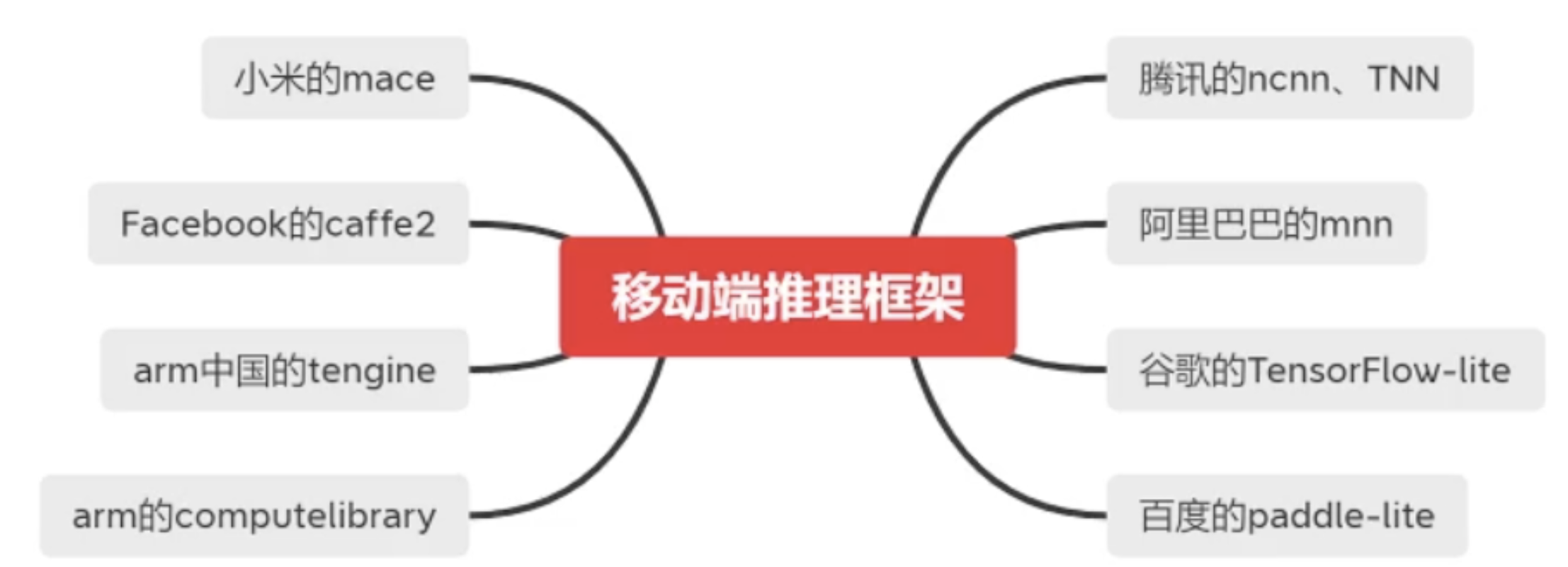
推理框架有很多,它的原理就是负责把我们训练出来的模型进行转换,然后再部署到终端上,然后我们可以在终端上使用我们训练出来的模型
![]()
主要包括以上的种类,它们的对比如下
![]()
这里的框架支持是指的训练框架,一般现在都使用的是Pytorch。Pytorch转换出来的对应的是ONNX,具体可以参考PyTorch技术点整理 中的模型开发与部署中的ONNX。TensorFlow最擅长的就是使用Tensorflow-lite来转换自己的模型;百度的paddle-lite最擅长的也是转换自己的飞桨(PaddleFluid)模型。现在用的比较多的是MNN、ncnn、TNN。这里我们专门介绍阿里的MNN。
模型的转化与量化加速
环境监察
cmake -version
要求cmake版本在3.10或以上
pip list | grep -i protobuf
要求protobuf版本在3.0或以上
gcc --version
要求gcc版本在4.9或以上
下载地址:https://github.com/alibaba/MNN
NDK下载地址:https://developer.android.com/ndk/downloads
NDK下载完成后,因为我这里是mac系统,我的安装目录是/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/自己创建的路径,然后在/etc/profile中添加
export ANDROID_NDK=/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/Contents/NDK
export PATH=$PATH:$ANDROID_NDK
保存后source一下,执行
ndk-build
出现
Android NDK: Could not find application project directory !
Android NDK: Please define the NDK_PROJECT_PATH variable to point to it.
/Users/admin/Android/sdk/ndk/AndroidNDK8568313.app/Contents/NDK/build/core/build-local.mk:151: *** Android NDK: Aborting . Stop.
说明安装成功。
SDK下载地址:https://developer.android.com/studio/releases/platform-tools
根据你自己使用的操作系统进行下载。下载完成后进行安装,我这里的安装地址为/Users/admin/Android/sdk/platform-tools。在/etc/profile中添加
export ANDROID_HOME=/Users/admin/Android/sdk
export PATH=$PATH:$ANDROID_HOME/platform-tools
source之后,打开自己的手机,我的手机为HUAWEI P40 Pro,进入设置->关于手机,连续点击版本号,进入开发者模式。再进入系统和更新,进入开发人员选项,勾选如下
![]()
在mac终端中输入
adb get-state
出现
device
说明连接成功。
打开MNN的代码,找到CMakeLists.txt,修改如下内容
option(MNN_BUILD_CONVERTER "Build Converter" ON)
option(MNN_OPENCL "Enable OpenCL" ON)
option(MNN_OPENGL "Enable OpenGL" ON)
option(MNN_VULKAN "Enable Vulkan" ON)
option(MNN_ARM82 "Enable ARM82" ON)
大概解释一下是什么意思
- MNN_BUILD_CONVERTER:默认关闭,对训练模型进行转化的工具
- MNN_OPENCL:默认关闭,可以通过指定MNN_FORWARD_OPENCL利用GPU进行推理
- MNN_OPENGL:默认关闭,可以通过指定MNN_FORWARD_OPENGL利用GPU进行推理
- MNN_VULKAN:默认关闭,可以通过指定MNN_FORWARD_VULKAN利用GPU进行推理
- MNN_ARM82:默认关闭,用Arm8.2+扩展指令集实现半精度浮点计算(fp16)和int8(sdot)加速
这里我们需要看一下自己手机的CPU型号,在终端中输入
adb shell getprop ro.product.cpu.abi
得到
arm64-v8a
以上都准备好之后就可以开始编译MNN了,进入MNN代码目录下的project/android目录下,我这里是
cd /Users/admin/Documents/MNN-master/project/android
创建编译后的目录
mkdir build_32
我们需要编译两套动态库,一套是32位的(armeabi-v7a),一套是64位的(arm64-v8a)。新建一个编译目录build_32目录,进入该目录
cd build_32
执行
../build_32.sh
编译完成后,开始编译64位的,回到上级目录,创建64位的编译后的目录
mkdir build_64
进入该目录
cd build_64
执行
../build_64.sh
编译完成后,我们可以看到有这么一些工具文件
![]()
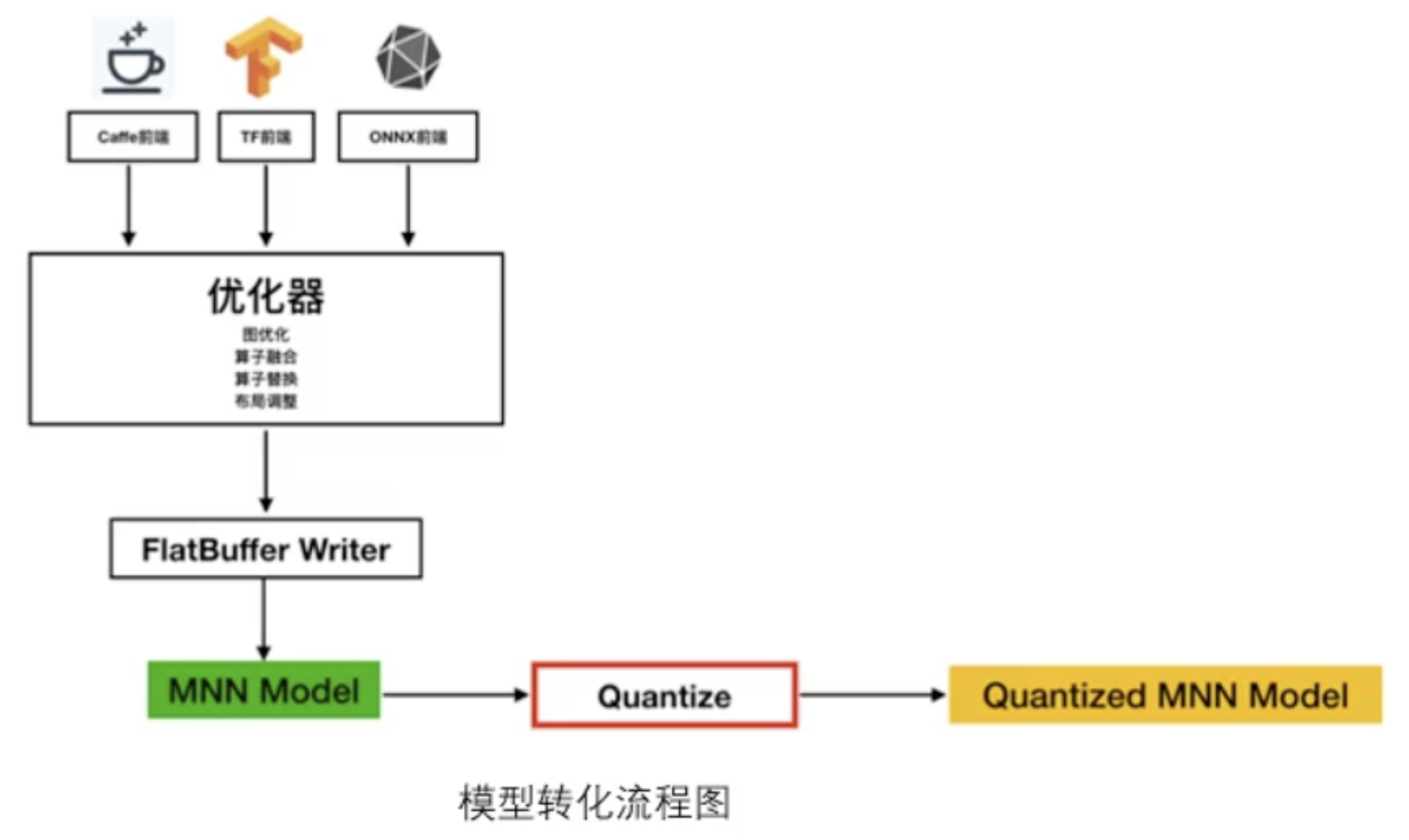
模型转化
![]()
无论是Caffe、TensorFlow还是Pytorch训练出来的模型都需要转成MNN自己的模型,得到了MNN Model之后,后续还可以进行量化、剪枝的操作。
TensorFlow -> MNN
./MNNConvert -f TF --modelFIle XXX.pb --MNNModel XXX.mnn --bizCode biz
TensorFlow Lite -> MNN
./MNNConvert -f TFLITE --modelFile XXX.tflite --MNNModel XXX.mnn --bizCode biz
Caffe -> MNN
./MNNConvert -f CAFFE --modelFile XXX.caffemodel --prototxt XXX.prototxt --MNNModel XXX.mnn --bizCode biz
ONNX -> MNN
./MNNConvert -f ONNX --modelFile XXX.onnx --MNNModel XXX.mnn --bizCode biz
Pytorch权重pth转换onnx
import torch
from torch.autograd import Variable
from u_net import UNet_ResNet
if __name__ == '__main__':
net = UNet_ResNet()
net.load_state_dict(torch.load('unetv1.pth', map_location=torch.device('cpu')))
X = Variable(torch.randn(1, 3, 512, 1024))
torch.onnx.export(net, X, 'unetv1.onnx', verbose=True, opset_version=10)
这里需要注意的是,如果你的模型代码中包含了dropout的代码,需要对其设置训练标识并关闭训练标识,如
class UNet_ResNet(nn.Module):
def __init__(self, in_channels=3, n_classes=N_CLASSES, dropout=0.5, start_fm=START_FRAME, is_train=False):
super(UNet_ResNet, self).__init__()
if self.is_train:
x = nn.Dropout2d(self.drop)(x)
模型转换可以用这个线上工具:https://convertmodel.com/
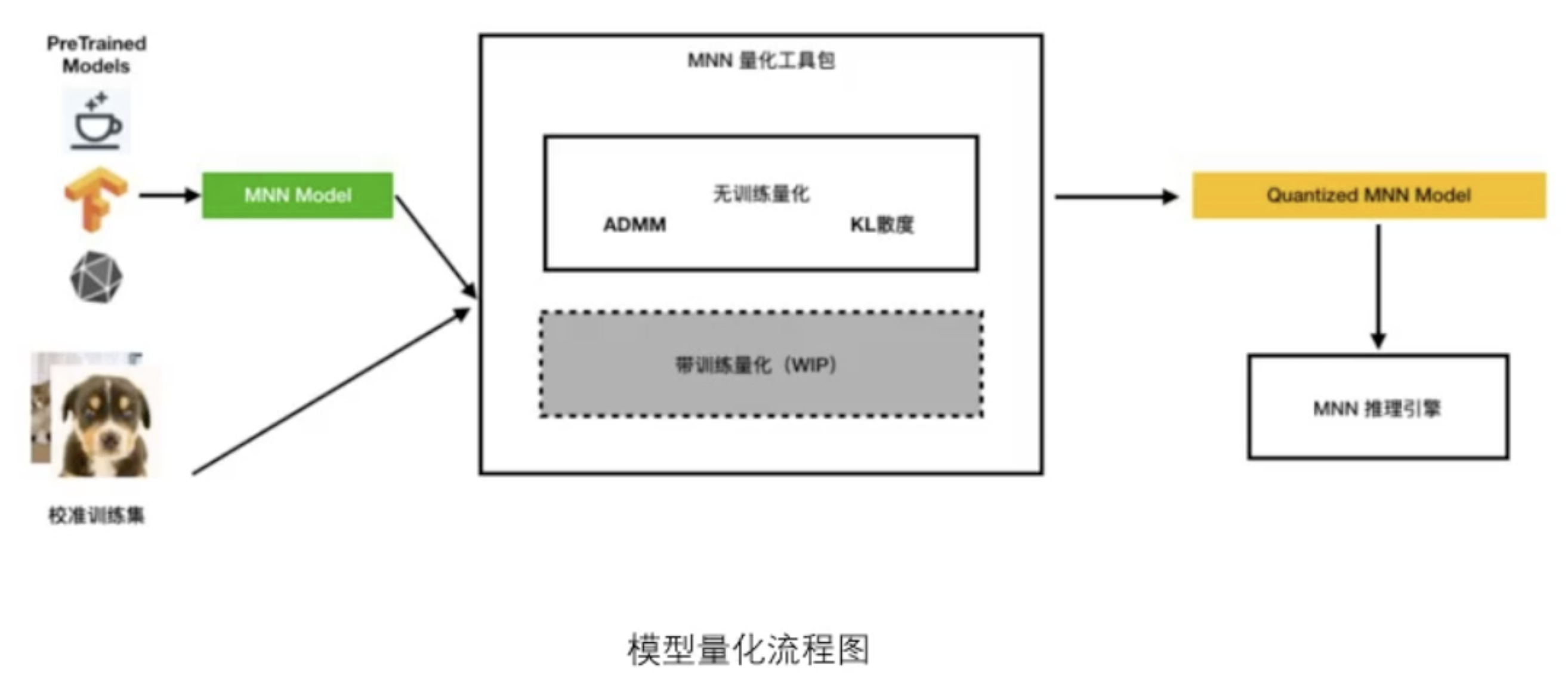
模型量化
![]()
量化不光可以压缩模型的大小,它还有加速的作用。但是需要根据实际情况而定,比如对于特征提取的影响就很小,但是对于目标检测,量化之后可能会飘,识别的精度也会有一定的损失。但是提速大概可以提升20%左右。量化后的模型跟量化前的文件完全一样。
命令格式
./quantized.out ./unetv1.mnn unetv1_qua.mnn ./preprocessConfig.json
这个preprocessConfig.json是一个我们自己要配置的文件,一般文件格式如下
{"format":"RGB",
"mean":[127.5,127.5,127.5 ],
"normal":[0.00784314,0.00784314,0.00784314 ],
"width":224,
"height":224,
"path":"path/to/images/",
"used_image_num":500,
"feature_quantize_method":"KL",
"weight_quantize_method":"MAX_ABS"
}
feature_quantize_method:指定计算特征量化系数的方法,可选:
- "KL":使用KL散度进行特征量化系数的校正,一般需要100~1000张图片(若发现精度损失严重,可以适当增减样本数量,特别是检测/对齐等回归任务模型,样本建议适当减少)。
- "ADMM":使用ADMM(Alternating Direction Method of Multipliers)方法进行特征量化系数的校正,一般需要一个batch的数据。
默认:KL
weight_quantize_method:指定权值的量化方法,可选:
- "MAX_ABS":使用权值的绝对值的最大值进行对称量化。
- "ADMM":使用ADMM方法进行权值量化。
默认:MAX_ABS
上述特征量化方法和权值量化方法可进行多次测试,择优使用。
安卓部署(tf-lite)
tf-lite量化原理
在tensorflow-lite的论文里面提到,量化是将使用较高浮点数(通常是32位或64位)的神经网络近似为一个低比特宽度的神经网络的过程。通俗的说就是将float32或者float64处理成float16或者是int8格式的神经网络。
量化属于模型压缩技术的一环,但也是效果比较明显的一环。模型压缩包含:剪枝、量化、蒸馏、低秩分解、权值共享等。前三种是目前模型轻量化用的比较多的技术。
![]()
量化有训练后量化(PTQ)和量化感知训练(QAT),tf-lite训练后量化推理大概流程:
- 输入量化后的数据和权重
- 通过反量化公式计算矩阵卷积
![]()
- 将int32 bias加到矩阵卷积结果,其中bias的量化参数为
![]()
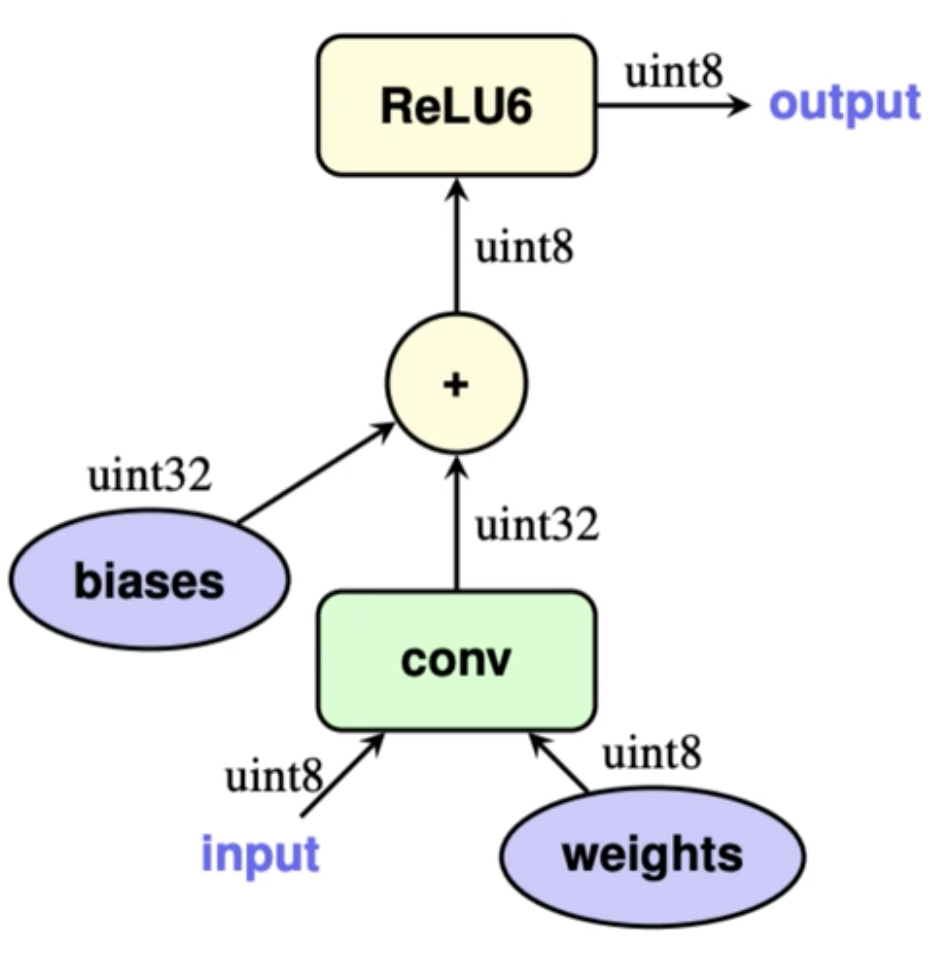
- 如果卷积之后包含bn层,则将bn层包含到卷积计算中
![]()
- 如果卷积/bn层之后包含激活层,比如ReLu,那么ReLu也会直接通过区间截断操作包含到对应的卷积计算中,如果不能包含的进去的,则会做相应的定点计算近似逼近。
- 最后将输出结果量化到int8。
其中4和5,是根据具体情况在导出量化模型的时候已经做好,推理的时候直接无需再多额外参数合并。
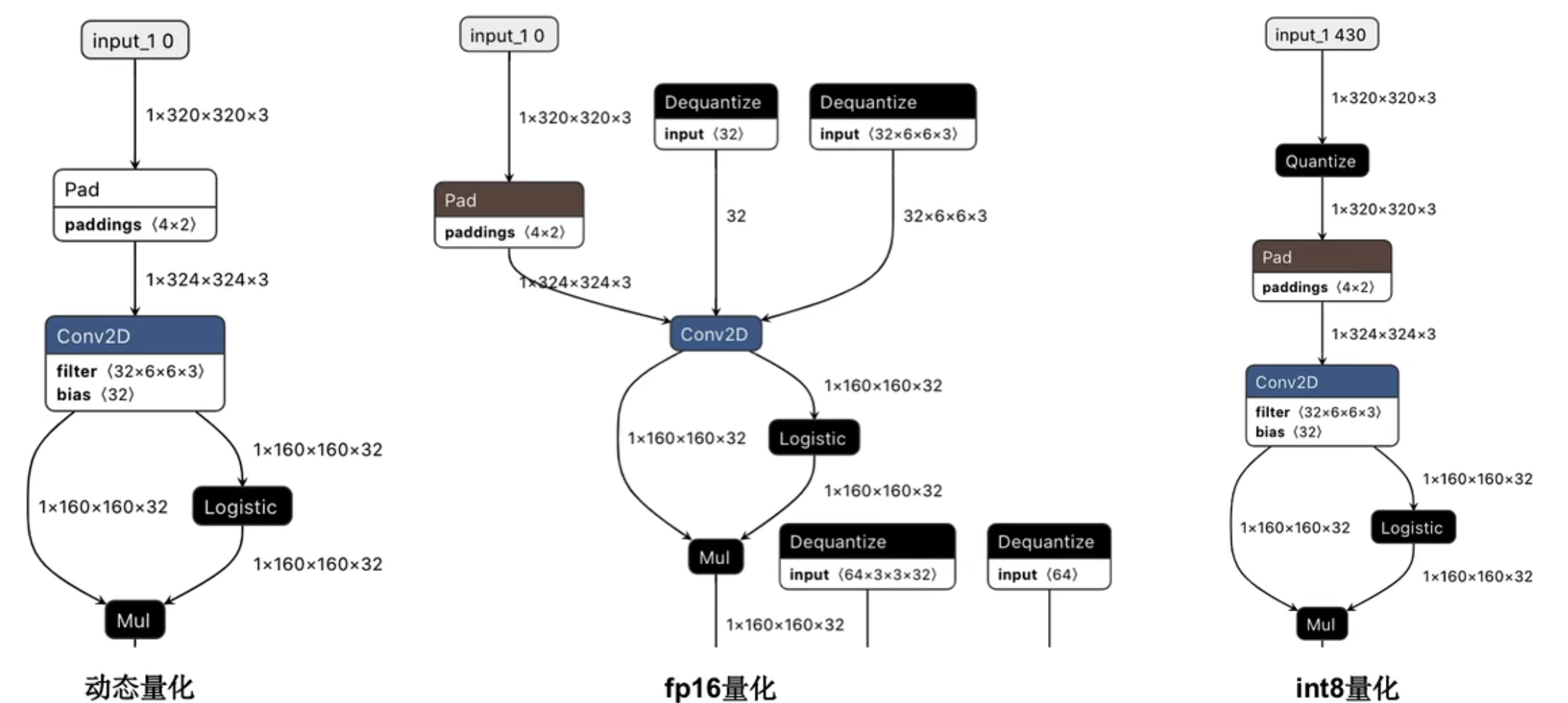
![]()
tf-lite训练后量化推理大概流程(int8为例)
1、输入量化后的数据和权重,通常都是float32/float64类型,量化模型会把float32/float64类型转化成float16/int格式
import numpy as np
import tensorflow as tf
def representative_dataset():
"""
模型转换时,提供represent_dataset方法帮助计算int8量化参数,
该方法根据自己数据读取提供部分即可
:return:
"""
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
def export_tflite(keras_model, f):
# 读取keras模型
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
# 指定优化器,DEFAULT会自己权衡模型大小和延迟性能
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 指定代表数据样本
converter.representative_dataset = representative_dataset()
# 指定模型量化类型为int8
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
# 指定输入和输出类型都是int8,所以才需要提供respresent_dataset
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
converter.experimental_new_quantizer = False
tflite_model = converter.convert()
open(f, 'wb').write(tflite_model)
2、反量化公式![]() ,公式里是假定两个矩阵相乘,分别为量化后的input tensor q1和filter kernel q2,另外S1、S2、S3为缩放因子,用来缩放值域;Z1、Z2、Z3为零点,用来对齐浮点和量化值0值,在没量化前,矩阵的乘法为:
,公式里是假定两个矩阵相乘,分别为量化后的input tensor q1和filter kernel q2,另外S1、S2、S3为缩放因子,用来缩放值域;Z1、Z2、Z3为零点,用来对齐浮点和量化值0值,在没量化前,矩阵的乘法为:![]() ,r表示浮点数,r(real value)和q(quantization value)的关系可以用下面公式表示
,r表示浮点数,r(real value)和q(quantization value)的关系可以用下面公式表示
![]()
进一步展开反量化公式可以得到最后卷积乘法的量化输出:
![]()
其中![]()
那么到目前为止,除了还没加上bias,tflite中int8卷积计算大概就是上面公式所示,该公式中除了M的计算设计浮点外,另外的所有计算都是在整数范围下,为了让整个计算过程能尽量减少浮点参与,tflite特地针对M的计算进行了优化,具体为将M替换为:![]()
由于S1、S2、S3都是已知,且通过大量观察得到M通常都是位于区间(0,1),这样就可以通过采用定点数![]() 以及位运算近似得到M,而定点数运算在gemmlowp库中已有高效的实现。
以及位运算近似得到M,而定点数运算在gemmlowp库中已有高效的实现。
tf-lite量化导出
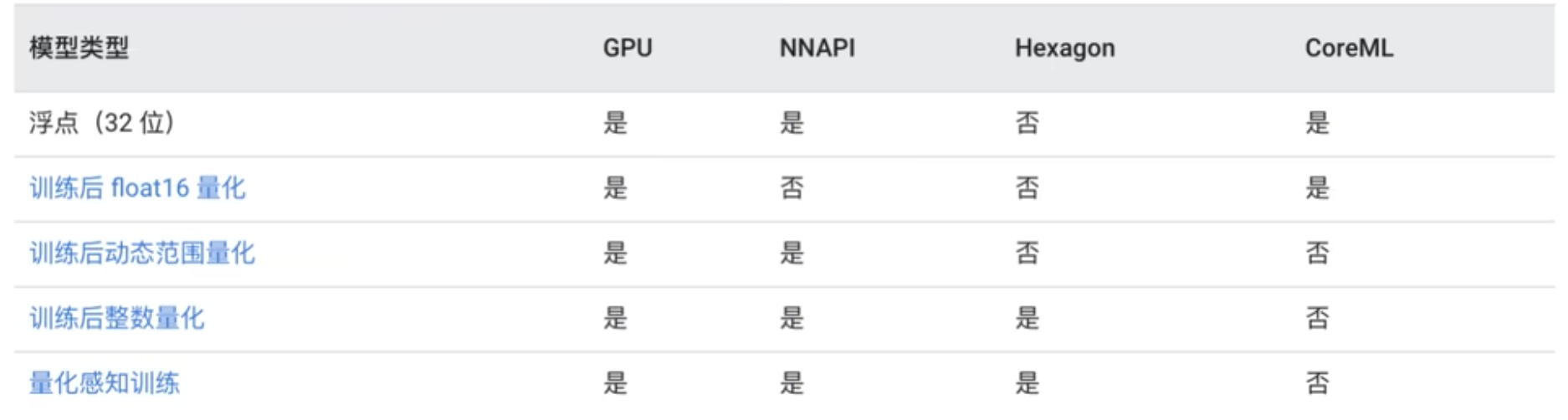
tflite官方提供了4种量化方法
![]()
从上到下分别为
- float16量化,input/output都是float32,体积减小50%,这种能尽最大可能保留模型精度,同时又能减小模型体积。
- 动态量化,input/output都是float32,模型参数为int8,过程输入输出都是float32,体积能减小75%。
- 全整型量化,input/output,包括整型参数,过程输入输出都是int8,同样体积能减小75%,与方法2不同的是,全整型量化输入输出都是int8,对于一些只能在整型上计算的板子,这是唯一的方法,同时这种方法需要提供小批量数据,用于标定input/output的量化参数scale/zero-point。
- 量化感知训练,可以用于边量化模型边训练,提高量化后模型精度。
python export.py --weights yolov5s.pt --include tflite --imgsz 320
此时我们可以看见导出文件
![]()
它的主要核心功能在这个方法中,我们可以在其他框架使用时自己来写这个方法。
def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
# YOLOv5 TensorFlow Lite export
try:
import tensorflow as tf
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
batch_size, ch, *imgsz = list(im.shape) # BCHW
f = str(file).replace('.pt', '-fp16.tflite')
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
# 指定使用哪些op作为量化时可以采用的,目前可以选择的有:
# tf.lite.OpsSet.TFLITE_BUILTINS:只用tflite内置op,这是默认选项
# tf.lite.OpsSet.SELECT_TF_OPS:采用tf本身的op,但是不是所有tf方法都支持,不建议使用,除非有自己设计
# 的比较复杂的结构
# tf.lite.OpsSet.TFLITE_BUILTINS_INT8:只用tflite里面的int8的op
# tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8:实验接口,int8权重
# int16激活值,int32 bias,建议生产环境不用,这种设计可以在牺牲一定体积压缩下取得比单纯int8更高的精度
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
from models.tf import representative_dataset_gen
dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = True
f = str(file).replace('.pt', '-int8.tflite')
tflite_model = converter.convert()
open(f, "wb").write(tflite_model)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
except Exception as e:
LOGGER.info(f'\n{prefix} export failure: {e}')
这里需要说明的是,我们平时在保存模型参数的时候一般使用的是pth文件,这里是pt文件,其实这两种文件没有本质的不同,它们的区别只在于后缀名而已,都可以使用
torch.save(model.state_dict(), 'name.pth')
或者
torch.save(model.state_dict(), 'name.pt')
是一个意思。
由于我们用的是一个Pytorch的model,所以要将其转化为TensorFlow的model。
YOLOV5中是使用TensorFlow将整个模型给重写了一遍,当然这对于我们其他模型并不适合,费时费力。这里我们依然使用onnx来进行转换。一般我们现在很少用Tensorflow来做训练,只需要安装CPU版本的就可以了,当然版本必须为2.9.0或以上。
pip install tensorflow-cpu==2.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
拉取onnx-tensorflow,并安装
git clone https://github.com/onnx/onnx-tensorflow.git
cd onnx-tensorflow/
pip install -e .
转换代码
from onnx_tf.backend import prepare
import onnx
import tensorflow as tf
if __name__ == '__main__':
onnx_model = onnx.load('yolov5s.onnx')
tf_rep = prepare(onnx_model)
tf_rep.export_graph("yolov5s.tf")
converter = tf.lite.TFLiteConverter.from_saved_model('yolov5s.tf')
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open("yolov5s-fp16.tflite", "wb").write(tflite_model)
这里我们需要注意的是yolov5s.tf其实是一个文件夹,它里面真正的tensorflow模型文件其实是saved_model.pb文件
![]()
YOLOV5中没有具体实现,但其实实现很简单,只需要注释掉
converter.target_spec.supported_types = [tf.float16]
即可
python export.py --weights yolov5s.pt --include tflite --imgsz 320 --int8
此时我们可以看见导出文件
![]()
全整型量化的核心其实是这一段
if int8:
from models.tf import representative_dataset_gen
dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = True
f = str(file).replace('.pt', '-int8.tflite')
当然用onnx转tflite也需要相应的修改,由于要提供小批量数据,所以会比较繁琐
from onnx_tf.backend import prepare
import onnx
import tensorflow as tf
import glob
from pathlib import Path
import os
import cv2
import numpy as np
import torch
import yaml
import logging
import platform
import time
from zipfile import ZipFile
from itertools import repeat
from multiprocessing.pool import ThreadPool
FILE = Path(__file__).resolve()
ROOT = FILE.parents[1]
DATASETS_DIR = ROOT.parent / 'datasets'
IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp' # include image suffixes
VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes
VERBOSE = str(os.getenv('YOLOv5_VERBOSE', True)).lower() == 'true'
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
class LoadImages:
# YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
def __init__(self, path, img_size=640, stride=32, auto=True):
p = str(Path(path).resolve()) # os-agnostic absolute path
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p):
files = [p] # files
else:
raise Exception(f'ERROR: {p} does not exist')
images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
ni, nv = len(images), len(videos)
self.img_size = img_size
self.stride = stride
self.files = images + videos
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv
self.mode = 'image'
self.auto = auto
if any(videos):
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count == self.nf:
raise StopIteration
path = self.files[self.count]
if self.video_flag[self.count]:
# Read video
self.mode = 'video'
ret_val, img0 = self.cap.read()
while not ret_val:
self.count += 1
self.cap.release()
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1
s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR
assert img0 is not None, f'Image Not Found {path}'
s = f'image {self.count}/{self.nf} {path}: '
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return path, img, img0, self.cap, s
def new_video(self, path):
self.frame = 0
self.cap = cv2.VideoCapture(path)
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
def __len__(self):
return self.nf # number of files
def is_kaggle():
# Is environment a Kaggle Notebook?
try:
assert os.environ.get('PWD') == '/kaggle/working'
assert os.environ.get('KAGGLE_URL_BASE') == 'https://www.kaggle.com'
return True
except AssertionError:
return False
def set_logging(name=None, verbose=VERBOSE):
# Sets level and returns logger
if is_kaggle():
for h in logging.root.handlers:
logging.root.removeHandler(h) # remove all handlers associated with the root logger object
rank = int(os.getenv('RANK', -1)) # rank in world for Multi-GPU trainings
logging.basicConfig(format="%(message)s", level=logging.INFO if (verbose and rank in (-1, 0)) else logging.WARNING)
return logging.getLogger(name)
LOGGER = set_logging('yolov5')
def emojis(str=''):
# Return platform-dependent emoji-safe version of string
return str.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else str
def colorstr(*input):
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
colors = {'black': '\033[30m', # basic colors
'red': '\033[31m',
'green': '\033[32m',
'yellow': '\033[33m',
'blue': '\033[34m',
'magenta': '\033[35m',
'cyan': '\033[36m',
'white': '\033[37m',
'bright_black': '\033[90m', # bright colors
'bright_red': '\033[91m',
'bright_green': '\033[92m',
'bright_yellow': '\033[93m',
'bright_blue': '\033[94m',
'bright_magenta': '\033[95m',
'bright_cyan': '\033[96m',
'bright_white': '\033[97m',
'end': '\033[0m', # misc
'bold': '\033[1m',
'underline': '\033[4m'}
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
def check_dataset(data, autodownload=True):
# Download and/or unzip dataset if not found locally
# Usage: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128_with_yaml.zip
# Download (optional)
extract_dir = ''
if isinstance(data, (str, Path)) and str(data).endswith('.zip'): # i.e. gs://bucket/dir/coco128.zip
download(data, dir=DATASETS_DIR, unzip=True, delete=False, curl=False, threads=1)
data = next((DATASETS_DIR / Path(data).stem).rglob('*.yaml'))
extract_dir, autodownload = data.parent, False
# Read yaml (optional)
if isinstance(data, (str, Path)):
with open(data, errors='ignore') as f:
data = yaml.safe_load(f) # dictionary
# Resolve paths
path = Path(extract_dir or data.get('path') or '') # optional 'path' default to '.'
if not path.is_absolute():
path = (ROOT / path).resolve()
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
data[k] = str(path / data[k]) if isinstance(data[k], str) else [str(path / x) for x in data[k]]
# Parse yaml
assert 'nc' in data, "Dataset 'nc' key missing."
if 'names' not in data:
data['names'] = [f'class{i}' for i in range(data['nc'])] # assign class names if missing
train, val, test, s = (data.get(x) for x in ('train', 'val', 'test', 'download'))
if val:
val = [Path(x).resolve() for x in (val if isinstance(val, list) else [val])] # val path
if not all(x.exists() for x in val):
LOGGER.info(emojis('\nDataset not found ⚠️, missing paths %s' % [str(x) for x in val if not x.exists()]))
if s and autodownload: # download script
t = time.time()
root = path.parent if 'path' in data else '..' # unzip directory i.e. '../'
if s.startswith('http') and s.endswith('.zip'): # URL
f = Path(s).name # filename
LOGGER.info(f'Downloading {s} to {f}...')
torch.hub.download_url_to_file(s, f)
Path(root).mkdir(parents=True, exist_ok=True) # create root
ZipFile(f).extractall(path=root) # unzip
Path(f).unlink() # remove zip
r = None # success
elif s.startswith('bash '): # bash script
LOGGER.info(f'Running {s} ...')
r = os.system(s)
else: # python script
r = exec(s, {'yaml': data}) # return None
dt = f'({round(time.time() - t, 1)}s)'
s = f"success ✅ {dt}, saved to {colorstr('bold', root)}" if r in (0, None) else f"failure {dt} ❌"
LOGGER.info(emojis(f"Dataset download {s}"))
else:
raise Exception(emojis('Dataset not found ❌'))
return data # dictionary
def download(url, dir='.', unzip=True, delete=True, curl=False, threads=1):
# Multi-threaded file download and unzip function, used in data.yaml for autodownload
def download_one(url, dir):
# Download 1 file
f = dir / Path(url).name # filename
if Path(url).is_file(): # exists in current path
Path(url).rename(f) # move to dir
elif not f.exists():
LOGGER.info(f'Downloading {url} to {f}...')
if curl:
os.system(f"curl -L '{url}' -o '{f}' --retry 9 -C -") # curl download, retry and resume on fail
else:
torch.hub.download_url_to_file(url, f, progress=threads == 1) # torch download
if unzip and f.suffix in ('.zip', '.gz'):
LOGGER.info(f'Unzipping {f}...')
if f.suffix == '.zip':
ZipFile(f).extractall(path=dir) # unzip
elif f.suffix == '.gz':
os.system(f'tar xfz {f} --directory {f.parent}') # unzip
if delete:
f.unlink() # remove zip
dir = Path(dir)
dir.mkdir(parents=True, exist_ok=True) # make directory
if threads > 1:
pool = ThreadPool(threads)
pool.imap(lambda x: download_one(*x), zip(url, repeat(dir))) # multi-threaded
pool.close()
pool.join()
else:
for u in [url] if isinstance(url, (str, Path)) else url:
download_one(u, dir)
def representative_dataset_gen(dataset, ncalib=100):
# Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
input = np.transpose(img, [1, 2, 0])
input = np.expand_dims(input, axis=0).astype(np.float32)
input /= 255
yield [input]
if n >= ncalib:
break
if __name__ == '__main__':
onnx_model = onnx.load('yolov5s.onnx')
tf_rep = prepare(onnx_model)
tf_rep.export_graph("yolov5s.tf")
dataset = LoadImages(check_dataset(ROOT / 'yolov5-master/data/coco128.yaml')['train'], img_size=(640, 640), auto=False) # representative data
converter = tf.lite.TFLiteConverter.from_saved_model('yolov5s.tf')
converter.representative_dataset = lambda: representative_dataset_gen(dataset, 100)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.uint8 # or tf.int8
converter.inference_output_type = tf.uint8 # or tf.int8
converter.experimental_new_quantizer = True
tflite_model = converter.convert()
open("yolov5s-int8.tflite", "wb").write(tflite_model)
这里我们用netron来看一下这三种模型的结构
![]()
动态量化下,input/output都是float32,计算过程整型加速与浮点加速同时兼顾,模型参数为int8,过程输入输出都是float32。
fp16量化下,input/output都是float32,同时当采用CPU运算时,模型权重w和bias会dequantize(反量化)到float32;如果采用GPU计算,则不需要做此步dequantize,因为tflite的gpu代理支持fp16操作。
int8量化下,input/output都是int8,在quantize是量化方法,里面有关于input/outoput的量化参数scale/zero point,所有的计算如Conv2D都遵循之前所讲的理论。
Python加载tf-lite模型
这一步是在我们部署之前进行验证,避免了直接到部署环境去验证。
import tensorflow as tf
import numpy as np
if __name__ == '__main__':
yolov5s = "yolov5s-fp16.tflite"
# 加载模型
interpreter = tf.lite.Interpreter(model_path=yolov5s)
# 把模型读取进内存
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
input_shape = interpreter.get_input_details()[0]['shape']
input_data = np.array(np.random.random_sample(input_shape), dtype=np.float32)
interpreter.set_tensor(input_index, input_data)
interpreter.invoke()
predictions = interpreter.get_tensor(output_index)
print(predictions)
运行结果
[[[4.42541981e+00 3.49107075e+00 8.37774658e+00 ... 9.10774746e-04
9.90639091e-04 3.53650772e-03]
[1.14531517e+01 3.92715073e+00 2.21152916e+01 ... 1.22958154e-03
1.04030559e-03 3.63455503e-03]
[1.81538811e+01 3.98713017e+00 2.72789650e+01 ... 1.17869792e-03
1.17305492e-03 5.34545118e-03]
...
[5.60652466e+02 5.99311646e+02 1.53121307e+02 ... 1.06547019e-02
1.21085590e-03 1.59583776e-03]
[5.88046204e+02 6.02140503e+02 1.11432640e+02 ... 1.27565460e-02
1.32254686e-03 1.94547337e-03]
[6.16697510e+02 6.09631348e+02 1.19094765e+02 ... 1.50865661e-02
1.55704899e-03 2.10566423e-03]]]
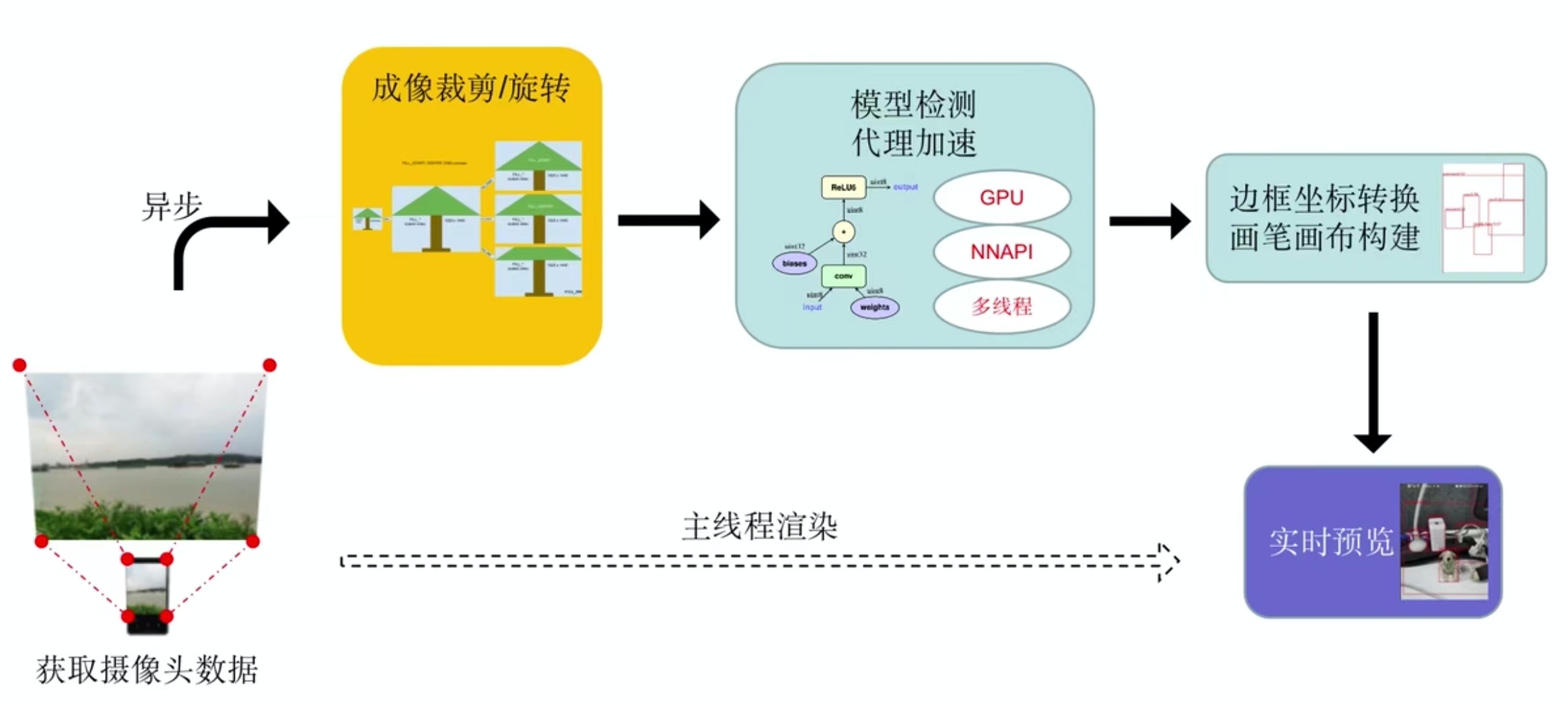
安卓部署(以摄像头检测为例)
![]()
上图是tflite安卓部署的一整个流程。第一步使用安卓自带的cameraX去读取手机摄像头的图片数据。然后对这些图片数据成像的裁剪和旋转,处理成能够满足模型输入数据的形状。然后调用模型对数据进行处理,其中会采用tflite代理的各种加速方法——GPU、NNAPI、多线程去加快模型检测的深度。最后就是拿到检测结果的坐标进行转换,转换成摄像头拍摄到的图片原图大小的目标边框。利用安卓画笔画布将这些目标边框给画出来,再和拍摄到的图片进行合并,就能够得到实时预览的效果。
我们来看一下安卓Gradle的比较重要的依赖
// 核心api库,管理模型加载和运行
implementation 'org.tensorflow:tensorflow-lite:2.8.0'
// gpu代理库,如果当前gpu不支持,则不必引入
implementation 'org.tensorflow:tensorflow-lite-gpu:2.8.0'
// 核心库之外的支持库,包含一些常用的数据处理方法
implementation 'org.tensorflow:tensorflow-lite-support:0.3.1'
// 模型元数据管理相关的api库
implementation 'org.tensorflow:tensorflow-lite-metadata:0.3.1'
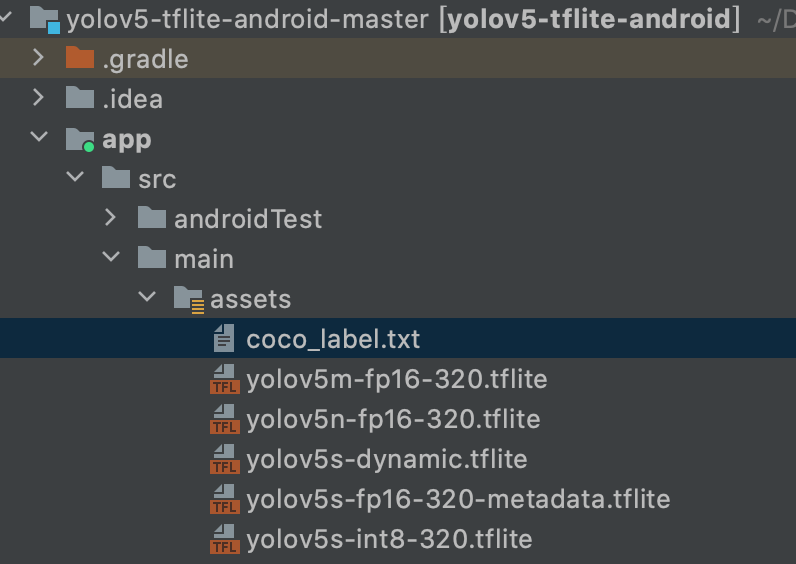
首先我们需要将Python生成的tflite模型放到安卓项目中
![]()
这个coco_label.txt是目标标签
person
bicycle
car
motorbike
aeroplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
handbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
sofa
potted plant
bed
dining table
toilet
tvmonitor
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
book
clock
vase
scissors
teddy bear
hair drier
toothbrush
现在我们来看一下跟YOLOV5模型有关的Java代码,先看一下该类的属性
public class Yolov5TFLiteDetector {
// 模型输入图片尺寸大小
private final Size INPNUT_SIZE = new Size(320, 320);
// 输出尺寸大小
private final int[] OUTPUT_SIZE = new int[]{1, 6300, 85};
// 是否是全整型量化
private Boolean IS_INT8 = false;
// 目标检测阈值
private final float DETECT_THRESHOLD = 0.25f;
// 交并比阈值
private final float IOU_THRESHOLD = 0.45f;
// 分类阈值
private final float IOU_CLASS_DUPLICATED_THRESHOLD = 0.7f;
private final String MODEL_YOLOV5S = "yolov5s-fp16-320-metadata.tflite";
// private final String MODEL_YOLOV5S = "yolov5s-dynamic.tflite";
private final String MODEL_YOLOV5N = "yolov5n-fp16-320.tflite";
private final String MODEL_YOLOV5M = "yolov5m-fp16-320.tflite";
private final String MODEL_YOLOV5S_INT8 = "yolov5s-int8-320.tflite";
private final String LABEL_FILE = "coco_label.txt";
// 全整型量化所需要的参数
MetadataExtractor.QuantizationParams input5SINT8QuantParams = new MetadataExtractor.QuantizationParams(0.003921568859368563f, 0);
MetadataExtractor.QuantizationParams output5SINT8QuantParams = new MetadataExtractor.QuantizationParams(0.006305381190031767f, 5);
private String MODEL_FILE;
// tflite模型解析器
private Interpreter tflite;
// 标签列表
private List<String> associatedAxisLabels;
// 模型解析器参数
Interpreter.Options options = new Interpreter.Options();
现在我们来看一下模型的加载
/**
* 初始化模型, 可以通过 addNNApiDelegate(), addGPUDelegate()提前加载相应代理
*
* @param activity
*/
public void initialModel(Context activity) {
// Initialise the model
try {
// 加载模型
ByteBuffer tfliteModel = FileUtil.loadMappedFile(activity, MODEL_FILE);
// 将模型放入内存中
tflite = new Interpreter(tfliteModel, options);
Log.i("tfliteSupport", "Success reading model: " + MODEL_FILE);
// 加载标签
associatedAxisLabels = FileUtil.loadLabels(activity, LABEL_FILE);
Log.i("tfliteSupport", "Success reading label: " + LABEL_FILE);
} catch (IOException e) {
Log.e("tfliteSupport", "Error reading model or label: ", e);
Toast.makeText(activity, "load model error: " + e.getMessage(), Toast.LENGTH_LONG).show();
}
}
FileUtil.loadMappedFile会自动从assets目录下去加载模型。加载模型之后我们需要对数据进行处理。
/**
* 检测步骤
*
* @param bitmap
* @return
*/
public ArrayList<Recognition> detect(Bitmap bitmap) {
// yolov5s-tflite的输入是:[1, 320, 320,3], 摄像头每一帧图片需要resize,再归一化
TensorImage yolov5sTfliteInput;
// 图形处理器
ImageProcessor imageProcessor;
// 如果是全整型量化模型,需要加上input5SINT8QuantParams的两个参数
if(IS_INT8) {
imageProcessor =
new ImageProcessor.Builder()
.add(new ResizeOp(INPNUT_SIZE.getHeight(), INPNUT_SIZE.getWidth(), ResizeOp.ResizeMethod.BILINEAR))
.add(new NormalizeOp(0, 255))
.add(new QuantizeOp(input5SINT8QuantParams.getZeroPoint(), input5SINT8QuantParams.getScale()))
.add(new CastOp(DataType.UINT8))
.build();
yolov5sTfliteInput = new TensorImage(DataType.UINT8);
} else { // 否则不需要
imageProcessor =
new ImageProcessor.Builder()
.add(new ResizeOp(INPNUT_SIZE.getHeight(), INPNUT_SIZE.getWidth(), ResizeOp.ResizeMethod.BILINEAR))
.add(new NormalizeOp(0, 255))
.build();
yolov5sTfliteInput = new TensorImage(DataType.FLOAT32);
}
// 导入图像
yolov5sTfliteInput.load(bitmap);
// 对图像进行处理
yolov5sTfliteInput = imageProcessor.process(yolov5sTfliteInput);
// yolov5s-tflite的输出是:[1, 6300, 85], 可以从v5的GitHub release处找到相关tflite模型, 输出是[0,1], 处理到320.
TensorBuffer probabilityBuffer;
// 如果是全整型量化模型,输出数据格式为int8
if(IS_INT8){
probabilityBuffer = TensorBuffer.createFixedSize(OUTPUT_SIZE, DataType.UINT8);
}else{ // 否则为float32
probabilityBuffer = TensorBuffer.createFixedSize(OUTPUT_SIZE, DataType.FLOAT32);
}
// 推理计算
if (null != tflite) {
// 这里tflite默认会加一个batch=1的纬度
tflite.run(yolov5sTfliteInput.getBuffer(), probabilityBuffer.getBuffer());
}
// 这里输出反量化,需要是模型tflite.run之后执行.
if(IS_INT8){
TensorProcessor tensorProcessor = new TensorProcessor.Builder()
.add(new DequantizeOp(output5SINT8QuantParams.getZeroPoint(), output5SINT8QuantParams.getScale()))
.build();
probabilityBuffer = tensorProcessor.process(probabilityBuffer);
}
// 输出数据被平铺了出来,即flatten操作
float[] recognitionArray = probabilityBuffer.getFloatArray();
// 这里将flatten的数组重新解析(xywh,obj,classes).
ArrayList<Recognition> allRecognitions = new ArrayList<>();
for (int i = 0; i < OUTPUT_SIZE[1]; i++) {
int gridStride = i * OUTPUT_SIZE[2];
// 由于yolov5作者在导出tflite的时候对输出除以了image size, 所以这里需要乘回去
float x = recognitionArray[0 + gridStride] * INPNUT_SIZE.getWidth();
float y = recognitionArray[1 + gridStride] * INPNUT_SIZE.getHeight();
float w = recognitionArray[2 + gridStride] * INPNUT_SIZE.getWidth();
float h = recognitionArray[3 + gridStride] * INPNUT_SIZE.getHeight();
// 左上角坐标
int xmin = (int) Math.max(0, x - w / 2.);
int ymin = (int) Math.max(0, y - h / 2.);
// 右下角坐标
int xmax = (int) Math.min(INPNUT_SIZE.getWidth(), x + w / 2.);
int ymax = (int) Math.min(INPNUT_SIZE.getHeight(), y + h / 2.);
// 目标类别概率
float confidence = recognitionArray[4 + gridStride];
float[] classScores = Arrays.copyOfRange(recognitionArray, 5 + gridStride, 85 + gridStride);
// if(i % 1000 == 0){
// Log.i("tfliteSupport","x,y,w,h,conf:"+x+","+y+","+w+","+h+","+confidence);
// }
int labelId = 0;
float maxLabelScores = 0.f;
for (int j = 0; j < classScores.length; j++) {
if (classScores[j] > maxLabelScores) {
maxLabelScores = classScores[j];
labelId = j;
}
}
Recognition r = new Recognition(
labelId,
"",
maxLabelScores,
confidence,
new RectF(xmin, ymin, xmax, ymax));
allRecognitions.add(
r);
}
// Log.i("tfliteSupport", "recognize data size: "+allRecognitions.size());
// 非极大抑制输出
ArrayList<Recognition> nmsRecognitions = nms(allRecognitions);
// 第二次非极大抑制, 过滤那些同个目标识别到2个以上目标边框为不同类别的
ArrayList<Recognition> nmsFilterBoxDuplicationRecognitions = nmsAllClass(nmsRecognitions);
// 更新label信息
for(Recognition recognition : nmsFilterBoxDuplicationRecognitions){
int labelId = recognition.getLabelId();
String labelName = associatedAxisLabels.get(labelId);
recognition.setLabelName(labelName);
}
return nmsFilterBoxDuplicationRecognitions;
}
这里需要注意的是,tflite.run(yolov5sTfliteInput.getBuffer(), probabilityBuffer.getBuffer());是针对YOLOV5的输入输出,对于其他模型,上面的代码并不适用,比如说我们的模型是一个Mask-RCNN这种既有目标检测,又有图像分割的网络。
// 加载模型和标签文件
TensorImage splitTfliteInput;
// 图形处理器
ImageProcessor imageProcessor;
// 如果是全整型量化模型,需要加上input5SINT8QuantParams的两个参数
if(IS_INT8) {
imageProcessor =
new ImageProcessor.Builder()
.add(new ResizeOp(INPNUT_SIZE.getHeight(), INPNUT_SIZE.getWidth(), ResizeOp.ResizeMethod.BILINEAR))
.add(new NormalizeOp(0, 255))
.add(new QuantizeOp(input5SINT8QuantParams.getZeroPoint(), input5SINT8QuantParams.getScale()))
.add(new CastOp(DataType.UINT8))
.build();
splitTfliteInput = new TensorImage(DataType.UINT8);
} else { // 否则不需要
imageProcessor =
new ImageProcessor.Builder()
.add(new ResizeOp(INPNUT_SIZE.getHeight(), INPNUT_SIZE.getWidth(), ResizeOp.ResizeMethod.BILINEAR))
.add(new NormalizeOp(0, 255))
.build();
splitTfliteInput = new TensorImage(DataType.FLOAT32);
}
// 导入图像
splitTfliteInput.load(bitmap1);
// 对图像进行处理
splitTfliteInput = imageProcessor.process(splitTfliteInput);
// 假设输入图像数据,mask数据,数据已经处理到对应的input size,最后输入处理成object[]格式
TensorImage imageInput = new TensorImage(DataType.FLOAT32);
imageInput.load(bitmap1);
TensorImage maskInput = new TensorImage(DataType.FLOAT32);
maskInput.load(bitmap2);
Object[] inputArray = {imageInput.getBuffer(),maskInput.getBuffer()};
// 假设输出类别标签数据,边框预测数据,mask分割数据,最后被处理成Map<>格式
TensorBuffer classesOutput = TensorBuffer.createFixedSize(CLASS_SIZE,DataType.FLOAT32);
TensorBuffer locationsOutput = TensorBuffer.createFixedSize(LOCATIONS_SIZE,DataType.FLOAT32);
TensorBuffer maskOutput = TensorBuffer.createFixedSize(MASK_SIZE,DataType.FLOAT32);
Map<Integer,Object> outputMap = new HashMap<>();
outputMap.put(0,classesOutput.getBuffer());
outputMap.put(1,locationsOutput.getBuffer());
outputMap.put(2,maskOutput.getBuffer());
// 执行推理,入口变了
tflite.runForMultipleInputsOutputs(inputArray,outputMap);
// 输出数据被平铺了出来,同样要一个一个解析
float[] classesOutArray = classesOutput.getFloatArray();
float[] locationsOutArray = locationsOutput.getFloatArray();
float[] maskOutputArray = maskOutput.getFloatArray();
我们可以看到在模型加载的时候有这么一行代码tflite = new Interpreter(tfliteModel, options);这里有一个options,它是模型解析器的参数,我们来看看它有哪些参数
/**
* 添加NNapi代理
*/
public void addNNApiDelegate() {
NnApiDelegate nnApiDelegate = null;
// Initialize interpreter with NNAPI delegate for Android Pie or above
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.P) {
nnApiDelegate = new NnApiDelegate();
options.addDelegate(nnApiDelegate);
Log.i("tfliteSupport", "using nnapi delegate.");
}
}
/**
* 添加GPU代理
*/
public void addGPUDelegate() {
CompatibilityList compatibilityList = new CompatibilityList();
if(compatibilityList.isDelegateSupportedOnThisDevice()){
GpuDelegate.Options delegateOptions = compatibilityList.getBestOptionsForThisDevice();
GpuDelegate gpuDelegate = new GpuDelegate(delegateOptions);
options.addDelegate(gpuDelegate);
Log.i("tfliteSupport", "using gpu delegate.");
} else {
addThread(4);
}
}
/**
* 添加线程数
* @param thread
*/
public void addThread(int thread) {
options.setNumThreads(thread);
}
通过上面的代码我们可以看到,它就是用于模型加速的GPU、NNAPI、多线程。
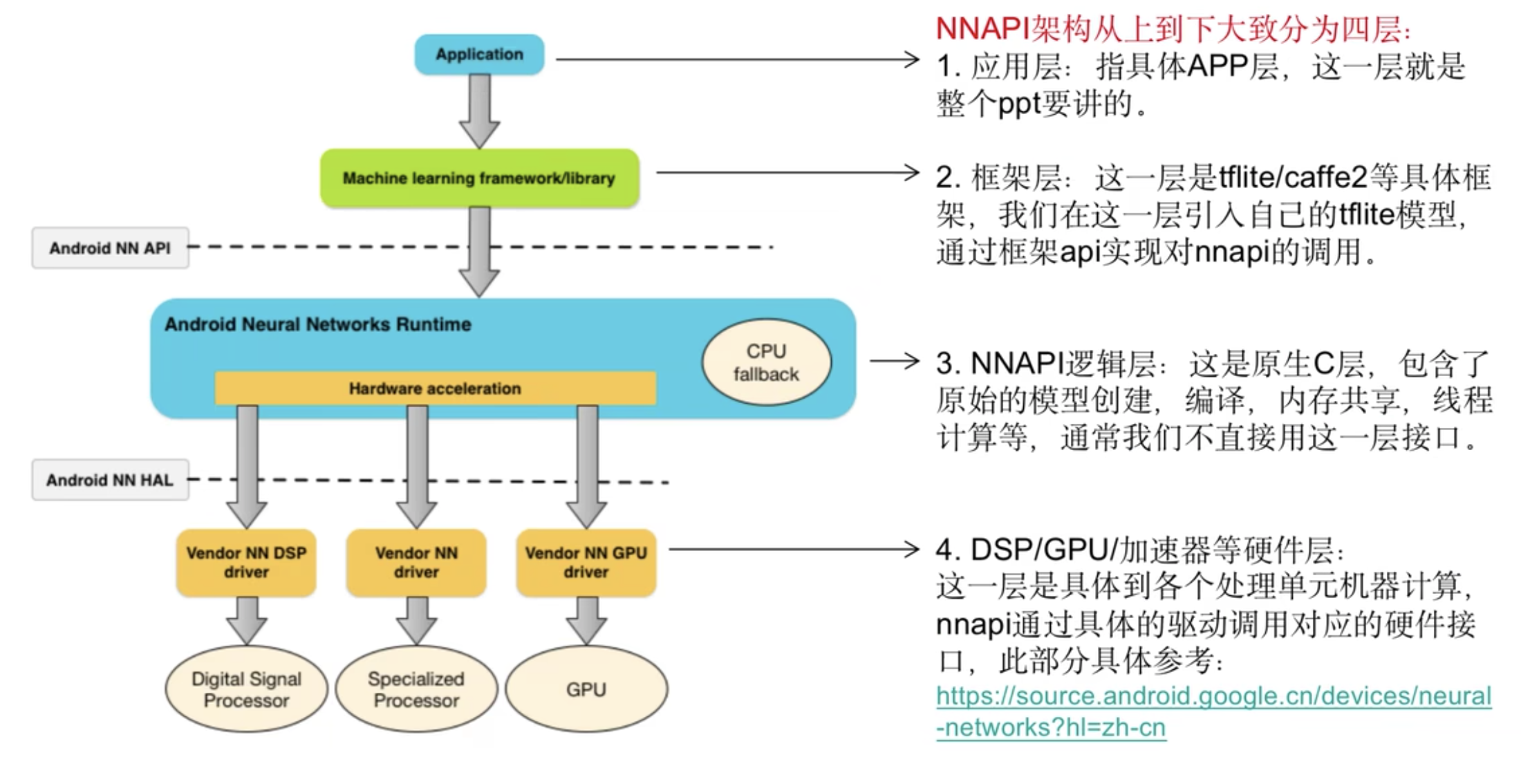
NNAPI代理、gpu代理、多线程加速
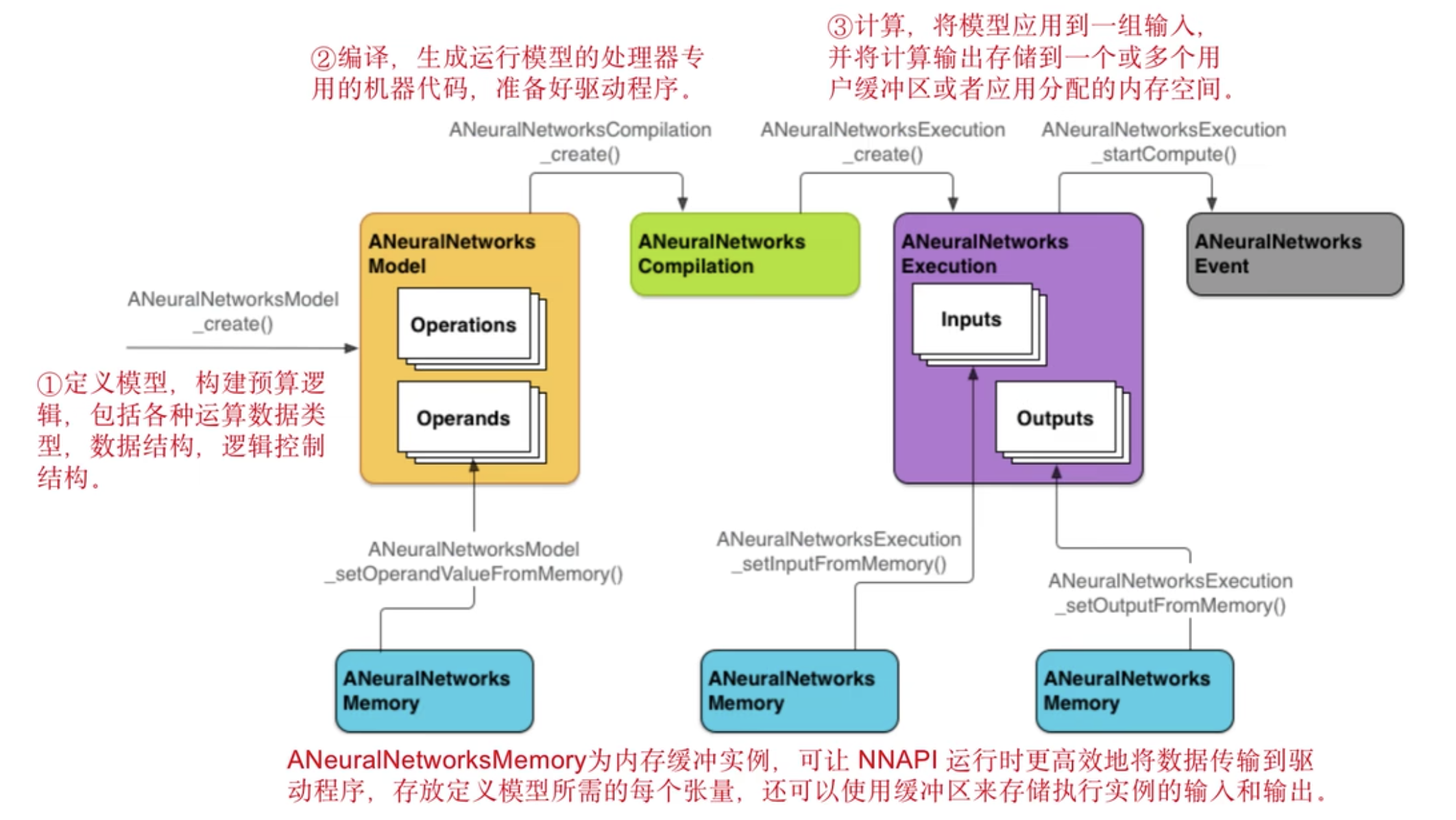
NNAPI:Android Neural Networks API(NNAPI)是一个Android C API,专为在Android设备上运行密集型运算而设计的,NNAPI旨在为更高层级的机器学习框架(如TensorFlow Lite和Caffe2)提供一个基本功能层,用来建立和训练神经网络。
![]()
其实如果我们不使用框架层,而是直接调用NNAPI逻辑层也是可以的
![]()
我们可以直接调用NNAPI的C接口去定义自己的模型,然后再去部署。
我们可以在模型初始化的地方加上NNAPI或者GPU的代理来提前加载加速模型
/**
* 初始化模型, 可以通过 addNNApiDelegate(), addGPUDelegate()提前加载相应代理
*
* @param activity
*/
public void initialModel(Context activity) {
// Initialise the model
addNNApiDelegate();
try {
// 加载模型
ByteBuffer tfliteModel = FileUtil.loadMappedFile(activity, MODEL_FILE);
// 将模型放入内存中
tflite = new Interpreter(tfliteModel, options);
Log.i("tfliteSupport", "Success reading model: " + MODEL_FILE);
// 加载标签
associatedAxisLabels = FileUtil.loadLabels(activity, LABEL_FILE);
Log.i("tfliteSupport", "Success reading label: " + LABEL_FILE);
} catch (IOException e) {
Log.e("tfliteSupport", "Error reading model or label: ", e);
Toast.makeText(activity, "load model error: " + e.getMessage(), Toast.LENGTH_LONG).show();
}
}
这里我们需要注意的是,gpu代理和nnapi代理会有资源竞争问题,同时使用时并不会带来2倍的提升,建议只用一个。gpu代理与多线程设置一个即可。
GPU代理与NNAPI代理的异同点:
从代理角度看:
- 相同之处在于,无论是gpu代理,nnapi代理,Hexagon代理,或者是coreML代理,都是tfliite对一些模型计算方法的再封装,目的就是为了让模型或者模型中的部分节点能在GPU/TPU/DSP等加速硬件上运行。
- 不同之处在于,gpu代理,Hexagon代理属于tflite中对硬件驱动的封装,nnapi代理和coreML属于是在Android和ios系统上对自身库的封装,而自身库里已包含了对各种加速器硬件的支持。
![]()
从支持量化类型上看:gpu代理支持所有量化类型,nnapi不支持半浮点(float16)量化类型。
tflite task和support的区别
tflite support提供了任意模型自定义输入输出,计算,数据处理方法。
tflite task是tflite封装了一些具体任务的库方法,需要提供满足输入输出要求的模型。
tflite里面大概提供了7种具体任务封装,分别如下
1、图像分类,目标检测,图像分割:
implementation 'org.tensorflow:tensorflow-lite-task-vision:0.3.1'
2、文本分类,基于bert的文本分类,基于bert的智能问答
implementation 'org.tensorflow:tensorflow-lite-task-text:0.3.1'
3、音频分类
implementation 'org.tensorflow:tensorflow-lite-task-audio:0.3.1'
以上的tflite task库提供了对特定模型的封装,只需要提供对应的模型输入输出即可以,比如
// 加载模型
ImageClassifier.ImageClassifierOptions options = ImageClassifier.ImageClassifierOptions.builder()
.setMaxResults(1).build();
ImageClassifier imageClassifier = ImageClassifier.createFromFileAndOptions(activity, MODEL_FILE, options);
// 推理计算
List<Classifications> results = imageClassifier.classify(image);
只需要提供模型满足如下即可:
- 输入:[batch=1,h,w,channel=3],可为float32/uint8,float32格式需归一化,channel为rgb格式。
- 输出:[1,N]或者[1,1,1,N],可为float32/uint8,N为类别数。
安卓程序调用模型
package com.example.yolov5tfliteandroid.analysis;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Matrix;
import android.graphics.Paint;
import android.graphics.RectF;
import android.util.Log;
import android.util.Size;
import android.widget.ImageView;
import android.widget.TextView;
import androidx.annotation.NonNull;
import androidx.camera.core.ImageAnalysis;
import androidx.camera.core.ImageProxy;
import androidx.camera.view.PreviewView;
import com.example.yolov5tfliteandroid.MainActivity;
import com.example.yolov5tfliteandroid.detector.Yolov5TFLiteDetector;
import com.example.yolov5tfliteandroid.utils.ImageProcess;
import com.example.yolov5tfliteandroid.utils.Recognition;
import java.util.ArrayList;
import io.reactivex.rxjava3.android.schedulers.AndroidSchedulers;
import io.reactivex.rxjava3.core.Observable;
import io.reactivex.rxjava3.core.ObservableEmitter;
import io.reactivex.rxjava3.core.ObservableOnSubscribe;
import io.reactivex.rxjava3.core.Scheduler;
import io.reactivex.rxjava3.schedulers.Schedulers;
public class FullImageAnalyse implements ImageAnalysis.Analyzer {
public static class Result{
public Result(long costTime, Bitmap bitmap) {
this.costTime = costTime;
this.bitmap = bitmap;
}
long costTime;
Bitmap bitmap;
}
// 画笔画布
ImageView boxLabelCanvas;
PreviewView previewView;
int rotation;
private TextView inferenceTimeTextView;
private TextView frameSizeTextView;
ImageProcess imageProcess;
private Yolov5TFLiteDetector yolov5TFLiteDetector;
public FullImageAnalyse(Context context,
PreviewView previewView,
ImageView boxLabelCanvas,
int rotation,
TextView inferenceTimeTextView,
TextView frameSizeTextView,
Yolov5TFLiteDetector yolov5TFLiteDetector) {
this.previewView = previewView;
this.boxLabelCanvas = boxLabelCanvas;
this.rotation = rotation;
this.inferenceTimeTextView = inferenceTimeTextView;
this.frameSizeTextView = frameSizeTextView;
this.imageProcess = new ImageProcess();
this.yolov5TFLiteDetector = yolov5TFLiteDetector;
}
/**
* 图像处理
* @param image 每一帧的图像
*/
@Override
public void analyze(@NonNull ImageProxy image) {
int previewHeight = previewView.getHeight();
int previewWidth = previewView.getWidth();
// 这里Observable将image analyse的逻辑放到子线程计算, 渲染UI的时候再拿回来对应的数据, 避免前端UI卡顿
Observable.create( (ObservableEmitter<Result> emitter) -> {
long start = System.currentTimeMillis();
// 获取画面数据,宽跟高
byte[][] yuvBytes = new byte[3][];
ImageProxy.PlaneProxy[] planes = image.getPlanes();
int imageHeight = image.getHeight();
int imagewWidth = image.getWidth();
// 转成字节的格式
imageProcess.fillBytes(planes, yuvBytes);
int yRowStride = planes[0].getRowStride();
final int uvRowStride = planes[1].getRowStride();
final int uvPixelStride = planes[1].getPixelStride();
int[] rgbBytes = new int[imageHeight * imagewWidth];
// 我们拿到的是YUV格式的图像,需要转成RGB格式的字节图像
imageProcess.YUV420ToARGB8888(
yuvBytes[0],
yuvBytes[1],
yuvBytes[2],
imagewWidth,
imageHeight,
yRowStride,
uvRowStride,
uvPixelStride,
rgbBytes);
// 将RGB字节图处理成原图bitmap
Bitmap imageBitmap = Bitmap.createBitmap(imagewWidth, imageHeight, Bitmap.Config.ARGB_8888);
imageBitmap.setPixels(rgbBytes, 0, imagewWidth, 0, 0, imagewWidth, imageHeight);
// 图片适应屏幕fill_start格式的bitmap
double scale = Math.max(
previewHeight / (double) (rotation % 180 == 0 ? imagewWidth : imageHeight),
previewWidth / (double) (rotation % 180 == 0 ? imageHeight : imagewWidth)
);
Matrix fullScreenTransform = imageProcess.getTransformationMatrix(
imagewWidth, imageHeight,
(int) (scale * imageHeight), (int) (scale * imagewWidth),
rotation % 180 == 0 ? 90 : 0, false
);
// 适应preview的全尺寸bitmap
Bitmap fullImageBitmap = Bitmap.createBitmap(imageBitmap, 0, 0, imagewWidth, imageHeight, fullScreenTransform, false);
// 裁剪出跟preview在屏幕上一样大小的bitmap
Bitmap cropImageBitmap = Bitmap.createBitmap(fullImageBitmap, 0, 0, previewWidth, previewHeight);
// 模型输入的bitmap
Matrix previewToModelTransform =
imageProcess.getTransformationMatrix(
cropImageBitmap.getWidth(), cropImageBitmap.getHeight(),
yolov5TFLiteDetector.getInputSize().getWidth(),
yolov5TFLiteDetector.getInputSize().getHeight(),
0, false);
Bitmap modelInputBitmap = Bitmap.createBitmap(cropImageBitmap, 0, 0,
cropImageBitmap.getWidth(), cropImageBitmap.getHeight(),
previewToModelTransform, false);
Matrix modelToPreviewTransform = new Matrix();
previewToModelTransform.invert(modelToPreviewTransform);
// 将旋转缩放好的图片放入模型中检测,获取检测结果
ArrayList<Recognition> recognitions = yolov5TFLiteDetector.detect(modelInputBitmap);
// ArrayList<Recognition> recognitions = yolov5TFLiteDetector.detect(imageBitmap);
Bitmap emptyCropSizeBitmap = Bitmap.createBitmap(previewWidth, previewHeight, Bitmap.Config.ARGB_8888);
// 创建画笔画布
Canvas cropCanvas = new Canvas(emptyCropSizeBitmap);
// Paint white = new Paint();
// white.setColor(Color.WHITE);
// white.setStyle(Paint.Style.FILL);
// cropCanvas.drawRect(new RectF(0,0,previewWidth, previewHeight), white);
// 边框画笔
Paint boxPaint = new Paint();
boxPaint.setStrokeWidth(5);
boxPaint.setStyle(Paint.Style.STROKE);
boxPaint.setColor(Color.RED);
// 字体画笔
Paint textPain = new Paint();
textPain.setTextSize(50);
textPain.setColor(Color.RED);
textPain.setStyle(Paint.Style.FILL);
// 将每一个目标边框都画到画布上去
for (Recognition res : recognitions) {
RectF location = res.getLocation();
String label = res.getLabelName();
float confidence = res.getConfidence();
modelToPreviewTransform.mapRect(location);
cropCanvas.drawRect(location, boxPaint);
cropCanvas.drawText(label + ":" + String.format("%.2f", confidence), location.left, location.top, textPain);
}
long end = System.currentTimeMillis();
long costTime = (end - start);
image.close();
// 在子线程中将结果传递给主线程
emitter.onNext(new Result(costTime, emptyCropSizeBitmap));
// emitter.onNext(new Result(costTime, imageBitmap));
}).subscribeOn(Schedulers.io()) // 这里定义被观察者,也就是上面代码的线程, 如果没定义就是主线程同步, 非异步
// 这里就是回到主线程, 观察者接受到emitter发送的数据进行处理
.observeOn(AndroidSchedulers.mainThread())
// 这里就是回到主线程处理子线程的回调数据.
.subscribe((Result result) -> {
boxLabelCanvas.setImageBitmap(result.bitmap);
frameSizeTextView.setText(previewHeight + "x" + previewWidth);
inferenceTimeTextView.setText(Long.toString(result.costTime) + "ms");
});
}
}
最后就是安卓主界面调用FullImageAnalyse的代码
package com.example.yolov5tfliteandroid;
import androidx.appcompat.app.AppCompatActivity;
import androidx.appcompat.widget.Toolbar;
import androidx.camera.view.PreviewView;
import android.graphics.Color;
import android.os.Bundle;
import android.util.Log;
import android.view.Surface;
import android.view.View;
import android.widget.AdapterView;
import android.widget.CompoundButton;
import android.widget.ImageView;
import android.widget.Spinner;
import android.widget.Switch;
import android.widget.TextView;
import android.widget.Toast;
import androidx.camera.lifecycle.ProcessCameraProvider;
import com.example.yolov5tfliteandroid.analysis.FullImageAnalyse;
import com.example.yolov5tfliteandroid.analysis.FullScreenAnalyse;
import com.example.yolov5tfliteandroid.detector.Yolov5TFLiteDetector;
import com.example.yolov5tfliteandroid.utils.CameraProcess;
import com.google.common.util.concurrent.ListenableFuture;
public class MainActivity extends AppCompatActivity {
private boolean IS_FULL_SCREEN = false;
private PreviewView cameraPreviewMatch;
private PreviewView cameraPreviewWrap;
private ImageView boxLabelCanvas;
private Spinner modelSpinner;
private Switch immersive;
private TextView inferenceTimeTextView;
private TextView frameSizeTextView;
private ListenableFuture<ProcessCameraProvider> cameraProviderFuture;
private Yolov5TFLiteDetector yolov5TFLiteDetector;
private CameraProcess cameraProcess = new CameraProcess();
/**
* 获取屏幕旋转角度,0表示拍照出来的图片是横屏
*
*/
protected int getScreenOrientation() {
switch (getWindowManager().getDefaultDisplay().getRotation()) {
case Surface.ROTATION_270:
return 270;
case Surface.ROTATION_180:
return 180;
case Surface.ROTATION_90:
return 90;
default:
return 0;
}
}
/**
* 加载模型
*
* @param modelName
*/
private void initModel(String modelName) {
// 加载模型
try {
this.yolov5TFLiteDetector = new Yolov5TFLiteDetector();
this.yolov5TFLiteDetector.setModelFile(modelName);
// this.yolov5TFLiteDetector.addNNApiDelegate();
this.yolov5TFLiteDetector.addGPUDelegate();
this.yolov5TFLiteDetector.initialModel(this);
Log.i("model", "Success loading model" + this.yolov5TFLiteDetector.getModelFile());
} catch (Exception e) {
Log.e("image", "load model error: " + e.getMessage() + e.toString());
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 打开app的时候隐藏顶部状态栏
// getWindow().getDecorView().setSystemUiVisibility(View.SYSTEM_UI_FLAG_LAYOUT_STABLE | View.SYSTEM_UI_FLAG_FULLSCREEN | View.SYSTEM_UI_FLAG_LAYOUT_FULLSCREEN);
getWindow().getDecorView().setSystemUiVisibility(View.SYSTEM_UI_FLAG_LAYOUT_STABLE | View.SYSTEM_UI_FLAG_LAYOUT_FULLSCREEN);
getWindow().setStatusBarColor(Color.TRANSPARENT);
// 全屏画面
cameraPreviewMatch = findViewById(R.id.camera_preview_match);
cameraPreviewMatch.setScaleType(PreviewView.ScaleType.FILL_START);
// 全图画面
cameraPreviewWrap = findViewById(R.id.camera_preview_wrap);
// cameraPreviewWrap.setScaleType(PreviewView.ScaleType.FILL_START);
// box/label画面
boxLabelCanvas = findViewById(R.id.box_label_canvas);
// 下拉按钮
modelSpinner = findViewById(R.id.model);
// 沉浸式体验按钮
immersive = findViewById(R.id.immersive);
// 实时更新的一些view
inferenceTimeTextView = findViewById(R.id.inference_time);
frameSizeTextView = findViewById(R.id.frame_size);
cameraProviderFuture = ProcessCameraProvider.getInstance(this);
// 申请摄像头权限
if (!cameraProcess.allPermissionsGranted(this)) {
cameraProcess.requestPermissions(this);
}
// 获取手机摄像头拍照旋转参数
int rotation = getWindowManager().getDefaultDisplay().getRotation();
Log.i("image", "rotation: " + rotation);
cameraProcess.showCameraSupportSize(MainActivity.this);
// 初始化加载yolov5s
initModel("yolov5s");
// 监听模型切换按钮
modelSpinner.setOnItemSelectedListener(new AdapterView.OnItemSelectedListener() {
@Override
public void onItemSelected(AdapterView<?> adapterView, View view, int i, long l) {
String model = (String) adapterView.getItemAtPosition(i);
Toast.makeText(MainActivity.this, "loading model: " + model, Toast.LENGTH_LONG).show();
initModel(model);
if(IS_FULL_SCREEN){
cameraPreviewWrap.removeAllViews();
FullScreenAnalyse fullScreenAnalyse = new FullScreenAnalyse(MainActivity.this,
cameraPreviewMatch,
boxLabelCanvas,
rotation,
inferenceTimeTextView,
frameSizeTextView,
yolov5TFLiteDetector);
cameraProcess.startCamera(MainActivity.this, fullScreenAnalyse, cameraPreviewMatch);
}else{
cameraPreviewMatch.removeAllViews();
FullImageAnalyse fullImageAnalyse = new FullImageAnalyse(
MainActivity.this,
cameraPreviewWrap,
boxLabelCanvas,
rotation,
inferenceTimeTextView,
frameSizeTextView,
yolov5TFLiteDetector);
cameraProcess.startCamera(MainActivity.this, fullImageAnalyse, cameraPreviewWrap);
}
}
@Override
public void onNothingSelected(AdapterView<?> adapterView) {
}
});
// 监听视图变化按钮
immersive.setOnCheckedChangeListener(new CompoundButton.OnCheckedChangeListener() {
@Override
public void onCheckedChanged(CompoundButton compoundButton, boolean b) {
IS_FULL_SCREEN = b;
if (b) {
// 进入全屏模式
cameraPreviewWrap.removeAllViews();
FullScreenAnalyse fullScreenAnalyse = new FullScreenAnalyse(MainActivity.this,
cameraPreviewMatch,
boxLabelCanvas,
rotation,
inferenceTimeTextView,
frameSizeTextView,
yolov5TFLiteDetector);
cameraProcess.startCamera(MainActivity.this, fullScreenAnalyse, cameraPreviewMatch);
} else {
// 进入全图模式
cameraPreviewMatch.removeAllViews();
FullImageAnalyse fullImageAnalyse = new FullImageAnalyse(
MainActivity.this,
cameraPreviewWrap,
boxLabelCanvas,
rotation,
inferenceTimeTextView,
frameSizeTextView,
yolov5TFLiteDetector);
cameraProcess.startCamera(MainActivity.this, fullImageAnalyse, cameraPreviewWrap);
}
}
});
}
}
TensorRT部署
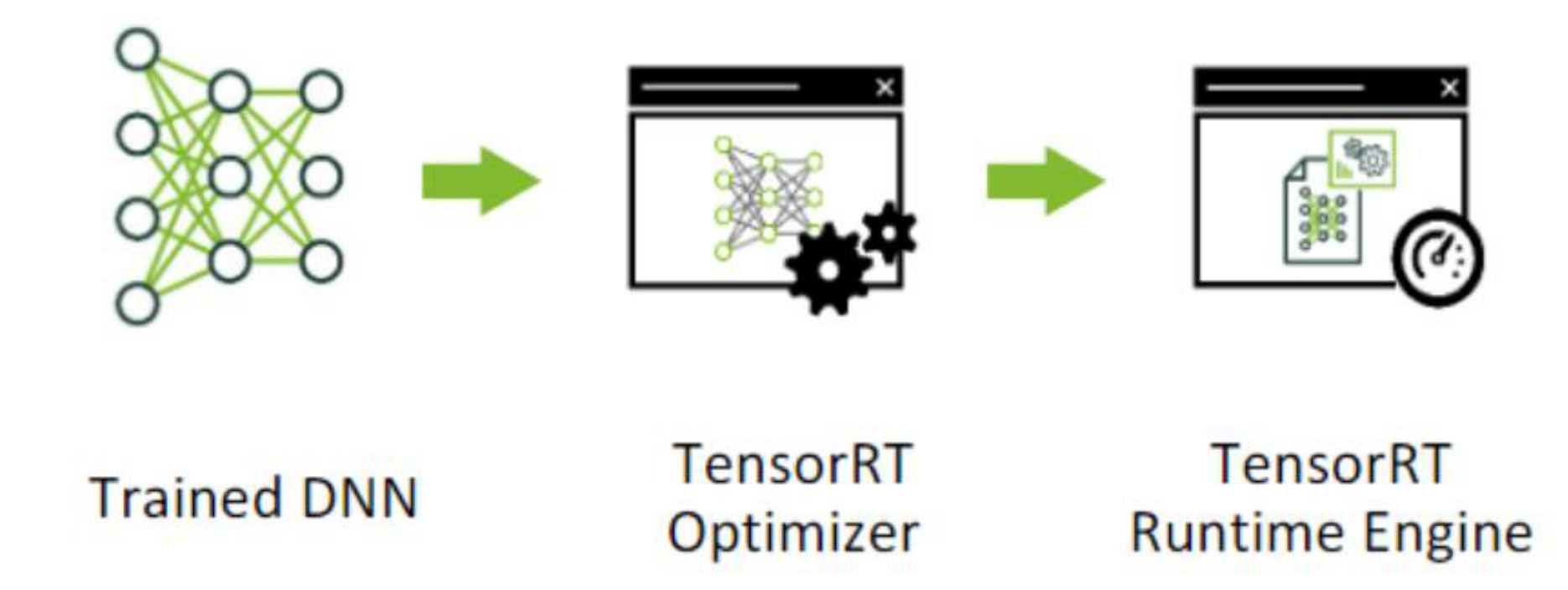
TensorRT是英伟达的高性能深度学习推理的SDK,如果我们部署环境是英伟达的环境,那么TensorRT是不二之选。此SDK包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。
![]()
![]()
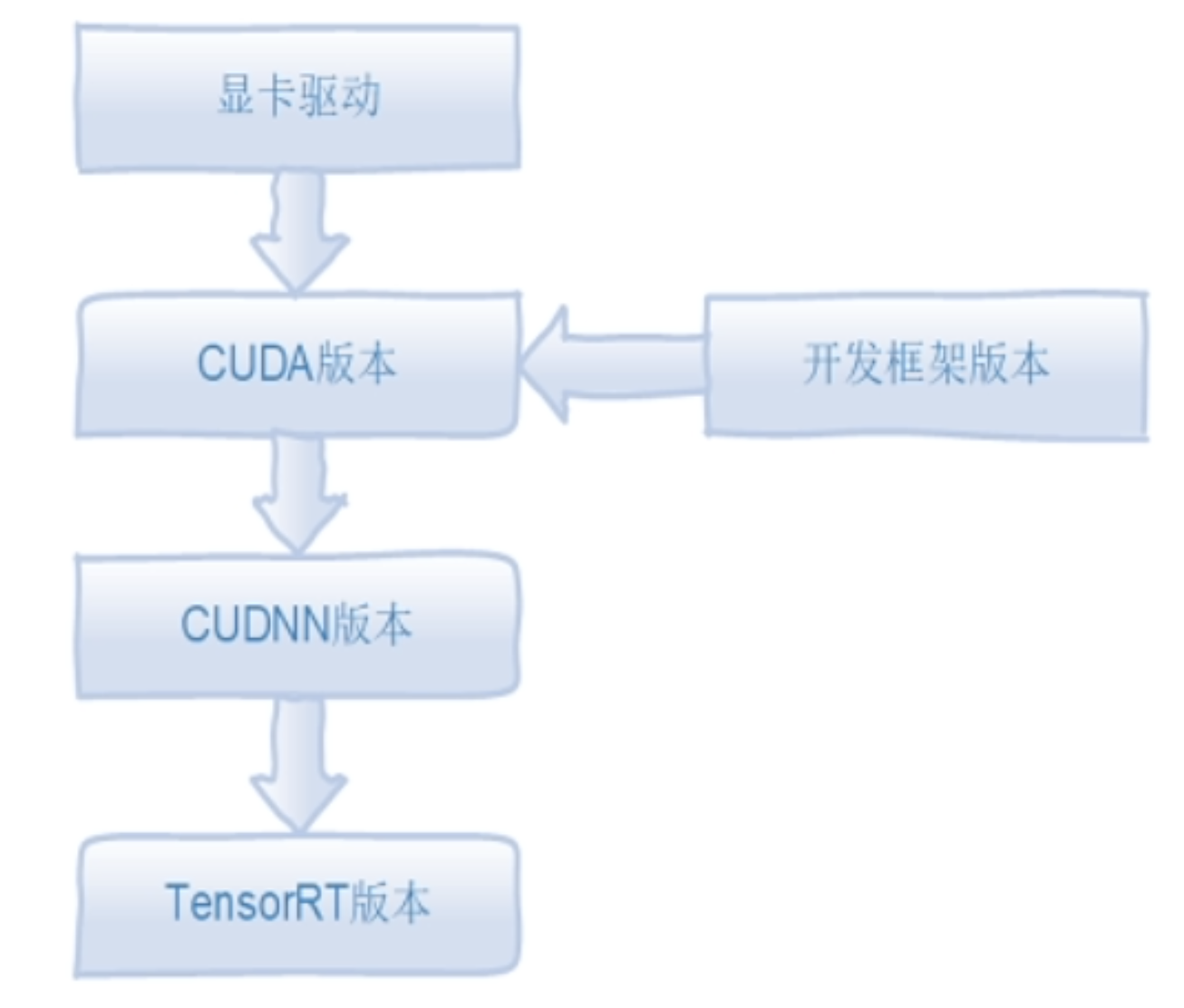
环境安装
![]()
前面的步骤可以参考乌班图安装Pytorch、Tensorflow Cuda环境 。
TensorRT下载地址:https://developer.nvidia.com/nvidia-tensorrt-download
这里需要英伟达的账户登陆。根据自己的GPU cuda版本进行下载。我这里下载的是TensorRT-8.4.1.5.Linux.x86_64-gnu.cuda-11.6.cudnn8.4.tar。
解压缩后,设置环境变量
编辑/etc/profile,添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/user/TensorRT-8.4.1.5/lib
保存后对/etc/profile进行source。
安装Python组件
cd python/
pip install tensorrt-8.4.1.5-cp39-none-linux_x86_64.whl
这里需要说明的是TensorRT基本是使用C++来进行部署的,Python版本只是用来做一些验证使用。
TensorRT测试
cd samples/sampleMNIST
make clean
make
之后退回到TensorRT主目录,再进入bin目录,执行
./sample_mnist
此时程序会选择一张手写数字图片进行识别
[06/22/2022-15:34:07] [I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@.*@@@@@@@@@@
@@@@@@@@@@@@@@@@.=@@@@@@@@@@
@@@@@@@@@@@@+@@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@% #@@.=@@@@@@@@@@
@@@@@@@@@@@+ *@@:-@@@@@@@@@@
@@@@@@@@@@@= *@@= @@@@@@@@@@
@@@@@@@@@@@. #@@= @@@@@@@@@@
@@@@@@@@@@= =++.-@@@@@@@@@@
@@@@@@@@@@ =@@@@@@@@@@
@@@@@@@@@@ :*## =@@@@@@@@@@
@@@@@@@@@@:*@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@% =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@# =@@@@@@@@@@
@@@@@@@@@@@@@@@* *@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@= #@@@@@@@@@@
@@@@@@@@@@@@@@@=.@@@@@@@@@@@
@@@@@@@@@@@@@@@++@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[06/22/2022-15:34:07] [I] Output:
0:
1:
2:
3:
4: **********
5:
6:
7:
8:
9:
我们可以看到程序将该图片识别为4。
TensorRT深度学习开发流程
![]()
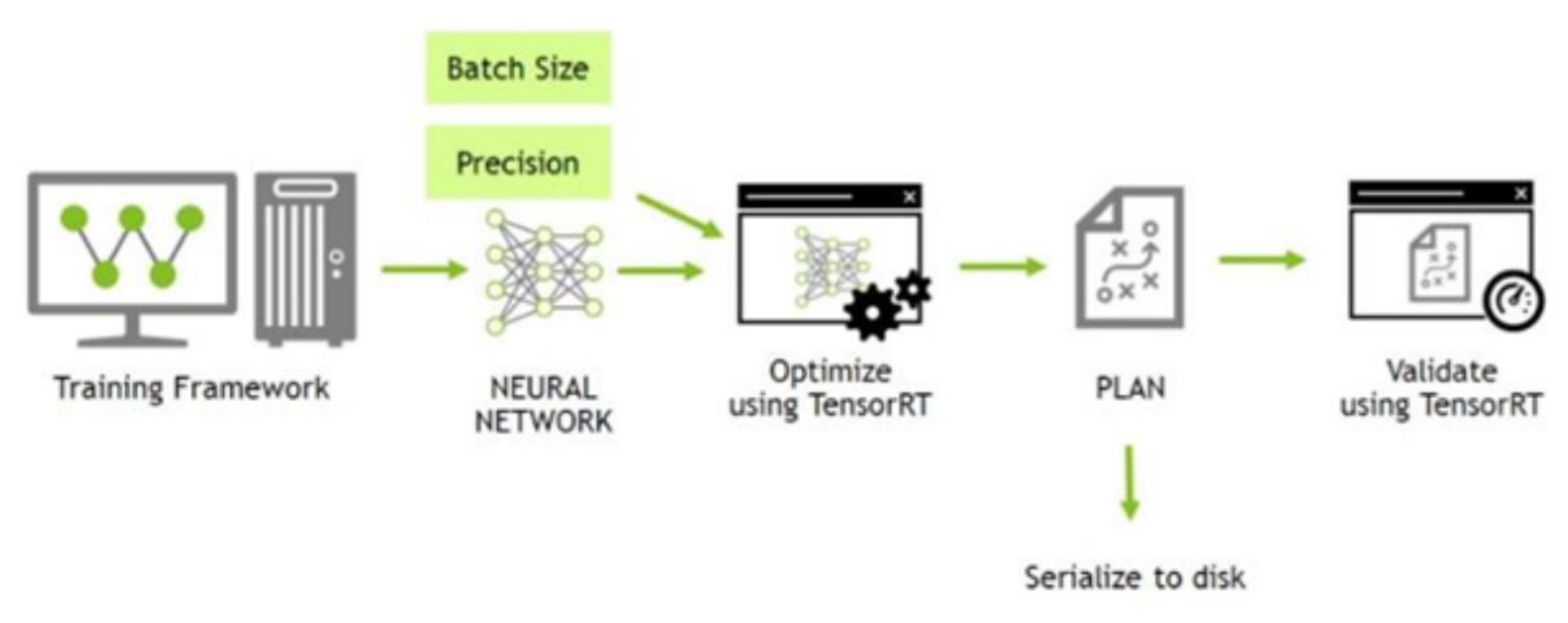
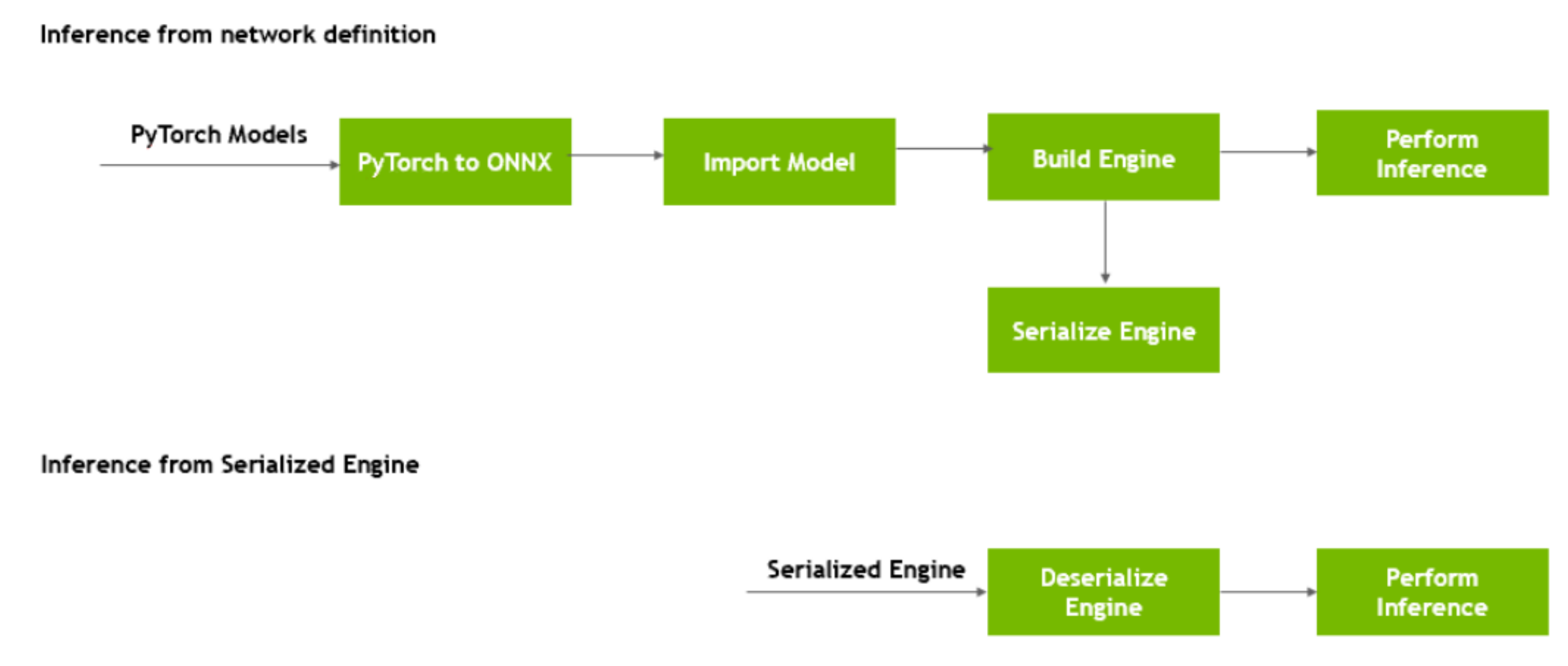
首先会进行深度学习的训练框架的训练,这里我们一般使用Pytorch,得到一个神经网络。然后使用TensorRT来进行优化,可以指定Batch Size和Precision(精确度)。得到一个优化后的推理引擎PLAN,然后序列化到磁盘。在使用的时候再反序列化使用。
![]()
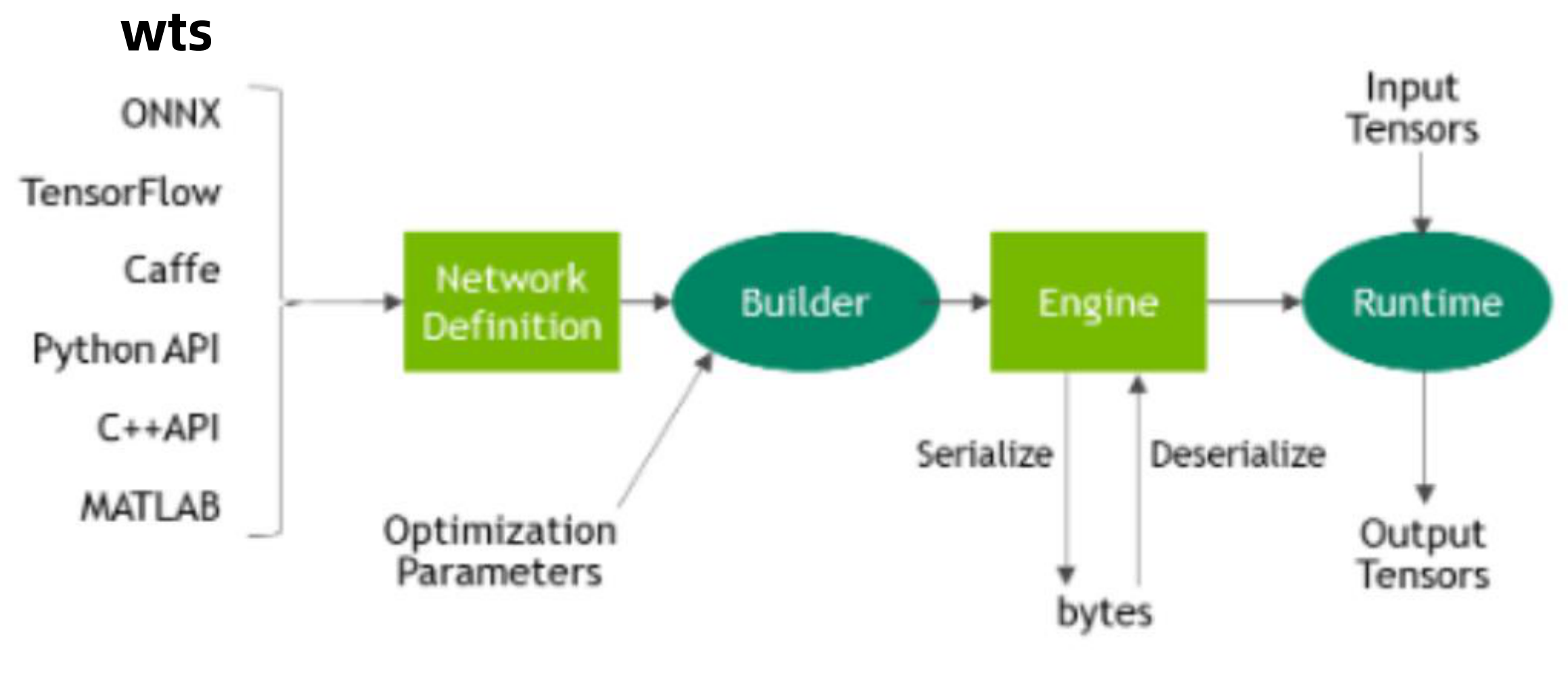
在使用各个框架进行训练后会得到一系列训练后的文件,我们这里主要为Pytorch的ONNX。得到了网络定义,然后使用构建器(Builder)来优化参数(Optimization Parameters),构建器会构建一个推理引擎(Engine),这个引擎可以序列化(保存到硬盘中)也可以反序列化(从硬盘中读取到内存)。真正的使用会有一个运行时(Runtime),输入的tensor经过该运行时就会得到输出的tensor了。
- Builder: TensorRT的模型优化器。构建器将网络定义作为输入,执行与设备无关和针对特定设备的优化,并创建引擎。
- Network definition: TensorRT中的模型表示。网络定义是张量和运算符的图。
- Engine:由TensorRT构建器优化的模型的表示。
- Plan:序列化格式的优化后的推理引擎。典型的应用程序经构建一次引擎,然后将其序列化为计划文件以供以后使用。要初始化推理引擎,应用程序将首先从plan文件中反序列化模型。
- Runtime:TensorRT的组件,可在TensorRT引擎上执行推理。
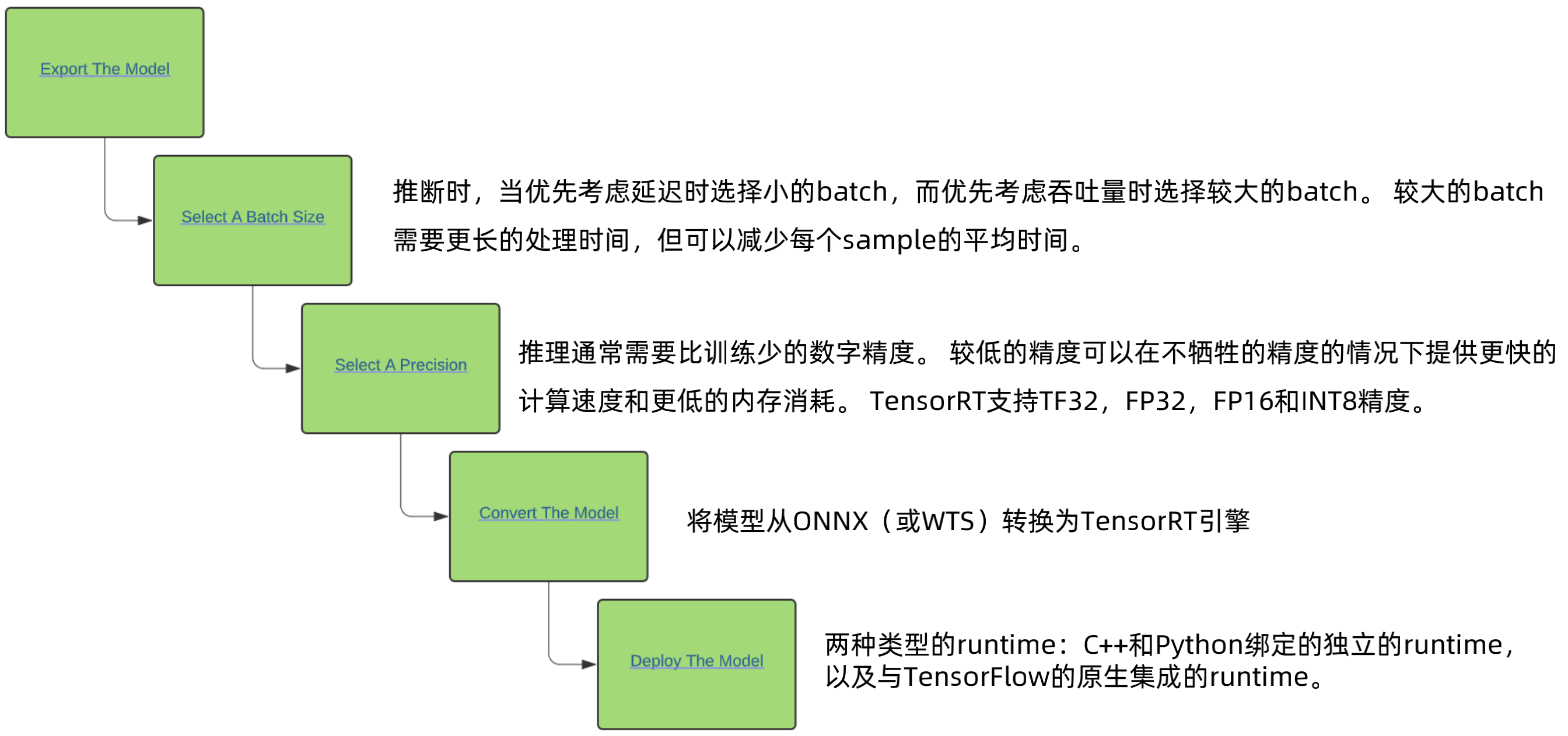
TensorRT的基本工作流程
![]()
第一步是导出模型,比如ONNX。
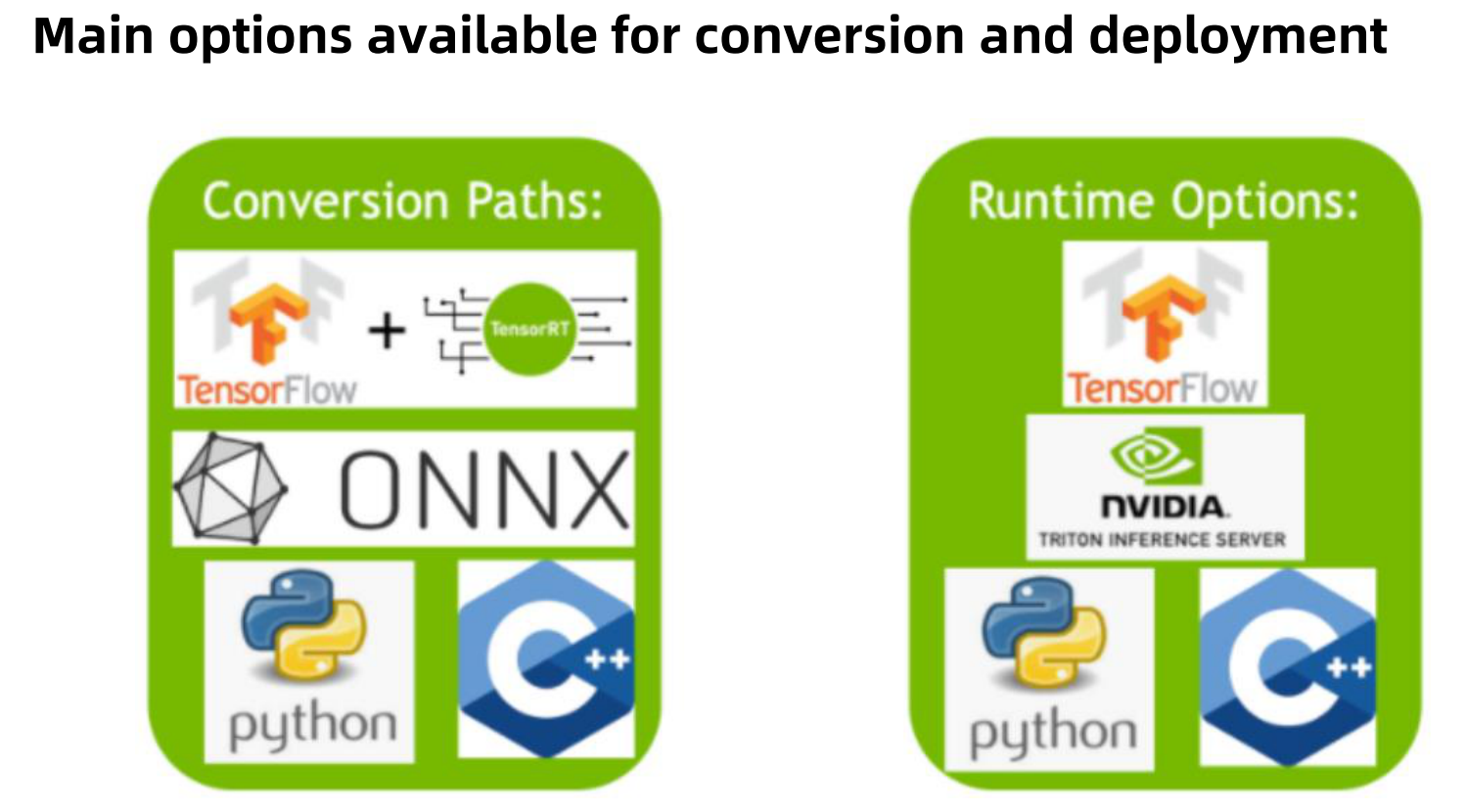
TensorRT生态系统分为两个部分:
- 用户可以遵循的各种路径将其模型转换为优化的TensorRT引擎。
- 部署优化的TensorRT引擎时,各种runtime用户可以使用TensorRT到不同的目标平台。
![]()
使用TensorRT转换模型有三个主要选择:
- 使用TF-TRT(与TensorFlow集成的TensorRT)
- 从ONNX文件自动转换
- 使用TensorRT API手动创建一个网络模型(包括C++)
为了获得最佳性能和可定制性,可以使用TensorRT网络定义API手动构建TensorRT引擎。这涉及仅使用TensorRT操作按目标平台构建与原模型(或近似相同)的网络。创建TensorRT网络后,可从框架中导出模型的权重,然后将其加载到TensorRT网络中。
使用TensorRT部署模型也有三个选择:
- 直接使用TensorFlow进行部署。
- 使用独立的TensorRT runtime API来进行部署。
- 使用英伟达Triton推理服务器来进行部署。
TensorRT的runtimeAPI允许最低的开销和最细粒度的控制,但是TensorRT本身不支持的运算符必须实现为插件(plugin)。
TensorRT库将链接到部署应用程序,部署应用程序在需要推断结果时将调用该库。要初始化推理引擎,应用程序将首先将模型从plan文件中反序列化为推理引擎。
TensorRT通常异步使用,因此,当输入数据到达时,程序将调用一个enqueue函数。
TensorRT如何工作
为了优化推理引擎,TensorRT会采用我们的网络定义,执行包括平台特定的优化,并生成推理引擎。此过程称为build阶段。build阶段可能会花费大量时间,尤其是在嵌入式平台上运行时。因此,典型的应用程序将只构建一次引擎,然后将其序列化为plan文件以供以后使用。
构建阶段对图执行以下优化:
- 消除不使用其输出的层;
- 消除等同于无操作的操作;
- 卷积、偏置和ReLU操作的融合;
- 使用完全相似的参数和相同的源张量(例如GoogleNet v5的初始模块中的1x1卷积)进行的操作聚合(aggregation);
- 通过将层输出定向到正确的最终目的地来合并拼接层;
必要时,builder还可以修改权重的精度。当生成8位整数精度的网络时,它使用称为calibration(校准)的过程来确定中间激活的动态范围,从而确定用于量化的适当缩放因子。此外,build阶段还会在dummy数据上运行各层,以从其kernel目录中选择最快的文件,并在适当的情况下执行权重预格式化和内存优化。
- 根据模型创建TensorRT的网络定义
- 调用TensorRT构建器以从网络创建优化的runtime引擎
- 序列化和反序列化引擎,以便可以在runtime快速重新创建它
- 向引擎提供数据以执行推理
![]()
从上图中我们可以看出,从Pytorch中导出ONNX模型,在TensorRT中导入模型来构建引擎,构建引擎后可以序列化引擎。在使用的时候可以反序列化来进行推理。
TensorRT可以实现自定义层(Custom Layers),用户可以使用C++和Python API的IPluginV2Ext类来实现自定义层,从而扩展TensorRT的功能。自定义层(通常称为插件)由应用程序实现和实例化。
TensorRT INT8量化原理
- 目的:将神经网络32位浮点表示的权重变成8位的整数,并且希望没有显著的准确率的下降。
- 原因:INT8可以带来更高的吞吐率,更少的内存的占用。
- 挑战:INT8比起32位浮点数会有更低的精度,更小的动态范围。
- 解决方案:在量化后的模型权重到INT8并且在用INT8来计算激活的时候,最小化信息到损失。
- 结果:TensorRT所采用的方法,不需要fine tuning(微调)和重新训练。
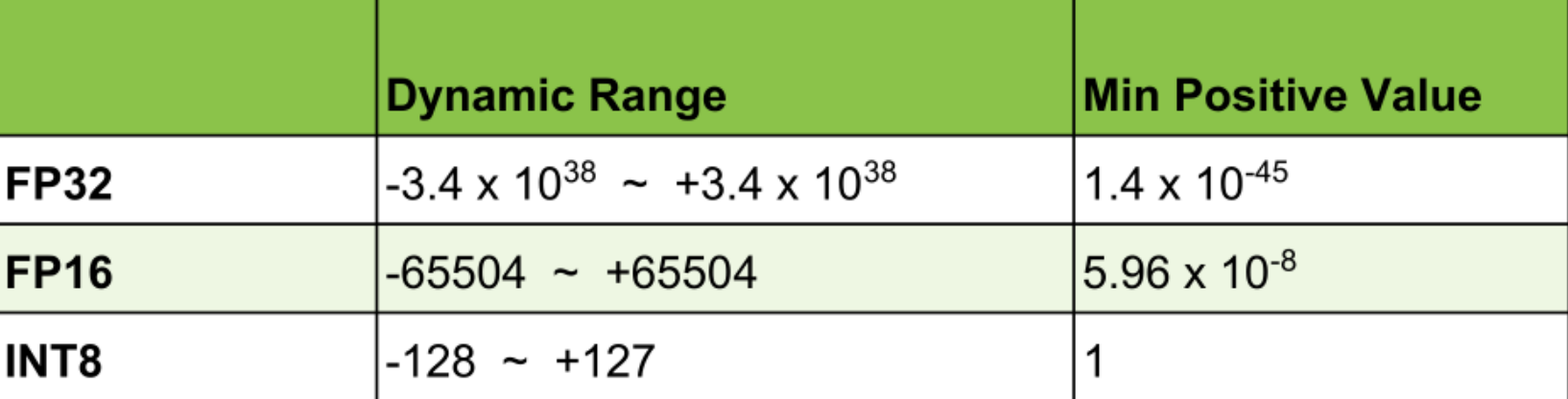
![]()
上图中我们可以看到,32位浮点、16位浮点和INT8的动态范围有很大的不同,以及它们各自的最小的正数值。所以这里我们不能通过简单的类型转换把浮点数转换成INT8,否则就会带来很大的性能损失。
我们先来考虑线性量化(Linear quantization)
![]()
INT8的值和张量的值关系如上图所示,它是由一个32位浮点的常数因子乘以int8的数组再加上32位浮点的偏置。实时上这个32位浮点的偏置对性能的影响不大,所以上式又可以写为
![]()
对于所有的INT8数组,只需要有一个32位浮点的常数因子就可以了。
![]()
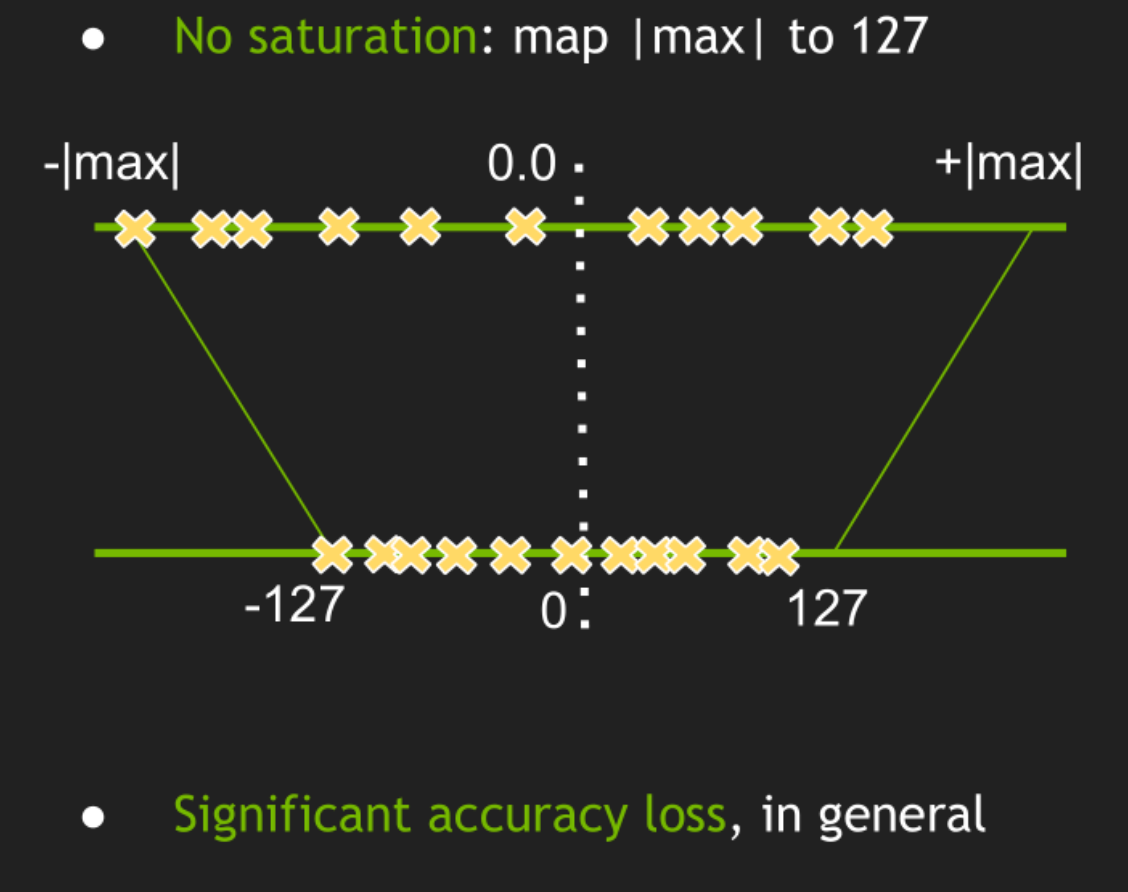
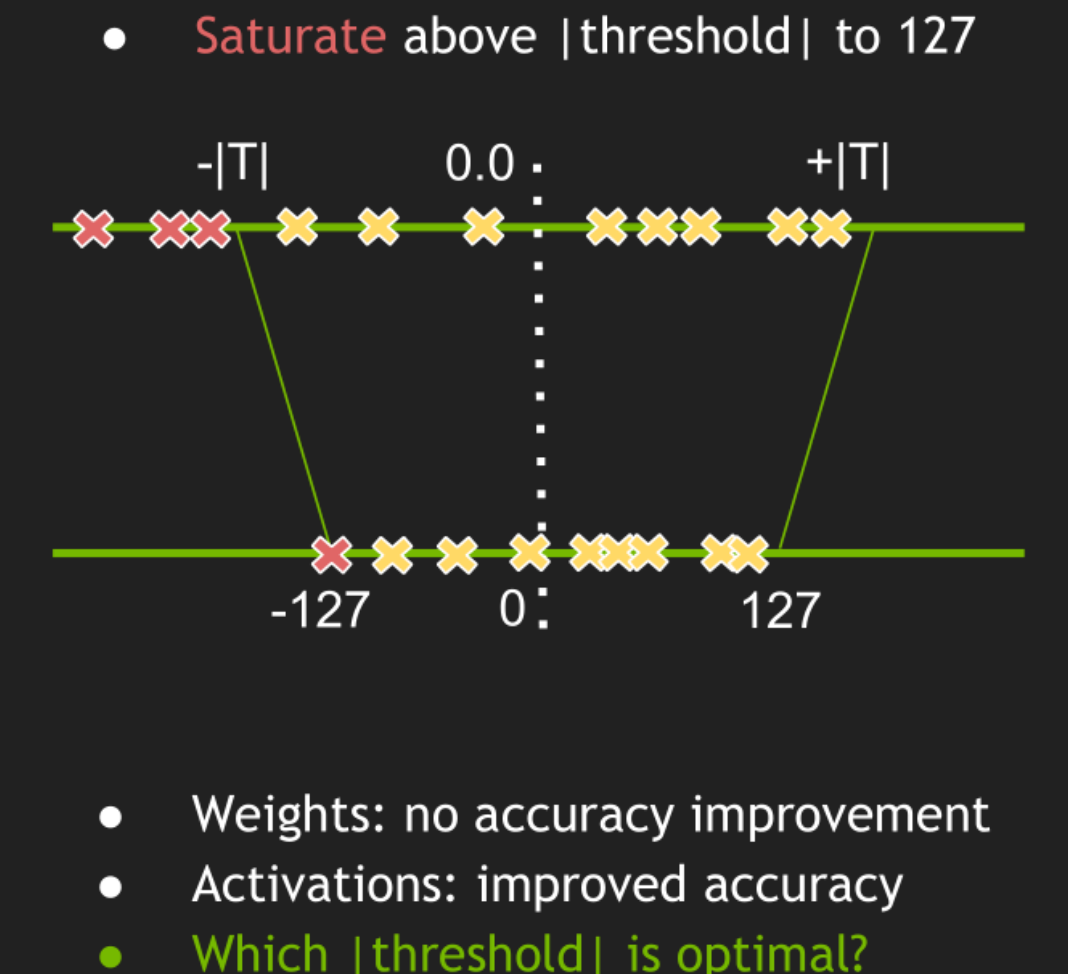
一种是不饱和(No saturation)量化,我们要将浮点数映射到整数,就是将浮点数的最小值映射到-127,浮点数的最大值映射到127。但是这会导致显著的准确率的下降。
![]()
还有一种就是饱和量化,它有一个阈值,这里不再将浮点数的最大最小值映射到-127和127,而是将该阈值的正负位映射到127和-127。超出阈值的部分,小于-|T|的部分只映射为-127,大于+|T|的部分映射为127,这里的T为阈值。这种方式如果我们能够很好的确定这个阈值的话,那么可以提高准确率。一般我们都使用这种饱和量化,现在的关键点就是如何确定这个阈值。
对于INT8的表示,要考虑它的范围和精度
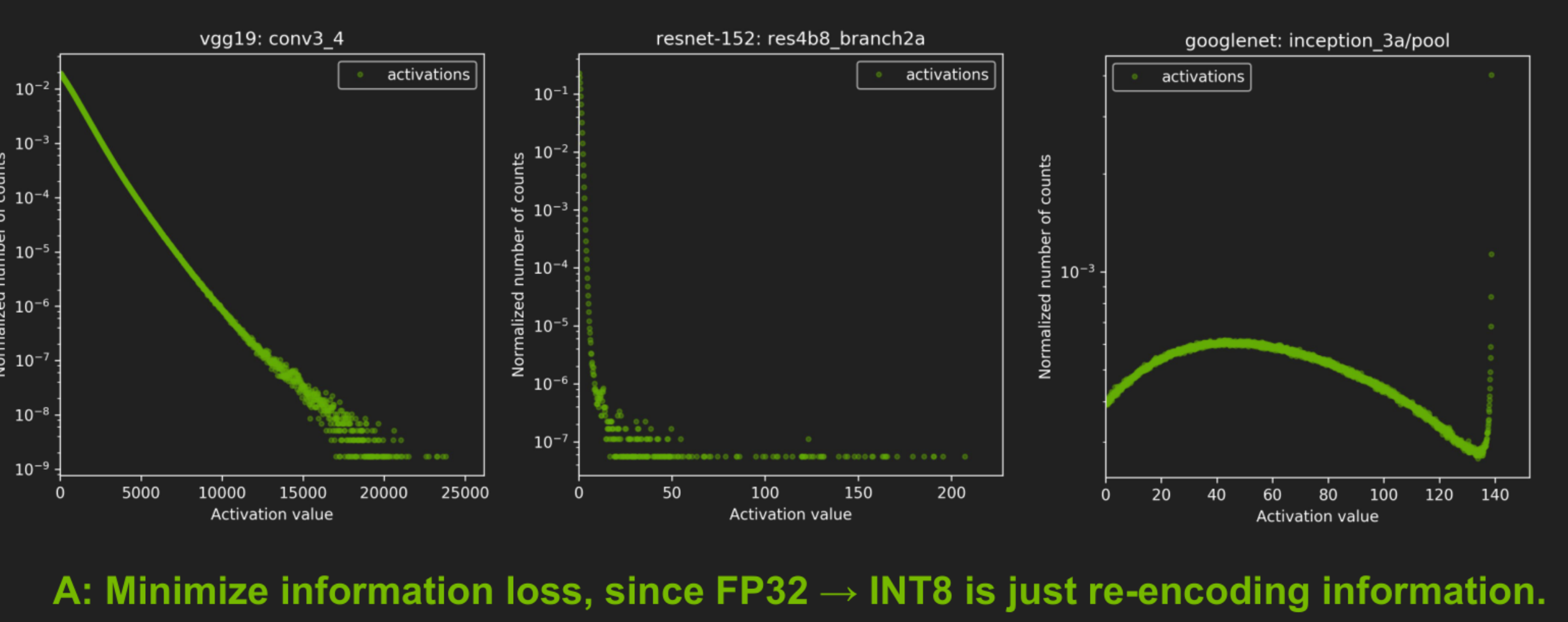
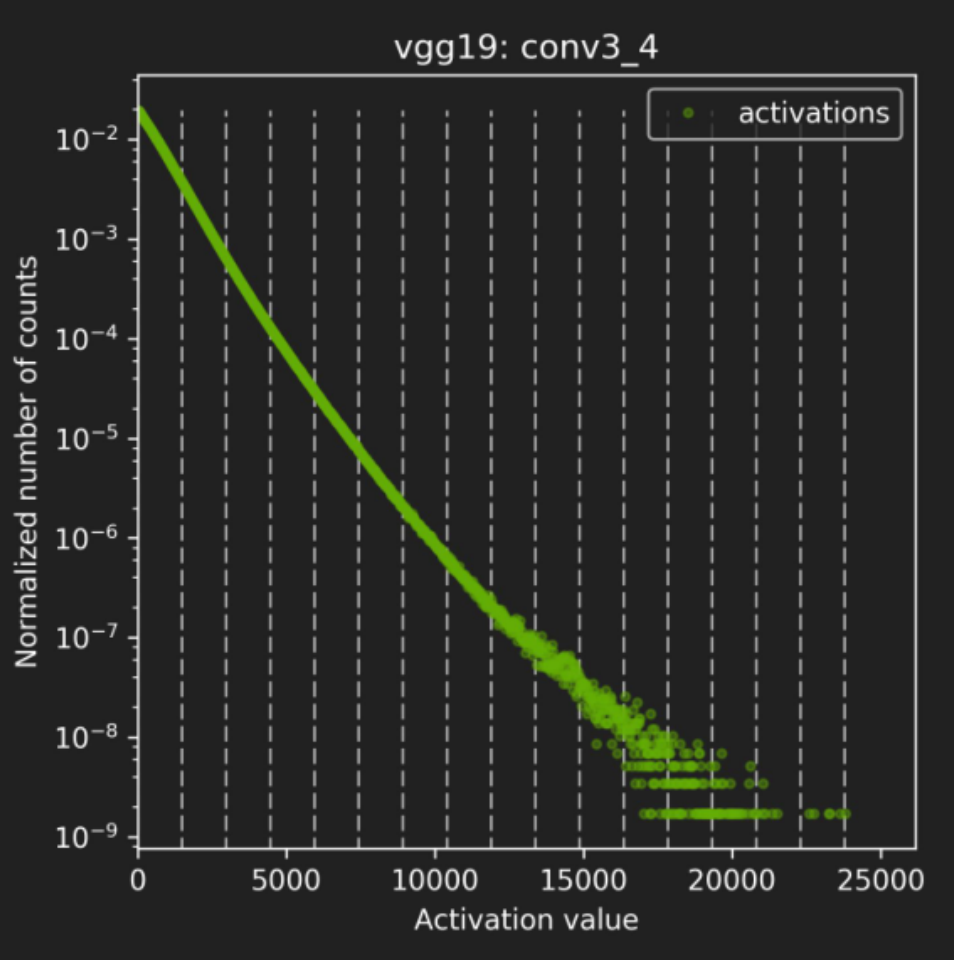
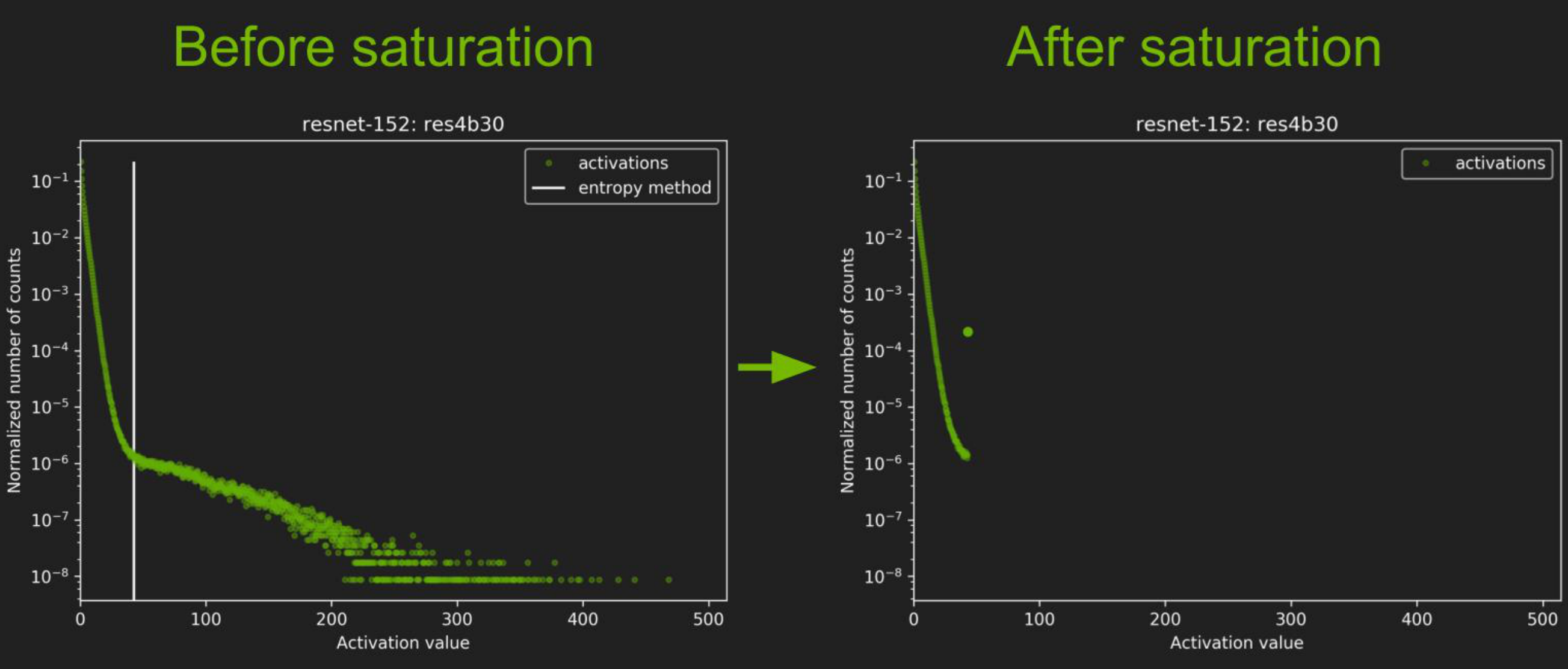
![]()
上图是不同的网络,每个图的横轴是激活值,纵轴是归一化所出现的数。在vgg19中,我们可以看到,激活值越大,它的分布越低,大部分在激活值较小的部分;中间和右边分别是resnet152和googlenet。我们要考虑的是从32位浮点到INT8的最小信息损失只是重新对信息的一种编码。
- INT8模型编码和最初的32位浮点模型是同样的信息。
- 即便做不到,也要最小化信息的损失。
- 可以使用KL散度(相对熵)来表示信息损失。它是用来度量两个概率分布之间的差异值。
- 直觉:KL散度度量的是一个近似给定的编码方式的信息损失。
- 对校准数据集(可以在训练数据集中拿取一部分)进行32位浮点的推理。
- 对于每一层
- 收集激活值的直方图。
- 使用不同的饱和阈值来得到很多的量化分布。
- 挑选一个可以最小化KL散度的阈值。迭代的过程就可以找到一个合适的阈值。
- 整个过程可能要花费几分钟的时间。
![]()
这个就是激活值的直方图。
英伟达选择的是KL散度(KL-divergence),其实就是相对熵。相对熵表述的是两个分布的差异程度,这里就是量化前后两个分布的差异程度。差异最小就是最好的,因此问题转换为求相对熵的最小值。
![]()
上式中,p和q都是一种分布。KL散度来精确测量这种最优和次优之间的差异。F32就是原来的最优编码,INT8就是次优的编码,用KL散度来描述这两种编码之间的差异。相对熵表示的是采用次优编码时会多需要多少个bits来编码,也就是与最优编码之间的bit差。而交叉熵表示的是用次优编码方式时确切需要多少个bits来表示。因此,最优编码所需要的bits=交叉熵-相对熵。
我们需要:
- 训练一个32位浮点的模型的权重。
- 校准数据集。
TensorRT需要:
- 在校准数据集上执行32位浮点的推理。
- 收集所需要的统计值。主要是刚才说的直方图。
- 执行校准算法来得到最优的比例因子(scaling factors)。
- 量化32位浮点权重到INT8权重。
- 最终得到一个"校准表"和一个INT8可执行的推理引擎。
![]()
上图中左边是没有考虑饱和的一张图,右边是考虑了饱和的图。在左图中,假设最优的阈值在那条白色的竖线上的值,那么在右图中小于阈值的部分都会保持不变,大于阈值的部分都会量化到一个值上,就是那个绿点的值。
TensorRT提供了IInt8EntropyCalibrator,该接口需要由客户端实现,以提供校准数据集和一些用于缓存校准结果的样板代码。
![]()
上图是一段伪代码,意思就是一个循环,不断地构造P和Q,并计算相对熵,然后找到最小(截断长度为m)的相对熵,此时表示Q能比较好地拟合P分布了。而阈值就等于(m+0.5)*一个bin的宽度。
需要INT8量化,需要
- 原来的未量化的模型
- 一个校准数据集
- 进行量化过程的校准器
校准过程我们是不用参与的,全部都由TensorRT内部完成,但是,需要告诉校准器如何获取一个batch的数据,也就是说,需要重写校准器类中的一些方法。
- 准备一个校准器,用于在转换过程中寻找使得转换后的激活值分布与原来的FP32类型的激活值分布差异最小的阈值;
- 写一个校准器类,该类需要继承trt.IInt8EntropyCalibrator2父类,并重写get_batch_size,get_batch,read_calibration_cache,write_calibration_cache这几个方法。
- 使用时,需额外指定cache_file,该参数是校准集cache文件的路径,会在校准过程中生成,方便下一次校准时快速提取。
tensorrtx
下载地址:https://github.com/wang-xinyu/tensorrtx
这是一个使用TensorRT网络定义的API来实现网络的加速。该项目中有很多知名的深度学习网络,作者都对其制作了TensorRT的加速。
![]()
当然我们这里依然以YOLOV5为主。该项目没有使用TensorRT内带的解释器,而是使用TensorRT网络定义的API来构建整个网络。
wts文件内容的解释
10
conv1.weight 150 be40ee1b bd20bab8 bdc4bc53 .......
conv1.bias 6 bd327058 .......
conv2.weight 2400 3c6f2220 3c693090 ......
conv2.bias 16 bd183967 bcb1ac8a .......
fc1.weight 48000 3c162c20 bd25196a ......
fc1.bias 120 3d3c3d49 bc64b948 ......
fc2.weight 10080 bce095a4 3d33b9dc ......
fc2.bias 84 bc71eaa0 3d9b276c .......
fc3.weight 840 3c252870 3d855351 .......
fc3.bias 10 bdbe4bb8 3b119ee0 ......
wts就是一个普通的文本文件,它的第一行表示除本行外,下面总共有多少行。下面的行的格式为
[weight name] [value count = N] [value1] [value2], ..., [valueN]
第一个就是权重的名字,第二个是参数数量,后面就是实际的参数值,而该参数值是使用十六进制来表示的。
GPU的CUDA编程方法
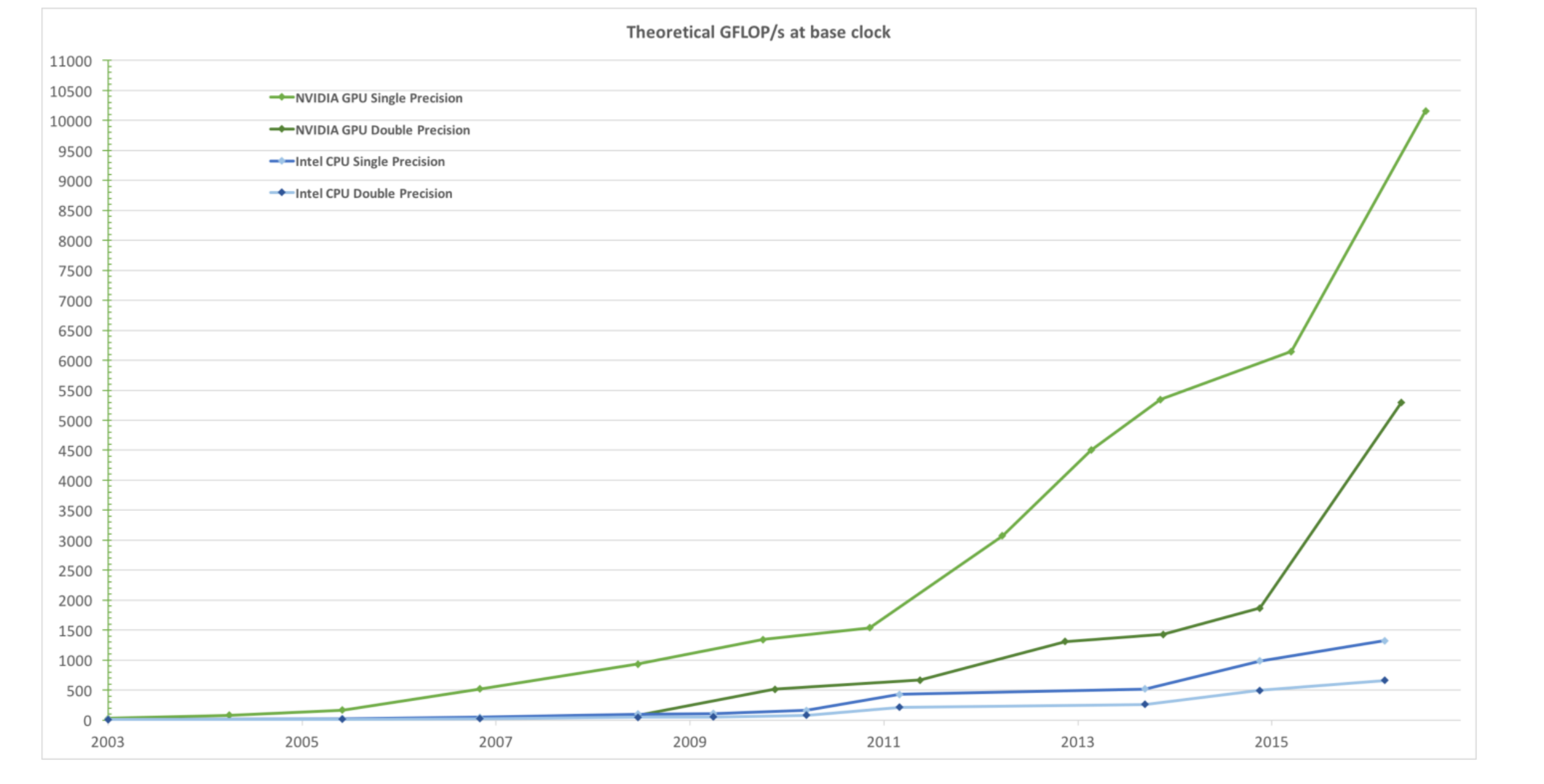
CPU和GPU的每秒浮点运算
![]()
上图中,下面蓝色的线是Inter的CPU的浮点运算的走势,上面的绿色的线是英伟达的GPU的浮点运算的走势。显然我们可以看到,GPU相比CPU的每秒的浮点运算能力要高的多。
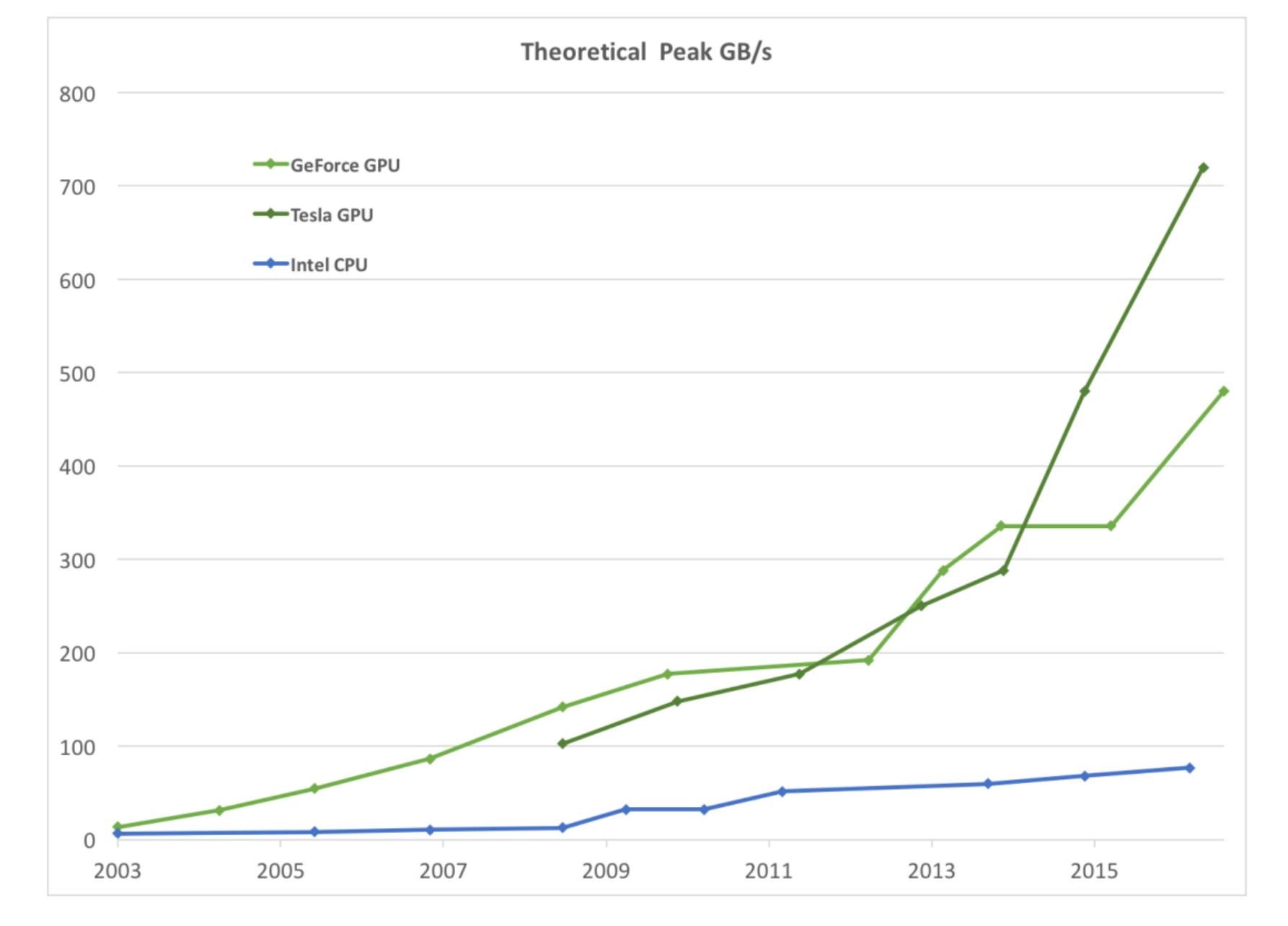
CPU和GPU的内存带宽
![]()
同样,如上图所示,GPU的内存带宽也是远远高于CPU的。
![]()
如上图所示,CPU在串行任务中有它的优势,而并行任务就是GPU的优势了。