业务挑战
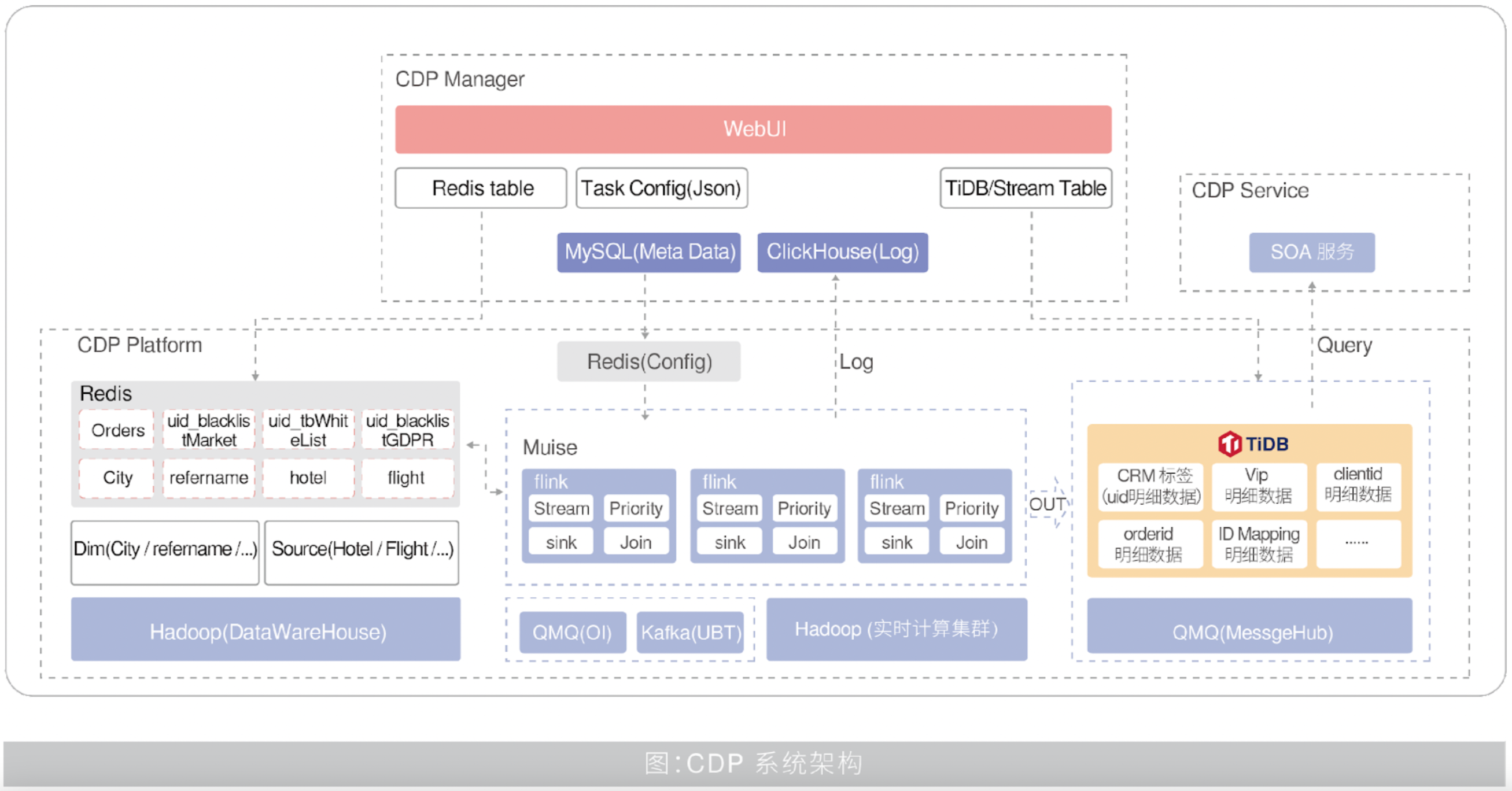
在国际业务上,由于面临的市场多,产品和业务复杂多样,投放渠道多,引流费用高,因此需要对业务和产品做出更精细化的管理和优化,满足市场投放和运营需要,降低整体成本,提高运营效率与转化率。为此,携程专门研发了国际业务动态实时标签化处理平台(以下简称 CDP )。
携程旅行的数据具有来源广泛、形式多样、离线数据处理与在线数据处理兼有等特点,如何通过系统对这些数据进行采集、管理、加工,形成满足业务系统、运营、市场需求的数据和标签。处理好的数据需要立刻运用到业务系统、EMD、PUSH 等使用场景中,对数据处理系统的时效性、准确性、稳定性以及灵活性提出了更高要求。
为了解决以上问题,CDP 系统必须提升数据处理能力。过去传统方案是通过数仓进行 T+1 计算,再导入 ES 集群存储,前端通过传入查询条件,组装 ES 查询条件查询符合条件的数据。携程已经上线的标签有上百个,有查询使用的超过 50% ,由于该方案是离线计算,所以数据时效性差,依赖底层离线平台计算和 ES 索引,查询响应速度较慢。
解决方案
CDP 希望在数据处理的过程中能提升数据处理时效性,同时满足业务灵活性的要求,对于数据处理逻辑、数据更新逻辑,可以通过系统动态配置规则的方式来消费消息数据(Kafka 或 QMQ)动态更新标签,业务层只需关心数据筛选逻辑及条件查询。 根据业务需求,业务数据标签筛选主要分为两大场景:
-
实时触发场景。根据业务需要,配置动态规则,实时订阅业务系统的变更消息,筛选出满足动态规则条件的数据,通过消息的方式推送到下游业务方;
-
标签持久化场景。将业务系统的实时业务变更消息按照业务需要,加工成业务相关的特征数据,持久化存储到存储引擎。业务根据需要组装查询条件查询引擎数据,主要有 OLAP (分析类)与 OLTP (在线查询)两大类查询。
基于以上需求,CDP 流式数据采用类 Kappa 架构,标签持久化采用类 Lambda 架构,如下图所示:
![携程 CDP 架构.png]()
其中,标签持久化场景需要解决业务标签的持久化存储、更新、查询服务,携程采用了 TiDB 来存储业务持久化的标签,并采用实时触发场景中的动态规则配置方式消费业务系统数据变更消息,保证业务持久化标签的时效性,通过 TiDB 对 OLTP 和 OLAP 不同场景查询特性的支持,来满足不同业务场景中访问业务特征数据的需要。
系统借鉴了 Lambda 数据处理架构的思想,新增数据根据来源不同分别发送到不同的通道中,历史全量数据通过数据批处理引擎(如 Spark)转换完,批量写入到数据持久化存储引擎 TiDB 中。增量数据业务应用以消息形式发送到 Kafka 或 QMQ 消息队列,将数据按照标签持久化的逻辑规则处理完成,增量写入到持久化存储引擎 TiDB,以此解决数据的时效性问题。
TiDB 同时具有两大持久化存储方式,一种是行存 TiKV ,可以支持 OLTP 场景,另一种是列存 TiFlash ,可以支持 OLAP 场景。TiDB 数据存储内部自动解决这两个引擎的数据同步问题,客户端查询根据自身需要选择查询方式。同时,TiDB 还能保障两种方式有着良好的隔离性,并兼顾数据强一致性,出色地解决了 HTAP 场景的隔离性及列存同步问题。
目前,CDP 已经与携程各个业务系统进行深度整合打通,为国际业务增长提供业务特征标签库的数据与服务支持。
应用价值