![]()
一、测试结果
最新发布的MatrixOne 0.2.0版本新增了Benchmarks章节,针对常规测试程序SSB与纽约出租车数据测试,在支持分布式强一致性前提下,基于向量化执行引擎和因子化加速的技术加持,MatrixOne计算引擎在查询速度方面表现突出,可以承载TB级别数据的快速查询,与同类数据库产品相比有较明显的优势。
-
单机单表的SSB测试:MatrixOne比Clickhouse快50%以上
-
单机多表的SSB测试:MatrixOne比Clickhouse快100%以上
-
集群多表的SSB测试:大幅快于Clickhouse。由于Clickhouse集群多表的能力有限,多表测试不详细展开对比。
MatrixOne项目作为一款从零开始自主打造的超融合数据库项目,经过8个月左右的开发,在分布式强一致的能力融合后,计算查询性能依然达到了可以与世界顶尖OLAP数据库性能媲美水平。
未来MatrixOne还将在融合更多引擎能力的同时坚持对极致性能的持续追求,为用户创造极简、快速的数据库产品体验。
二、测试内容
-
单机与集群上SSB测试单表、多表查询
-
单机服务器上纽约出租车数据的单表查询
-
测试硬件配置:本次所有测试所使用的服务器配置均为「AMD EPYC™ Rome CPU 2.6GHz/3.3GHz, 16核, 32 GiB 内存」
-
更加详细的测试信息可参见 「MatrixOne官方文档网站」
三、SSB测试
SSB测试基于TPC定义的TCP-H规范,是一套用于测试数据库产品在星型模式下性能表现的基准测试规范,目前在学术界和工业界都得到了广泛的使用。它将TPC-H的雪花模式简化为了星型模式,将基准查询由TPC-H的复杂Ad-Hoc查询改为了结构更固定的OLAP查询。
1. 测试概况
为体现MatrixOne的单表查询能力,特将SSB测试中所含有的五张数据表:lineorder, part, supplier, customer, dates合成为一张宽表:lineorder_flat。然后利用单机服务器进行单表查询(宽表共包含6亿行数据,总共约220GB空间)。此外,按照SSB既定的部分查询语句,利用单机与集群分别进行多表查询(共包含6亿行数据,主表占据约67GB空间)。同时由于MatrixOne对过滤的支持不完善,因此在标准SSB测试SQL中去除了需要带过滤的SQL语句。
2. 测试流程
SSB测试数据由dbgen命令产生,对数据预处理后使用load data infile命令将数据导入已建好的MatrixOne数据表中,最后进行相关查询操作。具体测试流程请参见已发布的「SSB Test with MatrixOne」文档。
3. 测试结果
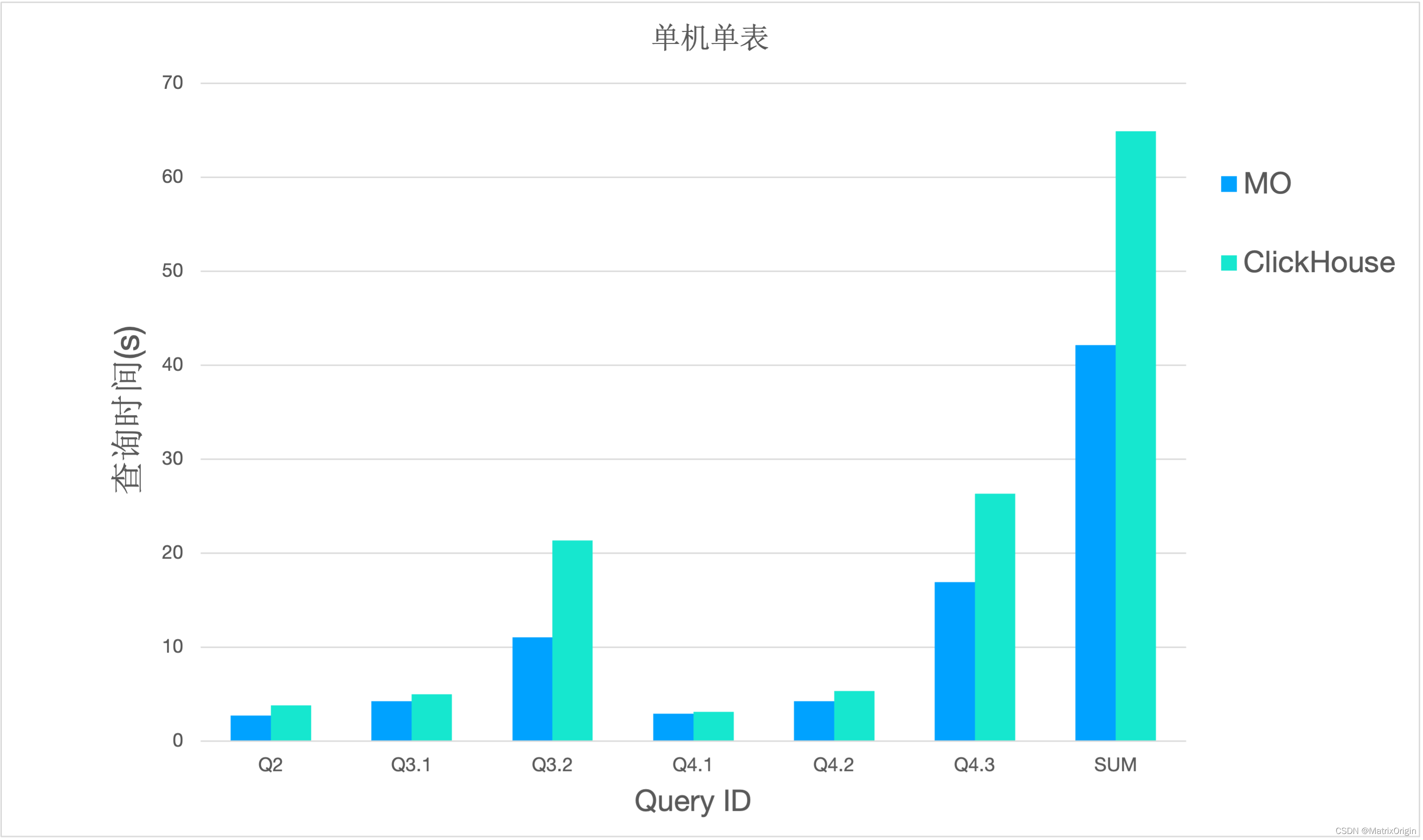
>>>单机单表测试<<<
在单机单表测试中,针对给定的版本,MatrixOne在每个查询上的运行速度均快于Clickhouse,总查询时间仅为Clickhouse的65%,结果如下:
| 单机单表测试 |
Q2 |
Q3.1 |
Q3.2 |
Q4.1 |
Q4.2 |
Q4.3 |
SUM |
| MO 0.2.0 |
2.71 |
4.23 |
11.05 |
2.94 |
4.27 |
16.91 |
42.11 |
| ClickHouse v21.11.4.14 |
3.82 |
5.01 |
21.34 |
3.1 |
5.32 |
26.32 |
64.91 |
![]()
>>>单机多表测试<<<
在单机多表测试中,针对给定的版本,MatrixOne在每个查询上的运行速度均快于Clickhouse,在总查询时间上表现优异,为Clickhouse的50%,结果如下:
| 单机多表测试 |
Q2 |
Q3.1 |
Q3.2 |
Q4.1 |
Q4.2 |
Q4.3 |
SUM |
| MO 0.2.0 |
13.6 |
12.94 |
23.56 |
13.96 |
19.72 |
46.07 |
129.85 |
| ClickHouse v21.11.4.14 |
28.05 |
27.81 |
54.84 |
27.2 |
41.82 |
85.99 |
265.71 |
四、纽约出租车(NYC)数据测试
纽约市出租车数据集收集了纽约市数十亿次出租车出行的详细信息,包括接送日期、时间、接送地点、行程距离、详细票价、费率、支付类型、以及乘客数量(大部分原始数据来自NYC Taxi & Limousine Commission)。
1. 测试概况
使用单机服务器对NYC数据进行单表查询(宽表共包含17亿行数据,总共约450GB空间)。由于目前MatrixOne对数据表分区的支持还不完善,因此去掉了Clickhouse中对Partition命令的使用。
2. 测试流程
NYC测试数据目前需要通过PostgreSQL进行下载,并导入MatrixOne的数据表,整个数据下载及导入的流程可参考「GitHub」以及官方文档「NYC Test with MatrixOne」。
3. 测试结果
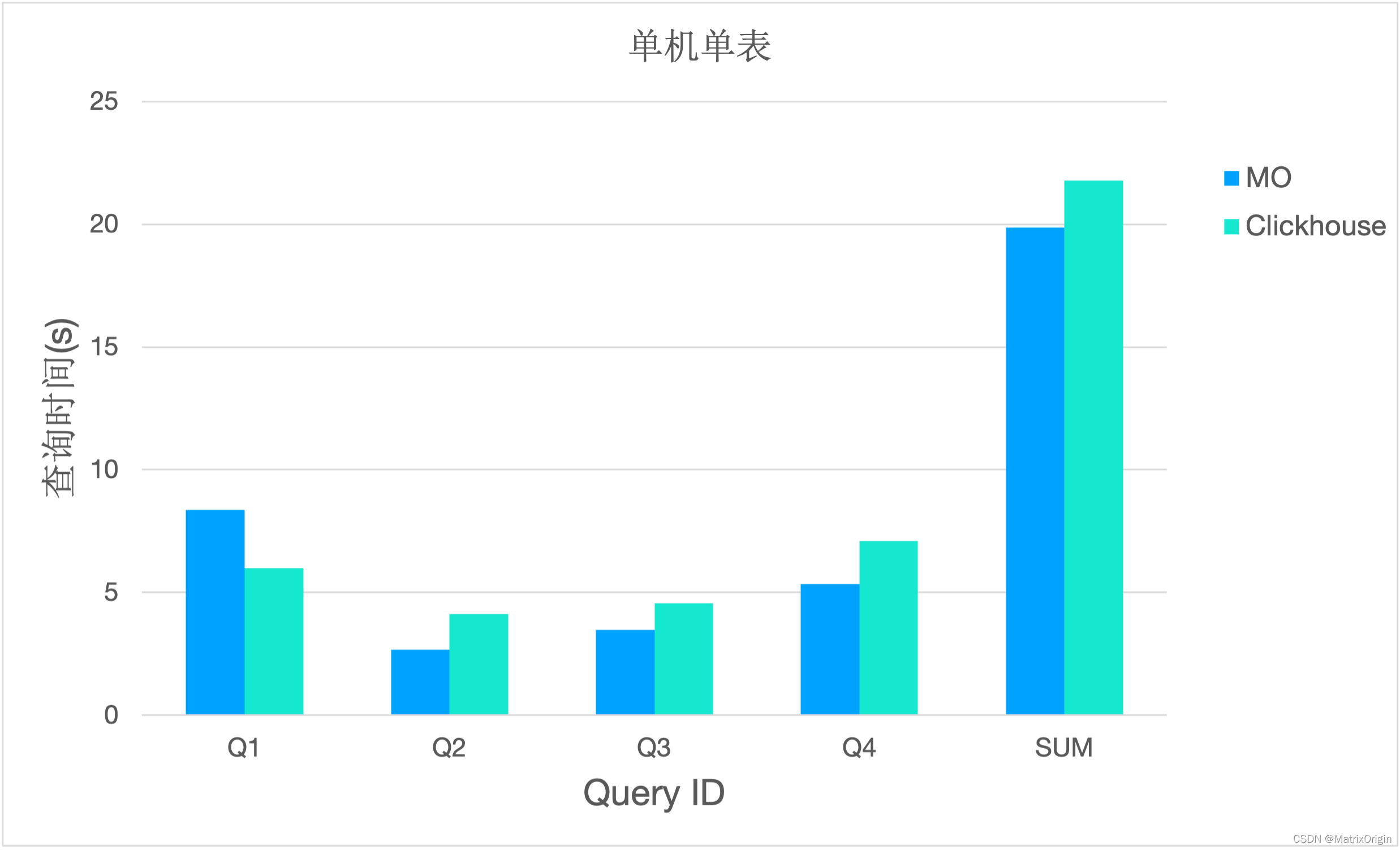
>>>单机单表测试<<<
在NYC数据的单机单表测试中,针对给定的版本,除Q1之外,MatrixOne的运行速度均快于Clickhouse,总查询时间略少于Clickhouse。具体结果如下:
| 单机单表测试 |
Q1 |
Q2 |
Q3 |
Q4 |
SUM |
| MO |
8.37 |
2.67 |
3.48 |
5.34 |
19.86 |
| ClickHouse |
5.99 |
4.13 |
4.56 |
7.09 |
21.77 |
![]()
五、欢迎加入MatrixOne社区
官网:matrixorigin.cn
源码:github.com/matrixorigin/matrixone
Slack:matrixoneworkspace.slack.com