摘要:控制语句,到底何错之有呢?
本文分享自华为云社区《业务代码如何才能不再写出大串的if/else?》,作者: JavaEdge 。
控制结构?没错!你最爱的 if、for都是一类坏味道,没想到吧?自己竟然每天都沉浸在写坏味道的体验中。
控制语句,到底何错之有呢?
嵌套代码
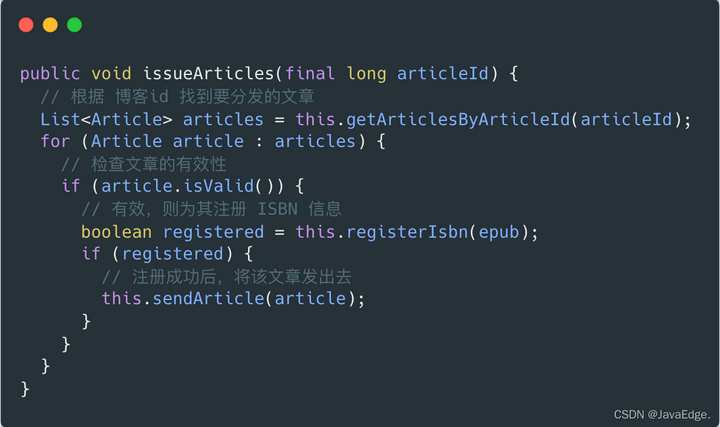
CR 如下分发我刚写完的一篇博客的案例:
![]()
逻辑很简单,但有多层缩进,for 循环一层,里面有俩 if ,又多加两层。若逻辑再复杂点,缩进岂不是像啤酒肚一般越来越大?
为啥代码会写成这鬼样子呢?
因为你在写流水账,如机器人般地按需求一步步翻译成代码。
代码逻辑肯定没错,但功能实现后,未重新整理代码。
现在就得消除缩进。
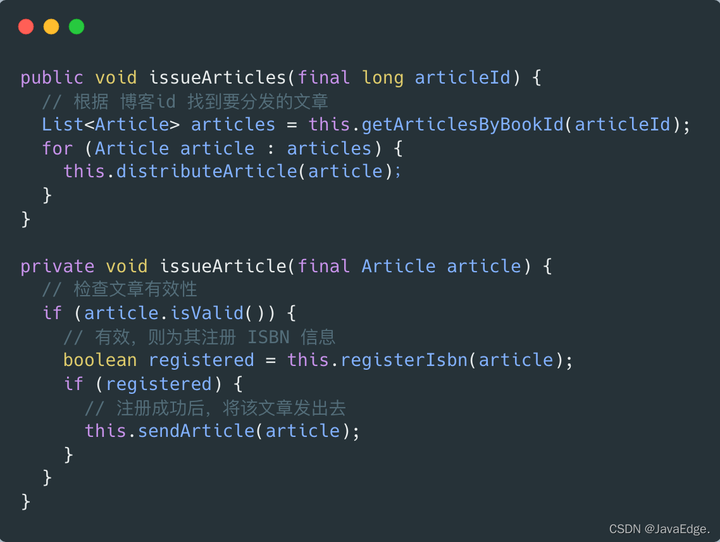
从for循环入手,通常for循环处理集合,而循环里处理的是该集合中的元素。所以,可将循环中的内容提取成方法,只处理一个元素:
![]()
这就是一次拆分,分解出来事务 issueArticle 每次只处理一个元素。这就优化了缩进问题:
- issueArticles 只有一层缩进,这才是正常方法应有的样子。
- 但 issueArticle 还残留多层缩进,待继续优化。
if 和 else
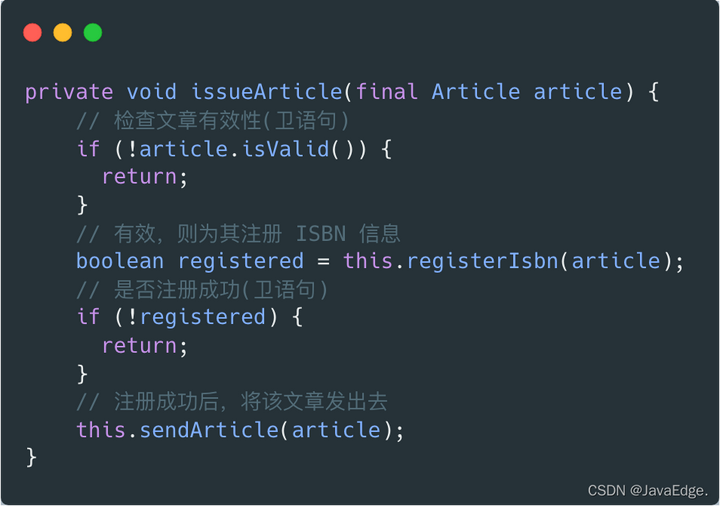
issueArticle 里,造成缩进的原因是 if 语句。if 缩进很多时候都是在检查某先决条件,条件通过时,才能执行后续代码。
这样的代码可使用卫语句(guard clause),即设置单独检查条件,不满足该检查条件时,方法立刻返回。
以卫语句取代嵌套的条件表达式(Replace Nested Conditional with Guard Clauses)。
重构后的 issueArticle 函数:
![]()
如今这就只剩一层缩进,代码复杂度大大降低,可读性和可维护性也大大增强。
禁用else
大多数人印象中,if 和 else 几乎比翼齐飞。
else 可以不写吗?
可以!
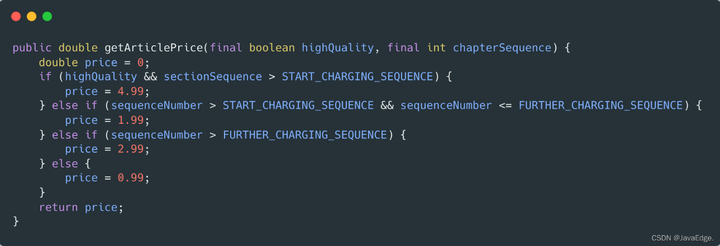
根据文章信息进行收费:
![]()
不用 else,简单方式就是让每个逻辑提前返回,类似卫语句:
![]()
业务简单的代码,这重构还很轻松,但对复杂代码,就得上多态了。
嵌套、else 语句,都是坏味道,本质上都在追求简单,因为一段代码的分支过多,其复杂度就会大幅度增加。
衡量代码复杂度常用的标准,圈复杂度(Cyclomatic complexity,CC),CC越高,代码越复杂,理解和维护的成本越高。
在CC判定中,循环和选择语句占主要地位。CC可使用工具检查,如Checkstyle,可限制最大的圈复杂度,当圈复杂度大于设定阈值,就报错。
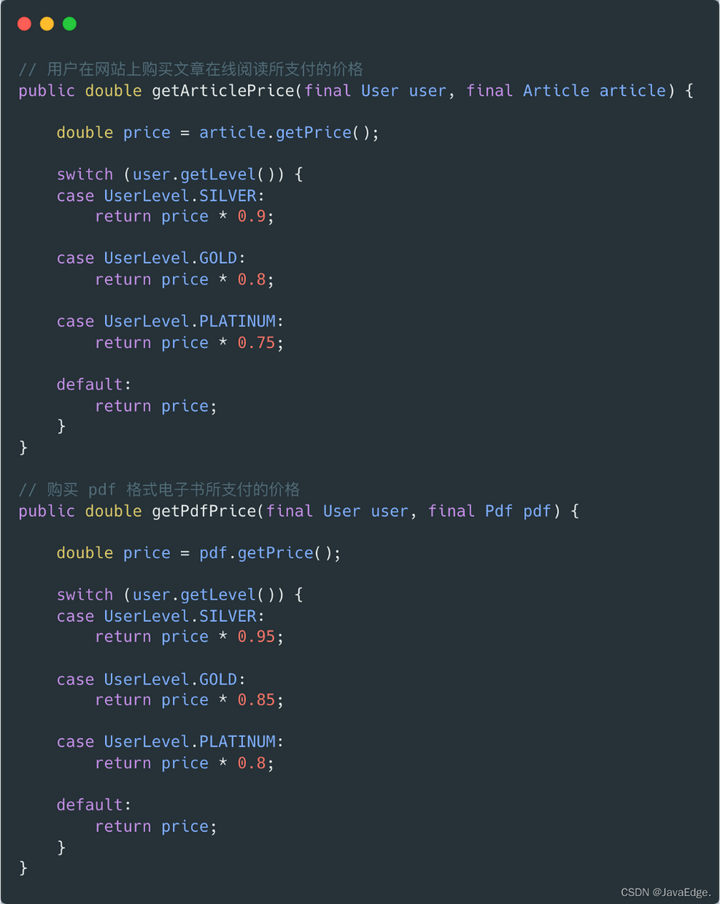
重复 Switch
![]()
实际支付的价格会根据用户在系统中的用户级别有所差异,级别越高,折扣越高。
两个函数里出现了类似的代码,其中最类似部分就是 switch,都据用户级别判断。
这并非仅有的根据用户级别进行判断的代码,各种需区分用户级别场景都有类似代码,而这也是一种典型的坏味道:重复switch(Repeated Switch),通常都是因为缺少一个模型。
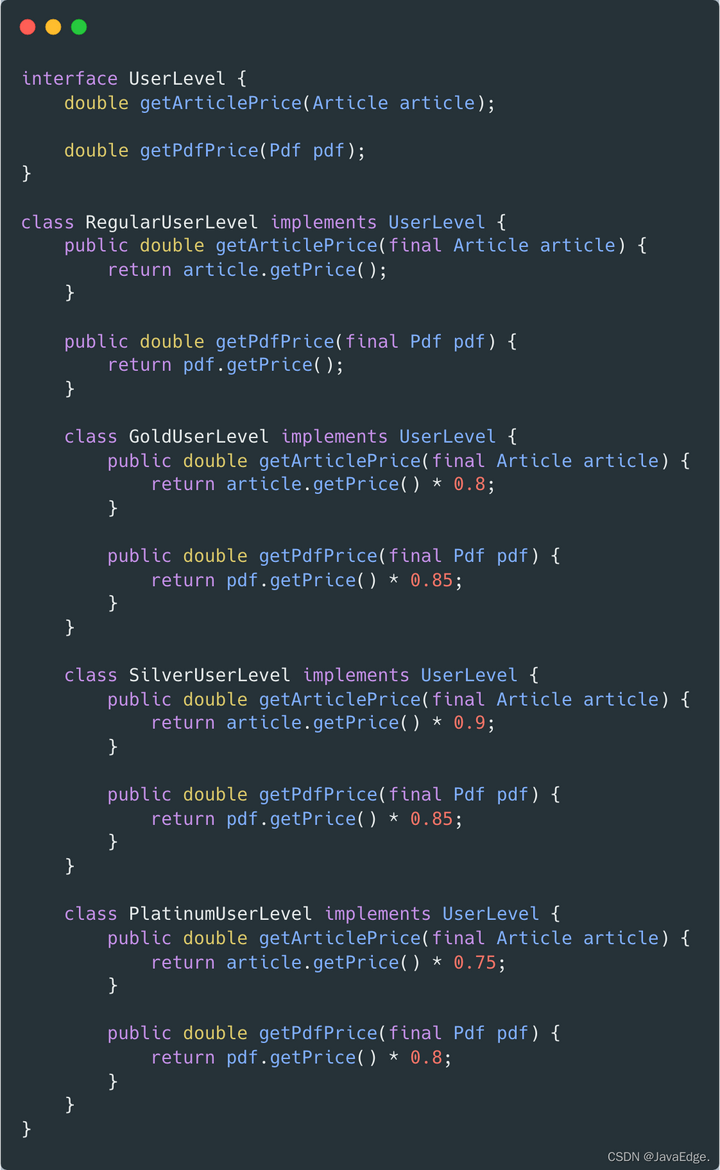
解决方案:以多态取代条件表达式(Relace Conditional with Polymorphism)。
引入 UserLevel 模型,消除 switch:
![]()
前面代码即可去掉 switch:
![]()
switch 其实就是一堆“ if…else” 的简化写法,二者等价,所以,这个重构手法,以多态取代的是条件表达式,而不仅是取代 switch。
点击关注,第一时间了解华为云新鲜技术~