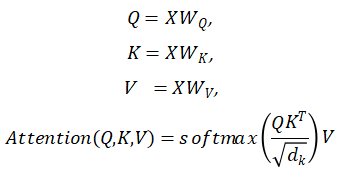那么我们为什么需要预训练模型呢?在这里做一个比喻,如果把深度学习算法比作武侠的话,那预训练模型就是他的内功,有了扎实的内功基础,就能够更容易、更快速的掌握各种武功招式,并发挥其最大效用。预训练模型的过程就是深度学习算法修炼内功的过程。
2 OPPO自研大规模cv预训练模型
2.1 概述
之所以要自研预训练模型主要是两点原因:首先,当前数据科学家们使用的预训练模型都是网上开源的,每年都有变化,最新的一些研究往往不开源,无法保证效果最优;其次就是网上开源的预训练模型,都是基于开源数据集数据集训练得到的,比如大家熟知的imagenet。没有充分利用公司自有数据的优势。因此,自研预训练模型是十分有意义的。
OPPO自研大规模cv预训练模型技术方案主要包括以下三大部分:
1)网络架构创新:主要是研究当前cv界主流模型架构如CNN,Transformer和MLP等,对不同结构当前SOTA的网络架构进行组合、优化的探索,尽可能的得到性能最优的网络架构作为预训练模型的主干网络。
2)自监督学习训练:主要是希望能够充分利用oppo自有的海量无标注数据,在海量无标注数据下进行预训练,从而得到更加通用的特征表达,让模型能够更好地克服OOD(与训练集分布不同)情况,得到更加鲁棒的预训练模型。
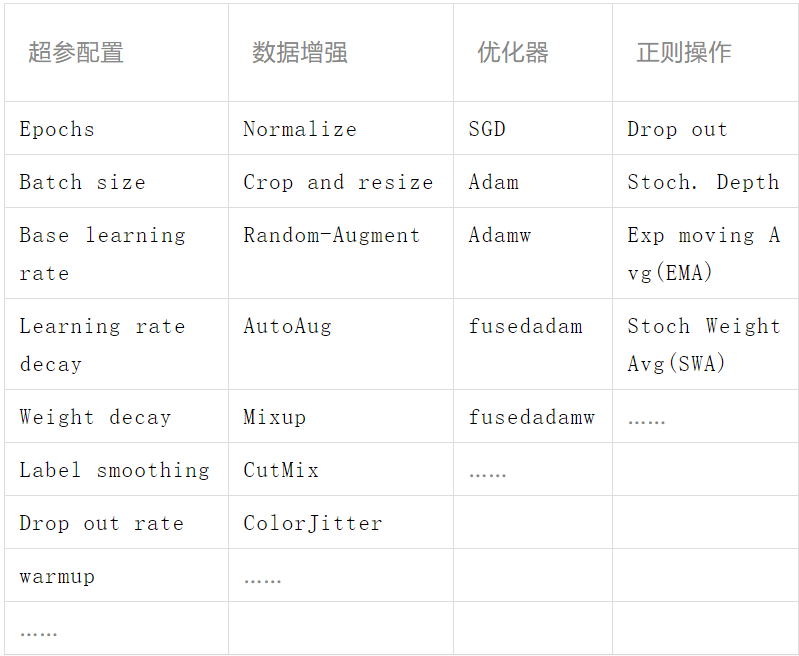
3)有监督微调训练:当利用具体的任务数据集(标注样本)对预训练模型的网络参数进行微调训练时,使用合适的训练方法及正则方法,可以使模型在具体下游任务达到最优效果。
2.2 关键技术
2.2.1 网络架构设计
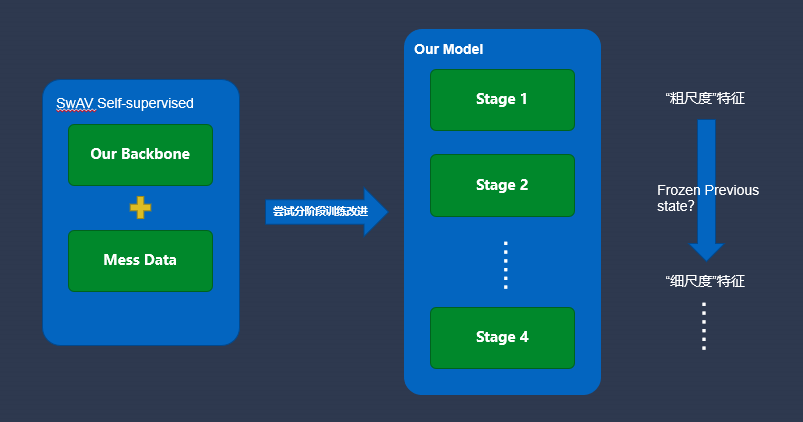
在网络架构方面,我们的目标是设计合适的网络架构,缩小特征探索空间,提升网络性能。为了能够更适合接入不同的稠密场景视觉任务,我们的网络架构需要设计成一种多阶段的层次结构来提供多尺度的特征图,并且我们的网络要易于拓展成不同参数量级的变体模型,以满足不同业务场景的需求同时要在参数量和浮点数计算量更低的条件下尽可能的提升网络的性能。
当前计算机视觉领域三大主流模型架构包括卷积神经网络CNN,Transfomer以及多层感知机MLP。其中CNN多年来一直是计算机视觉任务中占据主导地位的网络架构,CNN擅长提取局部细节特征,并且具有形变、平移及缩放不变性等优点。Transformer在NLP领域取得了巨大的成功,去年首次在CV界亮相开始引领新的趋势,Transformer的优点是擅长捕获全局信息, 具有更大的模型容量,且其运作机制更接近人类。在Transformer崛起的同时,一部分研究聚焦于MLP替代Transformer组件构建网络的研究,开辟了另一个研究方向,MLP 在小的模型规模下可以实现接近Transformer的性能,但当规模扩大时,它就会受到严重的过拟合影响。
通过对这三种主流模型架构进行研究分析后,我们得到了以下一些结论:对于MLP 来说,它的研究聚焦在替换 Transformer组件来获得相对有竞争力的结果,但是实际效果并没有超越基于transformer的方法,这系列工作只是一定程度上开拓了一个新的思路。CNN中的卷积操作擅长提取图片的局部信息,而Transformer通过构造图像tokens提取到图片的全局表示,因此CNN和Transformer在一定程度上可以形成良好的互补。还有就是Transformer 在三种架构中具有最大的模型容量,更适合做大规模预训练模型。因此,Transformer 加 CNN的架构或许是最优的解决方案。
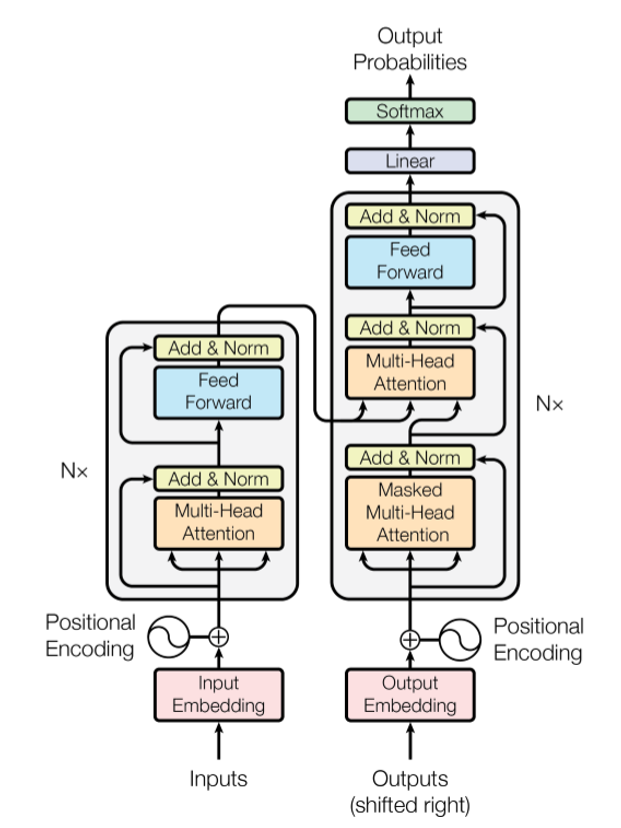
既然我们要聚焦于Transformer方法,我们就先要对Transformer的基本原理有一定的了解,以便对其进行改进。所以接下来我先对Transformer进行简单介绍。Transformer结构是google在17年的Attention Is All You Need论文中提出的,在NLP的多个任务上取得了非常好的效果。它最大特点是整个网络结构完全是由Self-Attention机制组成。如图一所示,Transformer采用Encoder-Decoder结构,输入经过 embedding后,要做位置编码,然后是多头自注意力机制,再经过Feed Forward,每个子层有残差连接,最后要经过Linear和softmax输出概率。