在 go-zero 的分布式缓存系统分享里,Kevin 重点讲到过一致性hash的原理和分布式缓存中的实践。本文来详细讲讲一致性hash的原理和在 go-zero 中的实现。
以存储为例,在整个微服务系统中,我们的存储不可能说只是一个单节点。
- 一是为了提高稳定,单节点宕机情况下,整个存储就面临服务不可用;
- 二是数据容错,同样单节点数据物理损毁,而多节点情况下,节点有备份,除非互为备份的节点同时损毁。
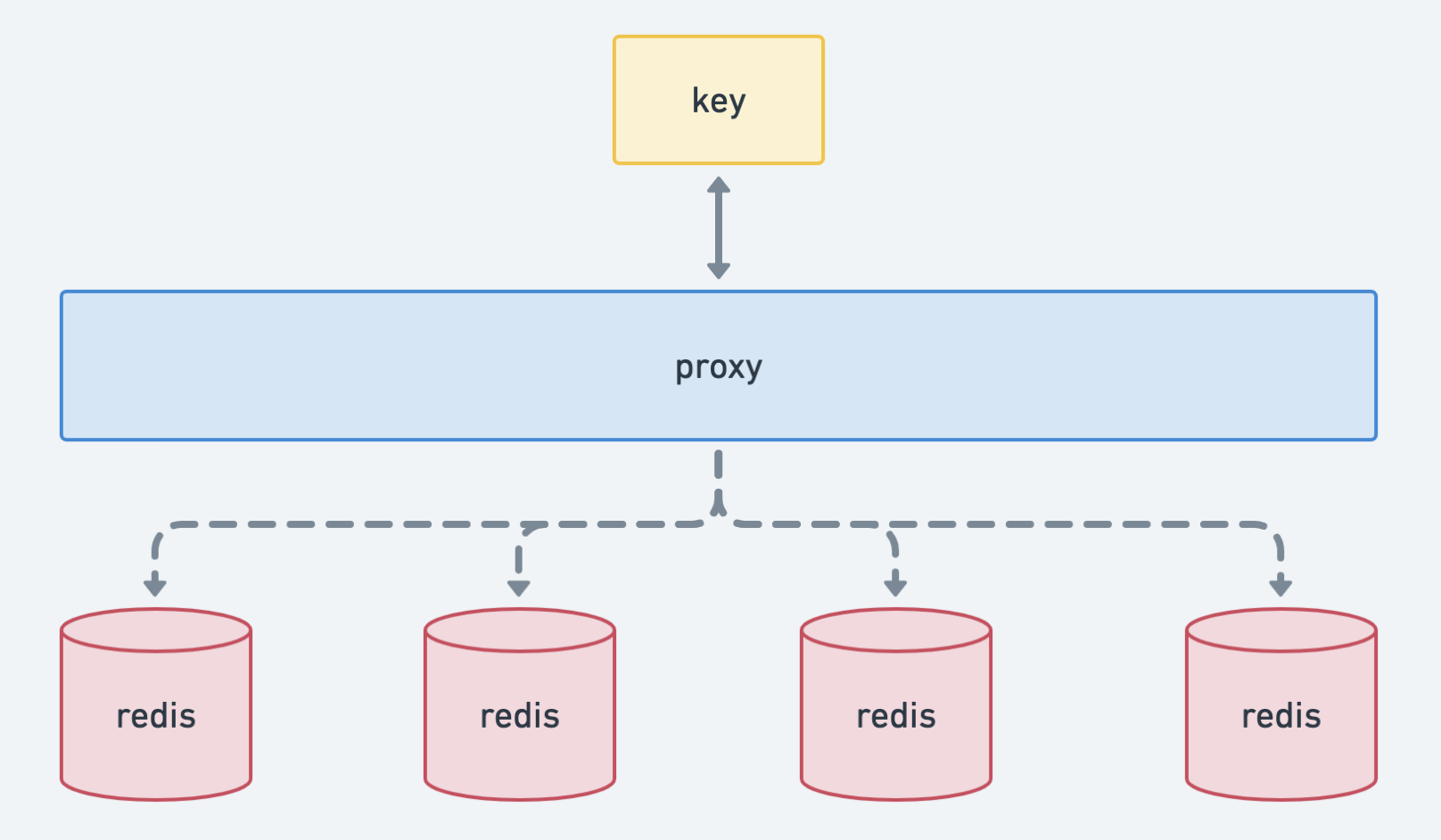
那么问题来了,多节点情况下,数据应该写入哪个节点呢?
hash
![]()
所以本质来讲:我们需要一个可以将输入值“压缩”并转成更小的值,这个值通常状况下是唯一、格式极其紧凑的,比如uint64:
- 幂等:每次用同一个值去计算 hash 必须保证都能得到同一个值
这个就是 hash 算法完成的。
但是采取普通的 hash 算法进行路由,如:key % N 。有一个节点由于异常退出了集群或者是心跳异常,这时再进行 hash route ,会造成大量的数据重新 分发到不同的节点 。节点在接受新的请求时候,需要重新处理获取数据的逻辑:如果是在缓存中,容易引起 缓存雪崩。
此时就需要引入 consistent hash 算法了。
consistent hash
我们来看看 consistent hash 是怎么解决这些问题的:
rehash
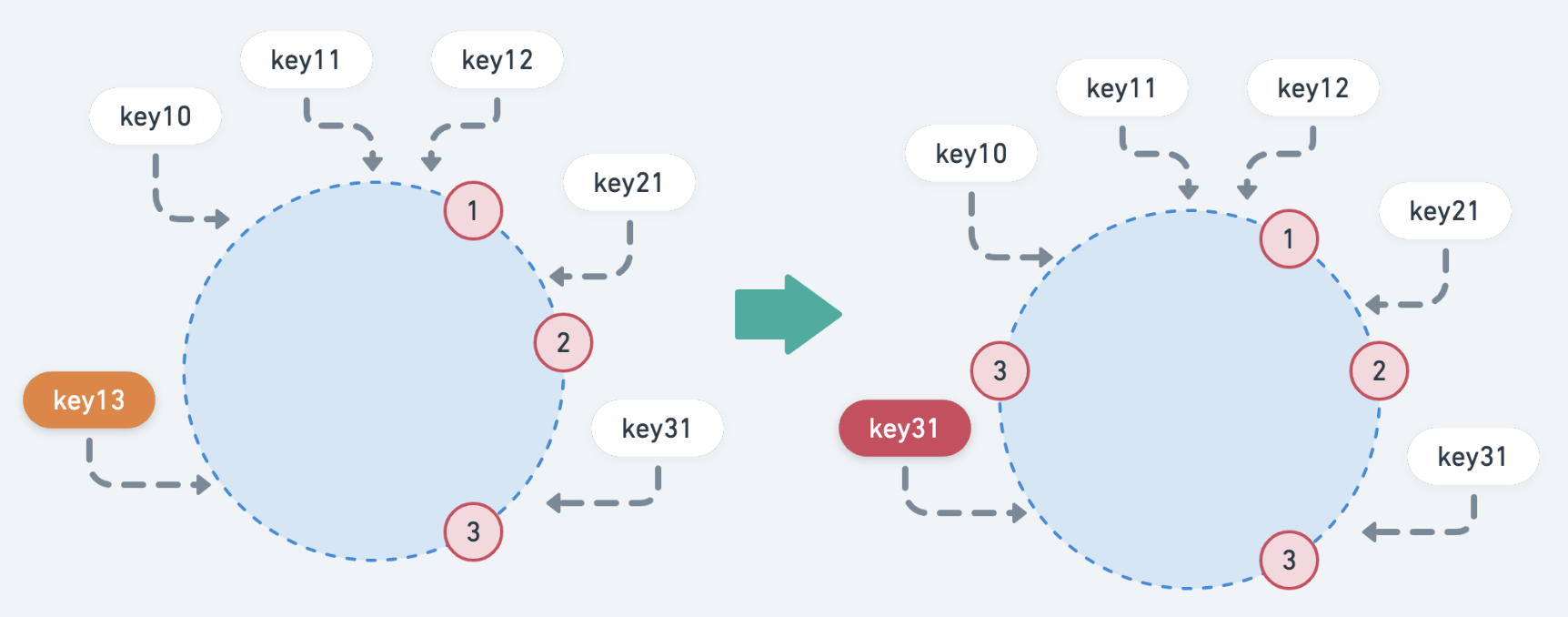
先解决大量 rehash 的问题:
![]()
如上图,当加入一个新的节点时,影响的key只有 key31,新加入(剔除)节点后,只会影响该节点附近的数据。其他节点的数据不会收到影响,从而解决了节点变化的问题。
这个正是:单调性。这也是 normal hash 算法无法满足分布式场景的原因。
数据倾斜
其实上图可以看出:目前多数的key都集中在 node 1 上。如果当 node 数量比较少的情况下,可以回引发多数 key 集中在某个 node 上,监控时发现的问题就是:节点之间负载不均。
为了解决这个问题,consistent hash 引入了 virtual node 的概念。
既然是负载不均,我们就人为地构造一个均衡的场景出来,但是实际 node 只有这么多。所以就使用 virtual node 划分区域,而实际服务的节点依然是之前的 node。
具体实现
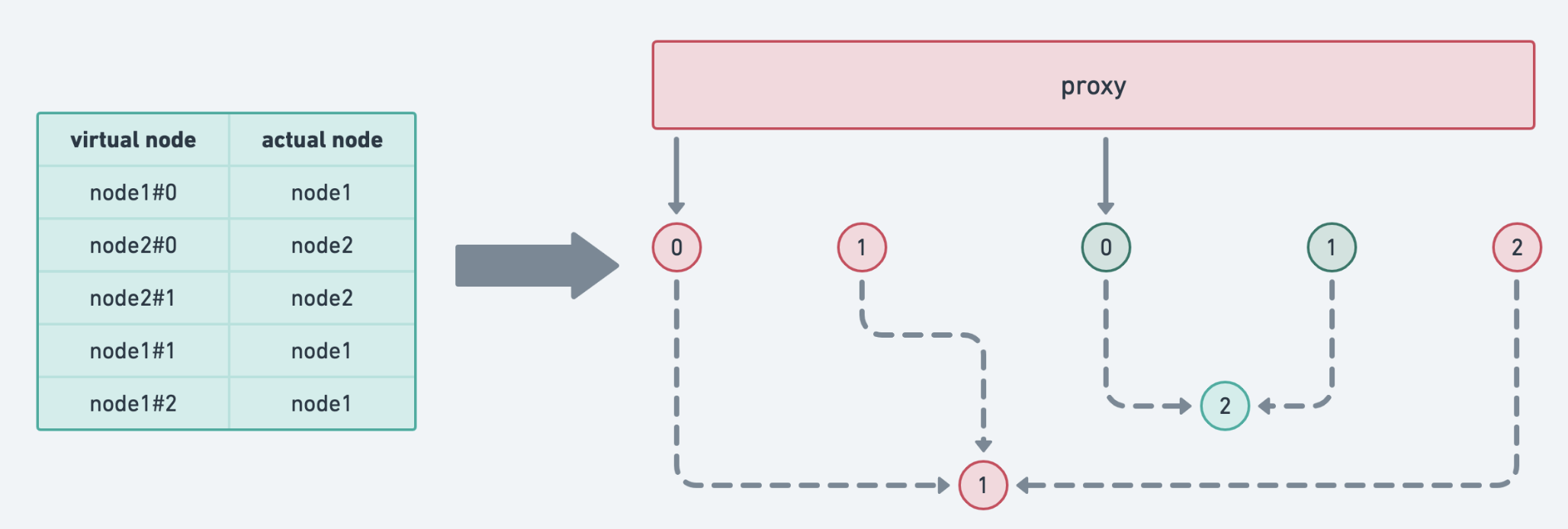
先来看看 Get():
Get
![]()
先说说实现的原理:
- 计算
key 的hash
- 找到第一个匹配的
virtual node 的 index,并取到对应的 h.keys[index] :virtual node hash 值
- 对应到这个
ring 中去寻找一个与之匹配的 actual node
其实我们可以看到 ring 中获取到的是一个 []node 。这是因为在计算 virtual node hash ,可能会发生hash冲突,不同的 virtual node hash 对应到一个实际node。
这也说明:node 与 virtual node 是一对多的关系。而里面的 ring 就是下面这个设计:
![]()
这个其实也就表明了一致性hash的分配策略:
virtual node 作为值域划分。key 去获取 node ,从划分依据上是以 virtual node 作为边界virtual node 通过 hash ,在对应关系上保证了不同的 node 分配的key是大致均匀的。也就是 打散绑定- 加入一个新的 node,会对应分配多个
virtual node。新节点可以负载多个原有节点的压力,从全局看,较容易实现扩容时的负载均衡。
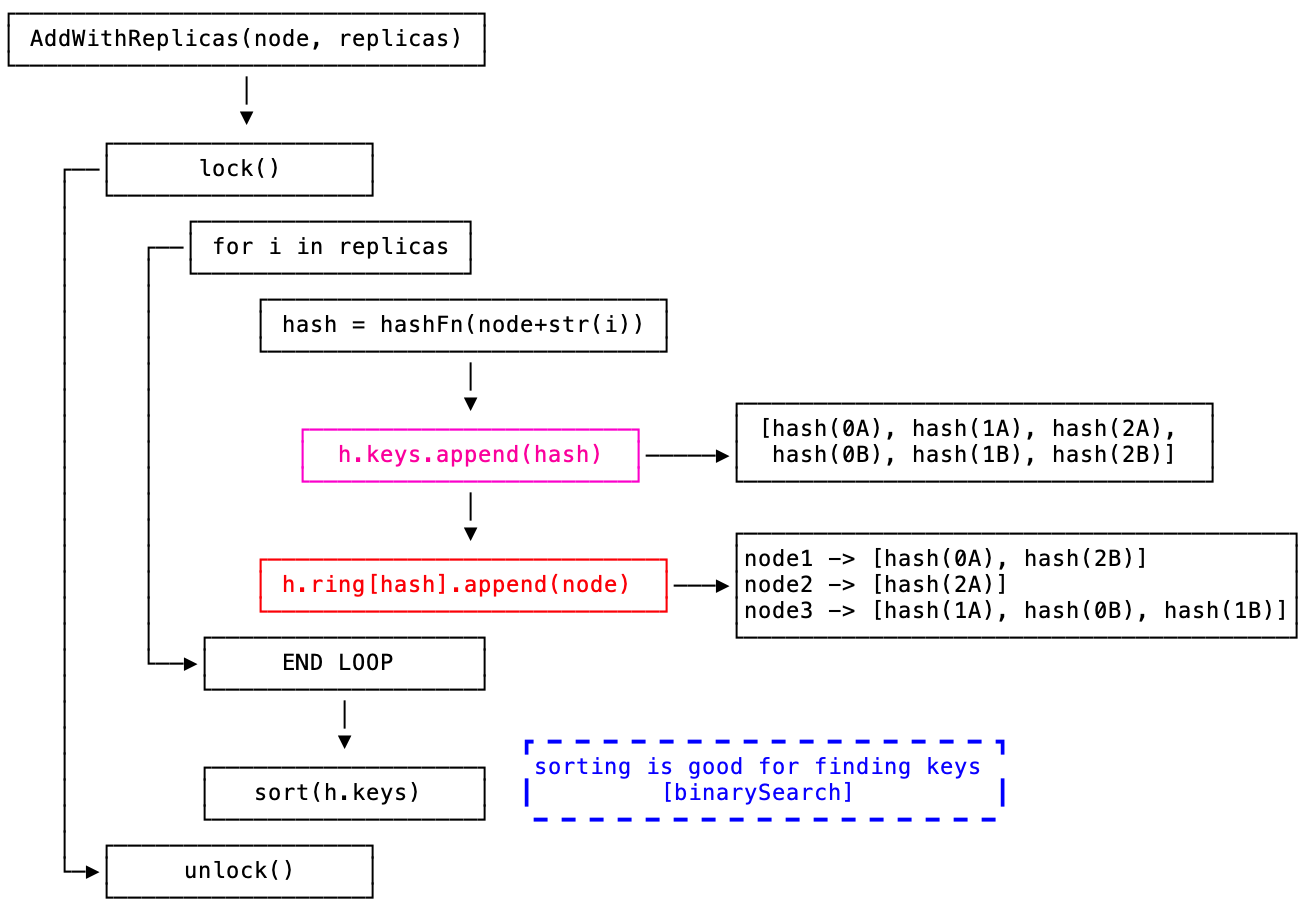
Add Node
![]()
看完 Get 其实大致就知道整个一致性hash的设计:
type ConsistentHash struct {
hashFunc Func // hash 函数
replicas int // 虚拟节点放大因子
keys []uint64 // 存储虚拟节点hash
ring map[uint64][]interface{} // 虚拟节点与实际node的对应关系
nodes map[string]lang.PlaceholderType // 实际节点存储【便于快速查找,所以使用map】
lock sync.RWMutex
}
好了这样,基本的一个一致性hash就实现完备了。
> 具体代码:https://github.com/tal-tech/go-zero/blob/master/core/hash/consistenthash.go
使用场景
开头其实就说了,一致性hash可以广泛使用在分布式系统中:
- 分布式缓存。可以在
redis cluster 这种存储系统上构建一个 cache proxy,自由控制路由。而这个路由规则就可以使用一致性hash算法
- 服务发现
- 分布式调度任务
以上这些分布式系统中,都可以在负载均衡模块中使用。
项目地址
https://github.com/tal-tech/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
一致性hash
在 go-zero 的分布式缓存系统分享里,Kevin 重点讲到过一致性hash的原理和分布式缓存中的实践。本文来详细讲讲一致性hash的原理和在 go-zero 中的实现。
以存储为例,在整个微服务系统中,我们的存储不可能说只是一个单节点。
- 一是为了提高稳定,单节点宕机情况下,整个存储就面临服务不可用;
- 二是数据容错,同样单节点数据物理损毁,而多节点情况下,节点有备份,除非互为备份的节点同时损毁。
那么问题来了,多节点情况下,数据应该写入哪个节点呢?
hash
![]()
所以本质来讲:我们需要一个可以将输入值“压缩”并转成更小的值,这个值通常状况下是唯一、格式极其紧凑的,比如uint64:
- 幂等:每次用同一个值去计算 hash 必须保证都能得到同一个值
这个就是 hash 算法完成的。
但是采取普通的 hash 算法进行路由,如:key % N 。有一个节点由于异常退出了集群或者是心跳异常,这时再进行 hash route ,会造成大量的数据重新 分发到不同的节点 。节点在接受新的请求时候,需要重新处理获取数据的逻辑:如果是在缓存中,容易引起 缓存雪崩。
此时就需要引入 consistent hash 算法了。
consistent hash
我们来看看 consistent hash 是怎么解决这些问题的:
rehash
先解决大量 rehash 的问题:
![]()
如上图,当加入一个新的节点时,影响的key只有 key31,新加入(剔除)节点后,只会影响该节点附近的数据。其他节点的数据不会收到影响,从而解决了节点变化的问题。
这个正是:单调性。这也是 normal hash 算法无法满足分布式场景的原因。
数据倾斜
其实上图可以看出:目前多数的key都集中在 node 1 上。如果当 node 数量比较少的情况下,可以回引发多数 key 集中在某个 node 上,监控时发现的问题就是:节点之间负载不均。
为了解决这个问题,consistent hash 引入了 virtual node 的概念。
既然是负载不均,我们就人为地构造一个均衡的场景出来,但是实际 node 只有这么多。所以就使用 virtual node 划分区域,而实际服务的节点依然是之前的 node。
具体实现
先来看看 Get():
Get
![]()
先说说实现的原理:
- 计算
key 的hash
- 找到第一个匹配的
virtual node 的 index,并取到对应的 h.keys[index] :virtual node hash 值
- 对应到这个
ring 中去寻找一个与之匹配的 actual node
其实我们可以看到 ring 中获取到的是一个 []node 。这是因为在计算 virtual node hash ,可能会发生hash冲突,不同的 virtual node hash 对应到一个实际node。
这也说明:node 与 virtual node 是一对多的关系。而里面的 ring 就是下面这个设计:
![]()
这个其实也就表明了一致性hash的分配策略:
virtual node 作为值域划分。key 去获取 node ,从划分依据上是以 virtual node 作为边界virtual node 通过 hash ,在对应关系上保证了不同的 node 分配的key是大致均匀的。也就是 打散绑定- 加入一个新的 node,会对应分配多个
virtual node。新节点可以负载多个原有节点的压力,从全局看,较容易实现扩容时的负载均衡。
Add Node
![]()
看完 Get 其实大致就知道整个一致性hash的设计:
type ConsistentHash struct {
hashFunc Func // hash 函数
replicas int // 虚拟节点放大因子
keys []uint64 // 存储虚拟节点hash
ring map[uint64][]interface{} // 虚拟节点与实际node的对应关系
nodes map[string]lang.PlaceholderType // 实际节点存储【便于快速查找,所以使用map】
lock sync.RWMutex
}
好了这样,基本的一个一致性hash就实现完备了。
> 具体代码:https://github.com/tal-tech/go-zero/blob/master/core/hash/consistenthash.go
使用场景
开头其实就说了,一致性hash可以广泛使用在分布式系统中:
- 分布式缓存。可以在
redis cluster 这种存储系统上构建一个 cache proxy,自由控制路由。而这个路由规则就可以使用一致性hash算法
- 服务发现
- 分布式调度任务
以上这些分布式系统中,都可以在负载均衡模块中使用。
项目地址
https://github.com/tal-tech/go-zero
https://gitee.com/kevwan/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。