Tapdata 是由深圳钛铂数据有限公司研发的一款实时数据处理及服务的平台产品,企业可以使用 Tapdata 快速构建数据中台和实时数仓, Tapdata 提供了一站式的解决方案,包括实时数据采集、数据融合以及数据发布等功能和能力。
Tapdata 专注于实时数据的处理技术,在数据库迁移和同步方面,Tapdata 的表现非常优秀,实时、多元、异构,尤其在关系数据库到非关系数据库之间的双向同步方面,无论是从操作上,还是效率上,都体现了业界领先的水平。
本文重点阐述 Tapdata 在数据库实时同步方面的技术要点。
基于数据库日志的实时迁移或同步
在数据库同步场景下,Tapdata 支持批量及增量的数据迁移及同步。Tapdata 主打的是实时场景,所以在数据库增量同步上是一个关键能力。目前 Tapdata 支持的数据源,基本上都支持增量同步。大部分场景下 Tapdata 通过解析数据库日志的方式来获得源端数据库的增删改操作,然后将这些操作转化为标准的数据库事件,推送到内部处理队列。![]()
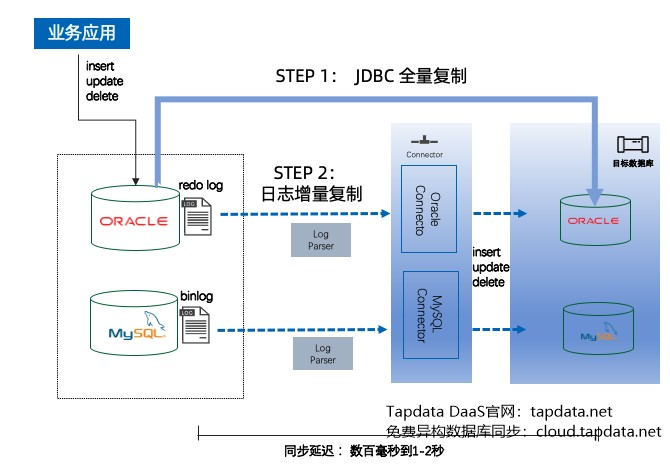
数据同步流程 那么,Tapdata 是怎么样来做数据同步的呢?
第一层的数据同步是基于CDC机制,也就是说它并不是用一个 Select 语句去定期的去扫最近有什么样的数据,或者是全量把它拿过来,而是基于数据库的事务日志,比如说 Oracle 的话就是 Redo log,SQL Server 的话就是它的 CDC 机制,MongoDB 有它的那个 Oplog,然后MySQL 的话就用它的 Binlog。为了监听这些 log 日志,Tapdata 每一个数据都有一个 log parser,把它拿出来以后,当监听到变化,就会把它转化成一个 update 语句或者 insret 的语句或者 delete 语句。在目标库里面,Tapdata 还创建了 FDM ,即基础层和主数据层。把它写到目标库里面,然后通过这种方式,等于是在目标平台里面建了一个逻辑的镜像,跟源库是是能保持高度的同步的那这种方式,这种 CDC 事件的延迟一般是在几百毫秒,往往在1~2秒之内,我们就可以把数据同步到这个目标的平台,所以同步的时延是非常短的,大概率是亚秒级别。
以下是各个数据库的采集增量数据的方式
- Oracle: 通过LogMiner 对redo log/archive log解析数据库日志
- SQLServer: 通过SQLServer自带的触发器方式获取数据库事件
- MySQL: 通过解析binlog方式来获取数据库事件
- MongoDB: 通过解析Oplog方式来获取数据库事件
- DB2: 通过解析DB2日志来获取数据库事件
- PostgreSQL: 通过解析日志方式来获取数据库事件
用户在开始同步任务的时候可以使用以下模式之一:
- 全量迁移,然后紧接着增量迁移
- 仅增量同步,从指定时间点开始
- 仅增量同步,从当前时间开始
基于 Pipeline 的流数据处理模式
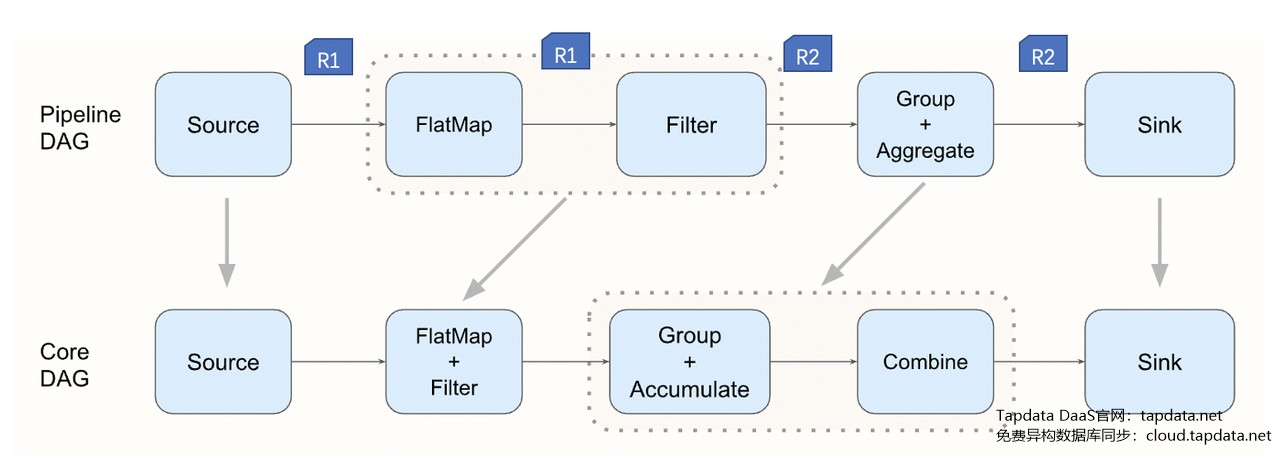
Tapdata 底层使用基于Hazelcast Jet 的 DAG 流处理引擎。该引擎支持基于 DAG(有向无环图)的任务链流计算能力。用户可以通过 Pipeline API 构建一个任务链的处理流程,包括数据源读取,数据处理,过滤,聚合,最后输出到目标 sink。该 Pipeline 会被系统转化为 Core DAG 在流数据处理引擎中执行。如下图所示:![]()
这些 DAG 里面的计算节点都是一个基于记录(原生流),而非基于批的处理。源端每产生一条新的记录(R1),会由数据库采集节点开始得到马上的处理,并随之交到 DAG 的下一个节点。通过结合 JSDK,用户可以按照 DAG 的规则,构建出非常复杂的数据库处理链路,并交给系统的流数据引擎来完成数据的处理。
流处理引擎的计算框架采用协程机制。与传统线程不同,DFS 并不会为每一个数据处理任务起一个单独的线程(线程资源是有限的),而是用一种类似于 Coroutines 的方式,处理任务的执行启停都是由Java端来完成。底层的线程会持续执行, 并不断地将控制交给框架管理程序来协调不同任务之间的计算工作。由于避免了昂贵的线程上下文切换,协程在很多时候可以显著提高处理速度。
Tapdata 流数据处理引擎支持以下Transformation能力(operator):
- map(fn)
- filter(fn)
- mapWithService( serviceFn)
- mapWithCache
- mapWithReplicatedCache
- hashJoin()
- merge()
在实时流数据统计方面,tapdata 可以支持以下时间窗相关的函数:
- aggregate
- groupingKey
- rollingAggregate
- window
- tumblingWindow
- slidingWindow
- sessionWindow
- mapStateful
NoSQL 支持
常见 ETL 工具大部分为针对于关系型数据库如 Oracle、MySQL 等。tapdata 在提供对关系型数据库的支持的基础之上,更提供完善的 NoSQL 支持,如 MongoDB,Elastic Search 以及Redis 等。目前企业的数据同步需求很大一部分是从关系型数据库实时同步到分布式 NoSQL,用来解决关系数据库的查询性能瓶颈及业务创新瓶颈。
Tapdata 的研发团队在处理 NoSQL 上有天然的优势,这跟这个团队成员大部分来自于 MongoDB 原厂、社区代码贡献者有关。
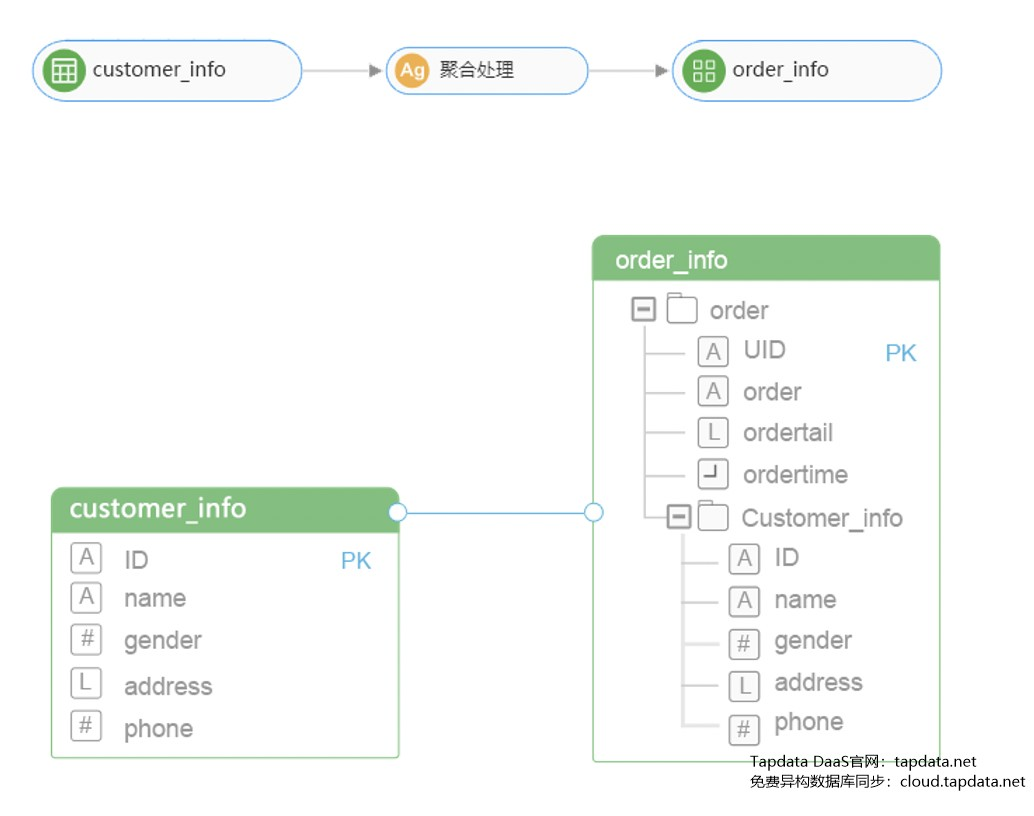
NoSQL 数据库的特点就是文档结构往往基于JSON,一个文档包含了一对多和多对一关系。在同步的时候需要从多个表按照相应的关系写入到目标 JSON,并且还需要在源表子表更新时同步更新目标JSON的子文档,如下图所示。![]()
Tapdata 支持以下高级 JSON 同步特性:
- 一对一合并同步更新
- 多对一合并同步更新
- 一对多合并同步更新
数据校验、增量校验
数据校验是任何涉及到数据同步或者迁移工具的必备功能。完善的校验能力可以给用户足够的信心来使用数据同步工具。
Tapdata 的校验数据类型包含以下:
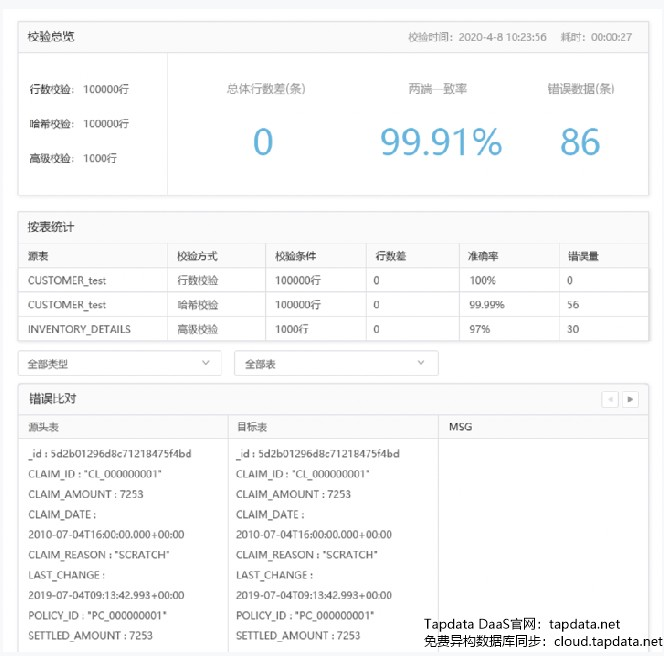
Tapdata 校验采用 Merge Sort 方式实现,可以快速完成对大数据表的迁移同步校验工作。测试表明对一个 5000 万行的表,只需要不到 2 分钟左右就可以完成一次全量校验。校验结果分析包括一致率,错误数据比对等。![]()
此外,Tapdata 支持独创的增量校验功能。用户启动对指定的数据同步任务的增量校验功能以后,Tapdata 将对需要校验的表的 CDC 事件单独记录到一个缓存区,并启动一个后台线程,按照用户指定的检验策略,对缓存区的新增 CDC 事件进行解析。解析的时候会根据源表的DDL 获取主键信息,然后依次查询到目标和源表的数据进行比对。
容错机制
Tapdata 提供一下在部署上提供高可用机制以及在数据写入上提供幂等性操作来保证在错误状态下,任务可以持续运行并且数据可以获得最终一致。
每一个数据处理任务在运行的时候会频繁的向管理端汇报健康状况(每 5 秒一次)。如果管理端在一分钟之内没有收到汇报,则认为该处理节点已经离线。此时另一个存活节点会检查到这个没有心跳的任务,并将其接管过来。
每一个数据处理任务会在运行的时候频繁记录当前处理流的位置。当任务重新开启的时候,会自动从该位置从新开始。
为实现上述的容错机制,Tapdata 要求源端和目标端满足以下条件:
- 源端保留足够长时间的操作日志(通常 1 天以上)
- 目标端支持幂等性操作或能够参与分步式二阶段事务
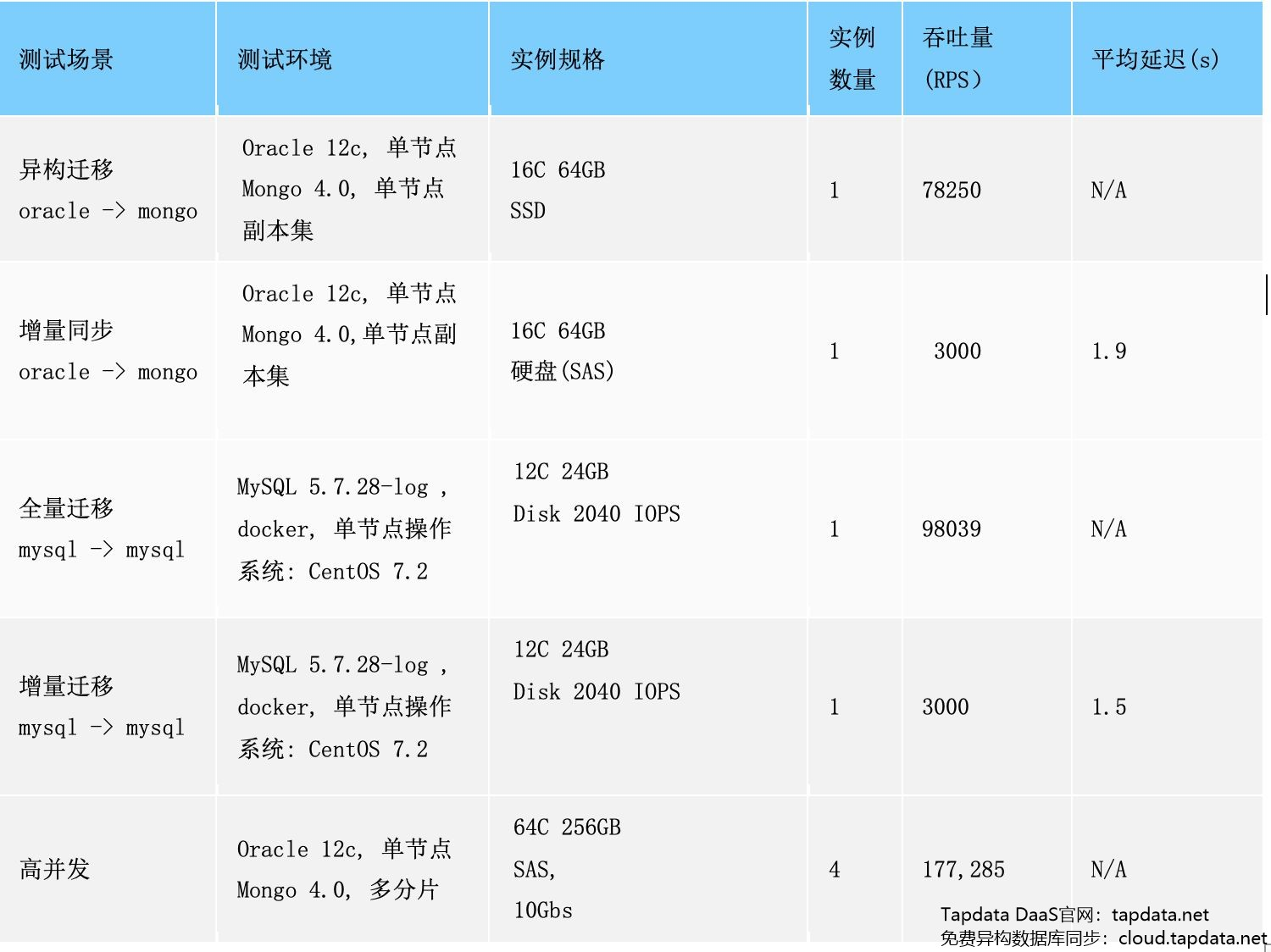
附性能参数
![]()
Tapdata 是一个企业级的商业产品,数据实时同步和迁移只是其中一部分的功能,想了解产品的更多内容,可以访问官网,提交测试申请可以获得运行的demo。
官网地址: https://www.tapdata.net/
此外, Tapdata 还推出了异构数据实时同步的云服务,登录云服务平台,只需要简单三步操作,即可实现数据实时同步,更令人兴奋的是,该功能是免费使用的。
云服务平台:https://cloud.tapdata.net/