![]()
Node.js被设计用来做快速高效的网络I/O。它的事件驱动流使其成为一种智能代理的理想选择,通常作为后端系统和前端之间的粘合剂。Node的设计初衷就是为了实现这一目的,但与此同时,它已成功用于构建传统的Web应用程序:一个HTTP服务器,提供为HTML页面或JSON消息响应,并使用数据库存储数据。
尽管其他平台和语言有比较成熟的Web框架并更倾向于使用开源关系型数据库,如MySQL或PostgreSQL,大多数Node Web框架(如Express、Hapi等)并不强制使用任何特定的数据库,甚至根本不强制使用任何类型的数据库。昨天在《浅谈前端异常监控平台实现方案》一文中就提到LevelDB,今天跟大家介绍这个超高性能的Key-Value数据库LevelDB,同类型的比较流行的有MongoDB,本文暂不介绍MongoDB。
认识LevelDB
LevelDB是Google传奇工程师Jeff Dean和Sanjay Ghemawat开源的一款超高性能Key-Value存储引擎,以其惊人的读性能和更加惊人的写性能在轻量级NoSql数据库中鹤立鸡群,此开源项目目前是支持处理十亿级别规模Key-Value型数据持久性存储的C++ 程序库。在优秀的表现下对于内存的占用也非常小,大量数据都直接存储在磁盘上,可以理解为以空间换取时间。
设计思路
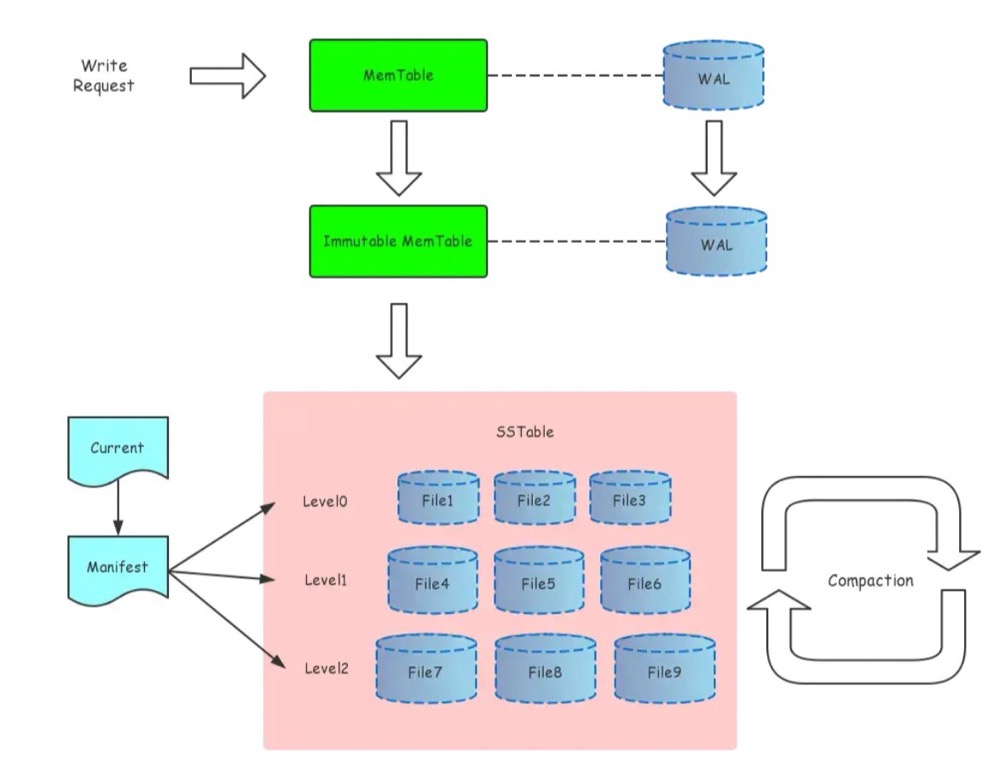
对于普通机械磁盘顺序写的性能要比随机写高很多,而LevelDB的设计思想正是利用了磁盘的这个特性。 LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。为了做到这一点LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,共同维护一个有序的key空间。写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有顺序写。如下图所示:
![]()
上图为 LevelDB 整体架构,静态结构主要由六个部分组成:
MemTable(wTable):内存数据结构,具体实现是 SkipList。 接受用户的读写请求,新的数据修改会首先在这里写入。Immutable MemTable(rTable):当 MemTable 的大小达到设定的阈值时,会变成 Immutable MemTable,只接受读操作,不再接受写操作,后续由后台线程 Flush 到磁盘上。SST Files:Sorted String Table Files,磁盘数据存储文件。分为 Level0 到 LevelN 多层,每一层包含多个 SST 文件,文件内数据有序。Level0 直接由 Immutable Memtable Flush 得到,其它每一层的数据由上一层进行 Compaction 得到。Manifest Files:Manifest 文件中记录 SST 文件在不同 Level 的分布,单个 SST 文件的最大、最小 key,以及其他一些 LevelDB 需要的元信息。由于 LevelDB 支持 snapshot,需要维护多版本,因此可能同时存在多个 Manifest 文件。Current File:由于 Manifest 文件可能存在多个,Current 记录的是当前的 Manifest 文件名。Log Files (WAL):用于防止 MemTable 丢数据的日志文件。
粗箭头表示写入数据的流动方向:
- 先写入 MemTable。
- MemTable 的大小达到设定阈值的时候,转换成 Immutable MemTable。
- Immutable Table 由后台线程异步 Flush 到磁盘上,成为 Level0 上的一个 sst 文件。
- 在某些条件下,会触发后台线程对 Level0 ~ LevelN 的文件进行 Compaction。
读操作的流动方向和写操作类似:
- 读 MemTable,如果存在,返回。
- 读 Immutable MemTable,如果存在,返回。
- 按顺序读 Level0 ~ Leveln,如果存在,返回。
- 返回不存在。
上面就是简单的介绍 LevelDB 的设计原理,架构和读写操作的数据流向,因为独特的设计原理,LevelDB很适合查询较少,写操作很多的场景。如果需要进一步了解其设计原理,就需要去学习跳跃表的设计算法,这里就不展开了。
跳跃表是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳跃表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳跃表的插入和删除的工作是比较简单的。
LevelDB特征:
- key和value都是任意长度的字节数组;
- 存储按键排序的数据;
- 提供基本的
put(key, value)、get(key)和delete(key)接口;
- 支持批量操作以原子操作进行;
- 可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
- 可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
- 自动使用Snappy压缩数据;
- 可移植性;
基于以上特性,很多区块链项目都是采用LevelDB来作为数据存储。下面就开始介绍如何在项目中使用LevelDB,本文涉及的代码在项目Pretender-Service。
安装LevelDB
项目是基于Node.js,基础环境就需要自己配置一下。执行一下命令:
npm install level --save
复制代码
接下来还需要安装level-sublevel,为了方便更好的使用LevelDB,不用自己设计分键空间。
npm install level-sublevel --save
复制代码
还需要为数据生成唯一ID的模块,这里我们安装 cuid。
npm install cuid --save
复制代码
安装完成后,将在应用程序中使用它,创建一个levelDb的类 ./src/db/levelDb.js :
添加引用的依赖库
const level = require("level");
const sublevel = require("level-sublevel");
复制代码
在构造函数中声明两个变量,代码如下:
class LevelDb {
constructor(dbPath, options = {}) {
this.options = options;
this.db = sublevel(level(dbPath, { valueEncoding: "json" }));
}
}
module.exports = LevelDb;
复制代码
在这里,创建了一个导出LevelDB数据库的单例模块。首先需要level模块,并使用它来实例化数据库,并为其提供路径 dbPath 。此路径为 LevelDB 存储数据文件的目录路径。此目录专门用于 LevelDB ,可能在开始时不存在。在这里定义的路径为外部声明的时候传入进来。valueEncoding 定义了使用的值的格式为 json,支持一下格式:hex、utf8、base64、binary、ascii、utf16le。
添加LevelDB操作方法
现在来为上面定义的类增加方法,常用的方法有 put、get、delete、batch、find。本文只是基本的操作,实际项目需要对数据进行合理的设计。
在构造函数中创建了LevelDB数据库对象this.db,可以调用其方法。
put
新增或者更新数据。
put(key, value, callback) {
if (key && value) {
this.db.put(key, value, (error) => {
callback(error);
});
} else {
callback("no key or value");
}
}
复制代码
get
获取指定key的数据。
get(key, callback) {
if (key) {
this.db.get(key, (error, value) => {
callback(error, value);
});
} else {
callback("no key", key);
}
}
复制代码
delete
删除指定key的数据
delete(key, callback) {
if (key) {
this.db.del(key, (error) => {
callback(error);
});
} else {
callback("no key");
}
}
复制代码
batch
LeveLDB的一个强大功能是,它允许对要自动执行的批处理中的操作进行分组。
batch(arr, callback) {
if (Array.isArray(arr)) {
var batchList = [];
arr.forEach(item);
{
var listMember = {};
if (item.hasOwnProperty("type")) {
listMember.type = item.type;
}
if (item.hasOwnProperty("key")) {
listMember.key = item.key;
}
if (item.hasOwnProperty("value")) {
listMember.value = item.value;
}
if (
listMember.hasOwnProperty("type") &&
listMember.hasOwnProperty("key") &&
listMember.hasOwnProperty("value")
) {
batchList.push(listMember);
}
}
if (batchList && batchList.length > 0) {
this.db.batch(batchList, (error) => {
callback(error, batchList);
});
} else {
callback("array Membre format error");
}
} else {
callback("not array");
}
}
复制代码
到这里已经完成一个 LevelDB 基础操作类,下面就开始将其应用于项目中。
使用LevelDB
接下来创建一个examples的文件夹,增加文件index.js,key-value数据库存储和关系型数据库有所不一样,关系型数据库每条记录一般都有一个唯一的自增长id,而key-value数据库需要自己维护一个类似id的唯一key值,这个key值的设计也影响数据查询是否遍历。这里我们只是做一个简单的实例,完整代码如下:
"use strict";
require("../src/utils/logger.js")(2);
const { dbConfig } = require("../config");
const LevelDB = require("../src/db/levelDb");
const path = require("path");
const cuid = require("cuid");
const dbHelper = new LevelDB(
path.resolve(__dirname, dbConfig.path, dbConfig.folder)
);
// 增加用户信息
const administrators = [
{
name: "QuintionTang",
email: "QuintionTang@gmail.com",
password: "123456",
id: "ckoyhjqbj0000mzkd1o63e31p",
},
{
name: "JimGreen",
email: "JimGreen@gmail.com",
password: "123456",
id: "ckoyhjqbk0001mzkdhuq9abo4",
},
];
const keyPrefix = "administrator";
console.info("====>开始插入数据");
const administratorsKeys = [];
for (const item of administrators) {
const uid = item.id;
const keyName = `${keyPrefix}_${uid}`;
item.id = uid;
dbHelper.put(keyName, item, (error) => {
if (error !== null) {
administratorsKeys.push(keyName);
}
});
}
console.info("====>开始查找数据");
// 开始查找uid为 ckoyhjqbj0000mzkd1o63e31p 的用户信息
const findUid = "ckoyhjqbj0000mzkd1o63e31p";
const findKeyName = `${keyPrefix}_${findUid}`;
dbHelper.find(
{
prefix: findKeyName,
},
(error, result) => {
console.info(result);
}
);
复制代码
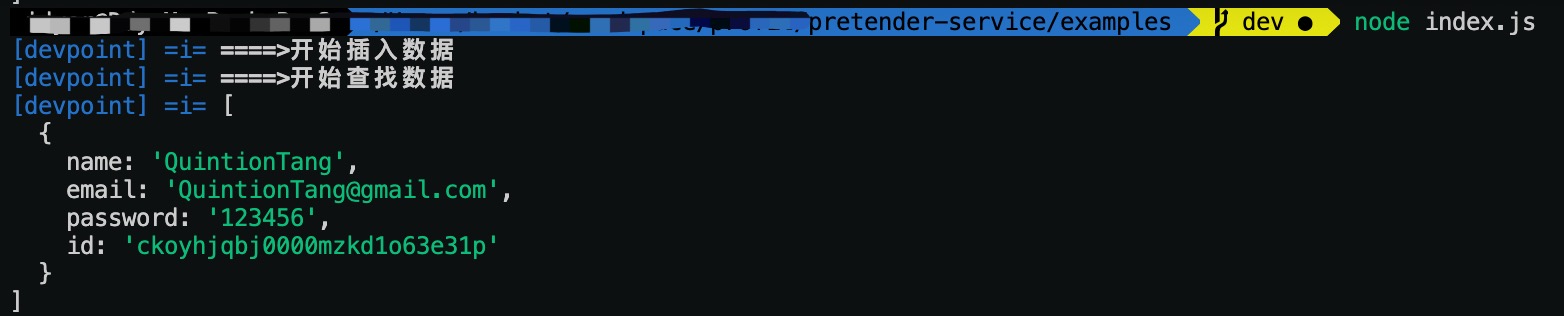
接下来执行实例代码:
cd examples
node index.js
复制代码
执行结果如下:
![]()
此时查看根目录下 database 就会生成数据库文件。
总结
本文简单介绍了LevelDB的设计原理,在项目中完成LevelDB类的定义,并实现一个简单的数据插入和查询。后续会在项目Pretender-Service完成更加复杂的业务逻辑,实现基本的CURD,敬请关注项目动态。