hi, 大家好,我是 haohongfan。
sync.Pool 应该是 Go 里面明星级别的数据结构,有很多优秀的文章都在介绍这个结构,本篇文章简单剖析下 sync.Pool。不过说实话 sync.Pool 并不是我们日常开发中使用频率很高的的并发原语。
尽管用的频率很低,但是不可否认的是 sync.Pool 确实是 Go 的杀手锏,合理使用 sync.Pool 会让我们的程序性能飙升。本篇文章会从使用方式,源码剖析,运用场景等方面,让你对 sync.Pool 有一个清晰的认知。
使用方式
sync.Pool 使用很简单,但是想用对却很麻烦,因为你有可能看到网上一堆错误的示例,各位同学在搜索 sync.Pool 的使用例子时,要特别注意。
sync.Pool 是一个内存池。通常内存池是用来防止内存泄露的(例如C/C++)。sync.Pool 这个内存池却不是干这个的,带 GC 功能的语言都存在垃圾回收 STW 问题,需要回收的内存块越多,STW 持续时间就越长。如果能让 new 出来的变量,一直不被回收,得到重复利用,是不是就减轻了 GC 的压力。
正确的使用示例(下面的demo选自gin)
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c)
engine.pool.Put(c)
}
一定要注意的是:是先 Get 获取内存空间,基于这个内存做相关的处理,然后再将这个内存还回(Put)到 sync.Pool。
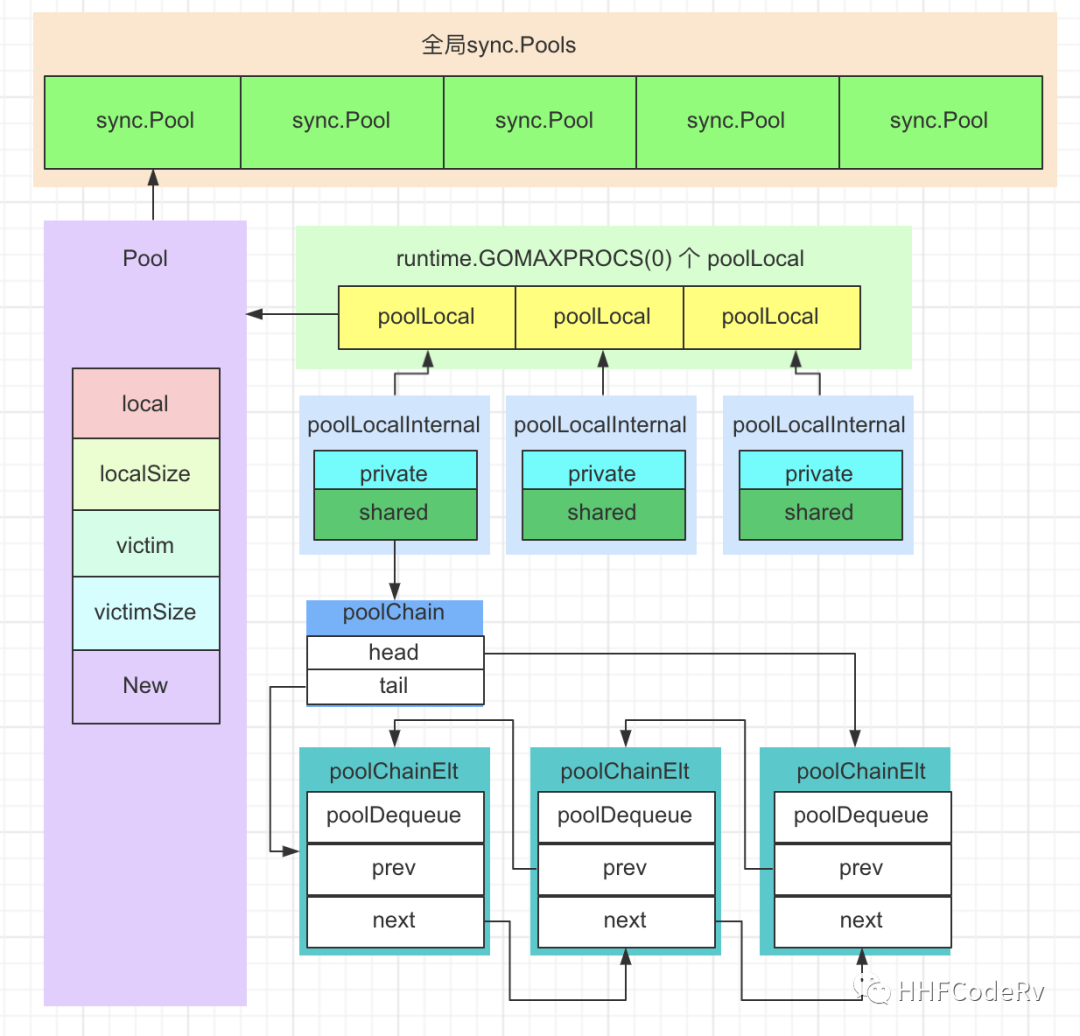
Pool 结构
![]()
sync.Pool 全景图
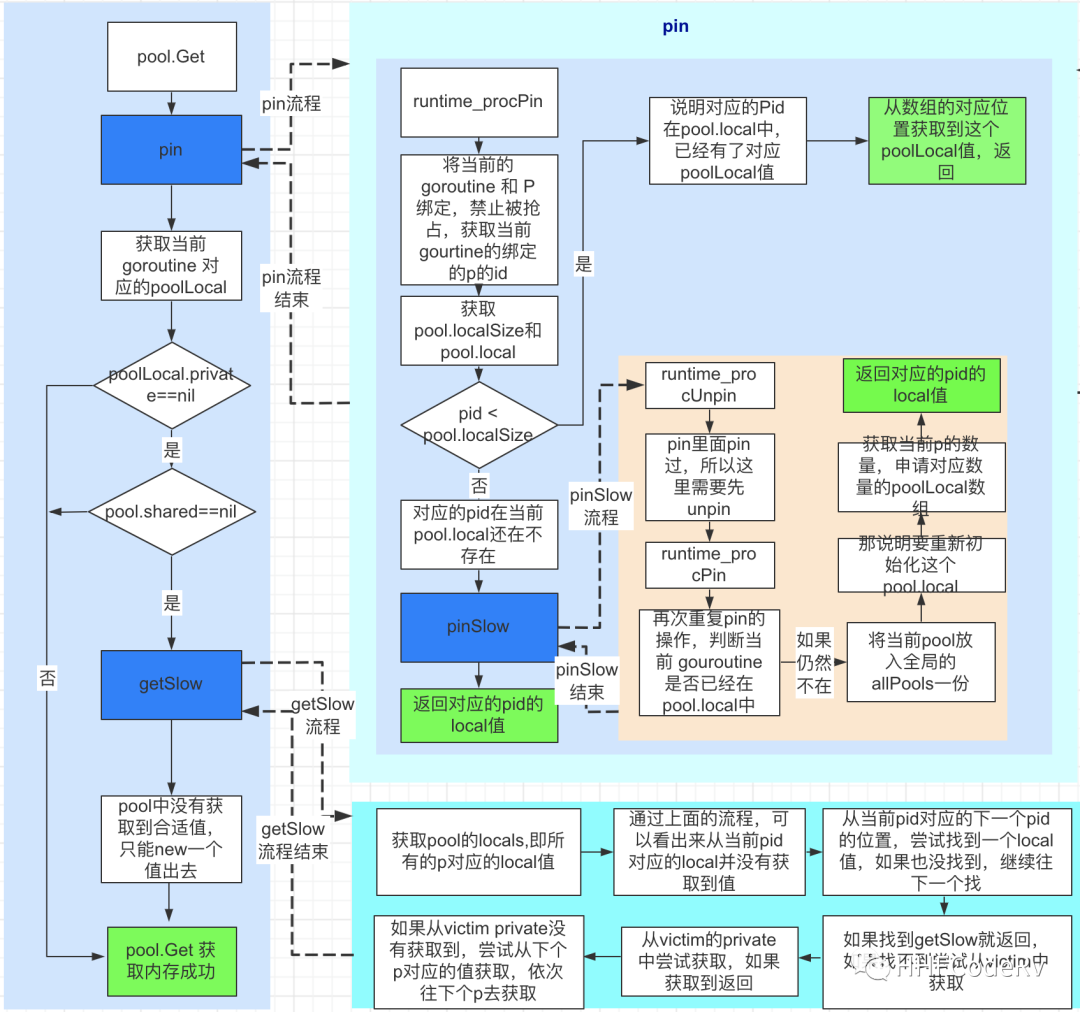
源码图解
![]()
Pool.Get
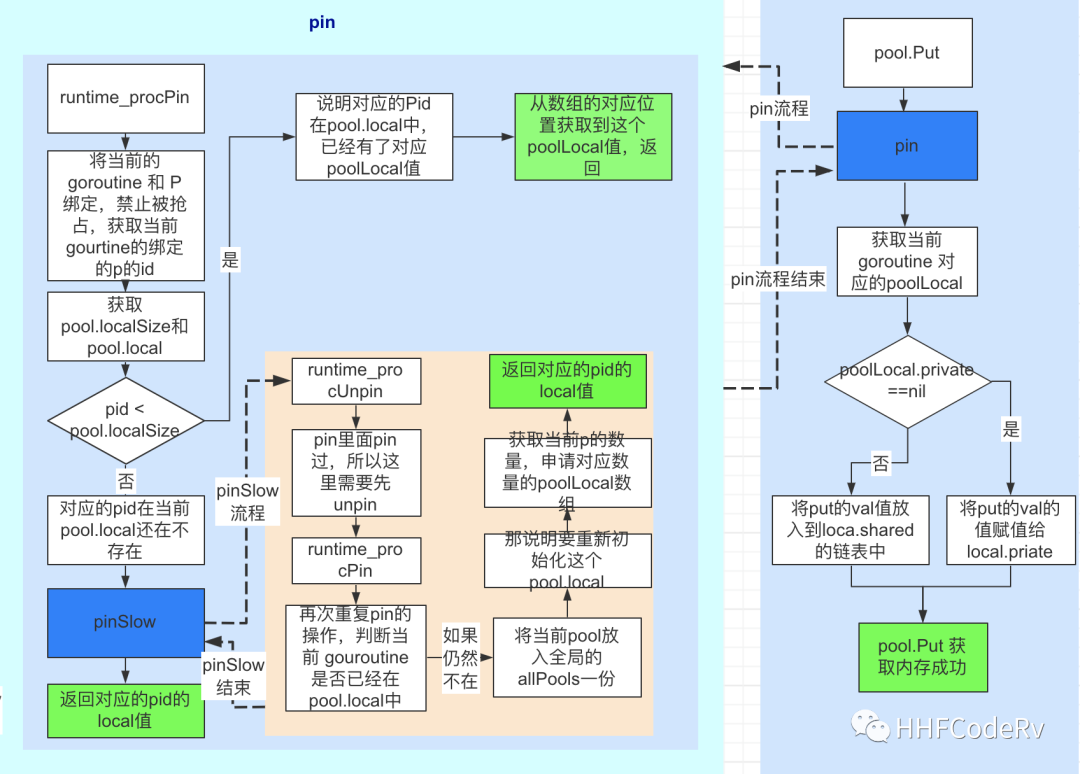
![]()
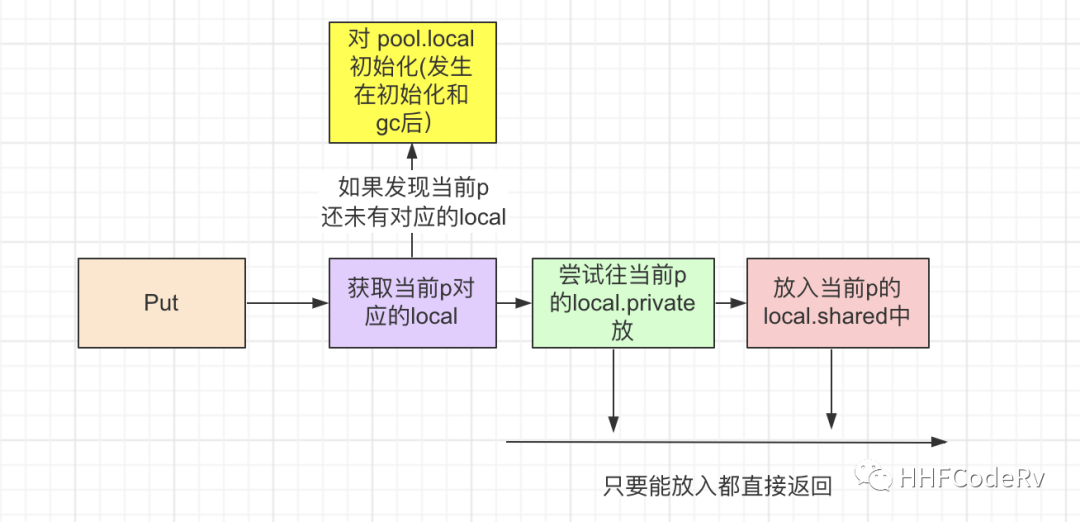
Pool.Put
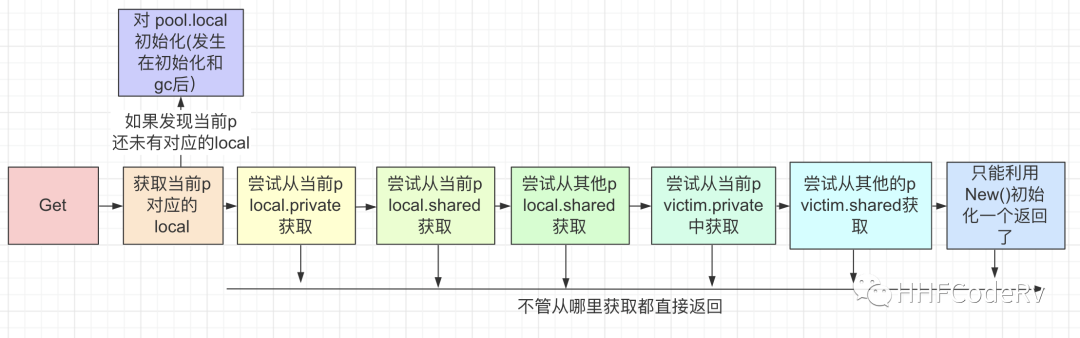
简单点可以总结成下面的流程:
![]()
Pool.Get 流程
![]()
Pool.Put流程
![]()
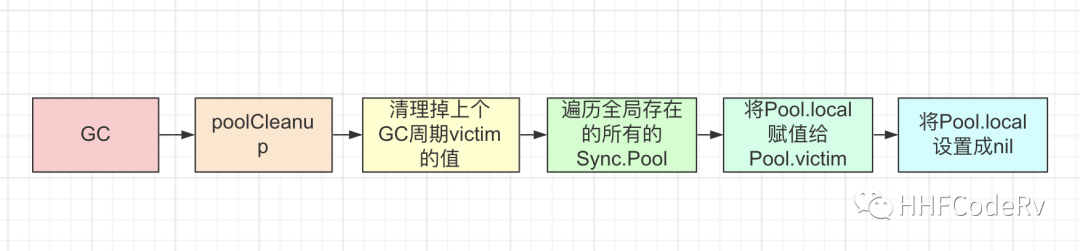
Pool GC 流程
Sync.Pool 梳理
Pool 的内容会清理?清理会造成数据丢失吗?
Go 会在每个 GC 周期内定期清理 sync.Pool 内的数据。
要分几个方面来说这个问题。
-
已经从 sync.Pool Get 的值,在 poolClean 时虽说将 pool.local 置成了nil,Get 到的值依然是有效的,是被 GC 标记为黑色的,不会被 GC回收,当 Put 后又重新加入到 sync.Pool 中
-
在第一个 GC 周期内 Put 到 sync.Pool 的数值,在第二个 GC 周期没有被 Get 使用,就会被放在 local.victim 中。如果在 第三个 GC 周期仍然没有被使用就会被 GC 回收。
runtime.GOMAXPROCS 与 pool 之间的关系?
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
runtime.GOMAXPROCS(0) 是获取当前最大的 p 的数量。sync.Pool 的 poolLocal 数量受 p 的数量影响,会开辟 runtime.GOMAXPROCS(0) 个 poolLocal。某些场景下我们会使用 runtime.GOMAXPROCS(N) 来改变 p 的数量,会使 sync.Pool 的 pool.poolLocal 释放重新开辟新的空间。
为什么要开辟 runtime.GOMAXPROCS 个 local?
pool.local 是个 poolLocal 结构,这个结构体是 private + shared链表组成,在多 goroutine 的 Get/Put 下是有数据竞争的,如果只有一个 local 就需要加锁来操作。每个 p 的 local 就能减少加锁造成的数据竞争问题。
New() 的作用?假如没有 New 会出现什么情况?
从上面的 pool.Get 流程图可以看出来,从 sync.Pool 获取一个内存会尝试从当前 private,shared,其他的 p 的 shared 获取或者 victim 获取,如果实在获取不到时,才会调用 New 函数来获取。也就是 New() 函数才是真正开辟内存空间的。New() 开辟出来的的内存空间使用完毕后,调用 pool.Put 函数放入到 sync.Pool 中被重复利用。
如果 New 函数没有被初始化会怎样呢?很明显,sync.Pool 就废掉了,因为没有了初始化内存的地方了。
先 Put,再 Get 会出现什么情况?
「一定要注意,下面这个例子的用法是错误的」
func main(){
pool:= sync.Pool{
New: func() interface{} {
return item{}
},
}
pool.Put(item{value:1})
data := pool.Get()
fmt.Println(data)
}
如果你直接跑这个例子,能得到你想像的结果,但是在某些情况下就不是这个结果了。
在 Pool.Get 注释里面有这么一句话:“Callers should not assume any relation between values passed to Put and the values returned by Get.”,告诉我们不能把值 Pool.Put 到 sync.Pool 中,再使用 Pool.Get 取出来,因为 sync.Pool 不是 map 或者 slice,放入的值是有可能拿不到的,sync.Pool 的数据结构就不支持做这个事情。
前面说使用 sync.Pool 容易被错误示例误导,就是上面这个写法。为什么 Put 的值 再 Get 会出现问题?
-
情况1:sync.Pool 的 poolCleanup 函数在系统 GC 时会被调用,Put 到 sync.Pool 的值,由于有可能一直得不到利用,被在某个 GC 周期内就有可能被释放掉了。
-
情况2:不同的 goroutine 绑定的 p 有可能是不一样的,当前 p 对应的 goroutine 放入到 sync.Pool 的值有可能被其他的 p 对应的 goroutine 取到,导致当前 goroutine 再也取不到这个值。
-
情况3:使用 runtime.GOMAXPROCS(N) 来改变 p 的数量,会使 sync.Pool 的 pool.poolLocal 释放重新开辟新的空间,导致 sync.Pool 被释放掉。
-
情况4:还有很多情况
只 Get 不 Put 会内存泄露吗?
使用其他的池,如连接池,如果取连接使用后不放回连接池,就会出现连接池泄露,「是不是 sync.Pool 也有这个问题呢?」
通过上面的流程图,可以看出来 Pool.Get 的时候会尝试从当前 private,shared,其他的 p 的 shared 获取或者 victim 获取,如果实在获取不到时,才会调用 New 函数来获取,New 出来的内容本身还是受系统 GC 来控制的。所以如果我们提供的 New 实现不存在内存泄露的话,那么 sync.Pool 是不会内存泄露的。当 New 出来的变量如果不再被使用,就会被系统 GC 给回收掉。
如果不 Put 回 sync.Pool,会造成 Get 的时候每次都调用的 New 来从堆栈申请空间,达不到减轻 GC 压力。
使用场景
上面说到 sync.Pool 业务开发中不是一个常用结构,我们业务开发中没必要假想某块代码会有强烈的性能问题,一上来就用 sync.Pool 硬怼。sync.Pool 主要是为了解决 Go GC 压力过大问题的,所以一般情况下,当线上高并发业务出现 GC 问题需要被优化时,才需要用 sync.Pool 出场。
使用注意点
-
sync.Pool 同样不能被复制。
-
好的使用习惯,从 pool.Get 出来的值进行数据的清空(reset),防止垃圾数据污染。
❝
本文基于的 Go 源码版本:1.16.2
❞
参考链接
-
深度解密 Go 语言之 sync.Pool https://www.cnblogs.com/qcrao-2018/p/12736031.html
-
请问sync.Pool有什么缺点? https://mp.weixin.qq.com/s/2ZC1BWTylIZMmuQ3HwrnUg
-
Go 1.13中 sync.Pool 是如何优化的? https://colobu.com/2019/10/08/how-is-sync-Pool-improved-in-Go-1-13/
sync.Pool 的剖析到这里基本就写完了,想跟我交流的可以在评论区留言。
sync.Pool 完整流程图获取链接:链接: https://pan.baidu.com/s/1T5e8qCzp8JcTgARZFjGQoQ 密码: ngea 其他模块流程图,请关注公众号回复1获取。学习资料分享,关注公众号回复指令:
-
回复 0,获取 《Go 面经》
-
回复 1,获取 《Go 源码流程图》
![]()