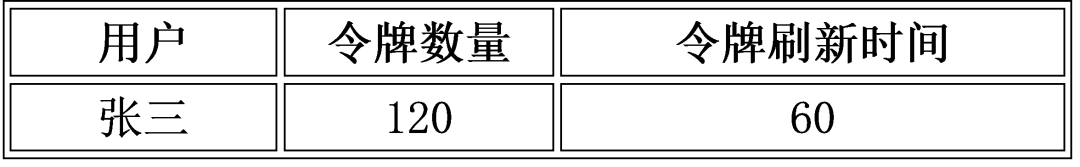![]()
转载本文需注明出处:微信公众号EAWorld,违者必究。
雪崩一词指的是山地积雪由于底部溶解等原因而突然大块塌落的现象,具有很强的破坏力。在系统架构中提到的雪崩,就是由于一台服务器或者一台服务器中的某个模块发生故障进而引起连锁反应,最后导致大量的服务器或者软件模块无法正常工作,这种现象也较做“急剧变化”现象。
在某通信集团统一流程平台项目上线初期就发生过几次服务雪崩的事故,由于业务系统接入持续增多,业务系统的查询请求数量大大高于了前期的设计。当集群中的一台节点宕机下线后,请求压力迅速传导给了整个集群,从而引发了集群整体宕机。
为了保障平台整体能稳定运行,在重新对服务器负载进行估算、增加集群冗余后,项目组增加了在部署架构、压力负载分流方面考虑,以持续提升平台性能。
我们对现有平台集群的逻辑架构进行了调整,将业务访问请求按系统ID分流到各子集群,由各集群分开处理,通过对业务请求的细分,达到子集群隔离,提升系统的稳定性与可扩展性。
具体到实施层面,项目组预备在负载均衡上增加服务网关的功能,使得nginx集群不再单纯的做反向代理,而是扩展为服务网关。
服务网关基于openresty开发,OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
我们在其基础上实现了以下功能:
流量限制:设立限流名单制度,对于非VIP且请求量大的用户进行限流。对名单中用户的请求进行计数,限制用户每分钟的请求次数,避免重复调用或短期内大量无效请求。
请求分域:根据请求来源的租户实现请求分域,将不同的租户请求分发到该租户的专用集群。
健康检查:提供一个简单的查询页面,可以查询当前集群节点的健康状况。
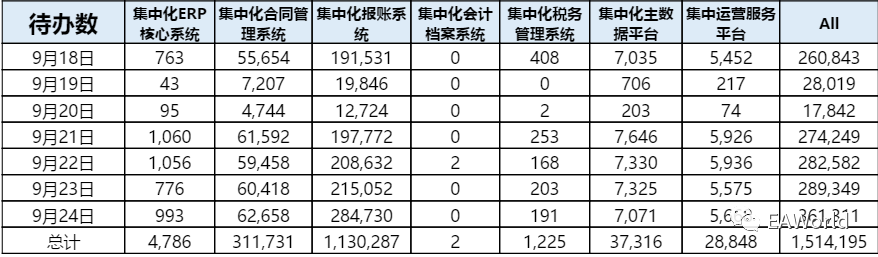
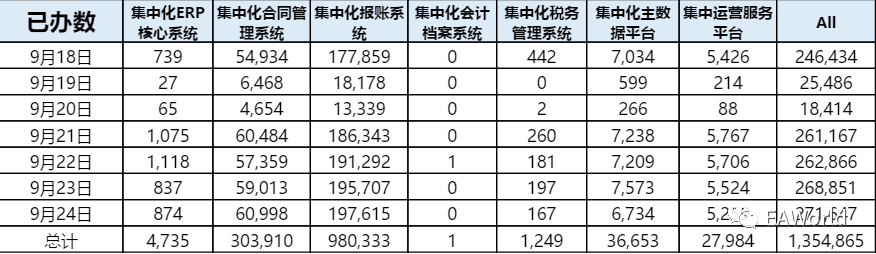
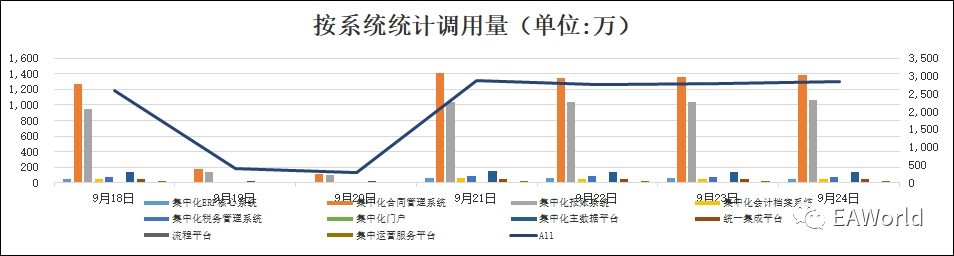
在改造网关之前,我们首先要对集群的物理架构进行调整。通过对统一平台的业务量以及调用量的统计,以及对业务请求的监控我们发现,无论从业务数量以及调用量来看,业务压力主要来自于其中的两个业务系统。
![]()
![]()
![]()
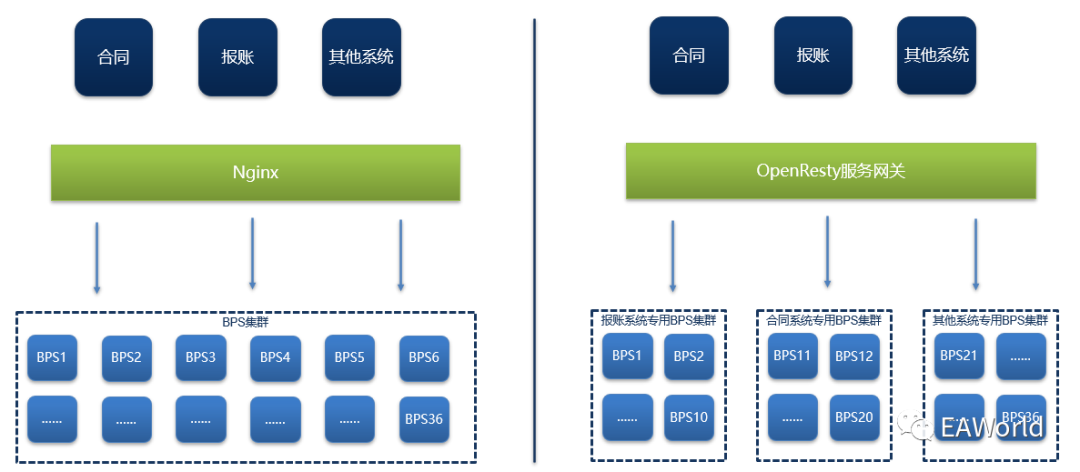
于是我们对现有架构进行了调整,将负载均衡随机分发请求到集群,调整为按系统分发,将一个大集群切割成若干个小集群,按请求所在的系统将请求分发到各自响应的集群中。
![]()
首先我们已经通过调整集群的部署,将集群进行了物理分割,接下来我们只需要将相关系统的请求转发到对应的集群中即可。
首先通过获取每个请求的请求头,来获得该请求的所属系统、所属用户等关键信息。
map $host $fmt_localtime { default '';}map $host $bpm_method { default '';}map $host $bpm_tenantid { default '';}map $host $bpm_province { default '';}map $host $bpm_userid { default '';}map $host $bpm_provinceFlag { default '';}map $host $RequestId { default '';}
(左右滑动查看全部代码)
然后我们在脚本中定义好每个系统的节点地址
#报账upstream bpm_cluster_rbs {server 10.24.20.45:8080;server 10.24.20.46:8080;……server 10.24.20.52:8080; }
#合同upstream bpm_cluster_cms {server 10.24.20.53:8080;……server 10.24.20.60:8080;}
#其他upstream bpm_cluster_other {server 10.24.20.10:8080;……server 10.24.20.16:8080;}
(左右滑动查看全部代码)
最后当收到请求时,将对应请求转发到对应的upstream就可以了
function forwardUpstream(tenantid)if tenantid == "CMS" --对于合同 系统 而且是 查询待办相关操作 then ngx.var.upstream="bpm_cluster_cms" elseif tenantid == "RBS" --对于报账 系统 而且是 查询待办相关操作 then ngx.var.upstream="bpm_cluster_rbs"else ngx.var.upstream="bpm_cluster_other" enden
(左右滑动查看全部代码)
lua-resty-limit-traffic是一个openresty中用于限制和控制流量的Lua库,使用这个库可以方便的对用户、IP进行限流
https://github.com/openresty/lua-resty-limit-traffic
(左右滑动查看全部代码)
lua-resty-limit-traffic模块限流分为两种:
第一种限制某用户每分钟只能调用120次(允许在时间段开始的时候一次性放过120个请求)
local limit_count = require "resty.limit.count"local lim, err = limit_count.new("my_limit_count_store", 120, 60)
(左右滑动查看全部代码)
第二种限制每分钟处理120个请求(平滑处理,每秒钟只放过两个请求)
local limit_req = require "resty.limit.req"local lim, err = limit_req.new("my_limit_req_store", 2, 0)
(左右滑动查看全部代码)
实战中,我们的策略是将流量大的用户加入到限流名单中,名单内的用户会在redis中维护一份配置表,包括
![]()
在请求进来后,我们先从请求头中获取当前请求的用户
map $host $bpm_userid { default '';}
(左右滑动查看全部代码)
然后判断该用户是否在限流名单内,如果确定为限流用户则读取该用户的配置信息
local cache_ngx = ngx.shared.my_ngx_redis_cachelocal user_conf = cache_ngx:get(userid)local redis_josn = cjson.decode(user_conf)local maxReq = redis_josn['maxReq']local nextReqTime = redis_josn['nextReqTime']
(左右滑动查看全部代码)
根据配置调用限流方法,设置某用户每分钟只能调用XX次请求(允许一次性放过)
local limit_count = require "resty.limit.count"local maxReq = redis_josn['maxReq']local nextReqTime = redis_josn['nextReqTime']local lim, err = limit_count.new("my_limit_count_store", maxReq, nextReqTime)if not lim then ngx.log(ngx.ERR, "failed to instantiate a resty.limit.count object: ", err) return ngx.exit(500)endlocal delay, err = lim:incoming(key, true)-- 如果发生错误则返回500,如果请求数超过了 count 限制则返回403if not delay then if err == "rejected" then return ngx.exit(403) end ngx.log(ngx.ERR, "failed to limit count:", err) return ngx.exit(500)end
(左右滑动查看全部代码)
upstream.healthcheck本质上是个定时器,它会定期发送指定的http请求并解析响应码,去探测upstream中每个peer的存活状态,再结合历史请求记录来判断并标记其状态。
模块的源码见下面的页面:
https://github.com/openresty/lua-resty-upstream-healthcheck
(左右滑动查看全部代码)
实战中我们的代码如下:
local ok, err = hc.spawn_checker{ shm = "healthcheck", -- defined by "lua_shared_dict" upstream = "bpm_cluster_rbs", -- defined by "upstream" type = "http", http_req = "GET /default/engineState.jsp HTTP/1.0\r\nHost: bpm_cluster_rbs\r\n\r\n", -- raw HTTP request for checking interval = 2000, -- 每两秒检查一次 timeout = 1000, -- 1 sec is the timeout for network operations fall = 3, -- # 连续3次失败才认定为down rise = 2, -- # 对down状态的节点,连续2次成功认定为UP valid_statuses = {200, 302}, -- 状态正常的code concurrency = 10, -- 检查线程数}
(左右滑动查看全部代码)
![]() 关于作者:李云涛,普元高级开发工程师,擅长性能调优、微服务、容器、消息队列等技术。先后参与邮储银行Java开发平台、中移总ERP流程平台、中煤信息技术中台等平台的的架构设计与平台研发工作。
关于作者:李云涛,普元高级开发工程师,擅长性能调优、微服务、容器、消息队列等技术。先后参与邮储银行Java开发平台、中移总ERP流程平台、中煤信息技术中台等平台的的架构设计与平台研发工作。
![]() 关于EAWorld:使能数字转型,共创数智未来,长按二维码关注!
关于EAWorld:使能数字转型,共创数智未来,长按二维码关注!