
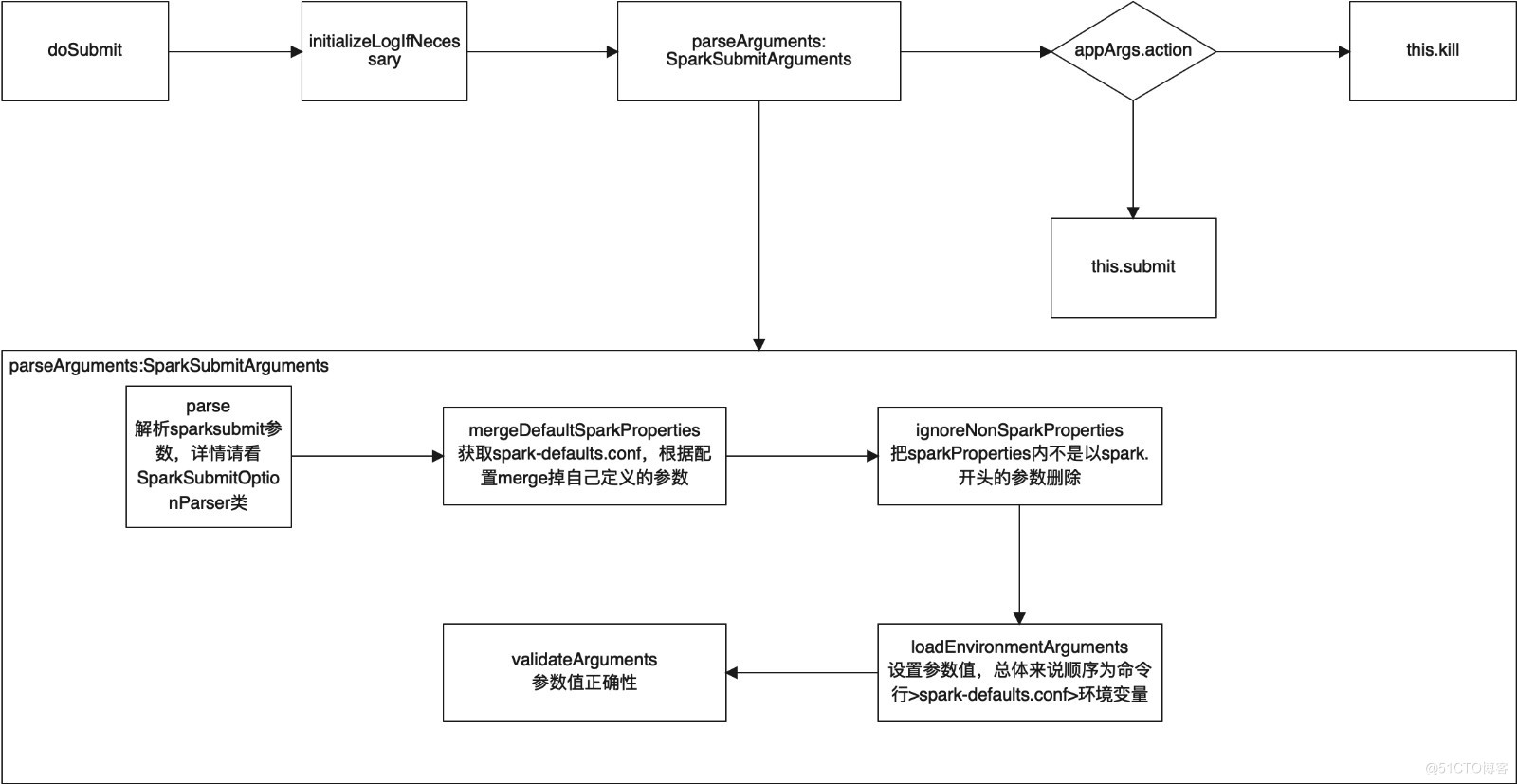

Maven相关知识总结
Maven相关知识总结 目录 认识Maven Maven下载安装 Maven能用来做什么 Maven核心概念 开发目录 坐标和仓库 POM文件 POM文件内容 Maven依赖管理 构建生命周期 构建多模块系统 聚合 继承 聚合与继承 认识Maven Maven是Apache软件基金会组织维护的一款自动化构建工具, 专注于Java平台工程的项目构建和依赖管理:1:项目构建构建不是创建,创建一个工程并不等于构建一个项目,用Maven可以管理项目开发的整个生命周期2:依赖管理管理项目依赖的所有jar文件,Maven项目依赖于一个库,而这个库又依赖其他库,只需要加上直接依赖的库,间接依赖的库也会加入到项目中假设上图,引入spring-mvc后,spring-mvc依赖的spring-core等库也会加入到项目里面 Maven下载安装 Maven 是一个基于 Java 的工具,所以要做的第一件事情就是安装JDK,下载安装只需要把下载的文件解压到指定目录,然后配置环境变量即可:1:准备依赖的JDK2:下载安装3:配置环境变量4:测试是否安装成功环境变量配置:新建系统变量MAVEN_HOME,设置变...