![]()
01 pyspark简介及环境搭建
pyspark是python中的一个第三方库,相当于Apache Spark组件的python化版本(Spark当前支持Java Scala Python和R 4种编程语言接口),需要依赖py4j库(即python for java的缩略词),而恰恰是这个库实现了将python和java的互联,所以pyspark库虽然体积很大,大约226M,但实际上绝大部分都是spark中的原生jar包,占据了217M,体积占比高达96%。
由于Spark是基于Scala语言实现的大数据组件,而Scala语言又是运行在JVM虚拟机上的,所以Spark自然依赖JDK,截止目前为止JDK8依然可用,而且几乎是安装各大数据组件时的首选。所以搭建pyspark环境首先需要安装JDK8,而后这里介绍两种方式搭建pyspark运行环境:
1)pip install pyspark+任意pythonIDE
pyspark作为python的一个第三方库,自然可以通过pip包管理工具进行安装,所以仅需执行如下命令即可完成自动安装:
- pip install pyspark
为了保证更快的下载速度,可以更改pip源为国内镜像,具体设置方式可参考历史文章:是时候总结一波Python环境搭建问题了
2)Spark官网下载指定tar包解压
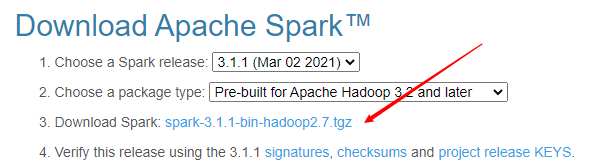
与其他大数据组件不同,Spark实际上提供了windows系统下良好的兼容运行环境,而且方式也非常简单。访问spark官网,选择目标版本(当前最新版本是spark3.1.1版本),点击链接即可跳转到下载页面,不出意外的话会自动推荐国内镜像下载地址,所以下载速度是很有保证的。
![]()
下载完毕后即得到了一个tgz格式的文件,移动至适当目录直接解压即可,而后进入bin目录,选择打开pyspark.cmd,即会自动创建一个pyspark的shell运行环境,整个过程非常简单,无需任何设置。
![]()
进入pyspark环境,已创建好sc和spark两个入口变量
两种pyspark环境搭建方式对比:
- 运行环境不同:pip源安装相当于扩展了python运行库,所以可在任何pythonIDE中引入和使用,更为灵活方便;而spark tar包解压本质上相当于是安装了一个windows系统下的软件,只能通过执行该“软件”的方式进入
- 提供功能不同:pip源安装方式仅限于在python语言下使用,只要可以import pyspark即可;而spark tar包解压,则不仅提供了pyspark入口,其实还提供了spark-shell(scala版本)sparkR等多种cmd执行环境;
- 使用方式不同:pip源安装需要在使用时import相应包,并手动创建sc和spark入口变量;而spark tar包解压进入shell时,会提供已创建好的sc和spark入口变量,更为方便。
总体来看,两种方式各有利弊,如果是进行正式的开发和数据处理流程,个人倾向于选择进入第一种pyspark环境;而对于简单的功能测试,则会优先使用pyspark.cmd环境。
02 三大数据分析工具灵活切换
在日常工作中,我们常常会使用多种工具来实现不同的数据分析需求,比如个人用的最多的还是SQL、Pandas和Spark3大工具,无非就是喜欢SQL的语法简洁易用、Pandas的API丰富多样以及Spark的分布式大数据处理能力,但同时不幸的是这几个工具也都有各自的弱点,比如SQL仅能用于处理一些简单的需求,复杂的逻辑实现不太可能;Pandas只能单机运行、大数据处理乏力;Spark接口又相对比较有限,且有些算子写法会比较复杂。
懒惰是人类进步的阶梯,这个道理在数据处理工具的选择上也有所体现。
希望能在多种工具间灵活切换、自由组合选用,自然是最朴(偷)素(懒)的想法,所幸pyspark刚好能够满足这一需求!以SQL中的数据表、pandas中的DataFrame和spark中的DataFrame三种数据结构为对象,依赖如下几个接口可实现数据在3种工具间的任意切换:
- spark.createDataFrame() # 实现从pd.DataFrame -> spark.DataFrame
- df.toPandas() # 实现从spark.DataFrame -> pd.DataFrame
- df.createOrReplaceTempView() # 实现从spark.DataFrame注册为一个临时SQL表
- spark.sql() # 实现从注册临时表查询得到spark.DataFrame
当然,pandas自然也可以通过pd.read_sql和df.to_sql实现pandas与数据库表的序列化与反序列化,但这里主要是指在内存中的数据结构的任意切换。
![]()
举个小例子:
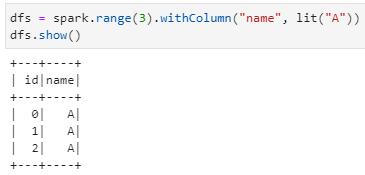
1)spark创建一个DataFrame
![]()
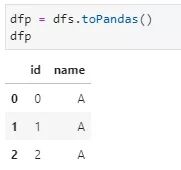
2)spark.DataFrame转换为pd.DataFrame
![]()
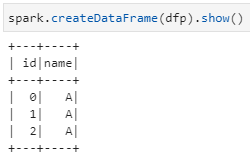
3)pd.DataFrame转换为spark.DataFrame
![]()
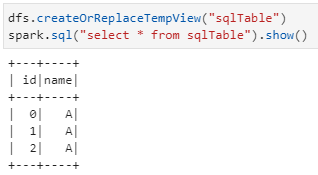
4)spark.DataFrame注册临时数据表并执行SQL查询语句
![]()
畅想一下,可以在三种数据分析工具间任意切换使用了,比如在大数据阶段用Spark,在数据过滤后再用Pandas的丰富API,偶尔再来几句SQL!然而,理想很丰满现实则未然:期间踩坑之深之广,冷暖自知啊……