本文翻译自https://engineering.nanit.com/rabbitmq-retries-the-full-story-ca4cc6c5b493。
RabbitMQ是当今应用最为广泛的一种消息中间件之一。在nanit公司,很多内部服务之间的通信都是基于RabbitMQ,这也导致我们踏上了一条寻找“消息处理失败重试机制最优解决方案”的旅程。
惊讶的是,RabbitMQ自己并没有原生地实现任何重试机制。在这篇博客中,我将探究四种不同的基于RabbitMQ实现重试的方式。针对每一种方式,我们都会go through以下几点:
基于RabbitMQ实现的拓扑图
重试的流程
一个基于ruby实现的代码示例
ruby代码运行的结果
优缺点总结
每个场景的示例代码都可以在Github找到。我强烈推荐大家在阅读本文的过程中运行这些示例代码。
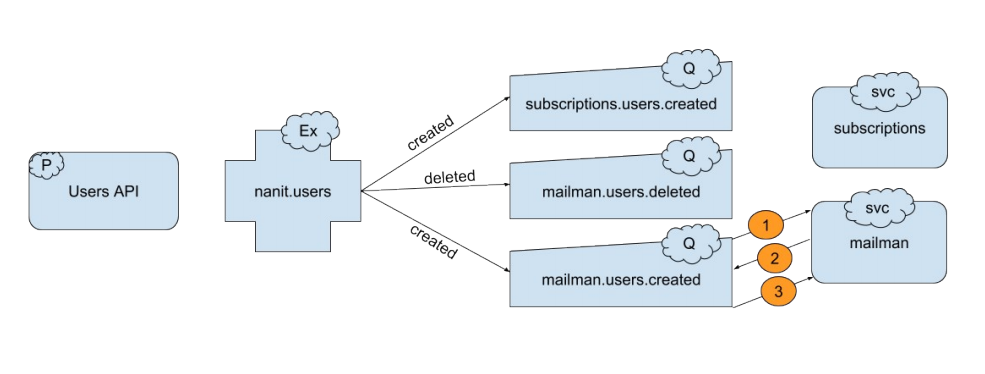
在详谈之前,让我们先了解一下nanit公司的RabbitMQ拓扑图是怎样的:
![]()
Users API是一个发布者,它发布消息到一个direct exchange - nanit.users
针对direct exchange,我们使用nanit.object_name的命名规范 - 本例即是nanit.users
每个服务(mailman和subscriptions)都创建一个名字为service_name.object_name.routing_key的队列,并且用合适的routing key把它绑定到相应的exchange上。在上面的例子,subscriptions和mailman服务都注册了用户创建事件,但是只有mailman注册了用户删除事件。
最后服务就可以开始消费队列里面的消息。
Dead Letter Exchanges
在我们继续深入之前,有必要先提一下一个概念,那就是死信交换机(Dead Letter Exchange)。其实一个死信交换机就是一个普通的RabbitMQ交换机。如果交换机exl设置成是队列q1的死信交换机,一条消息在下面的情况就会自动从q1转发到exl:
来自q1的一条消息被reject了,并且requeue等于false
来自q1的一条消息TTL到了
队列q1的长度限制超了
接下来通篇文章,我们都会用到死信交换机很多。
既然,我们知道了拓扑结构长什么样,也知道了死信交换机是什么,下面我们就可以具体探讨一些重试机制了。
方案一:Reject + Requeue
![]()
拓扑
没什么花俏的 - 不需要创建任何额外的交换机和队列。
流程
一条消息到达mailman消费者端。
消费者端处理这条消息失败,拒绝这条消息并且把requeue设置成true。然后这条消息就被放回到队列头部。
这条消息再次到达消费者端,这一次消息带有redelivered等于true的header。
为了避免这条消息不断重试陷入无限循环,消费者端只应该在消息不是redelivered的情况下,才把requeue设置成true。
输出
$> OPTION=1 make run-example14:11:48 received message: hello | redelivered: falsefirst try, rejecting with requeue=true14:11:48 received message: hello | redelivered: truealready retried, rejecting with retry=false14:11:53 Bye
这种方式允许我们仅可以重试一次,并且没有一点延迟。
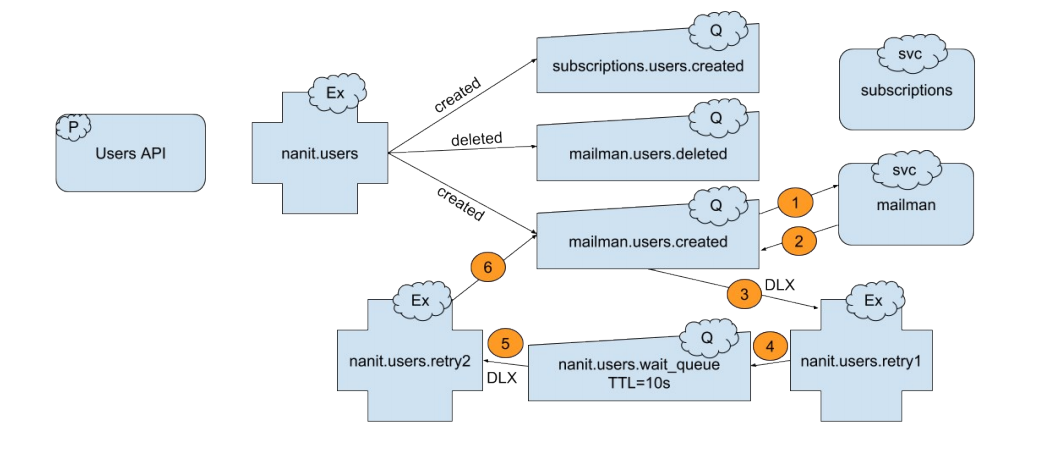
方案二:Reject + DLX topology
![]()
拓扑
这里我们加了两个交换机和一个队列。
我们把nanit.users.retry1设置成队列mailman.users.created的死信交换机,因此,当队列里面的一条消息被reject时,这条消息会被立即转发到nanit.users.retry1。
nanit.users.wait_queue,一个等待队列,用来放不断重试的消息。这个队列通过x-message-ttl设置了一个TTL,当TTL一过期,消息就会被转发到nanit.users.retry2(其是等待队列的死信交换机)。
流程
消息从队列nanit.users.created到达mailman消费者端。
消费者端处理这条消息失败,reject这条消息。
这条消息然后就被转发到这个队列的死信交换机nanit.users.retry1。我们把原始消息的routing key替换成消息来源队列的名字 - nanit.users.created。后面会解释。
队列nanit.users.wait_queue绑定到DLX使用匹配所有的routing key,因此所有的消息都会被转到这个队列。
等待队列通过x-message-ttl参数设置了一个TTL。一旦TTL一过期,消息就会被转到第二个交换机- nanit.users.retry2(队列nanit.users.wait_queue的死信交换机)。
原始队列nanit.users.created绑定到交换机nanit.users.retry2,并且routing key是自己队列的名字,因此这条消息只会再次到达它被reject的队列中,而不会到达绑定了created routing key的其它队列。
输出
$> OPTION=2 make run-example14:12:50 received message: hello | retry_count: 0 rejecting (retry via DLX)14:12:55 received message: hello | retry_count: 1 rejecting (retry via DLX)14:13:00 received message: hello | retry_count: 2 rejecting (retry via DLX)14:13:05 received message: hello | retry_count: 3 max retries reached - acking14:13:11 Bye
这种拓扑结构允许我们定义重试次数,并且可以定义一个固定的重试间隔时间。
要拿到一条消息当前的重试次数,我们可以利用x-death header的count字段,每次消息被死信之后,RabbitMQ都会把这个header的值自动递增。
重试延迟时间是一个常量,因为它是定义在队列级别,而不是消息级别。
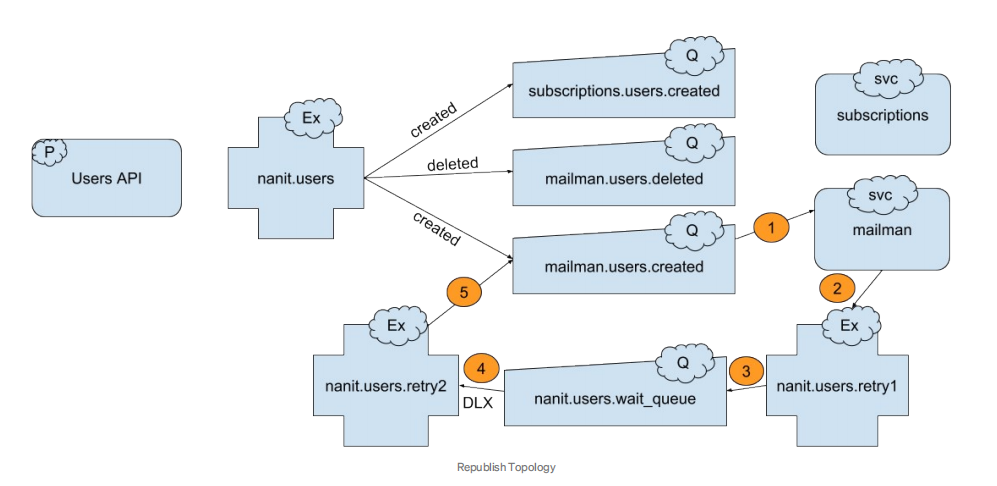
方案三:Republishing to a Retry Exchange
![]()
拓扑
其实,这种拓扑结构和上面的很像,有一点不同的是:nanit.users.retry1不是一个死信交换机,因为我们是重新发布这个失败的消息,而不是reject它。
流程
消息从队列nanit.users.created到达mailman消费者端。
消费者端处理这消息失败,但是确认这条消息,然后把这条消息发布到nanit.users.retry1交换机。由于我们没有reject这条消息,RabbitMQ并不会帮我们保存x-death header,因此我们需要自己处理重试计数问题。这个可以很容易做到,只需要给消息增加一个自定义的header,比如说x-retries。还有,我们需要自己处理TTL:因为等待队列层面没有设置TTL,我们在发布消息的时候,需要设置一个消息级别的TTL。我们可以新增一个expiration的header,其值就是base-retry-delay和当前重试次数的乘积。这种方式,重试的延迟会随着重试次数增加而增加。最后提一下:我们发布消息的时候,消息的routing key要设成队列的名字。当前这个例子就是,mailman.users.created。
这条消息通过nanit.users.retry1交换机转发到队列nanit.users.wait_queue。这一次,等待队列没有默认的TTL,因为我们在每个消息级别指定了一个TTL。
当一条消息的TTL一过期,这条消息就会从等待队列转发到它的死信交换机nanit.users.retry2,并且routing key是原始队列名字-mailman.users.created。
原始队列nanit.users.created,绑定到死信交换机nanit.users.retry2,routing key设置成自己队列的名字,因此消息只会到达它被reject的队列,而不是所有绑定了created routing key的队列。
输出
$> OPTION=3 make run-example14:14:32 received message: hello | retry_count: 0publishing to retry exchange with 3s delay 14:14:35 received message: hello | retry_count: 1publishing to retry exchange with 6s delay 14:14:41 received message: hello | retry_count: 2publishing to retry exchange with 9s delay 14:14:50 received message: hello | retry_count: 3max retries reached - throwing message14:14:53 Bye
这种实现允许我们可以指定重试次数和逐次递增的重试延迟。重试次数通过x-retries header来追踪,并且消息过期时间通过重试的次数和基数过期时间计算出来。
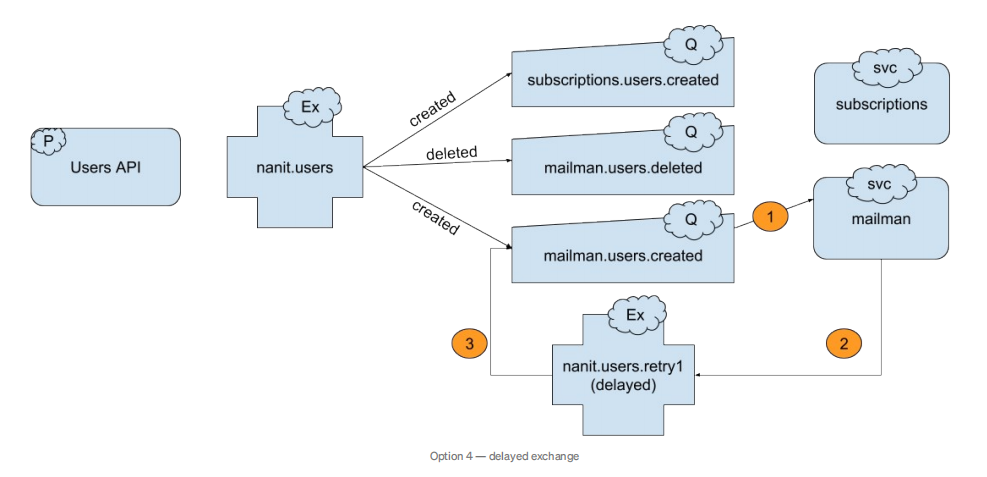
方案四:Delayed Exchange
最后一个方案,也是我们nanit在用的,就是delayed exchange,它是一个RabbitMQ的插件。它允许我们可以很容易地就定义消息级别的TTL时间,而不需要设置额外的等待队列和死信交换机。
![]()
拓扑
这种方式的拓扑结构就很简单 - 我们只有一个重试交换机,其是一个delayed exchange。当消费者端处理消息失败,它就基于一个不断增加的延迟把这条消息发布到这个交换机,前提是还在最大重试次数的限制之下。这种机制和方案3是一样的,只是说流程看起来更加简单。
流程
mailman消费者端收到一条消息,并且处理失败。
然后消费者端确认这条消息,并且把它发布到delayed exchange上,发布的消息加了一个逐步递增的x-retries的header;一个计算出来的x-delay header(这个header可以使这条消息被延迟转发);还有一个routing key,值是匹配原始队列的名字(mailman.users.created)。
当TTL一过期,delayed exchange就会把消息转发回到队列mailman.users.created,其绑定到了这个delayed exchange,并且routing key就是队列名字。
mailman再次消费这条消息。
输出
$> OPTION=4 make run-example14:15:43 received message: hello | retry_count: 0 publishing to retry (delayed) exchange with 3s delay 14:15:46 received message: hello | retry_count: 1 publishing to retry (delayed) exchange with 6s delay 14:15:52 received message: hello | retry_count: 2 publishing to retry (delayed) exchange with 9s delay 14:16:01 received message: hello | retry_count: 3 max retries reached - throwing message14:16:04 Bye
正确地使用重试
尽管加上重试机制是一个很好的主意,但是我们需要记住重试也有一些成本:它意味着更多的消息会被发给RabbitMQ,继而更多的消息被消费者端消费。最终这会转化为更高的CPU/内存/网络消耗。这也是需要认真区分不同失败很重要的原因,这样我们才可以决定哪些消息需要重试,哪些可以被立即忽略。
我们不应该重试的一个例子:消息格式不对,因为对于这样的例子,即使是重试,我们也做不了什么。
而值得重试的一个例子是:处理一条消息需要使用第三方API,而调用这个API收到一个503(temporarily unavailable)的返回。对于这种例子,确实可以考虑重试,因为第三方API可能会很快再次变成Available,这样这条消息就可以再次处理了。
总结
我希望这篇文章可以让你了解到我们在nanit是如何使用RabbitMQ的。
You are invited to check out our open source RabbitMQ on Kubernetes setup。
Useful Links
https://github.com/nanit/rabbitmq-retries-blog
https://www.rabbitmq.com/dlx.html
https://github.com/nanit/kubernetes-rabbitmq-cluster