![]()
在进行数据分析的时候,经常需要将数据进行可视化,以方便我们对数据的认识和理解。
0,Matplotlib 简介
Matplotlib 是一个可视化工具包,可以让我们使用Python 来可视化数据。
![Matplotlib]()
这里有一些官方资源你可以点击查看:
很多更高级的绘图库,也都是基于Matplotlib,比如seaborn,HoloViews,ggplot 等。
在使用 Matplotlib 时,经常需要用到 pyplot 模块,用下面代码引入:
import matplotlib.pyplot as plt
下文中,都用plt 来代指pyplot。
说明: 这里我们只介绍几种简单的图,更多其它的图,可以查看官方手册。 下面的每个函数,只介绍了最简单的用法,其它更多的参数可以查看手册。
1,散点图
plt.scatter 函数用于绘制散点图。函数原型:
scatter(x, y, s = None, c = None, marker = None)
参数含义:
x, y:分别表示点的横纵坐标。x, y 可以是单个点坐标,也可以是一组点坐标。s:表示点的大小。c:表示点的颜色。marker:表示点的形状,可选的值见这里,比如 marker 的值为x, o, s等。
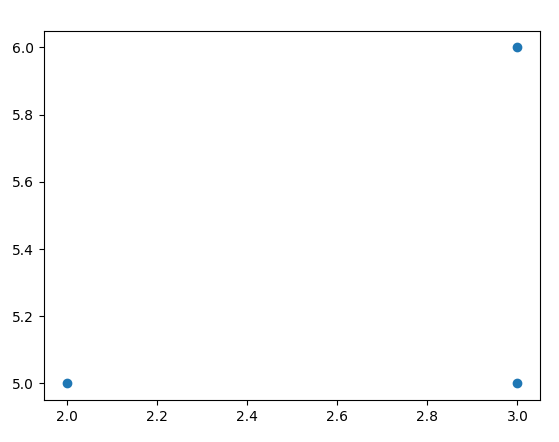
如下代码,画了三个点:
# 三个点的坐标分别是:
# (2, 5)
# (3,6)
# (3, 5)
plt.scatter([2, 3, 3], [5, 6, 5], marker='o')
plt.show() # 展示图
画出的散点图如下:
![在这里插入图片描述]()
2,折线图
plt.plot 函数用于绘制折线图。函数原型:
plot(x, y)
参数 x,y分别表示点的横纵坐标,一般是一组点坐标。
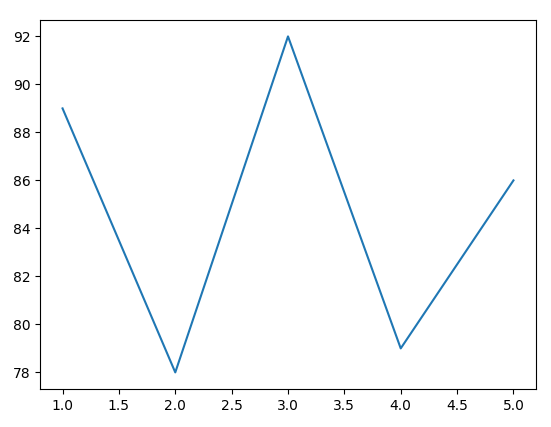
比如下面表格代表5 次数学考试成绩:
| 次数 |
1 |
2 |
3 |
4 |
5 |
| 成绩 |
89 |
78 |
92 |
79 |
86 |
将上面表格数据,绘制成折线图,代码如下:
x = [1, 2, 3, 4, 5]
y = [89, 78, 92, 79, 86]
plt.plot(x, y)
plt.show()
画出的折线图如下:
![在这里插入图片描述]()
3,直方图
直方图用于描述数据的分布情况。
plt.hist 函数用于绘制直方图。函数原型:
plt.hist(x, bins=None)
参数x是一个一维数组,bins 可以理解为矩形的个数,默认是10。
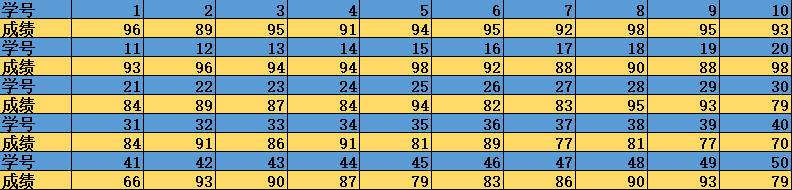
假如下面是一次数学考试的成绩,全班共50 名同学:
![在这里插入图片描述]()
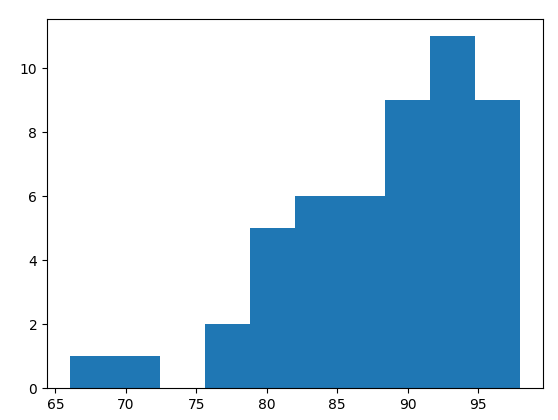
将所有同学的成绩画成直方图,代码如下:
scores = [
96, 89, 95, 91, 94, 95, 92, 98, 95, 93,
93, 96, 94, 94, 98, 92, 88, 90, 88, 98,
84, 89, 87, 84, 94, 82, 83, 95, 93, 79,
84, 91, 86, 91, 81, 89, 77, 81, 77, 70,
66, 93, 90, 87, 79, 83, 86, 90, 93, 79,
]
plt.hist(scores)
plt.show()
画出来的直方图如下,横坐标为成绩区间,纵坐标为人数:
![在这里插入图片描述]()
通过该直方图,可以直观的看出来每个成绩区间的人数。
4,条形图
plt.bar 函数用于绘制条形图。函数原型:
plt.bar(x, y, width = 0.8)
参数x, y 均是一个数组,x 是横坐标,表示数据类别;y 是纵坐标,表示每个类别的频度。参数width 表示长条的宽度。
比如下表是一位同学的期中考试的各科成绩:
![在这里插入图片描述]()
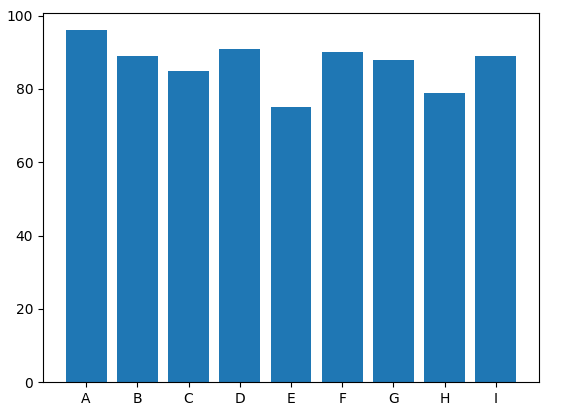
我们将这位同学的成绩单画成条形图,代码如下:
# 每个科目分别用字母表示
subjects = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
scores = [96, 89, 85, 91, 75, 90, 88, 79, 89]
plt.bar(subjects, scores)
plt.show()
画出的条形图如下:
![在这里插入图片描述]()
5,饼图
饼图常用于表示个体占总体的占比情况。
plt.pie 函数用于绘制饼图。函数原型:
plt.pie(x, labels=None)
参数x是一个数组,表示一组数据,labels 用于描述每个数据的含义。
比如下表是某个公司某年每个季度的收入:
![在这里插入图片描述]()
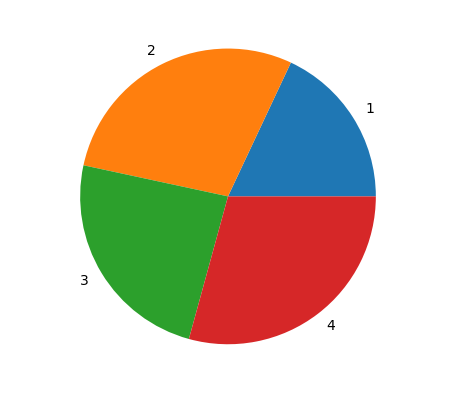
我们可以用饼图分析出每个季度占全年收入的占比,代码如下:
# 表示每个季度
quarters = ['1', '2', '3', '4']
incomes = [56, 89, 75, 91]
plt.pie(incomes, labels=quarters)
plt.show()
画出的饼图如下:
![在这里插入图片描述]()
(本节完。)
推荐阅读:
决策树算法-理论篇-如何计算信息纯度
决策树算法-实战篇-鸢尾花及波士顿房价预测
朴素贝叶斯分类-理论篇-如何通过概率解决分类问题
朴素贝叶斯分类-实战篇-如何进行文本分类
计算机如何理解事物的相关性-文档的相似度判断
欢迎关注作者公众号,获取更多技术干货。
![码农充电站pro]()