介绍
最近,我一直在研究Pulsar及其与Kafka的比较。快速搜索将显示两个最著名的开源消息传递系统之间存在当前的"战争"。
作为Kafka的用户,我确实对Kafka的某些问题感到困惑,并且我对Pulsar感到非常失望。所以最后,我设法花了一些时间进行研究,并且做了很多研究。在本文中,我将重点介绍Pulsar的优势,并为您提供一些理由,使您对比Kafka来考虑它。但是,请在产品使用,支持,社区,文档等方面明确一点;Kafka显然超过了Pulsar,并且只有在本文中讨论的大多数优点都适合您的用例的情况下,才考虑使用Pulsar。让我们开始!
Kafka基础知识
Kafka是消息传递系统之王。它由LinkedIn于2011年创建,并在Confluent的支持下得到了广泛的传播。Confluent已向开源社区发布了许多新功能和附加组件,例如用于模式演化的Schema Registry,用于从其他数据源轻松流式传输的Kafka Connect等。数据库到Kafka,Kafka Streams进行分布式流处理,最近使用KSQL对Kafka主题执行类似SQL的查询等等。它还具有用于许多系统的许多连接器,有关更多详细信息,请查看Confluent Platform。
Kafka快速,易于安装,非常受欢迎,可用于广泛的范围或用例。从开发人员的角度来看,尽管Apache Kafka一直很友好,但在操作上却是一团糟。因此,让我们回顾一下Kafka的一些痛点。
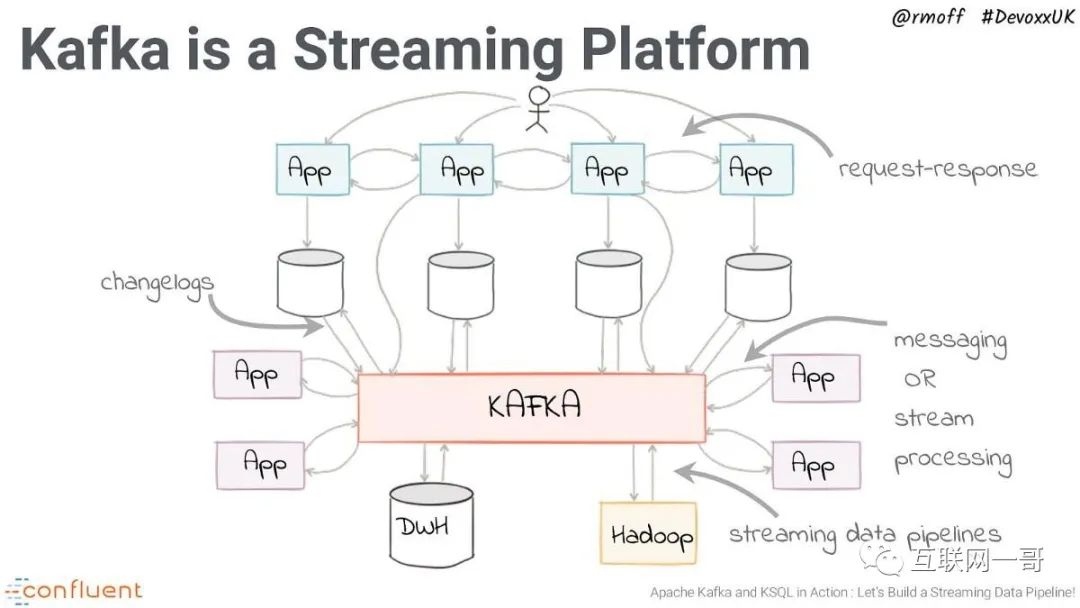
![]()
> Kafka example. Source: https://talks.rmoff.net/pZC6Za/slides
Kafka的问题
· 扩展Kafka十分棘手,这是由于代理还存储数据的耦合体系结构所致。剥离另一个代理意味着它必须复制主题分区和副本,这非常耗时。
· 没有与租户完全隔离的本地多租户。
· 存储可能会变得非常昂贵,尽管可以长时间存储数据,但是由于成本问题,很少使用它。
· 万一副本不同步,有可能丢失消息。
· 必须提前计划和计算代理,主题,分区和副本的数量(以适应计划的未来使用量增长),以避免扩展问题,这非常困难。
· 如果仅需要消息传递系统,则使用偏移量可能会很复杂。
· 集群重新平衡会影响相连的生产者和消费者的性能。
· MirrorMaker Geo复制机制存在问题。像Uber这样的公司已经创建了自己的解决方案来克服这些问题。
如您所见,大多数问题与操作方面有关。尽管安装起来相对容易,但Kafka难以管理和调整。而且,它还没有像它可能的那样灵活和有弹性。
Pulsar基础知识
Pulsar由Yahoo在2013年创建,并于2016年捐赠给Apache基金会。Pulsar现在是Apache的顶级项目。Yahoo,Verizon,Twitter等公司在生产中使用它来处理数百万条消息。它具有许多功能,并且非常灵活。它声称比Kafka更快,因此运行成本更低。它旨在解决Kafka的大部分难题,使其更易于扩展。
Pulsar非常灵活;它可以像Kafka这样的分布式日志,也可以像RabbitMQ这样的纯消息传递系统。它具有多种类型的订阅,几种交付保证,保留策略以及几种处理模式演变的方法。它还有很多功能……
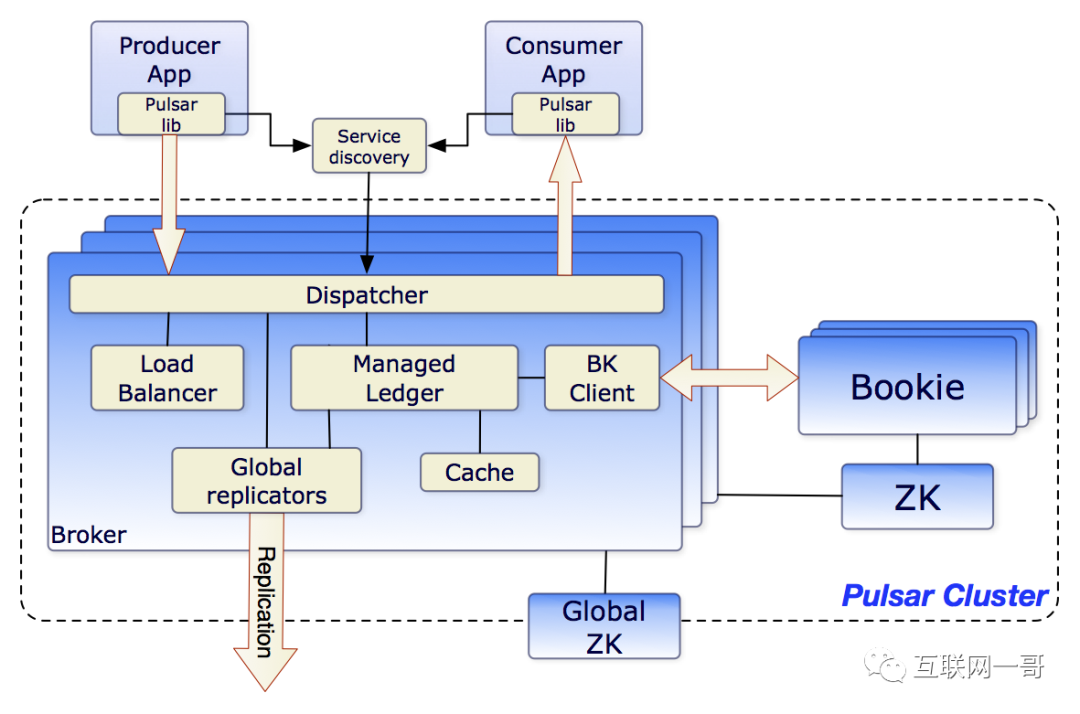
![]()
> Pulsar architecture: https://pulsar.apache.org/docs/en/concepts-architecture-overview/
Pulsar的特性
· 由于内置了多租户,因此不同的团队可以使用相同的集群并将其隔离。这解决了许多管理难题。它支持隔离,身份验证,授权和配额。
· 多层体系结构:Pulsar将所有主题数据存储在由Apache BookKeeper支持的专业数据层中,作为数据分类帐。存储和消息传递的分离解决了扩展,重新平衡和维护集群的许多问题。它还提高了可靠性,几乎不可能丢失数据。另外,在读取数据时,可以直接连接到Bookeeper,而不会影响实时摄取。例如,可以使用Presto对主题执行SQL查询,类似于KSQL,但请放心,这不会影响实时数据处理。
· 虚拟主题。由于采用n层体系结构,因此对主题的数量没有限制,主题及其存储是分离的。还可以创建非持久性主题。
· N层存储。Kafka的一个问题是,存储可能变得昂贵。因此,它很少用于存储"冷"数据,并且消息经常被删除。并且仍然向客户展示透明视图;客户端可以从时间开始读取,就像所有消息都存在于日志中一样。
·Pulsar函数。易于部署,轻量级计算过程,对开发人员友好的API,无需运行自己的流处理引擎(如Kafka)。
· 安全性:它具有内置的代理,多租户安全性,可插入身份验证等等。
· 快速重新平衡。分区分为易于重新平衡的段。
· 服务器端重复数据删除和无效字段。无需在客户端中执行此操作,也可以在压缩期间执行重复数据删除。
· 内置架构注册表。支持多种策略,非常易于使用。
· 地理复制和内置发现。将群集复制到多个区域非常容易。
· 集成的负载均衡器和Prometheus指标。
· 多重集成:Kafka,RabbitMQ等。
· 支持许多编程语言,例如GoLang,Java,Scala,Node,Python…
· 客户端不需要知道分片和数据分区,这是在服务器端透明进行的。
![]()
> List of features: https://pulsar.apache.org/
如您所见,Pulsar具有许多有趣的功能。
Pulsar 动手
开始使用Pulsar非常容易。确保已安装JDK!
· 下载Pulsar并解压缩:
$ wget https://archive.apache.org/dist/pulsar/pulsar-2.6.1/apache-pulsar-2.6.1-bin.tar.gz
2.下载连接器(可选):
$ wget https://archive.apache.org/dist/pulsar/pulsar-2.6.1/connectors/{connector}-2.6.1.nar
3.下载nar文件后,将文件复制到pulsar目录中的connectors目录
4.启动Pulsar!
$ bin/pulsar standalone
Pulsar提供了一个称为pulsar-client的CLI工具,我们可以使用它与集群进行交互。
产生消息:
$ bin/pulsar-client produce my-topic --messages "hello-pulsar"
阅读消息:
$ bin/pulsar-client consume my-topic -s "first-subscription"
Akka流示例
作为一个客户示例,让我们在Akka上使用Pulsar4s!
首先,我们需要创建一个Source来使用数据流,所需要的只是一个函数,该函数将按需创建使用者并查找消息ID:
val topic = Topic("persistent://standalone/mytopic")
val consumerFn = () => client.consumer(ConsumerConfig(topic, subscription))
然后,我们传递consumerFn函数来创建源:
import com.sksamuel.pulsar4s.akka.streams._
val pulsarSource = source(consumerFn, Some(MessageId.earliest))
Akka源的物化值是Control的一个实例,该对象提供了一种"关闭"方法,可用于停止使用消息。现在,我们可以像往常一样使用Akka Streams处理数据。
要创建一个接收器:
val topic = Topic("persistent://standalone/mytopic")
val producerFn = () => client.producer(ProducerConfig(topic))
import com.sksamuel.pulsar4s.akka.streams._
val pulsarSink = sink(producerFn)
完整示例摘自Pulsar4s:
Pulsar函数示例
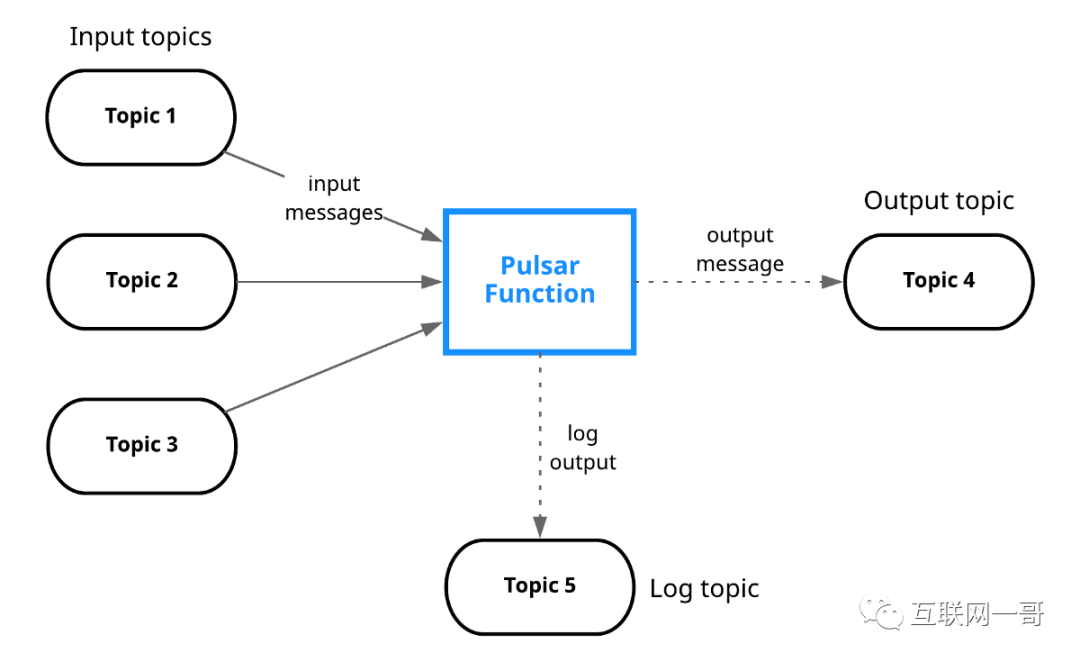
Pulsar函数处理来自一个或多个主题的消息,对其进行转换并将结果输出到另一个主题:
![]()
> Pulsar Functions. Source: https://pulsar.apache.org/docs/en/functions-overview/
可以在两个接口之间进行选择以编写函数:
· 语言本机界面:不需要特定于Pulsar的库或特殊的依赖项。无法访问上下文。仅支持Java和Python。
· Pulsar Function SDK:可用于Java / Python / Go,并提供更多功能,包括访问上下文对象。
使用语言本机接口非常容易,您只需编写一个简单的函数即可转换消息:
def process(input):
return "{}!".format(input)
用Python编写的这个简单函数只是向所有传入的字符串添加一个感叹号,并将结果字符串发布到主题。
要使用SDK,您需要导入依赖项,例如在Go中,我们将编写:
package main
import (
"context"
"fmt"
"github.com/apache/pulsar/pulsar-function-go/pf"
)
func HandleRequest(ctx context.Context, in []byte) error {
fmt.Println(string(in) + "!")
return nil
}
func main() {
pf.Start(HandleRequest)
}
要发布无服务器功能并将其部署到集群,我们使用pulsar-admin CLI,如果使用Python,我们将使用:
$ bin/pulsar-admin functions create \
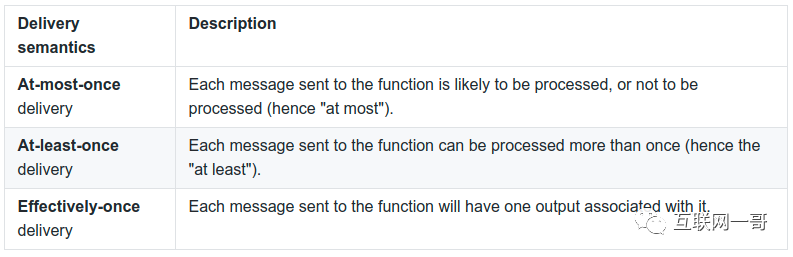
Pulsar Functions的一个重要功能是您可以在发布该函数时设置交付保证:
$ bin/pulsar-admin functions create \
有以下选择:
![]()
Pulsar的优势
让我们回顾一下与Kafka相比的主要优势:
· 更多功能:Pulsar函数,多租户,架构注册表,n层存储,多种使用模式和持久性模式等。
· 更大的灵活性:3种订阅类型(独占,共享和故障转移),您可以在一个订阅上收听多个主题。持久性选项:非持久(快速),持久,压缩(每个消息仅最后一个键)。可以选择交付保证,它具有服务器端重复数据删除和无效字样。许多保留政策和TTL。
· 无需提前定义扩展需求。
· 支持排队和流媒体。因此它可以像RabbitMQ或Kafka。
· 由于存储与代理分离,因此扩展性更好。重新平衡更快,更可靠。
· 易于操作:得益于去耦和n层存储。管理员REST API也很棒。
· 与Presto的SQL集成,可直接查询存储而不会影响代理。
· 借助n层自动存储选项,可以更便宜地存储。
· 更快:许多基准测试在各种情况下都表现出更好的性能。Pulsar声称具有较低的延迟和更好的扩展功能。但是,这正受到Confluent的挑战,因此,请带着盐味做,并自己制定基准。
· Pulsar Functions将无服务器计算带到您的消息传递平台。
· 集成架构注册表支持轻松的架构演变
· 集成的负载平衡器和Prometheus指标。
· 地理复制效果更好,更易于设置。Pulsar还内置了发现能力。
· 可以创建的主题数量没有限制。
· 与Kafka兼容,易于集成。
Pulsar的问题
Pulsar并不完美,Kafka之所以流行是有原因的,它做一件事并且做得很好。Pulsar试图解决太多领域,但没有超越任何一个领域。让我们总结一下Pulsar的一些问题:
· 受欢迎程度:Pulsar不那么受欢迎。它缺乏支持,文档和实际使用情况。对于大型组织而言,这是一个主要问题。
· 由于n层体系结构,它需要更多组件:Bookkeeper。
· 在平台内没有对流应用程序的适当支持。Pulsar函数与Kafka Streams不同,它们更简单,并且不用于实时流处理。您无法进行有状态处理。
· 与Kafka相比,插件和客户端更少。此外,掌握Pulsar技能的人较少,因此需要在内部学习。
· 它在云中的支持较少。Confluent具有托管云产品。
Confluent在Pulsar和Kafka之间进行了比较,可以在其中进行更多的详细说明。该博客还回答了有关Kafka与Pulsar的一些问题,但请注意,这些问题可能有偏见。
Pulsar使用案例
Pulsar可用于广泛的用例:
· 发布/订阅队列消息传递
· 分布式日志
· 事件源壁架,用于永久性事件存储
· 微服务
· SQL分析
· 无服务器功能
什么时候应该考虑Pulsar
· 需要像RabbitMQ这样的队列,也需要像Kafka这样的流处理程序。
· 需要简单的地理复制。
· 多租户是必须具备的,并且想确保每个团队的访问权限。
· 需要将所有消息保留很长时间,并且不想将其卸载到另一个存储中。
· 性能对你至关重要,基准测试表明Pulsar提供了更低的延迟和更高的吞吐量。
· 在本地运行,没有设置Kafka的经验,但具有Hadoop经验。
请注意,如果在云中,请考虑基于云的解决方案。云提供商拥有涵盖某些用例的不同服务。例如,对于队列消息传递,云提供商提供了许多服务,例如Google pub / sub。对于分布式日志,有Confluent云或AWS Kinesis。云提供商还提供了非常好的安全性。Pulsar的优势在于可以在一个平台上提供许多功能。一些团队可能将其用作微服务的消息传递系统,而另一些团队则将其用作数据处理的分布式日志。
结论
我是Kafka的忠实粉丝,这就是为什么我对Pulsar如此感兴趣。竞争是好的,它驱动创新。
Kafka是一种成熟,富有弹性且经过战斗考验的产品,在世界范围内获得了巨大成功。没有它,我无法想象任何公司。但是,我确实看到Kafka成为其自身成功的受害者,巨大的增长减慢了功能开发的速度,因为它们需要支持这么多大型公司。删除ZooKeeper依赖项等重要功能花费的时间太长。这为诸如Pulsar等工具蓬勃发展创造了空间。解决Kafka的一些问题并添加更多功能。
但是,Pulsar仍然很不成熟,在投入生产之前,我会格外小心。在将Pulsar纳入你的组织之前,进行分析,进行基准测试,研究并编写概念证明。从小处着手,在从Kafka迁移之前进行概念验证,并在决定进行完全迁移之前先评估影响。
作者:闻数起舞
链接:https://0x9.me/cYZFN