"a good representation should express general-purpose priors that are not task-specific but would be likely to be useful for a learning machine to solve AI-tasks."
「nlp领域好的文本表征则意味着能够捕捉蕴含在文本中的隐性的语言学规则和常识性知识.」
"capture the implicit linguistic rules and common sense knowledge hiding in text data, such as lexical meanings, syntactic structures, semantic roles, and even pragmatics."
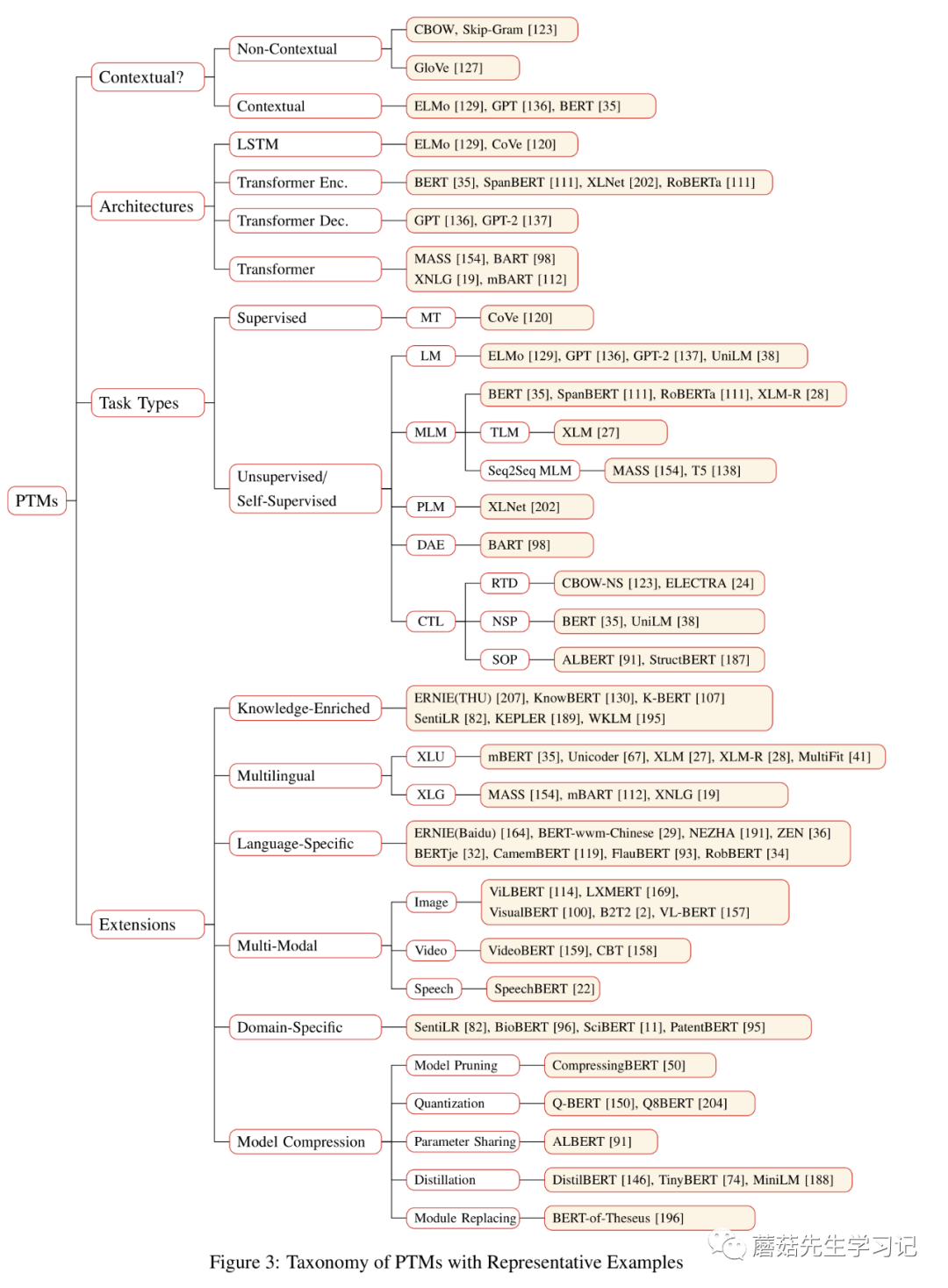
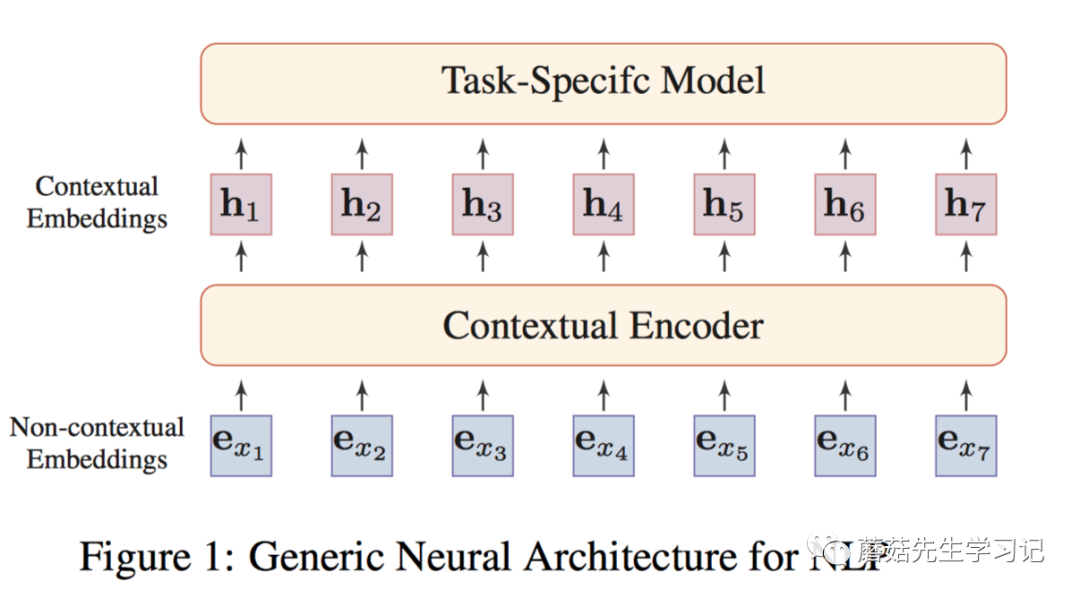
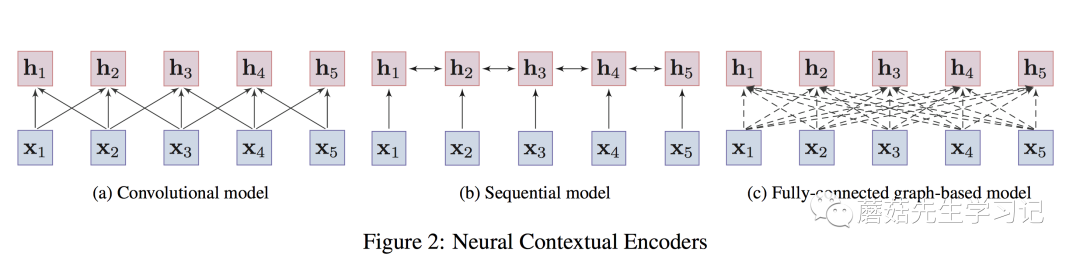
第二代预训练模型致力于学习「contextual」 word embeddings。第一代预训练模型主要是word-level的。很自然的想法是将预训练模型拓展到「sentence-level」或者更高层次,这种方式输出的向量称为contextual word embeddings,即:依赖于上下文来表示词。此时,预训练好的「Encoder」需要在下游任务「特定的上下文中」提取词的表征向量。代表性工作包括两方面,
(1) 「ULMFiT」[7] (Universal Language Model Fine-tuning):通过在文本分类任务上微调预训练好的语言模型达到了state-of-the-art结果。这篇也被认为是「预训练模型微调」模式的开创性工作。提出了3个阶段的微调:在通用数据上进行语言模型的预训练来学习「通用语言特征」;在目标任务所处的领域特定的数据上进行语言模型的微调来学习「领域特征;「在目标任务上进行微调。文中还介绍了一些」微调的技巧」,如区分性学习率、斜三角学习率、逐步unfreezing等。
「自监督学习」 (self-supervised learning):监督学习和无监督学习的折中。训练方式是监督学习的方式,但是输入数据的 「标签是模型自己产生的」。核心思想是,用输入数据的一部分信息以某种形式去预测其另一部分信息(predict any part of the input from other parts in some form)。例如BERT中使用的MLM就是属于这种,输入数据是句子,通过句子中其它部分的单词信息来预测一部分masked的单词信息。
上述式子是典型的概率论中的链式法则。链式法则中的每个部分是给定上下文条件下,当前要预测的词在整个词典上的条件概率分布。这意味着「当前的单词只依赖于前面的单词,即单向的或者自回归的,这是LM的关键原理」,也是这种预训练任务的特点。因此,LM也称为auto-regressive LM or unidirectional LM。
前面介绍的方法主要是基于上下文的PTMs,即:基于数据本身的上下文信息构造辅助任务。这里作者介绍的另一大类的预训练方法是基于对比的方法,即:通过「对比」来进行学习。很像learning to rank中的pairwise方法。CTL全称:Contrastive Learning,假设了「观测文本对」之间的语义比「随机采样的文本对」之间的语义更近。因此优化的目标是:
是观测的文本相似对,是负样本对。上述损失实际上是二路的softmax,实际上又等价于learning to rank中的BPR Loss,只需要把分子除到分母上,就可以整理成类似BPR的形式了,即:
[1] Qiu X, Sun T, Xu Y, et al. Pre-trained models for natural language processing: A survey[J]. arXiv preprint arXiv:2003.08271, 2020.
[2] NNLM:Yoshua Bengio, R´ejean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of machine learning research, 3(Feb):1137–1155, 2003.
[3] Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In NeurIPS, 2013.
[4] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global vectors for word representation. In EMNLP, 2014.
[5] Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. Learned in translation: Contextualized word vectors. In NeurIPS, 2017.
[6] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In NAACL-HLT, 2018.
[7] Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. In ACL, pages 328339, 2018.
[8] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
[9] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
[10]ICLR 2019: What do you learn from context? probing for sentence structure in contextualized word representations.
[11] NIPS 2019: Visualizing and measuring the geometry of BERT.
[12] ACL 2019: How can we know what language models know?
[13] Yoon Kim. Convolutional neural networks for sentence classification. In EMNLP, pages 1746–1751, 2014.
[14] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N Dauphin. Convolutional sequence to sequence learning. In ICML, pages 1243–1252, 201728015059046.
[15] Diego Marcheggiani, Joost Bastings, and Ivan Titov. Exploiting semantics in neural machine translation with graph convolutional networks. In NAACL-HLT, pages 486–492, 2018.
[16] Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MASS: masked sequence to sequence pre-training for language generation. In ICML, volume 97 of Proceedings of Machine Learning Research, pages 5926–5936, 2019.
[17] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
[18] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
[19] NIPS 2019, Unified language model pre-training for natural language understanding and generation.
[20] NIPS 2019, Cross-lingual language model pretraining
[21] ACL2020, SpanBERT: Improving pretraining by representing and predicting spans.
[22] 2019, ERNIE: enhanced representation through knowledge integration
[23] NIPS2019, XLNet: Generalized Autoregressive Pretraining for Language Understanding
[24] 2019, BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
[25] ICLR 2020, A mutual information maximization perspective of language representation learning
[26] ICLR 2020, ELECTRA: Pre-training text encoders as discriminators rather than generators.
[27] ICLR2020, WKLM, Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model.
[28] ICLR2020, ALBERT: A lite BERT for self-supervised learning of language representations
[29] ICLR 2020, StructBERT: Incorporating language structures into pre-training for deep language understanding.
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。