小三:“怎么了小二?一副无精打采的样子!”
![]()
小二:“唉!别提了,还不是最近又接触了一个叫英雄联盟的游戏,游戏中很多皮肤都需要花钱买,但是我钱不够呀...”
![]()
小三:“咋得,钱攒够了你还要买呀?还吃不吃饭了?!要我说,你干脆将英雄的炫彩皮肤都爬下来欣赏一下得了,饭钱还给你省下了。”
小二:“你说的也对,毕竟吃饭更重要,那我还是爬取皮肤欣赏一下算了。”
![]()
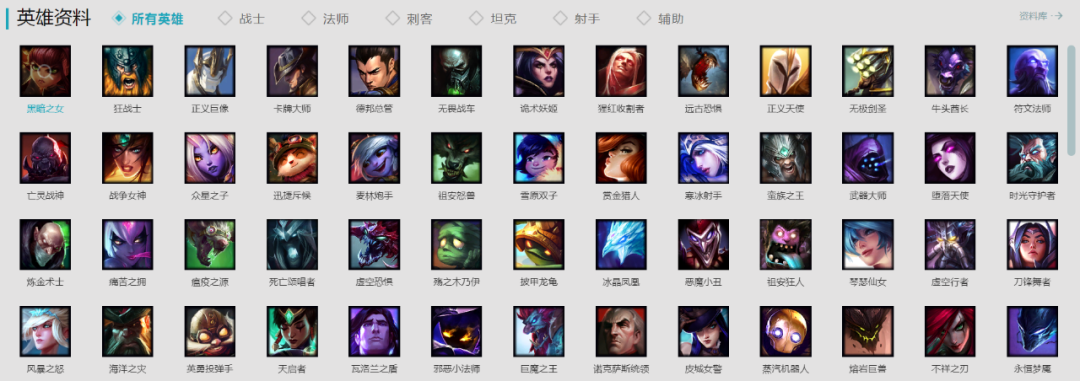
首先,我们打开英雄联盟官网主页,网址为:https://lol.qq.com/main.shtml,然后向下拉,可以看到英雄列表,如图所示:
![]()
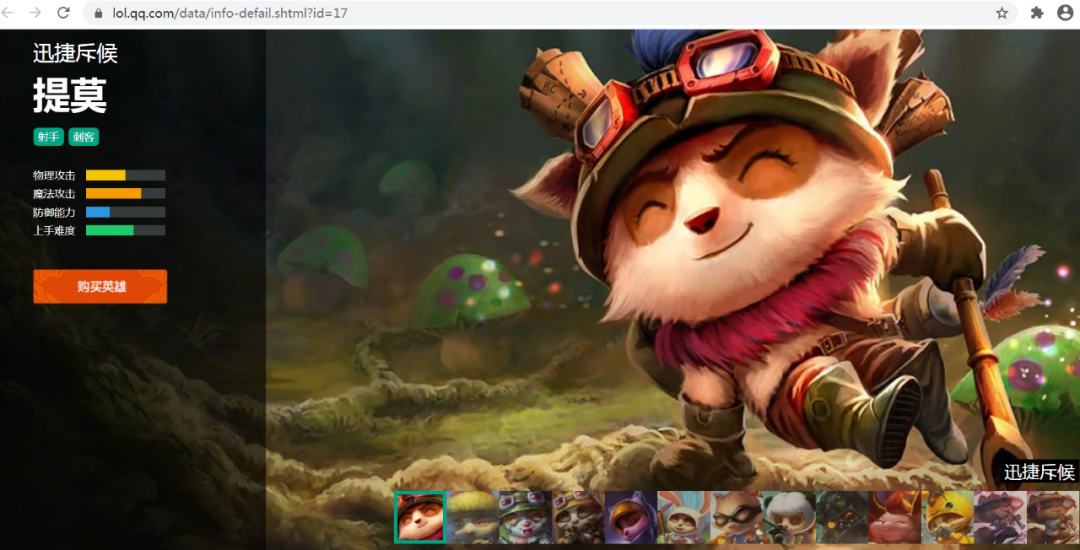
接着随意选一个英雄点击进入看一下,如图所示:
![]()
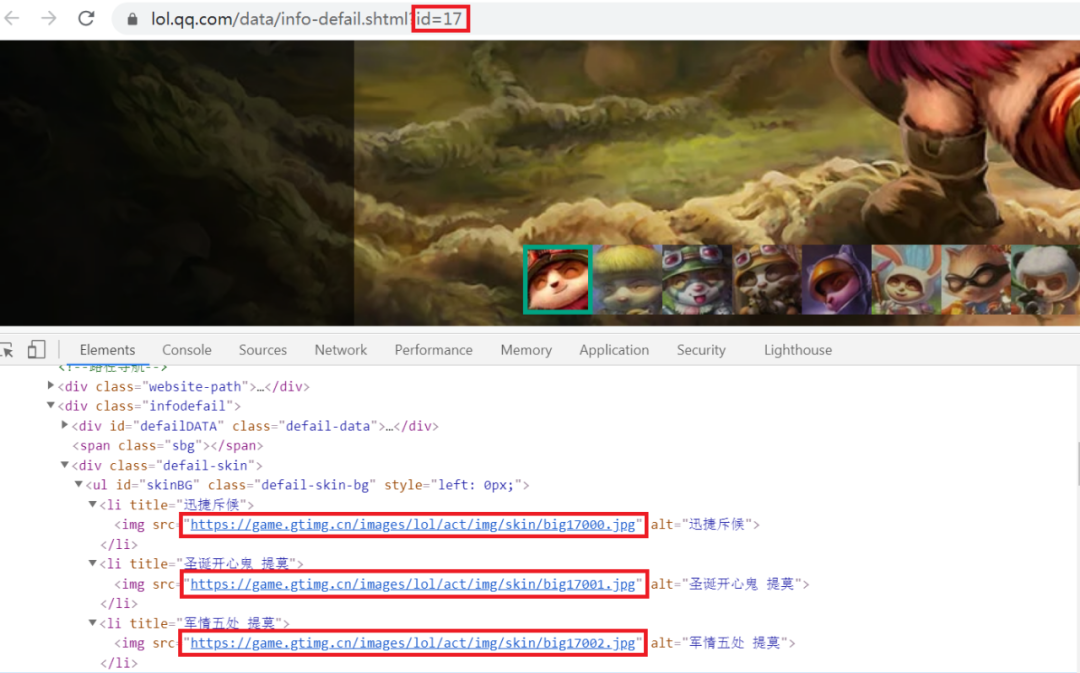
再点击鼠标右键,接着选择检查,看一下皮肤的 URL,如图所示:
![]()
通过观察,可以发现英雄皮肤 URL 组成方式为:https://game.gtimg.cn/images/lol/act/img/skin/big + 英雄id + 皮肤id.jpg。
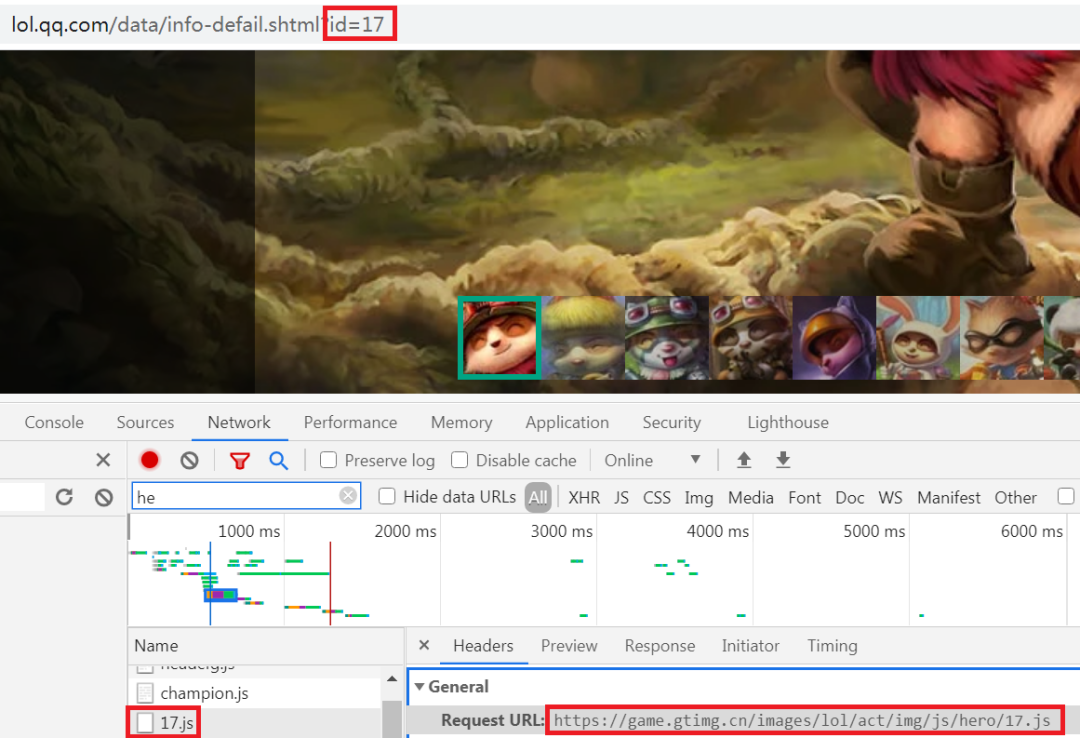
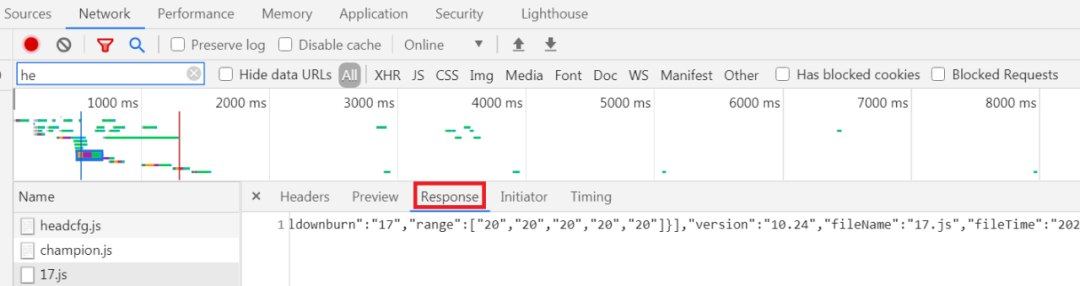
我们先看皮肤id,也就是看皮肤的个数,选择开发者工具的Network项,之后刷新一下页面,可以发现有一个17.js的请求,17实际就是英雄id,如图所示:
![]()
再选择Response项看一下相应数据,如图所示:
![]()
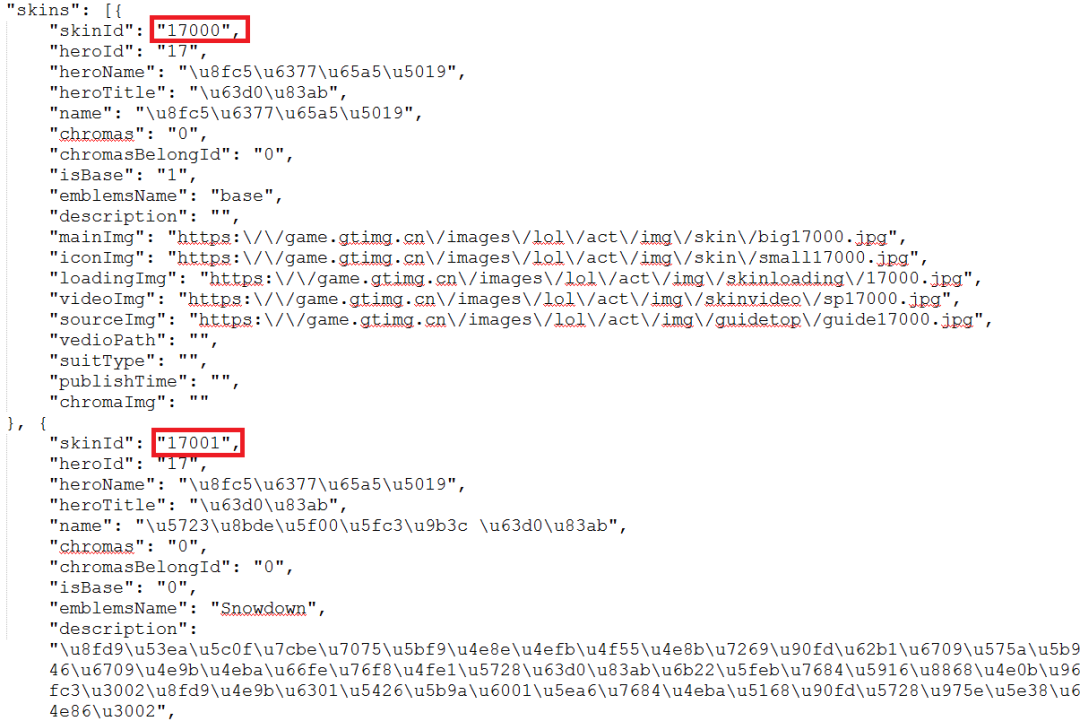
我们可以看到数据都显示在了一行,看着不太方便,我们将其格式化看一下,如图所示:
![]()
通过观察,可以发现获取指定英雄皮肤id的 URL 就是:https://game.gtimg.cn/images/lol/act/img/js/hero/ + 英雄id.js,获取皮肤id及下载皮肤图片的代码实现如下:
hero_skin_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/' + hero_id + '.js'
# 通过 url 获取英雄的皮肤数量
skin_text = requests.get(hero_skin_url).text
skin_json = json.loads(skin_text)
skin_list = skin_json['skins']
# 获取皮肤名
hero_skins.clear()
for skin in skin_list:
hero_skins.append(skin['name'].replace('/', '').replace('\\', '').replace(' ', ''))
# 皮肤数量
skins_num = len(hero_skins)
s = ''
for i in tqdm(range(skins_num), desc='【' + hero_name + '】皮肤下载'):
if len(str(i)) == 1:
s = '00' + str(i)
elif len(str(i)) == 2:
s = '0' + str(i)
elif len(str(i)) == 3:
pass
try:
# 拼接指定皮肤的 url
skin_url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + hero_id + '' + s + '.jpg'
img = requests.get(skin_url)
except:
# 没有炫彩皮肤 url 则跳过
continue
# 保存皮肤图片
if img.status_code == 200:
with open(hero_skins[i] + '.jpg', 'wb') as f:
f.write(img.content)
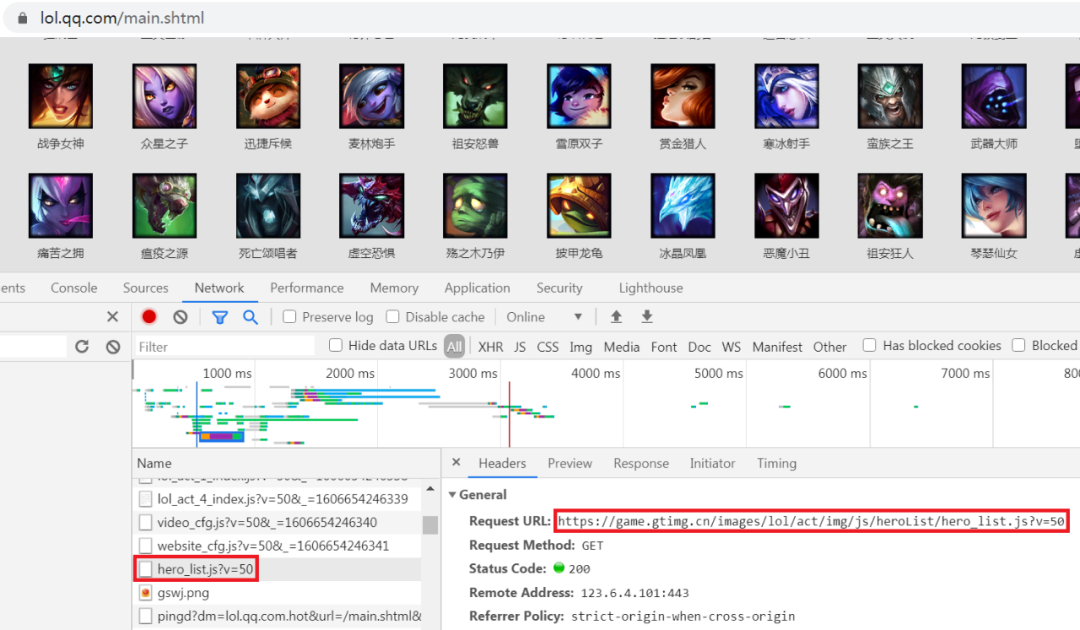
现在就差英雄id参数的获取了,我们接着看如何获取全部的英雄id,返回到 https://lol.qq.com/main.shtml页面,打开开发者工具并选择Network,然后刷新页面,我们可以观察到有一个hero_list.js的请求,如图所示:
![]()
与皮肤id的获取基本类似,通过这个请求就可以获取到全部英雄id,代码实现如下:
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
hero_text = requests.get(url).text
# 转为 json 格式
hero_json = json.loads(hero_text)['hero']
path = os.getcwd()
# 获取当前文件夹路径
workspace = os.getcwd()
# 皮肤路径
skin_path = "{}\\{}".format(workspace, 'skins')
# 遍历列表
for hero in hero_json:
# 将每一个英雄的 id、name 放入一个字典中
hero_dict = {'id': hero['heroId'], 'name': hero['name']}
# 放入列表
heros.append(hero_dict)
我们可以看出:代码中除了英雄id,还获取了英雄name,并将每一个英雄的id、name放在了一个字典中,又将所有英雄对应的字典放在了列表中。
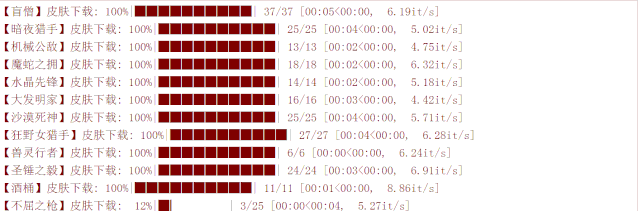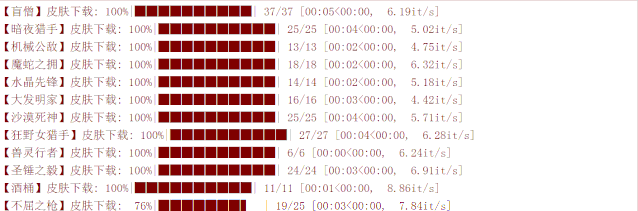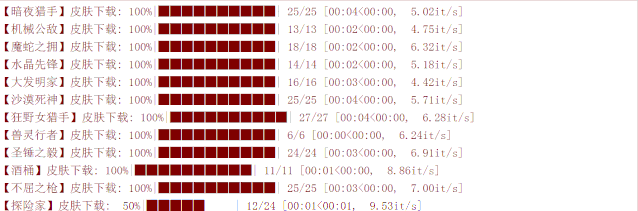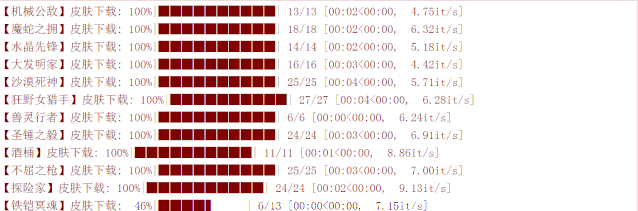
最后,我们看一下下载效果:
![]()
源码在公众号 Python小二 后台回复 201130 获取,有问题可以添加我个人微信号:ityard。
![]()
如果觉得有帮助,就给个分享、在看、赞吧~