![]()
之前写过一个 IoTDB 数据模型 的介绍 ,但是实际例子举得不多,所以部分用户对于一个实际系统如何建模还比较困惑,今天主要介绍一下建模实例。
实时库、InfluxDB、OpenTSDB等多是基于标签的模型。
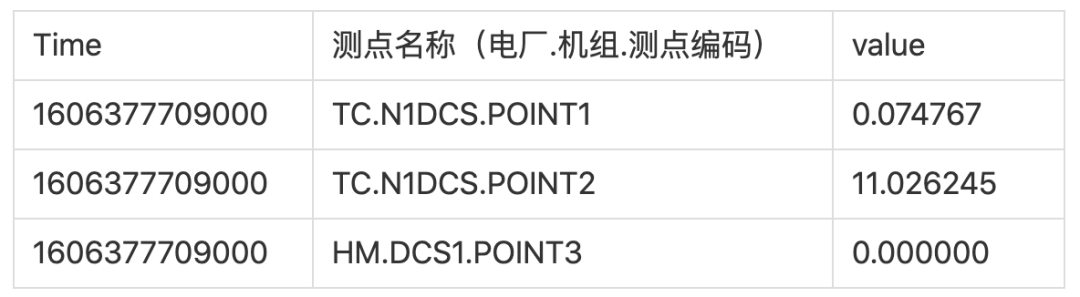
在实时库中,每个测点有一个名称(可以看成一个标签)。通常这个测点名称是由符号 “.” 连接的多个属性值。在一个电厂应用的命名示例是这样的:电厂名称.机组.测点编码。如果将实时库中的所有测点的数据理解成一张表,就是下边这样的:
![]()
这个表里,Time 和测点名称就是联合主键。
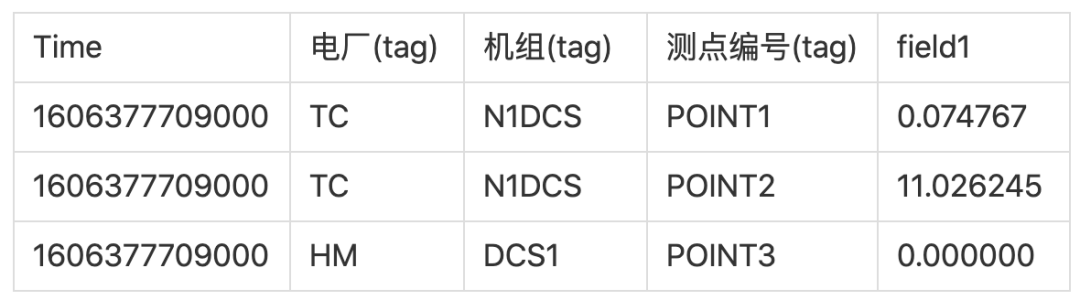
在 InfluxDB、OpenTSDB 中每条数据有 tag 和 field 的概念,上面的数据通常会被定义为 3 个 tag 和 1 个 field,查询出来的表结构是这样的:
![]()
这个表里,Time 和所有 tag 列是联合主键。
IoTDB 中的数据模型是什么样的呢?
先介绍一下 IoTDB 对时间序列的定义:一个测点在不断地采集数据,每个数据点会打上一个时间戳,这个测点的数据就对应一条时间序列,一条时间序列举例如下:
![]()
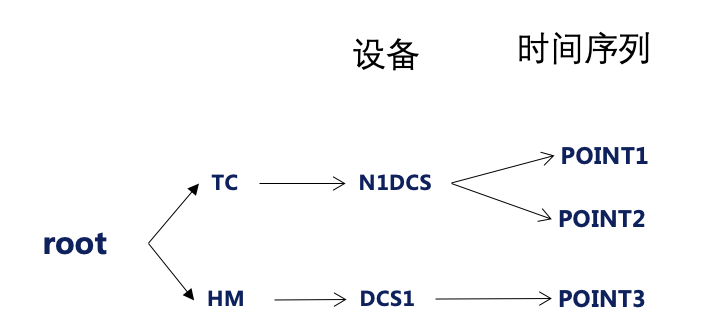
IoTDB 的目标场景就是管理很多这种时间序列,各个时间序列是由路径 唯一定位的。上一节中的数据对应到 IoTDB 中就是 3 个时间序列,3个时间序列的路径如下:
root.TC.N1DCS.POINT1root.TC.N1DCS.POINT2root.HM.DCS1.POINT3
这些路径形成了一棵树形的元数据结构:
![]()
其中从 root 到倒数第二级的路径在 IoTDB 中有个特殊的含义:设备 ,这个例子中有两个设备:root.TC.N1DCS,root.HM.DCS1。
同一设备的多个测点可以共享一个时间戳写入:
insert into root.TC.N1DCS(time, POINT1, POINT2) values(1606377709000, 0.074767, 11.026245)insert into root.HM.DCS1(time, POINT3) values(1606377709000, 0.0)
Tag 的值形成了树形结构的路径,是元数据树上的一个节点(避免把 Tag 的名称定义为一个时间序列,Tag 值存储成了这个时间序列的值)。
比如,在IoTDB 中,建立了以下两条时间序列(root.sg.taga, root.sg.value),并用来存储多个测点(a1, b1, c1)的值,这种就是错误的建模方式,这种情况下,同一个时间序列的同一个时间戳只保留最后写入的点,所以第 3 行蓝色的数据会被第 4 行覆盖掉。
![]()
对于这种情况,正确的建模方式是创建 3 条时间序列
root.sg.a1, root.sg.b1, root.sg.c1
这种情况下,3 条序列的数据分别为:
Time
|
root.sg.a1 |
| 1 |
1.23 |
| 2 |
2.31 |
![]()
以第一节的数据为例来介绍一下 IoTDB 的查询。首先根据 select 和 from 子句中的路径找到所有匹配到的时间序列,然后按照不同的对齐方式展示成一张表,这里提供了 3 种对齐方法。
(1)按照 Time 对齐(默认)
如查询 TC 下的所有测点的数据,以 root.TC 为前缀匹配到了 2 个序列
![]()
以 root.* 为前缀可以匹配 3 个序列
![]()
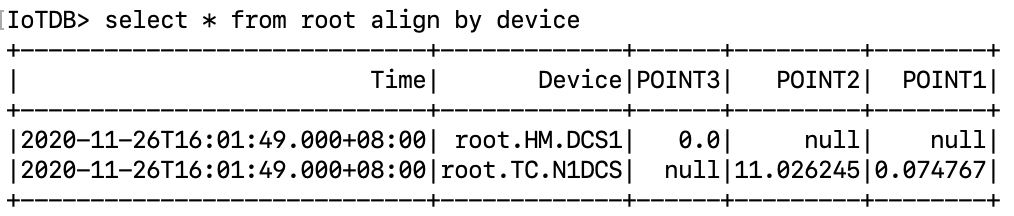
(2) 按照设备表展示,按照 Time 和 device 对齐,可以用 align by device 语句,对齐后为空的就展示 null
![]()
(3)不对齐,每个时间序列独立展示。每个时间序列有两列(时间列和值列),使用 disable align 修饰,这里其实是有3个表,每个表中应该空一些。
![]()
树形模型比较灵活,比如一个电厂有 3 个设备,每个设备的发电量是一个时间序列。我们会创建 3 个序列:root.电厂1.设备1.发电量,root.电厂1.设备2.发电量,root.电厂1.设备3.发电量。现在希望增加一个电厂总发电量,就可以在电厂下一级增加一个时间序列:root.电厂1.总发电量。
也有一些时序数据库采用关系模型,像 TimescaleDB,关系模型的好处是学习成本低,适用于数据较为规整的场景,但是表需要提前定义,修改(加列)的代价比较大,不适用预先不确定有多少测点,或一个设备的多个测点不同时采集的场景。
没有一种结构适用于所有场景,我们之后会逐渐让元数据模型更简单,降低学习成本。最后,欢迎大家加入社区一起交流~
QQ 群:659990460
微信群:添加好友 tietouqiao
Github:https://github.com/apache/iotdb
![]()