在Java并发编程中,公平锁与非公平锁是很常见的概念,ReentrantLock、ReadWriteLock默认都是非公平模式,非公平锁的效率为何高于公平锁呢?究竟公平与非公平有何区别呢?
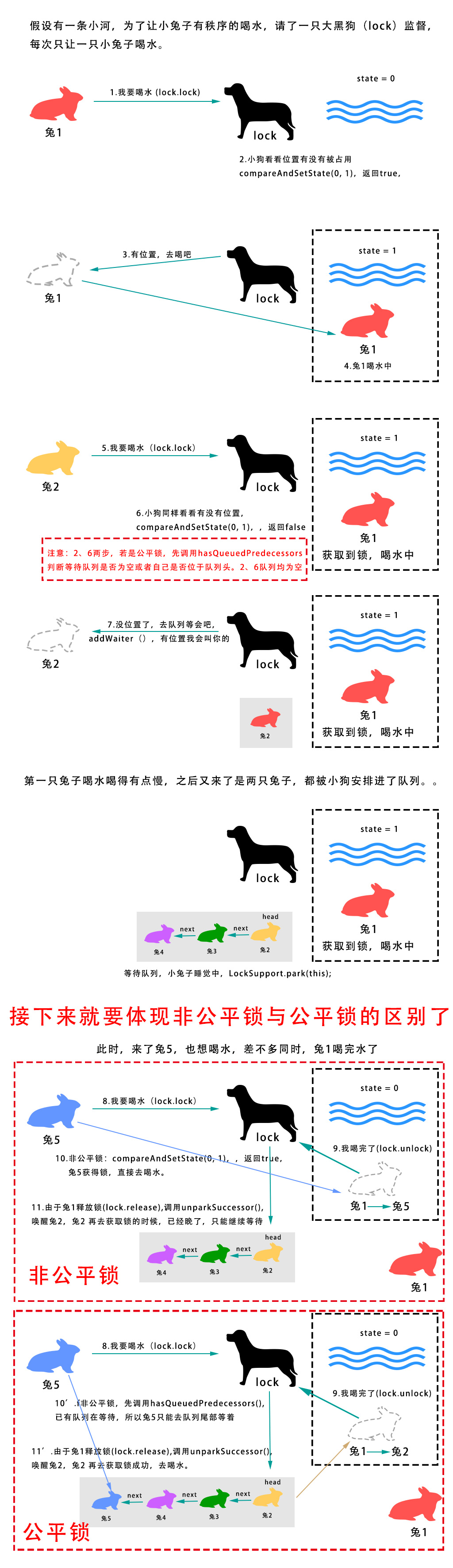
首先先简单从名字上来理解,公平锁就是保障了多线程下各线程获取锁的顺序,先到的线程优先获取锁,而非公平锁则无法提供这个保障。看到网上很多说法说非公平锁获取锁时各线程的的概率是随机的,这也是一种很不确切的说法。非公平锁并非真正随机,其获取锁还是有一定顺序的,但其顺序究竟是怎样呢?先看画了半天的图:
![]()
公平锁与非公平锁的一个重要区别就在于上图中的2、6、10那个步骤,对应源码如下:
//非公平锁
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
//区别重点看这里
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
//公平锁
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
//hasQueuedPredecessors这个方法就是最大区别所在
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
分析以上代码,我们可以看到公平锁就是在获取锁之前会先判断等待队列是否为空或者自己是否位于队列头部,该条件通过才能继续获取锁。
在结合兔子喝水的图分析,非公平锁获取所得顺序基本决定在9、10、11这三个事件发生的先后顺序,
1、若在释放锁的时候总是没有新的兔子来打扰,则非公平锁等于公平锁;
2、若释放锁的时候,正好一个兔子来喝水,而此时位于队列头的兔子还没有被唤醒(因为线程上下文切换是需要不少开销的),此时后来的兔子则优先获得锁,成功打破公平,成为非公平锁;
其实对于非公平锁,只要线程进入了等待队列,队列里面依然是FIFO的原则,跟公平锁的顺序是一样的。因为公平锁与非公平锁的release()部分代码是共用AQS的代码。
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
//唤醒队列头的线程
LockSupport.unpark(s.thread);
}
上文说到的线程切换的开销,其实就是非公平锁效率高于公平锁的原因,因为非公平锁减少了线程挂起的几率,后来的线程有一定几率逃离被挂起的开销。