![]()
了解更多Greenplum相关内容,欢迎访问Greenplum中文社区网站
引言
PostgreSQL数据库采用快照隔离(Snapshot Isolation)技术实现并发控制,快照隔离是利用数据的多版本实现并发控制的一种方式。快照保存了某个特定时间点活跃事务的状态信息。在PostgreSQL数据库中,对于Read Committed隔离级别,事务中的每条SQL语句的执行都会获取一个快照,对于Repeatable Read隔离级别,事务只在第一条SQL语句的执行时获取一个快照,后续的SQL语句使用同一个快照。
快照隔离存在的异常现象
尽管快照隔离可以避免脏读、不可重复读、幻读这三种读异常现象,但并不是真正的可串行化隔离级别,文献[1]指出快照隔离级别中存在写偏斜(Write Skew)的异常现象。写偏斜发生在两个并发的事务读取相同的数据,然后都修改了数据的交集部分。
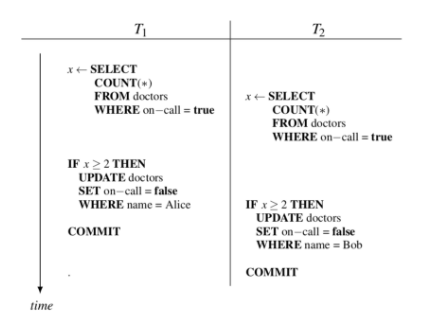
我们以一个示例讲述,这个示例来自于Dan和Kevin关于PostgreSQL数据库SSI实现的论文[2]。这个示例有两个并发的事务参与,每个事务完成的操作是:查找当前在值守的医生的数量,如果数量大于等于2,那么就选择一位医生离岗。在快照隔离级别下,假如两个事务执行之前,医生Alice和Bob都在岗,每个事务开始执行,首先取得自己的快照,查询满足条件的医生数量,就是Alice和Bob都在岗,然后更新两位医生为离岗状态。这就违背了可串行化隔离级别,因为业务逻辑是要保证至少有一位医生在岗。如果两个事务串行方式依次执行,就能保证这个业务逻辑。
![]()
图1:一个写偏斜的示例
再看一个有三个事务参与的异常现象。这个示例描述了一个收入报表的业务,在这个业务中,有两个表,收据表receipts记录每条收入的批号(batch,以日期表示)和其他相关信息,控制表记录当前批号。有三个事务参与这个业务,事务T1从控制表里获取当前批号,然后向收据表里增加一条记录;事务T2将控制表里的批号加一;事务T3是一个只读事务,先获取当前批号,然后查询上一个批号的所有收入,也就是获取昨天的所有收入。下图描述了三个事务一个执行顺序,在这个例子中,当T3统计昨天的所有收入,并不能查询到T1增加的新记录。
尽管快照和加锁方式实现并发控制相比有性能上的优势,但是快照隔离并不等同于可串行化隔离级别,会引入如上图两个例子所示的异常和数据不一致现象。所以为了既能享受快照的性能优势,又能让快照的实现满足可串行化隔离级别,业内研究者做了很多相关工作,提出了可串行化快照隔离(Serializable Snapshot Isolation,SSI),PostgreSQL社区也于2012年实现了SSI技术,使得PostgreSQL真正意义上支持可串行化隔离级别。
![]()
图2:多个事务参与的SI的异常现象
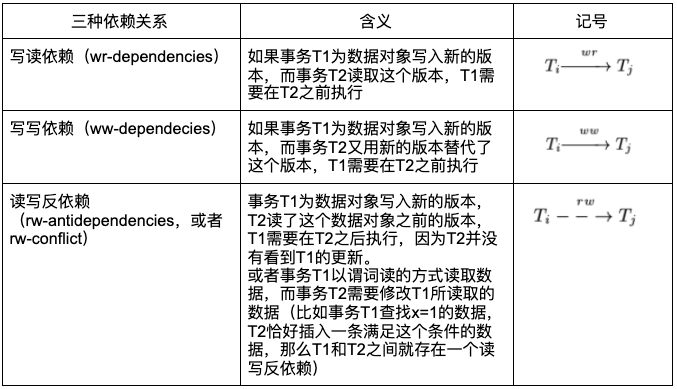
简单介绍SSI的理论基础。Adya在文献[3]提出了用多版本可序列化图(multiversion serialization graph,简称MVSG)来表示并发事务之间的关系。在MVSG图中,每个顶点代表一个事务,如果有两个事务T1和T2,T1必须在T2之前,那么就有一条从T1到T2的有向边。如下表所示,有三种有向边:
![]()
如果这些事务所构成的MVSG图中形成一个有向环,那么这些事务是无法对应一个可串行化调度,也是无法可串行化的。
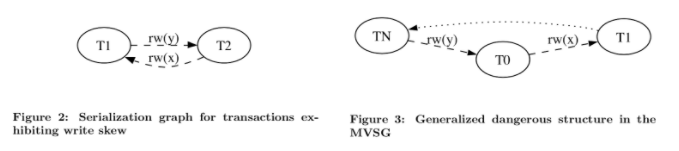
有了MVSG图的定义,我们再回头看刚才的两个示例,第一个实际示例中两个事务互相读写反依赖于对方,所以形成了一个环路,这两个事务构成的调度不是可串行化的。第二个示例,T1和T2之间存在读写反依赖,而T2和T3之间存在写读依赖,三个事务的调度构成了一个环路,同样不是可串行化的。
![]()
图4:读写反依赖
Adya和Fekete的研究[4]发现一个定理:在序列化历史图里的每一个环路都存在着T1 -> T2 -> T3读写反依赖关系,其中,T3一定是这个环里的事务中最先提交的事务。
如果T1和T3为同一个事务就是在第一个例子的情况,T1和T2之间构成环。第二个示例的环中,同样存在T1 -> T2 -> T3读写反依赖的序列。
SSI技术的实现原理
Cahill等人根据这个定理使用快照隔离技术实现了可串行化快照隔离级别[4],这个实现的原理是在数据库运行的过程中,检查可能存在的异常现象,如果发现按需终止某些事务,以保证其余的事务以可串行化隔离级别运行。这个实现的思路,和通过SSN(Serial Safety Net)协议[5]类似。与之不同的是,SSN协议检查时查找的是一个环路,而SSI协议查找的是一个“危险结构”,也就是SSI PostgreSQL论文里所提到的“dangerous structure”,这个危险结构就是上面所说的两个相邻的读写反依赖关系。
但是这个结论反过来并不成立,也就是说,如果在MVSG图中发现两个相邻的读写反依赖,不一定构成一个环路。SSI实现的理论基础,就是在并发的事务中寻找这种危险的结构,然后采取一定的策略,回滚某个事务。所以SSI的实现是在发现这种危险结构后会主动回滚一些事务,而且也有可能出现错判的情况。SSI这种实现收益却是很明显的,首先不需要检测存在的环路,仅仅需要检测两个相邻的读写反依赖关系,代价比SSN方式小很多,另外,SSI实现仅需要追踪读写反依赖,并不需要追踪写写依赖或者写读依赖,也极大地减轻了实现层面上的复杂性和数据库系统运行时资源的开销。并且这种方式比两阶段加锁和乐观并发控制协议有更高的并发性能。两阶段加锁和乐观并发控制协议不允许出现读写反依赖,而SSI允许出现读写反依赖,只要不形成这种“危险结构”。
PostgreSQL的SSI实现基础就是基于这个定理,在并发的事务中查找可能存在的两个相邻的读写冲突(rw-conflicts),如果发现就根据一定策略选择一个事务回滚。并返回SQL ERROR 400。
PostgreSQL SSI使用示例
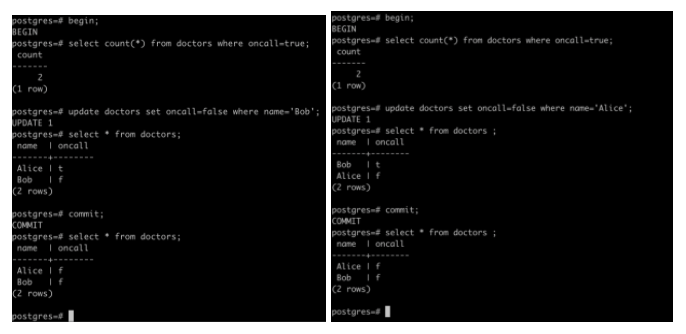
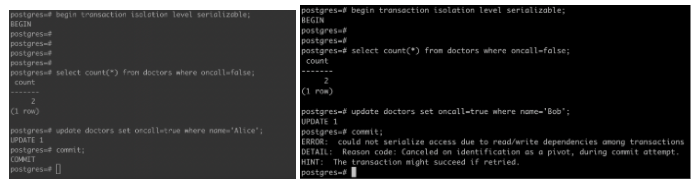
我们在PostgreSQL里用可重复读隔离级别和可串行化隔离级别分别运行上述的例子,可以发现在可重复读隔离级别,两个事务都能执行成功,也就出现了不一致现象。而在可串行隔离级别运行同样的例子,可以发现,第二个提交的事务返回一个SQL400的错误,这是因为SSI的实现检测到了两个事务存在“危险的结构”,于是根据“先提交者获胜”(first-commit-win)的原则,终止第二个提交的事务。
![]()
图5:在可重复读隔离级别的运行示例
![]()
图6:在可串行化隔离级别的运行示例
参考资料:
[1] H. Berenson, P. Bernstein, J. Gray, J. Melton,
E. O’Neil, , and P. O’Neil. A critique of ANSI SQL isolation levels. In Proceedings of ACM SIGMOD International Conference on Management of Data, pages 1–10. ACM Press, June 1995
[2] Dan R. K. Ports and Kevin Grittner. 2012. Serializable Snapshot Isolation in PostgreSQL. Proceedings of the VLDB Endowment vol. 5 (12) , August 2012
[3] A. Adya, B. Liskov, and P. O’Neil. Generalized isolation level definitions. In ICDE, pages 67–80, 2000.
[4] M.J.Cahill,U.Röhm,and A.D.Fekete. Serializable Isolation for Snapshot Databases. SIGMOD, 2008.
[5] T. Wang, R. Johnson, A. Fekete, and I. Pandis. Efficiently Making (Almost) Any Concurrency Control Mechanism Serializable. arXiv:1605.04292, 2016.
![]()