回复“ 666 ”获取独家整理的学习资料!
作者:远航
cnblogs.com/yang-guang-zhang/p/13884023.html
一、单链表
1、在我们数据结构中,单链表非常重要。它里面的数据元素是以结点为单位,每个结点是由数据元素的数据和下一个结点的地址组成,在java集合框架里面 LinkedList、HashMap(数组加链表)等等的底层都是用链表实现的。
2、下面是单链表的几个特点:
数据元素在内存中存放的地址是不连续的:单链表的结点里面还定义一个结点,它里面保存着下一个结点的内存地址,在实例化对象的时候,jvm会开辟不同内存空间,并且是不连续的。
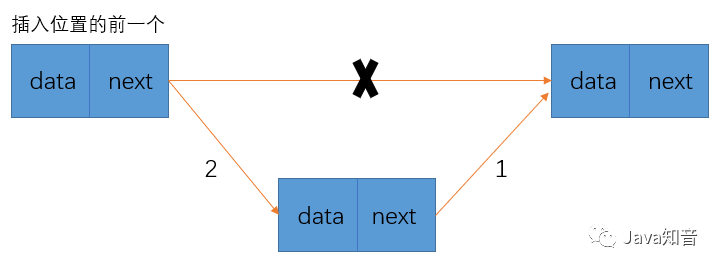
添加效率高:添加一个元素时,先找到插入位置的前一个,只需要将1,2个元素的连接断开,将插入结点的next指向第一个元素的next
(1),然后将第一个元素的next指向插入结点(2),
不用在挪动后面元素。
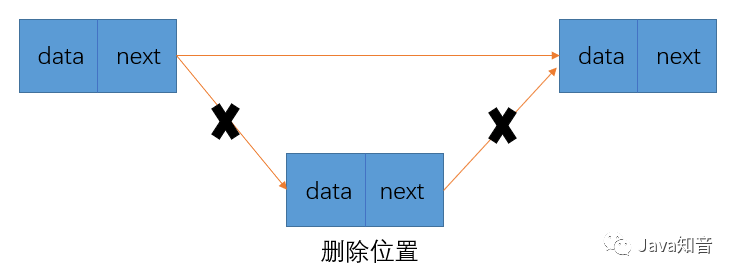
删除效率高:删除一个元素时,先找到删除位置,将前一个的next指向删除位置的next,不用在挪动后面元素。
3、下面通过代码来实现单链表结构:
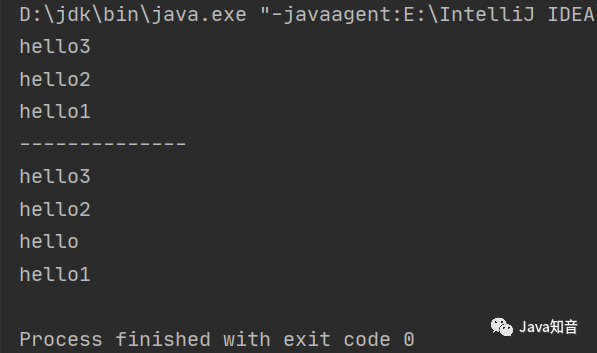
package com.tlinkedList;/** public class TLinkedList <T > private Node head;//链表头部 private int size;//链表元素的个数 public TLinkedList () null ;0 ;// 将结点作为内部类。也可以新建一个Node类,作为结点 class Node private Node next;//下一个结点 private T t;//结点的数据 public Node (T t) this .t=t;public T getT () return t;public void setT (T t) this .t = t;// 在链表头部添加一个结点 public void addFirst (T t) new Node(t);// 在链表中间添加一个结点 public void addMid (T t,int index) new Node(t);for (int i = 0 ; i < index - 1 ; i++) {// 在链表尾部添加一个结点 public void addLast (T t) new Node(t);while (last.next!=null ){null ;// 删除链表的头结点 public void removeFirst () // 删除链表的中间元素 public void removeMid (int index) if (index==0 ){return ;int j=0 ;while (j<index){// 删除链表的尾结点 public void removeLast () while (mid.next!=null ){null ;// 获取链表指定下标的结点 public Node get (int index) if (index==0 ){return head;int j=0 ;while (j<index){return mid;public static void main (String[] args) new TLinkedList<>();"hello1" );"hello2" );"hello3" );for (int i = 0 ; i < linkedList.size; i++) {// linkedList.removeLast(); // linkedList.removeFirst(); // linkedList.addLast("hello4"); "hello" ,2 );"--------------" );for (int i = 0 ; i < linkedList.size; i++) {结果如下:
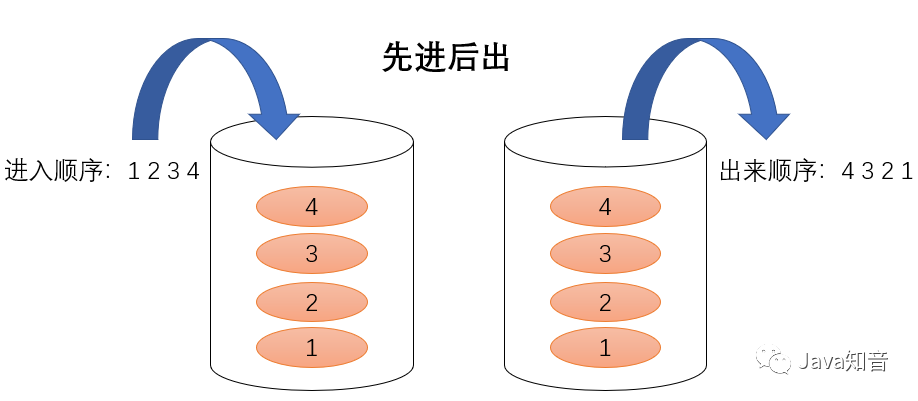
1、一提到栈我们脑海就会浮现四个字“先进后出”,没错,它就是栈的最大特点。
3、栈里面的主要操作有:
peek(返回栈顶元素):将栈顶元素的数据返回
4、下面通过链表结构实现栈结构:
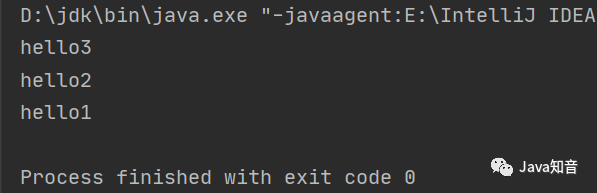
package com.tStack;/** public class Test_Stack <T > private Node head;//栈的头结点 private int size;//栈的元素个数 class Node private Node next;//下一个结点 private T t;//结点的数据 public Node (T t) this .t=t;public T getT () return t;public void setT (T t) this .t = t;public Test_Stack () null ;0 ;public static void main (String[] args) new Test_Stack<>();"hello1" );"hello2" );"hello3" );for (int i = 0 ; i < 3 ; i++) {// 入栈 public void push (T t) new Node(t);if (size==0 ){return ;if (size==1 ){null ;return ;while (lastNode.next!=null ){null ;// 出栈 public T pop () if (size==0 ){"栈内无值" );return null ;if (size==1 ){null ;return t;while (lastNode.next!=null ){null ;return t;// 获取栈里面元素的个数 public int getSize () return size;// 返回栈顶元素 public T peek () if (size==0 ){"栈内无值" );return null ;if (size==1 ){return head.getT();while (lastNode.next!=null ){return lastNode.getT();结果:
1、队列的特点也用“先进先出”四个字来概括。就是先进去的元素先输出出来。
2、我们常见的消息队列就是队列结构实现的。
3、队列的常见操作如下:
pop(出队):将头结点的下一个结点作为头,然后将原来的头结点删除。
4、通过链表结构实现队列:
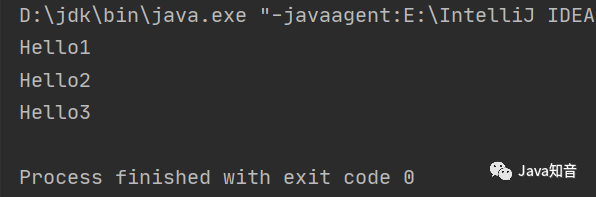
package com.tQueue;/** public class TQueue <T > private Node front;//头结点 private Node tail;//尾结点 private int size;//队列中元素的个数 class Node private Node next;//下一个结点 private T t;//结点的数据 public Node (T t) this .t = t;public T getT () return t;public void setT (T t) this .t = t;public int getSize () return size;public void setSize (int size) this .size = size;public TQueue () null ;// 入队 public void put (T t) new Node(t);if (size == 0 ) {return ;while (lastNode.next != null ) {// 出队 public T pop () if (size == 0 ) {"队列中无值" );return null ;return t;public static void main (String[] args) new TQueue<>();"Hello1" );"Hello2" );"Hello3" );for (int i = 0 ; i < 3 ; i++) {结果:
文章有不足之处,欢迎大家留言指正,谢谢大家啦!
最近面试BAT,整理一份面试资料 《Java面试BAT通关手册 》 ,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“ 在看 ”,关注公众号并回复 666 领取,更多内容陆续奉上。