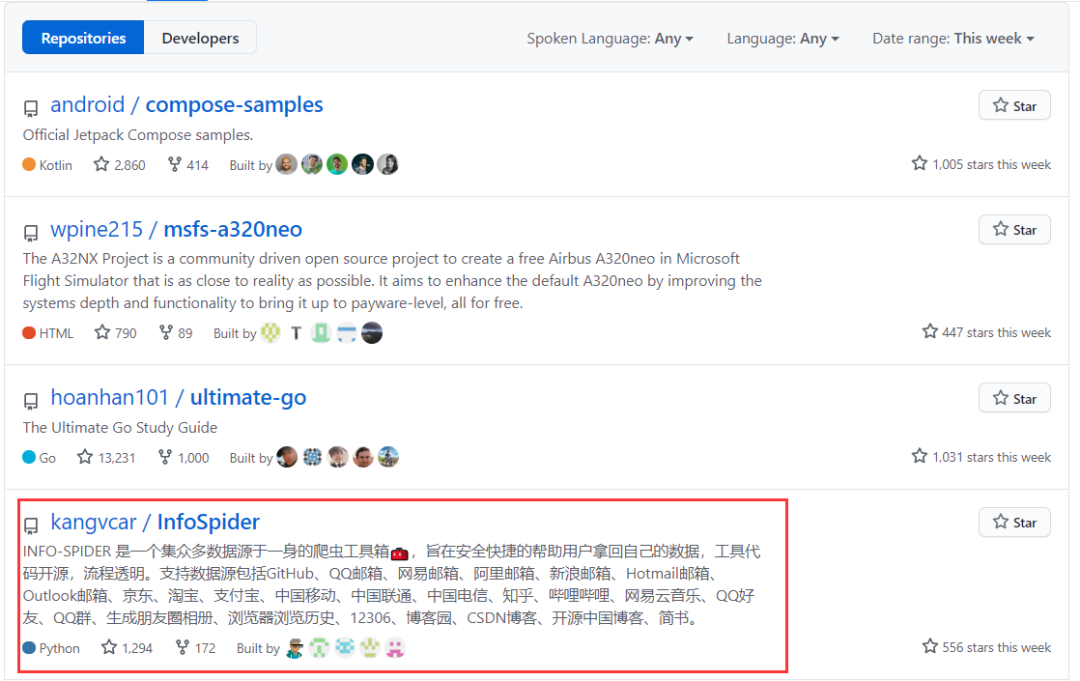
最近国内一位开发者在 GitHub 上开源了个集众多数据源于一身的爬虫工具箱——InfoSpider,一不小心就火了!!!
![]()
有多火呢?开源没几天就登上GitHub周榜第四,标星1.3K,累计分支 172 个。同时作者已经开源了所有的项目代码及使用文档,并且在B站上还有使用视频讲解。
项目代码:
https://github.com/kangvcar/InfoSpider
项目使用文档:
https://infospider.vercel.app
项目视频演示:
https://www.bilibili.com/video/BV14f4y1R7oF/
在这样一个信息爆炸的时代,每个人都有很多个账号,账号一多就会出现这么一个情况:个人数据分散在各种各样的公司之间,就会形成数据孤岛,多维数据无法融合,这个项目可以帮你将多维数据进行融合并对个人数据进行分析,这样你就可以更直观、深入了解自己的信息。
InfoSpider 是一个集众多数据源于一身的爬虫工具箱,旨在安全快捷的帮助用户拿回自己的数据,工具代码开源,流程透明。并提供数据分析功能,基于用户数据生成图表文件,使得用户更直观、深入了解自己的信息。
![]()
目前支持数据源包括 GitHub、QQ邮箱、网易邮箱、阿里邮箱、新浪邮箱、Hotmail邮箱、Outlook邮箱、京东、淘宝、支付宝、中国移动、中国联通、中国电信、知乎、哔哩哔哩、网易云音乐、QQ好友、QQ群、生成朋友圈相册、浏览器浏览历史、12306、博客园、CSDN博客、开源中国博客、简书 。
根据创建者介绍,InfoSpider 具有以下特性:
-
安全可靠 :本项目为开源项目,代码简洁,所有源码可见,本地运行,安全可靠。
-
使用简单 :提供 GUI 界面,只需点击所需获取的数据源并根据提示操作即可。
-
结构清晰 :本项目的所有数据源相互独立,可移植性高,所有爬虫脚本在项目的 Spiders 文件下。
-
数据源丰富 :本项目目前支持多达24+个数据源,持续更新。
-
数据格式统一:爬取的所有数据都将存储为json格式,方便后期数据分析。
-
个人数据丰富 :本项目将尽可能多地为你爬取个人数据,后期数据处理可根据需要删减。
-
数据分析 :本项目提供个人数据的可视化分析,目前仅部分支持。
InfoSpider使用起来也非常简单,你只需要安装python3和Chrome浏览器,运行 python3 main.py,在打开的窗口点击数据源按钮, 根据提示选择数据保存路径,接着输入账号密码,就会自动爬取数据,根据下载的目录就可以查看爬下来的数据。
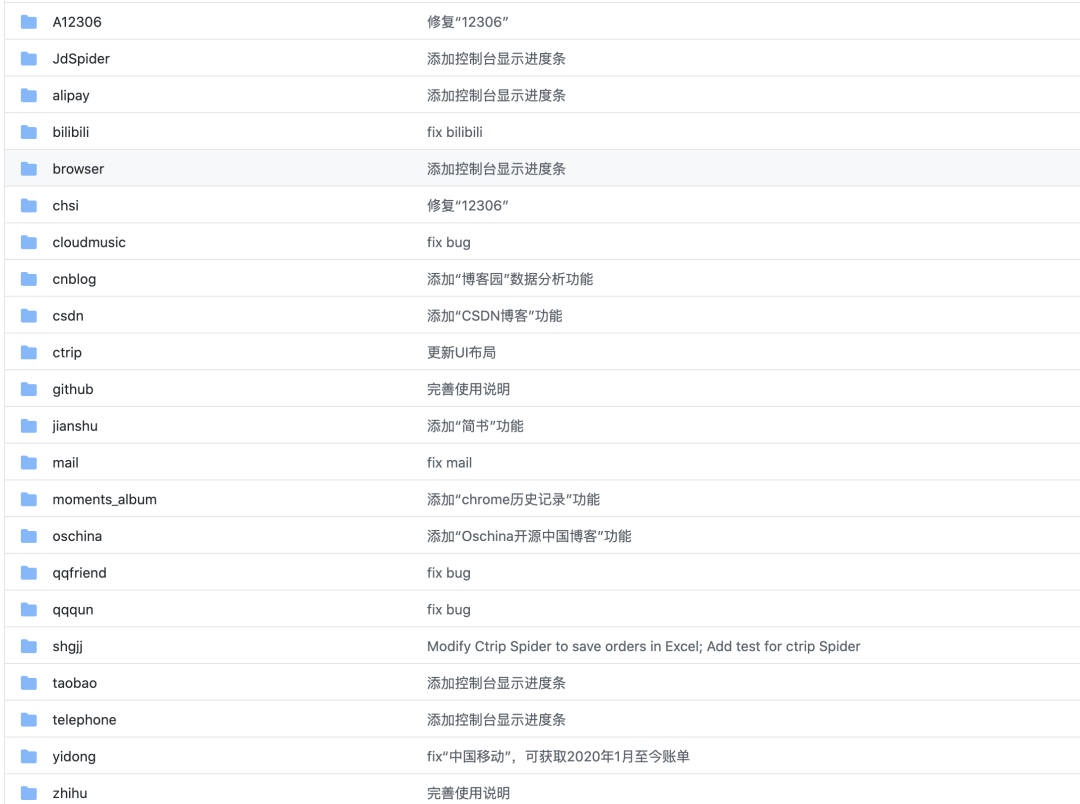
当然如果你想自己去练习和学习爬虫,作者也开源了所有的爬取代码,非常适合实战。
![]()
举个例子,比如爬取taobao的:
import json
import random
import time
import sys
import os
import requests
import numpy as np
import math
from lxml import etree
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver import ChromeOptions, ActionChains
from tkinter.filedialog import askdirectory
from tqdm import trange
def ease_out_quad(x):
return 1 - (1 - x) * (1 - x)
def ease_out_quart(x):
return 1 - pow(1 - x, 4)
def ease_out_expo(x):
if x == 1:
return 1
else:
return 1 - pow(2, -10 * x)
def get_tracks(distance, seconds, ease_func):
tracks = [0]
offsets = [0]
for t in np.arange(0.0, seconds, 0.1):
ease = globals()[ease_func]
offset = round(ease(t / seconds) * distance)
tracks.append(offset - offsets[-1])
offsets.append(offset)
return offsets, tracks
def drag_and_drop(browser, offset=26.5):
knob = browser.find_element_by_id('nc_1_n1z')
offsets, tracks = get_tracks(offset, 12, 'ease_out_expo')
ActionChains(browser).click_and_hold(knob).perform()
for x in tracks:
ActionChains(browser).move_by_offset(x, 0).perform()
ActionChains(browser).pause(0.5).release().perform()
def gen_session(cookie):
session = requests.session()
cookie_dict = {}
list = cookie.split(';')
for i in list:
try:
cookie_dict[i.split('=')[0]] = i.split('=')[1]
except IndexError:
cookie_dict[''] = i
requests.utils.add_dict_to_cookiejar(session.cookies, cookie_dict)
return session
class TaobaoSpider(object):
def __init__(self, cookies_list):
self.path = askdirectory(title='选择信息保存文件夹')
if str(self.path) == "":
sys.exit(1)
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
option.add_argument('--headless')
self.driver = webdriver.Chrome(options=option)
self.driver.get('https://i.taobao.com/my_taobao.htm')
for i in cookies_list:
self.driver.add_cookie(cookie_dict=i)
self.driver.get('https://i.taobao.com/my_taobao.htm')
self.wait = WebDriverWait(self.driver, 20) # 超时时长为10s
# 模拟向下滑动浏览
def swipe_down(self, second):
for i in range(int(second / 0.1)):
# 根据i的值,模拟上下滑动
if (i % 2 == 0):
js = "var q=document.documentElement.scrollTop=" + str(300 + 400 * i)
else:
js = "var q=document.documentElement.scrollTop=" + str(200 * i)
self.driver.execute_script(js)
time.sleep(0.1)
js = "var q=document.documentElement.scrollTop=100000"
self.driver.execute_script(js)
time.sleep(0.1)
# 爬取淘宝 我已买到的宝贝商品数据, pn 定义爬取多少页数据
def crawl_good_buy_data(self, pn=3):
# 对我已买到的宝贝商品数据进行爬虫
self.driver.get("https://buyertrade.taobao.com/trade/itemlist/list_bought_items.htm")
# 遍历所有页数
for page in trange(1, pn):
data_list = []
# 等待该页面全部已买到的宝贝商品数据加载完毕
good_total = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#tp-bought-root > div.js-order-container')))
# 获取本页面源代码
html = self.driver.page_source
# pq模块解析网页源代码
doc = pq(html)
# # 存储该页已经买到的宝贝数据
good_items = doc('#tp-bought-root .js-order-container').items()
# 遍历该页的所有宝贝
for item in good_items:
# 商品购买时间、订单号
good_time_and_id = item.find('.bought-wrapper-mod__head-info-cell___29cDO').text().replace('\n', "").replace('\r', "")
# 商家名称
# good_merchant = item.find('.seller-mod__container___1w0Cx').text().replace('\n', "").replace('\r', "")
good_merchant = item.find('.bought-wrapper-mod__seller-container___3dAK3').text().replace('\n', "").replace('\r', "")
# 商品名称
# good_name = item.find('.sol-mod__no-br___1PwLO').text().replace('\n', "").replace('\r', "")
good_name = item.find('.sol-mod__no-br___3Ev-2').text().replace('\n', "").replace('\r', "")
# 商品价格
good_price = item.find('.price-mod__price___cYafX').text().replace('\n', "").replace('\r', "")
# 只列出商品购买时间、订单号、商家名称、商品名称
# 其余的请自己实践获取
data_list.append(good_time_and_id)
data_list.append(good_merchant)
data_list.append(good_name)
data_list.append(good_price)
#print(good_time_and_id, good_merchant, good_name)
#file_path = os.path.join(os.path.dirname(__file__) + '/user_orders.json')
# file_path = "../Spiders/taobao/user_orders.json"
json_str = json.dumps(data_list)
with open(self.path + os.sep + 'user_orders.json', 'a') as f:
f.write(json_str)
# print('\n\n')
# 大部分人被检测为机器人就是因为进一步模拟人工操作
# 模拟人工向下浏览商品,即进行模拟下滑操作,防止被识别出是机器人
# 随机滑动延时时间
swipe_time = random.randint(1, 3)
self.swipe_down(swipe_time)
# 等待下一页按钮 出现
good_total = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.pagination-next')))
good_total.click()
time.sleep(2)
# while 1:
# time.sleep(0.2)
# try:
# good_total = self.driver.find_element_by_xpath('//li[@title="下一页"]')
# break
# except:
# continue
# # 点击下一页按钮
# while 1:
# time.sleep(2)
# try:
# good_total.click()
# break
# except Exception:
# pass
# 收藏宝贝 传入爬几页 默认三页 https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
def get_choucang_item(self, page=3):
url = 'https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow={}'
pn = 0
json_list = []
for i in trange(page):
self.driver.get(url.format(pn))
pn += 30
html_str = self.driver.page_source
if html_str == '':
break
if '登录' in html_str:
raise Exception('登录')
obj_list = etree.HTML(html_str).xpath('//li')
for obj in obj_list:
item = {}
item['title'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]//text()')])
item['url'] = ''.join([i.strip() for i in obj.xpath('./div[@class="img-item-title"]/a/@href')])
item['price'] = ''.join([i.strip() for i in obj.xpath('./div[@class="price-container"]//text()')])
if item['price'] == '':
item['price'] = '失效'
json_list.append(item)
# file_path = os.path.join(os.path.dirname(__file__) + '/shoucang_item.json')
json_str = json.dumps(json_list)
with open(self.path + os.sep + 'shoucang_item.json', 'w') as f:
f.write(json_str)
# 浏览足迹 传入爬几页 默认三页 https://shoucang.taobao.com/nodejs/item_collect_chunk.htm?ifAllTag=0&tab=0&tagId=&categoryCount=0&type=0&tagName=&categoryName=&needNav=false&startRow=60
def get_footmark_item(self, page=3):
url = 'https://www.taobao.com/markets/footmark/tbfoot'
self.driver.get(url)
pn = 0
item_num = 0
json_list = []
for i in trange(page):
html_str = self.driver.page_source
obj_list = etree.HTML(html_str).xpath('//div[@class="item-list J_redsList"]/div')[item_num:]
for obj in obj_list:
item_num += 1
item = {}
item['date'] = ''.join([i.strip() for i in obj.xpath('./@data-date')])
item['url'] = ''.join([i.strip() for i in obj.xpath('./a/@href')])
item['name'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="title"]//text()')])
item['price'] = ''.join([i.strip() for i in obj.xpath('.//div[@class="price-box"]//text()')])
json_list.append(item)
self.driver.execute_script('window.scrollTo(0,1000000)')
# file_path = os.path.join(os.path.dirname(__file__) + '/footmark_item.json')
json_str = json.dumps(json_list)
with open(self.path + os.sep + 'footmark_item.json', 'w') as f:
f.write(json_str)
# 地址
def get_addr(self):
url = 'https://member1.taobao.com/member/fresh/deliver_address.htm'
self.driver.get(url)
html_str = self.driver.page_source
obj_list = etree.HTML(html_str).xpath('//tbody[@class="next-table-body"]/tr')
data_list = []
for obj in obj_list:
item = {}
item['name'] = obj.xpath('.//td[1]//text()')
item['area'] = obj.xpath('.//td[2]//text()')
item['detail_area'] = obj.xpath('.//td[3]//text()')
item['youbian'] = obj.xpath('.//td[4]//text()')
item['mobile'] = obj.xpath('.//td[5]//text()')
data_list.append(item)
# file_path = os.path.join(os.path.dirname(__file__) + '/addr.json')
json_str = json.dumps(data_list)
with open(self.path + os.sep + 'address.json', 'w') as f:
f.write(json_str)
if __name__ == '__main__':
# pass
cookie_list = json.loads(open('taobao_cookies.json', 'r').read())
t = TaobaoSpider(cookie_list)
t.get_orders()
# t.crawl_good_buy_data()
# t.get_addr()
# t.get_choucang_item()
# t.get_footmark_item()